2.6 GBDT+LR
主要思想:
FM/FFM只能做二阶交叉,Facebook提出一种GDBT+LR的结构,利用GBDT在自动进行特征筛选和组合,生成新的离散特征向量,再把该向量作为LR模型的输入,来进行ctr的预估。
特征构造:
这里GBDT和LR是分开训练的。一个训练样本在进入一颗树后,最终会落到一个叶子节点,把该叶子置1,其余叶子置0,这样所有叶子组成的向量构成该样本新的离散特征,将GBDT所有子树的特征向量连接为一个特征向量。决策树的深度决定了特征交叉的阶数。
GDBT+LR的优势:
特征工程模型化,在这之前主要解决方法:a.人工组合筛选 b.改进模型结构,增加交叉项。GBDT使得投入在特征工程上的人力减少,实现的是端到端的训练(end to end)
2.7 LS-PLM (又被成为MLR)-大规模分段线性模型(混合逻辑回归)
主要思想:
对样本进行聚类,再对每个分类进行逻辑回归ctr预估,数学形式如下。m为超参,表示分片数量,m=1表示样本不分类,也就退化为LR。当m越大,模型拟合能力越强。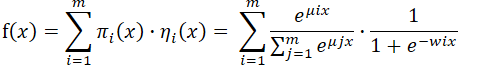
LS-PLM优点:
- 端到端的非线性学习能力,能够拟合非线性的分类面,同时省略了大量人工特征工程的过程。
- 模型的稀疏性强:建模时引入了L1和L2,1范数,可以使模型具有较高的稀疏度
从深度视角看LS-PLM:
LS-PLM可以看成一个加入了attention机制的3层神经网络,m个分片可以看做m个神经元的隐藏层,隐层和输出之间的权重可以看做注意力得分。

若有收获,就点个赞吧
0 人点赞
