场景:搜索(一个query 多个文档)
用squeeze-and-Excitation从排序候选序列中动态地学习特征的重要性。
对于列表中item重要的特征取决于其所属的整个list的情况。
整体模型架构
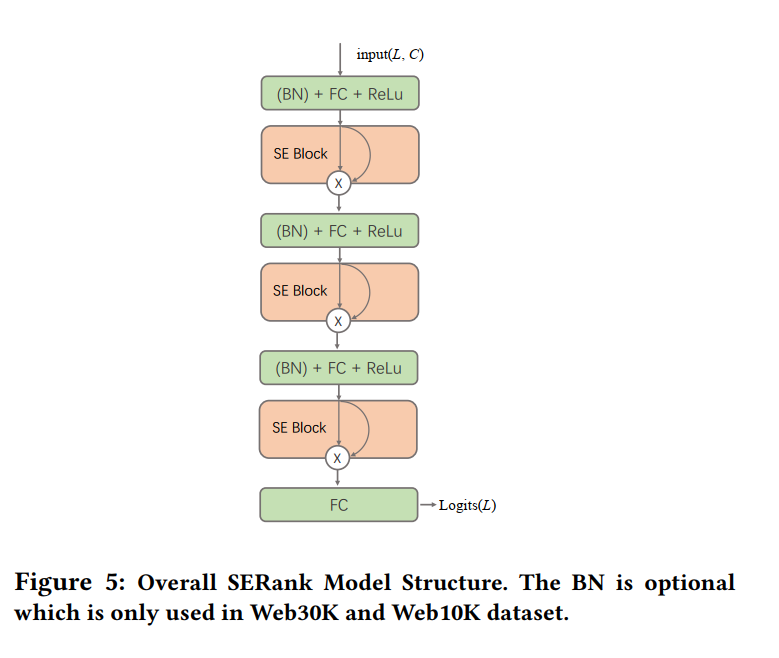
Squeeze-and-Excitation Model
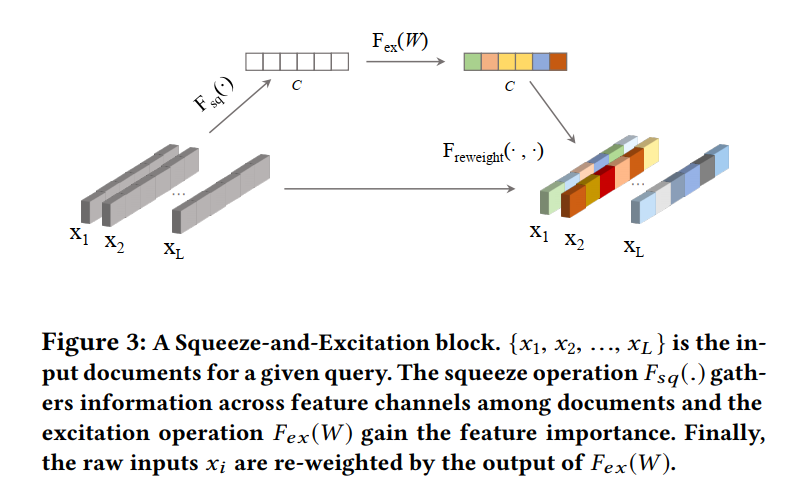
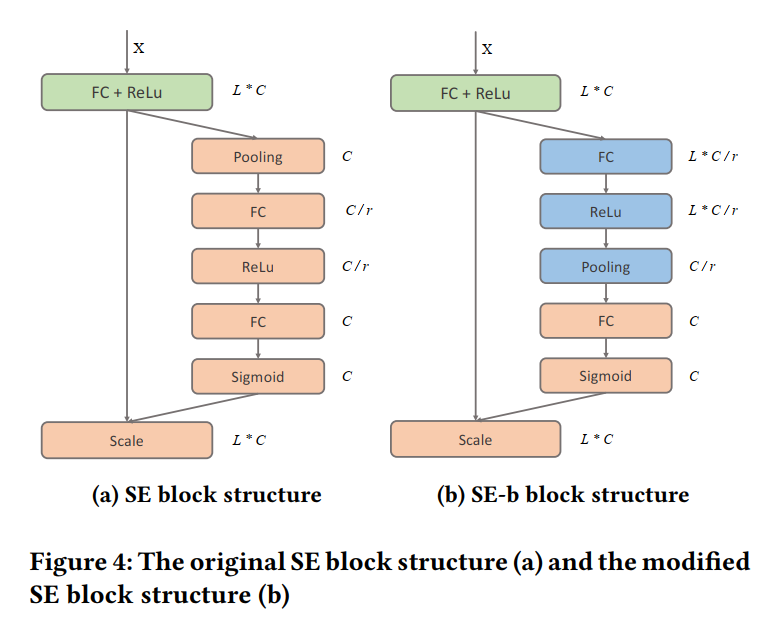
Squeeze操作
该步骤是对每个特征的全局信息进行统计(mean or max)。如图中所示,即对所有doc的同一维度的特征进行统计。
该步可以是max也可以是mean pooling。
Excitation操作
该步骤基于特征组的压缩统计量来学习各个特征的重要性权重。
用两层全连接的NN来实现。第一层为一个维度缩减层,第二层为维度提升层。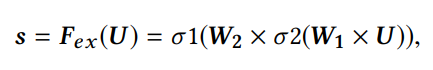
输出的s代表每一个文档的特征的权重。
Re-weight
这一步利用Excitation操作得到的特征权重来对原始的特征组embedding向量逐元素相乘,得到新的embedding向量。
排序模型
本文中以DNN为基本模型,并加入SE block。
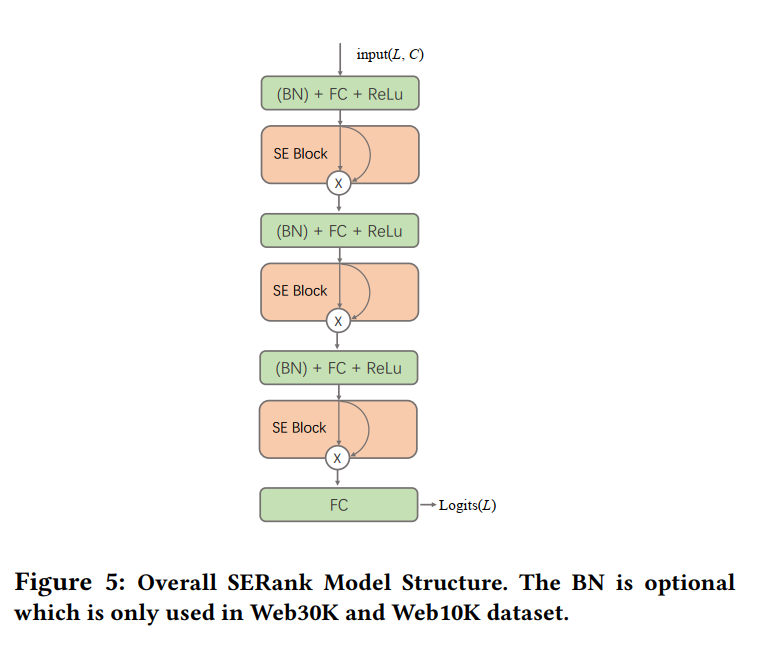
在这里我们使用修改过的SE模块,其结构如下所示。
Loss
对于该模型可以基于任意的loss函数。故本文使用了pair-wise和List-wise两种进行了实验。
实验细节
shrinkage rate = 2
数据集中query对应的doc数:16(知乎数据集)、120(Web30K)
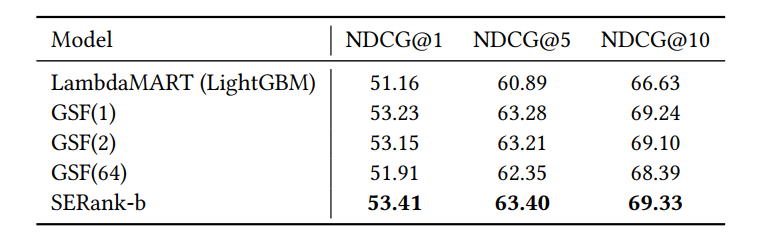
指标提升
NDCG
online click
相比于普通的DNN模型(三层隐藏层的网络结构),点击率提升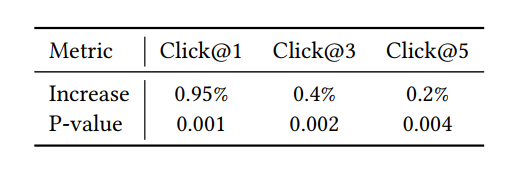

若有收获,就点个赞吧
0 人点赞
