问题
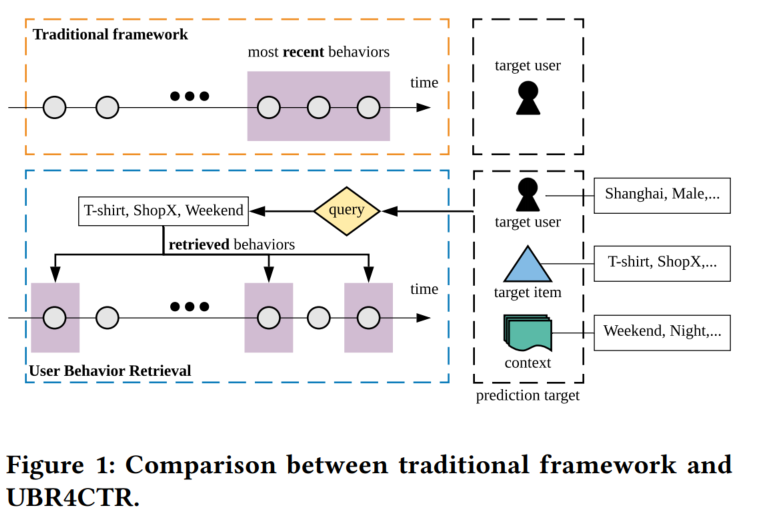
为了要捕获用户的转移兴趣,建模用户的序列行为是很重要的。但是往往只能截取用户最近的行为序列用于模型,因为使用用户所有的行为序列不可行。那么这样带来的问题就是截取的最近行为序列无法反应出周期性或者长期依赖等顺序模式。
本文思路
该文为了解决这个问题,选择从数据的角度考虑,而不是设计更复杂的模型。
UBR4CTR使用一种可学习的搜索方法从整个用户历史序列中检索出最相关和最合适的用户行为,然后将这些检索行为输入深度模型进行最终的预测。
框图
详细框架
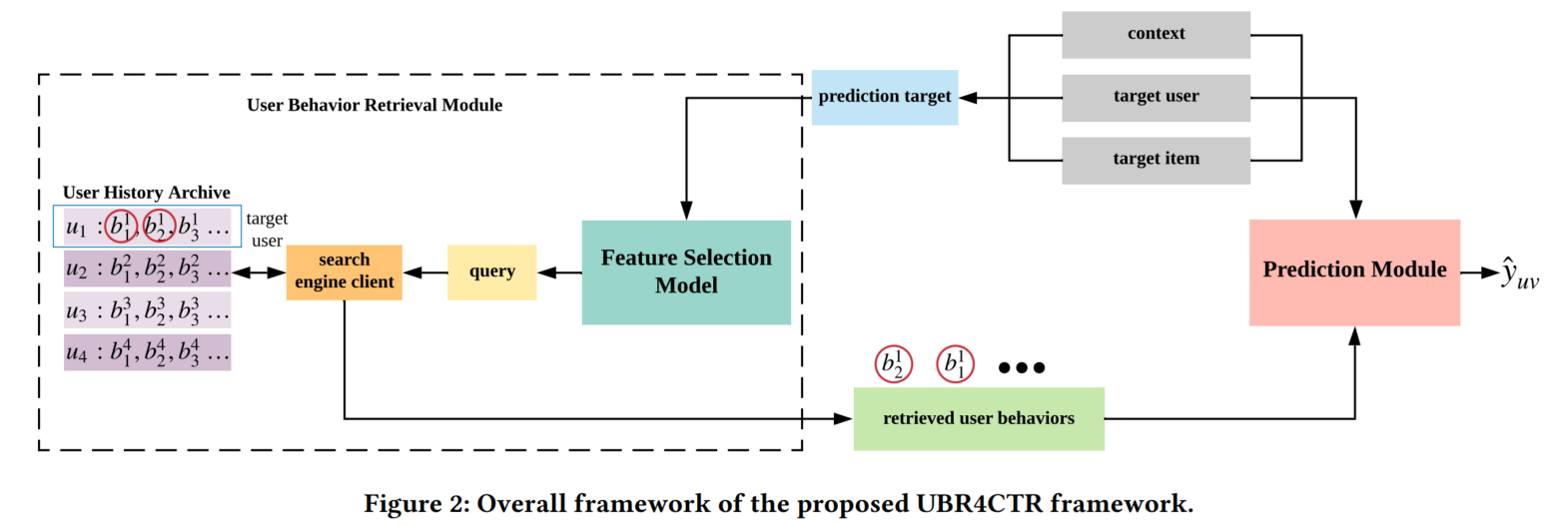
预测目标:由目标用户、目标物品和上下文的一系列特征组成。
query:由特征选择模块从预测目标中挑选出的合适的特征组成。
特征选择模块
该模块的网络设计是:MSA+MLP+sigmoid。
然后根据模型输出概率从特征中采样特征。特别地,usr id是一定要采样的特征。因为要根据usr id特征从用户历史集合中选中该用户的历史行为序列。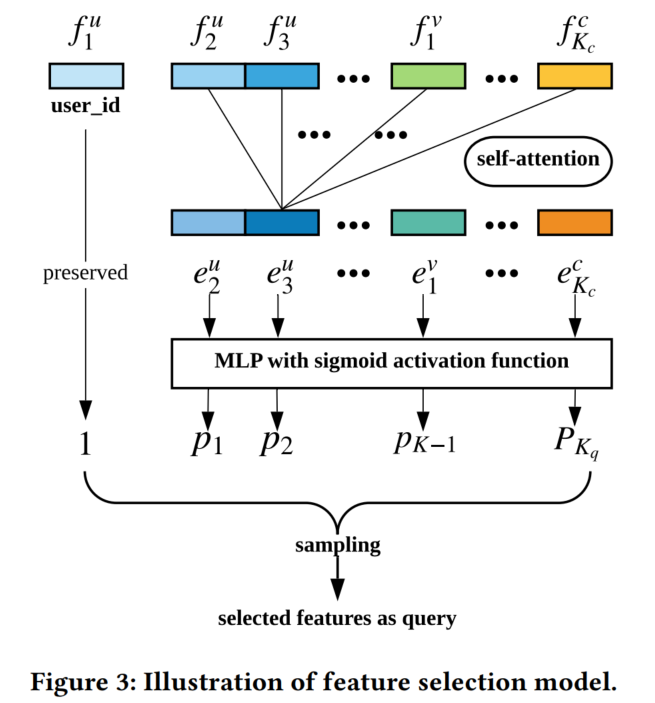
行为搜索
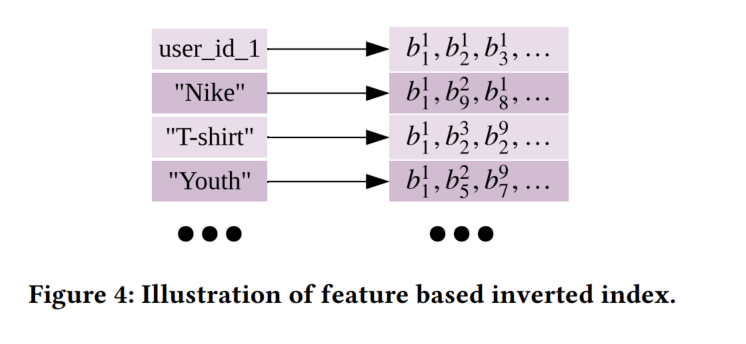
这里,将每个行为看做一个文档,每个特征看做文档中的一项。首先,使用inverted index的方式存储用户历史行为。具体地,如特征”NIKE”这一索引对应着包含有NIKE这一品牌的用户历史行为的列表
inverted index,可以翻译为转置索引,倒排索引。这里采用转置索引会更好记忆和理解一点,采用倒排索引的翻译容易使人混淆。一般数据库中文档的存储方式为,文档ID为索引,文档内容为记录。而转置索引是使用单词或者记录为索引,将文档ID为记录。这样能快速地通过单词或者记录查找到所在的文档。
那么行为检索,就是使用上一步获得的特征集合,利用每一个特征去索引用户行为,最终检索的用户行为如下所示: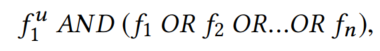
然后使用BM25算法对query和docment之间计算相似度,取Top S。
预测模块
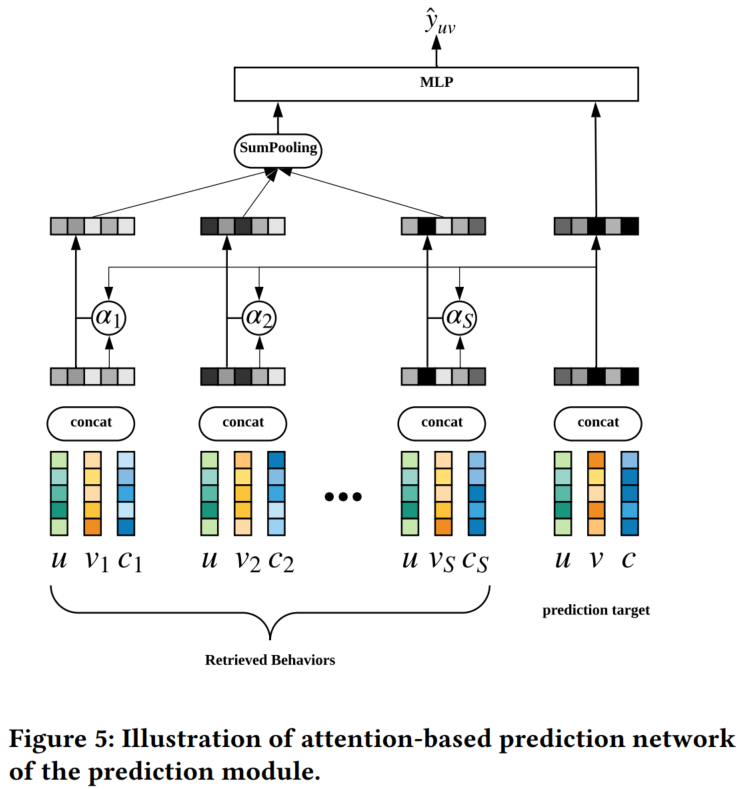
该模块的网络结构就是一个SA+MLP。

若有收获,就点个赞吧
0 人点赞
