2.4&2.5 逻辑回归&特征交叉
逻辑回归无法进行自动特征交叉,一般可以通过手动组合,设计出交叉特征,再进行筛选。但是手动进行特征交叉效率低,并且人类经验具有局限性。POLY2/FM/FFM的设计主要利用模型来自动进行特征交叉,但一般也仅限于低阶(二阶)交叉,高阶交叉的组合数太多,过于复杂。
逻辑回归
主要思想
相比协同过滤和矩阵分解,逻辑回归可以综合利用物品/用户/上下文等特征。之前提到的两种思想主要是计算“相似度”,而逻辑回归可以把推荐看成一个分类问题,通过预测正样本的概率来排序,也就是转换为ctr预估的问题。一般将曝光未点击作为负样本,点击的作为正样本。
缺点
逻辑回归虽然弥补了无法融入相关特征的缺点,但是无法进行特征交叉,也就导致信息量损失,模型表达能力受限
POLY2
主要思想:
POLY2模型实现了对所有特征进行两两交叉,除了特征的交叉,模型和逻辑回归一样还是线性模型,训练方式也和逻辑回归一样。
POLY2的二阶部分如下,相比逻辑回归,新增了n(n-1)/2 个交叉特征项,模型要学习的参数也相应增加了这么多,计算复杂度O(n2)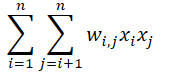
缺点:
- 特征中许多类别型特征要经过one-hot,转换后的向量很稀疏,POLY2在交叉特征时会有很多交叉项为0,也就是说对应交叉项的权重没有有效数据来训练更新
- 权重的参数量从n增长到n的平方项。
FM
主要思想:
与POLY2相比,FM主要用向量内积代替了单一系数,FM为每一个特征学习了一个隐向量(latent vector),在特征交叉时使用两个特征对应的隐向量内积作为该交叉项的权重系数。FM的二阶部分如下,只不过交叉项前的系数并不是相互独立的标量,而是特征对应的隐向量,从下面的公式可以看出,FM二阶部分的参数量只有n*k(k是超参),小于POLY2的n(n-1)/2(一般k远小于n),可以看出计算复杂度为O(kn)(原本特征交叉的复杂度为O(n),每次交叉在计算隐向量内积的复杂度为O(k)),通过化简可以达到O(kn)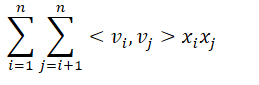
FM与POLY2对比:
隐向量的可以很好地解决数据稀疏的问题,在POLY2中需要两个特征同时出现,该交叉项才能学到这个组合的权重,而FM中通过隐向量能计算未出现过的组合特征权重,隐向量可以通过样本中的其他组合进行更新。
FFM
主要思想:
FFM引入了特征域感知(field-aware)的概念,FFM二阶部分和FM类似,只是将每个特征的隐向量由一个扩展到F个,F是特征域的个数。假设特征有性别/城市/年龄… 这里的性别可以编码为[0,1]或[1,0],这样的向量就可以作为一个特征域。在FM中,性别特征在于城市/年龄做交叉的时候使用的隐向量v是同一个,而FFM中则分别使用VV因此FFM在训练时,需要学习的参数量为:nkf (n-特征维数,k-隐向量维数,f-特征域个数)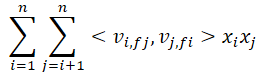
FFM需要为每个特征分配一个特征域
离散型特征 categorical :通常对离散型特征进行 one-hot 编码,编码后的所有二元特征都属于同一个 field
数值型特征 numuerical :a.可以不做任何处理,将一个特征作为一个域,如果全是数值型此时就退化为FM;b.先离散化,此时增加超参bucket的个数要调
与FM的对比:
相比较FM,FFM特征域的概念使得隐向量带了更多信息,但是计算复杂度上升了,FFM二阶部分无法像FM可以经过化简,所以还是O(kn),需要在模型效果和工程复杂度之间trade-off
_

若有收获,就点个赞吧
0 人点赞
