Model
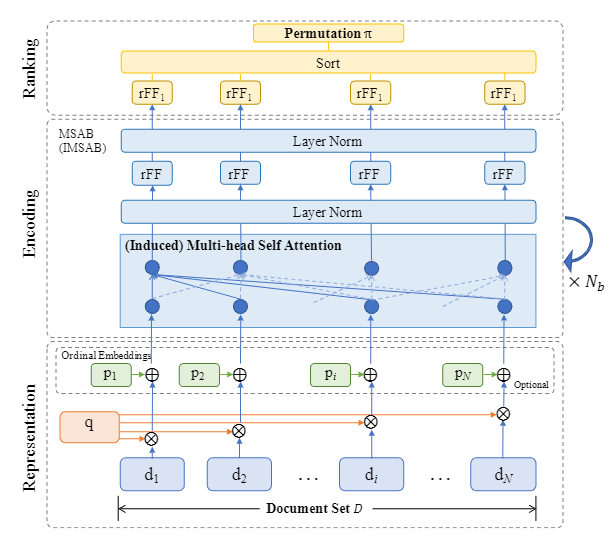
整个模型分为三步:
- representation
- Encoding
- Ranking
Representation
该层除了对每一个文档进行特征表示,对图输入的文档列表既可以是有序的可以是无序的。Document Representation
在文中的实验,直接使用数据集提供的特征表示。ordinal embedding
这里提出了一个ordinal嵌入函数P,该函数以文档的绝对排序位置作为输入,将该位置编码为与特征表示同纬度的向量。
其中提到的“绝对排序位置”是指由排序模型生成的序列中的位置。
该嵌入函数的存在,使得模型能够接受多种排序算法生成的不同的序列。P函数能将相同的item在不同序列中的位置信息整合到一起。表示层输出
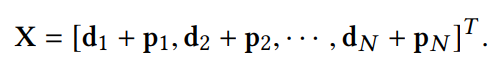
Encoding
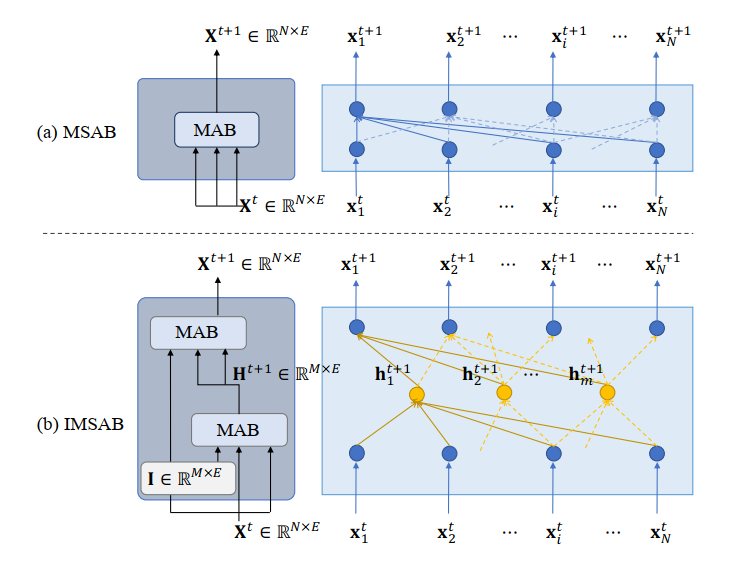
Induced MSAB
MSAB对输入集合的大小比较敏感。具体来说,就是测试集的匹配集合大于训练集的大小时,模型就会失效。
故使用了Set Transformer中的IMSAB,该模块的整体过程就是将输入X投影到低维空间H,然后再重构高维输出。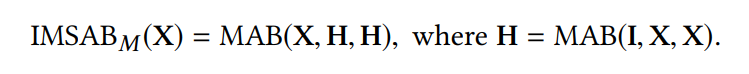
这里MAB中的三个参数分别表示Q、K、V。即Q=I,K=X,V=X。
在Set Transformer里面当对集合内部进行SA的时候,设置成Q=K=V=X,这样就能不使用残差模块了。
Ranking
在该步中,将多层SA的最终输出通过一个row-wise feed-forward(rFF) Function 得到最终的评分。rFF就是就是将每一个文档表达投影到一个实数,作为其最终的评分。
Loss
attention rank loss function。计算label的注意力分布和预测分数的注意力分布的距离。
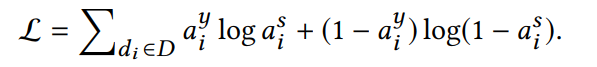

若有收获,就点个赞吧
0 人点赞
