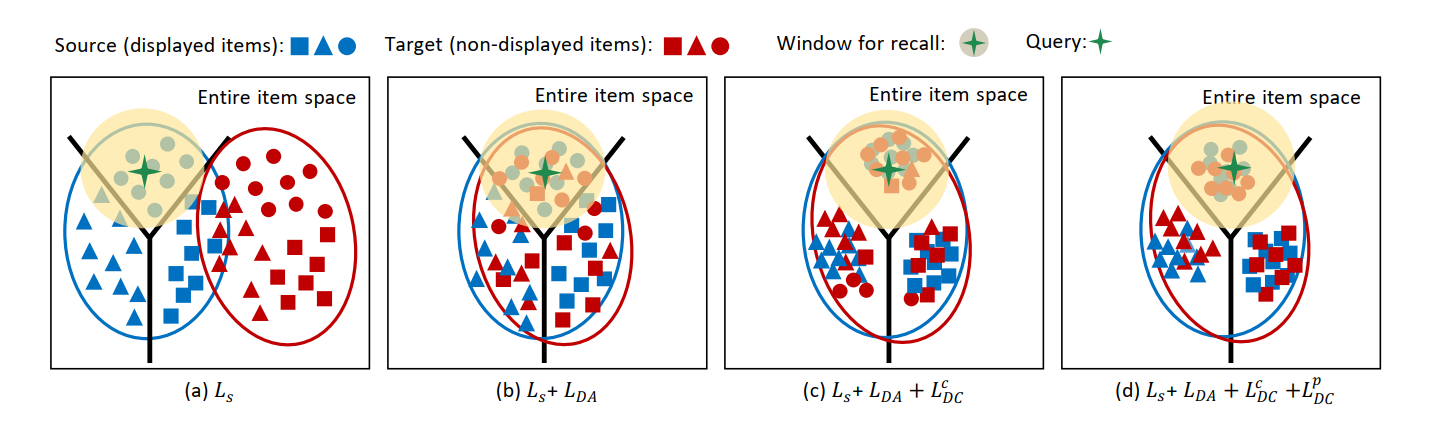
动机
只有曝光item才有label,所以只能在曝光数据集上训练embedding映射函数,但这导致学习出来的映射函数会将“曝光item”和“未曝光item”映射到向量空间中相距较远的两个区域。这使得训练出来的映射函数面对大量“未曝光item”时失效。
摘要
该工作从域适应(DA)的角度提出一个解决长尾推荐效果差的模型EASM(Entire Space Adaptation Model)。
- EASM将曝光的和未曝光的物品分别视为source和target域。
- 考虑到物品高层次属性之间的相关性,其设计了属性相关对齐(attribute correlation alignment)来实现分布对齐。
- 引入了两个正则化策略。
引言
ESAM是从为没有受到曝光的物品学习到好的特征表示这一角度来解决长尾物品的推荐问题。
ACA(attribute correlation alignment)是该工作为排序任务提出的一种新的域适应的方法。
- 特征的每个维度可以看做是物品的一个高级属性。两个空间中的物品表示中高级属性之间都需要遵循相同的规则。
- 具体地,设计了属性相关一致性(attribute correlation congruence,A2C)来利用高级属性之间的成对相关作为分布。从而解决分布不一致的问题。
ESAM
将item vetors组成的矩阵的相关性矩阵定义为分布。
定义属性相关一致性(A2C)作为分布度量,并且减少分布之间的距离,以保证高层属性在源域和目标域的相关性一致。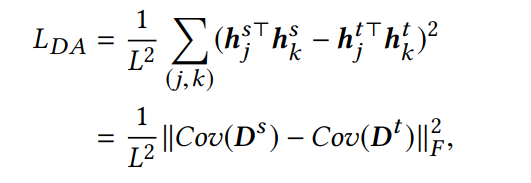
 就是用于实现A2C的。其中Cov()代表物品属性表示之间的协方差矩阵。虽然能source和target域对齐,但是无法对不同feedback的item进行区分。因此增加
就是用于实现A2C的。其中Cov()代表物品属性表示之间的协方差矩阵。虽然能source和target域对齐,但是无法对不同feedback的item进行区分。因此增加 ,实现feedback类别之间的高内聚、低耦合。
,实现feedback类别之间的高内聚、低耦合。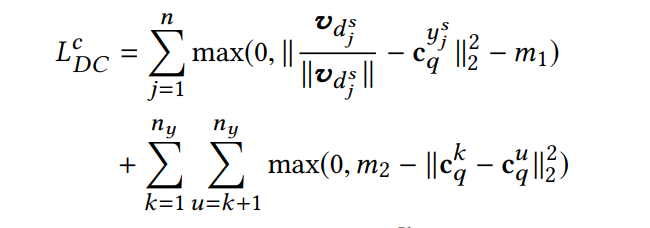
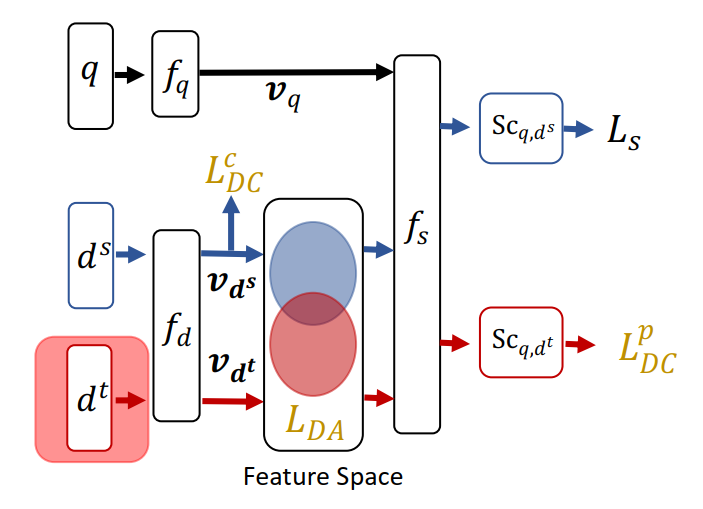
self-training for target clustering
目前,对于模型的期望,就是希望模型能够在target domain中也能像source domain中一样根据feedback类别进行聚类。但是问题在于,target domain中的item没有曝光机会,不能知道用户对于他们的feedback所属类别。
为了解决这个问题,ESAM提出了“伪label”。
- 训练中,如果当前模型,query “q” 与某个“未曝光item”的匹配得分相当低(小于阈值p1),我们就认为其是负样本,在接下来的训练中得分就要变得越来越小,趋近与0。
- 训练中,如果当前模型,query “q” 与某个“未曝光item”的匹配得分相当高(大于阈值p1),我们就认为其是正样本,在接下来的训练中得分就要变得越来越大,趋近与1。
在这个过程,模型并不需要去动态修改label,仅仅只是指明接下来优化的方向。所以使用如下的优化函数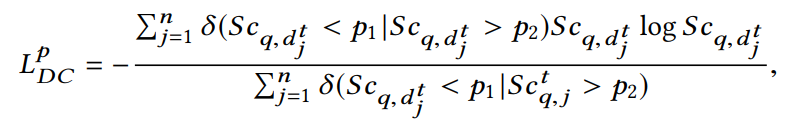
公式的主体其实是 的
的 形式。因为该函数具有当p较高时,其梯度能使其快速趋近于1;而在p较低时,其梯度能快速趋近于0。
形式。因为该函数具有当p较高时,其梯度能使其快速趋近于1;而在p较低时,其梯度能快速趋近于0。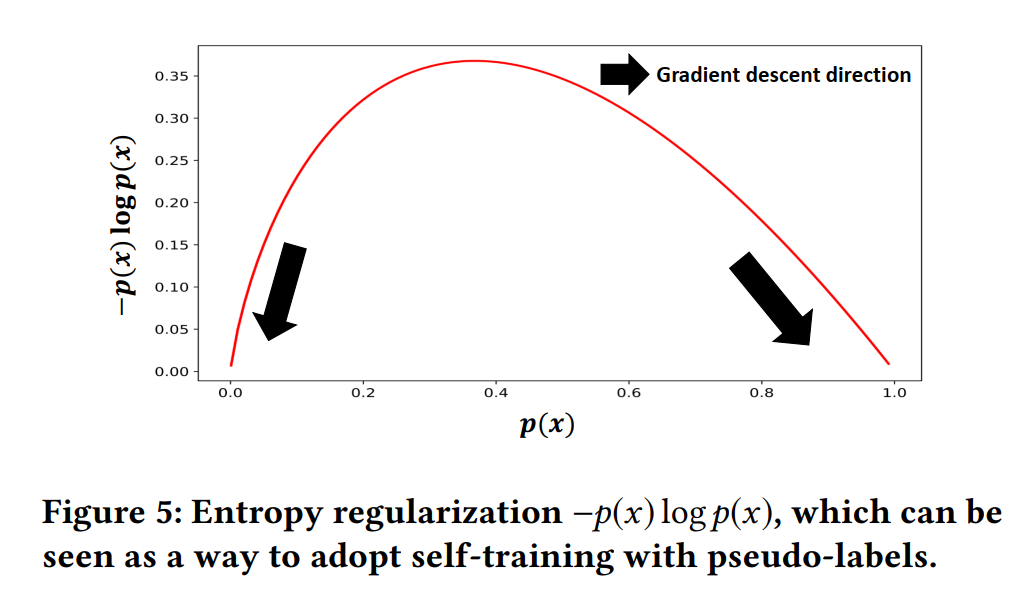
总结
最终模型的loss如下: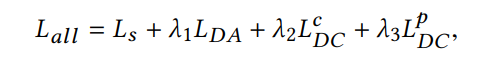
此文,最精彩的当属其使用伪标签的形式对“未曝光item”进行self-training。这使得模型不用定制一个硬规则决定哪些item属性hard negative。而是让面模型自己去学习这些lable,这属于一种自适应的hard negative策略。

若有收获,就点个赞吧
0 人点赞
