一、编译器
1、编译器做了什么?
编译器有两个职责:把 Objective-C 代码转化成低级代码,以及对代码做分析,确保代码中没有任何明显的错误。
Xcode的默认编译器是clang,clang 的功能是首先对 Objective-C 代码做分析检查,然后将其转换为低级的类汇编代码:LLVM Intermediate Representation(LLVM 中间表达码)。接着 LLVM 会执行相关指令将 LLVM IR 编译成目标平台上的本地字节码,这个过程的完成方式可以是即时编译 (Just-in-time),或在编译的时候完成。
2、clang和LLVM
1)LLVM
LLVM项目是模块化、可重用的编译器以及工具链技术的集合。
LVVM架构
LVVM三层式架构(官方LLVM):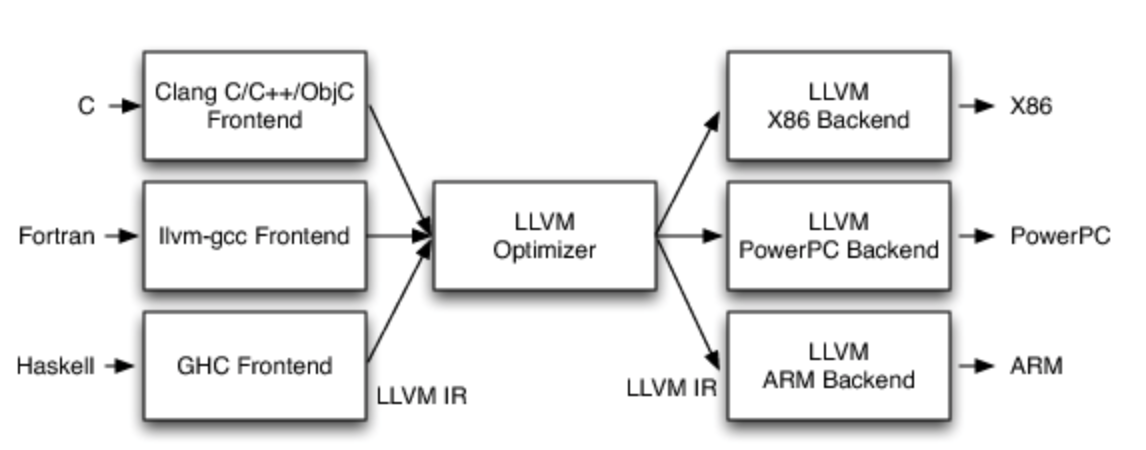
- 第一层支持多种语言作为输入
- 第二层是一个共享式的优化器
- 第三层是许多不同的目标平台
- 第一层和第二层使用相同的中间代码LLVM IR
优化阶段是一个通用的阶段,它针对的是统一的LLVM IR,不论是支持新的编程语言,还是支持新的硬件设备,都不需要对优化阶段做修改
2)clang
LLVM项目的一个子项目,基于LLVM架构的C/C++/Objective-C编译器前端。
clang的功能是首先对Objective-C代码进行分析检查,然后将其转换为低级的类汇编代码:LLVM 中加表达码
3) clang与LLVM的关系
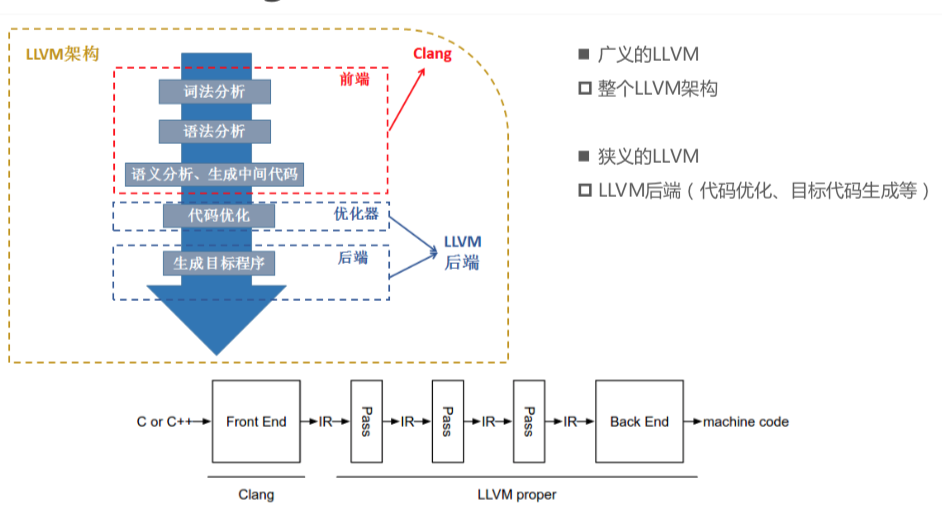
LLVM整体架构,前端用的是clang,广义的LLVM是指整个LLVM架构,一般狭义的LLVM指的是LLVM后端(包含代码优化和目标代码生成)。
源代码(c/c++)经过clang—> 中间代码(经过一系列的优化,优化用的是Pass) —> 机器码
3、编译器处理过程
1)预处理
每当编源译文件的时候,编译器首先做的是一些预处理工作。比如替换宏定义,类似代码#import <Foundation/Foundation.h> 预处理器对这行代码的处理是用 Foundation.h 文件中的内容去替换这行代码。如果Foundation.h 中也使用了类似的宏引入,则会按照同样的处理方式用各个宏对应的真正代码进行逐级替代。
自定义宏时,不要在需要预处理的代码中加入内联代码逻辑,典型的例子:
#import <Foundation/Foundation.h>#define MAX(a,b) a>b ? a : bint main(int argc, const char * argv[]) {@autoreleasepool {// insert code here...int i = 200;NSLog(@"%d",MAX(i++, 100)); // 输出 201NSLog(@"%d",i); // 输出 202}return 0;}
输出结果:201,202,原因是MAX(i++, 100)将转化为i++>100 ? i++ : 100
如果比较的值是300,则输出是 300,201
2) 词法分析标记
预处理完成以后,每一个 .m 源文件里都有一堆的声明和定义。这些代码文本都会从 string 转化成特殊的标记流。
示例代码:
int main() {NSLog(@"hello, %@", @"world");return 0;}
使用clang -Xclang -dump-tokens test.m进行标记之后输出如下代码
int 'int' [StartOfLine] Loc=<test.m:1:1>identifier 'main' [LeadingSpace] Loc=<test.m:1:5>l_paren '(' Loc=<test.m:1:9>r_paren ')' Loc=<test.m:1:10>l_brace '{' [LeadingSpace] Loc=<test.m:1:12>identifier 'NSLog' [StartOfLine] [LeadingSpace] Loc=<test.m:2:3>l_paren '(' Loc=<test.m:2:8>at '@' Loc=<test.m:2:9>string_literal '"hello, %@"' Loc=<test.m:2:10>comma ',' Loc=<test.m:2:21>at '@' [LeadingSpace] Loc=<test.m:2:23>string_literal '"world"' Loc=<test.m:2:24>r_paren ')' Loc=<test.m:2:31>semi ';' Loc=<test.m:2:32>return 'return' [StartOfLine] [LeadingSpace] Loc=<test.m:3:3>numeric_constant '0' [LeadingSpace] Loc=<test.m:3:10>semi ';' Loc=<test.m:3:11>r_brace '}' [StartOfLine] Loc=<test.m:4:1>eof '' Loc=<test.m:4:2>
可以发现,每一个标记都包含了对应的源码内容和其在源码中的位置。注意这里的位置是宏展开之前的位置,这样一来,如果编译过程中遇到什么问题,clang 能够在源码中指出出错的具体位置。
3)解析
之前生成的标记流将会被解析成一棵抽象语法树 (abstract syntax tree -- AST),在抽象语法树中的每个节点都标注了其对应源码中的位置,同样的,如果产生了什么问题,clang 可以定位到问题所在处的源码位置。
4)静态分析
一旦编译器把源码生成了抽象语法树,编译器可以对这棵树做分析处理,以找出代码中的错误。比如类型检查,检查是否有定义从未使用过的变量等,具体详见clang源码的目录lib/StaticAnalyzer/Checkers
5)代码生成和优化
clang 完成代码的标记,解析和分析后,接着就会生成 LLVM 代码。 clang 能对代码进行多方面的优化处理。
6)参考文献
[编译器]
[clang AST]
[clang编译器]
[LLVM]
二、Build过程
三、Mach-O可执行文件
我们用 Xcode 构建一个程序的过程中,会把源文件 (.m 和 .h) 文件转换为一个可执行文件。这个可执行文件中包含的字节码会将被 CPU (iOS 设备中的 ARM 处理器或 Mac 上的 Intel 处理器) 执行。这个可执行文件就是Mach-O可执行文件。
将.m和.h文件转化为Mach-O这个过程,编译器需要进行以下处理:
1、预处理
- 符号化 (Tokenization)
- 宏定义的展开
#include的展开
2、语法和语义分析
- 将符号化后的内容转化为一棵解析树 (parse tree)
- 解析树做语义分析
- 输出一棵抽象语法树(Abstract Syntax Tree* (AST))
3、生成代码和优化
- 将 AST 转换为更低级的中间码 (LLVM IR)
- 对生成的中间码做优化
- 生成特定目标代码
- 输出汇编代码
4、汇编器
- 将汇编代码转换为目标对象文件。
5、链接器
- 将多个目标对象文件合并为一个可执行文件 (或者一个动态库)
Mach-O可执行文件的结构:
- Header——描述了文件的大概信息
- Load Commands——描述了 Data 在二进制文件和虚拟内存中的布局信息
- Data —-存储了实际的内容,主要是程序的指令和数据,它们的排布完全依照 Load Commands 的描述。
常用命令集:
- help —-列举所有命令
- print —-打印值
- p
- prin
- pri
- expression —-改变调试器中的值
- e
- continue —- process continue
- c

若有收获,就点个赞吧
0 人点赞
