18’SIGIR
总结
第一个直接将精排的top结果的局部上下文合并到一个LTR框架中的,并且直接使用原始的特征表示不需要额外的特征提取过程。
使用一个带GRU的RNN,获得上下文的表征,然后基于编码的上下文及各item的RNN隐藏表示使用排序函数对物品进行重新打分。
序
文章的introduction中提到了一个很好的切入点。就是对于不同的query的检索结果,其对结果的关注点不同(原文是说特征分布不同)。以新鲜和准确两个特征为例,
Motivation
针对现有的LTR是从全局数据中学习的,因此忽视了每个query之间特征分布的差别。
Method
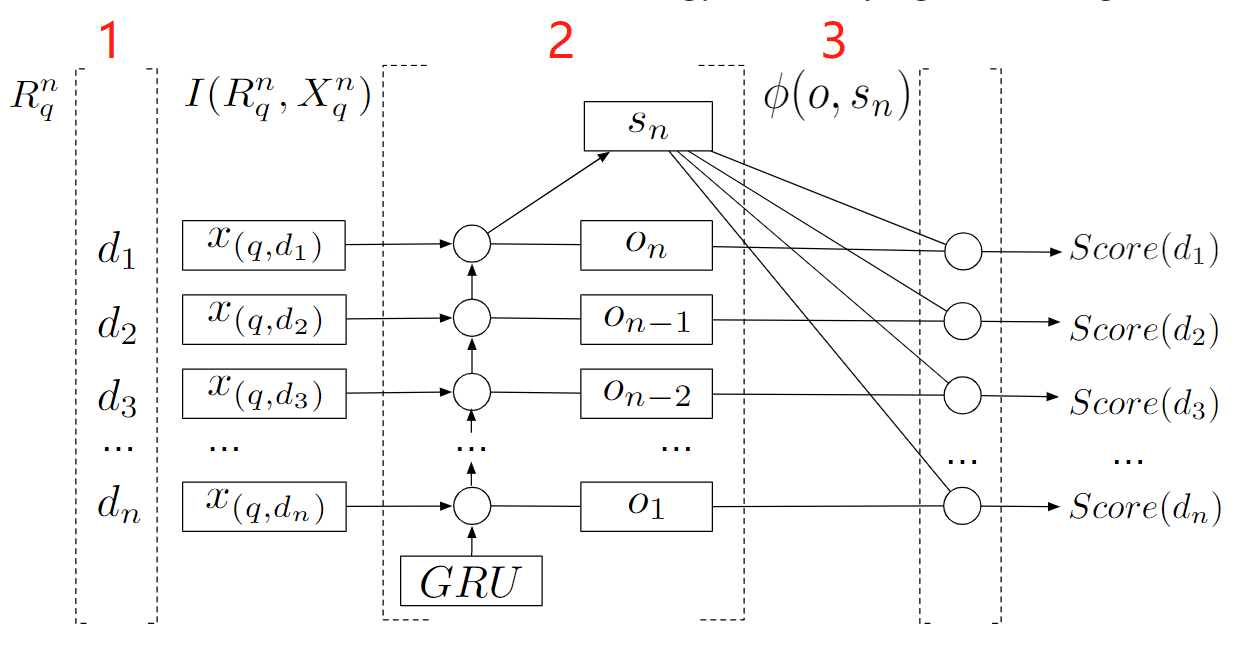
1.特征表示
将原始的特征表示通过两层的NN获得一个高阶的特征表示,然后将原始的特征表示与高阶的特征表示concat作为后续输入。
2. RNN with GRU
使用带有GRU的RNN来捕获上下文信息。因为RNN是一个一个地进行输入,所以当前的输入比前序的输入对当前的神经网络状态有着更大的影响。而为了让排在前列的物品对最终的网络状态产生更大的影响,这里选择了由排名低往排名高的顺序往RNN进行输入。
在该阶段使用RNN获得最终的网络状态 。
。 也表示着编码了局部上下文的模型
也表示着编码了局部上下文的模型
3. 打分重排
使用一个基于物品对应的RNN的输出表示 及排序上下文表示的排序函数对物品进行最终的打分。
及排序上下文表示的排序函数对物品进行最终的打分。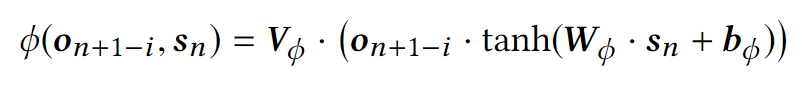

若有收获,就点个赞吧
0 人点赞
