Spark MLlib
spark分布式计算原理
spark在具体执行程序时,会把程序拆解成一个DAG,进一步的,可并行的部分被分割进Stage,stage的边界处进行消耗资源的shuffle或者最终的reduce操作。
sparkMLlib的模型并行训练原理
- 将当前模型参数广播到各个数据partition
- 各个计算节点进行数据采样,得到minibatch的数据,分别计算梯度
- 通过汇总梯度,得到最终梯度
- 利用汇总的梯度,更新权重
对应到spark并行计算的过程,每次迭代,stage的内部并行的部分是各个节点数据采样和计算梯度,stage的边界是汇总各个节点的梯度。spark并行训练过程是“数据并行”,不涉及“参数并行”。
sparkMLlib并行训练的局限性
- 在每轮迭代前进行全局广播,广播消耗带宽资源,当参数量比较大的时候,广播过程在每个节点要维护一个参数副本都是非常消耗资源的;
- 阻断式的梯度下降方式,每轮梯度下降由最慢的节点决定。每次迭代要等待每个节点生成梯度再进行reduce,如果出现数据倾斜,某个节点等待时间过长,那么就会阻断其他节点,导致效率低下;
- 不支持复杂深度学习网络结构和大量可调超参,这一点从以上两点也可以推断出。
Parameter Server
系统架构
parameter server采取了和spark mllib一样的数据并行训练产生局部梯度,再汇总梯度更新权重的并行化训练方案。Parameter Server主要有server和worker节点组成:
- server节点保存模型参数,接收worker节点计算出的局部梯度,汇总计算全局梯度并更新模型参数
- worker节点保存部分训练数据,从server拉取模型参数,计算局部梯度,上传给server
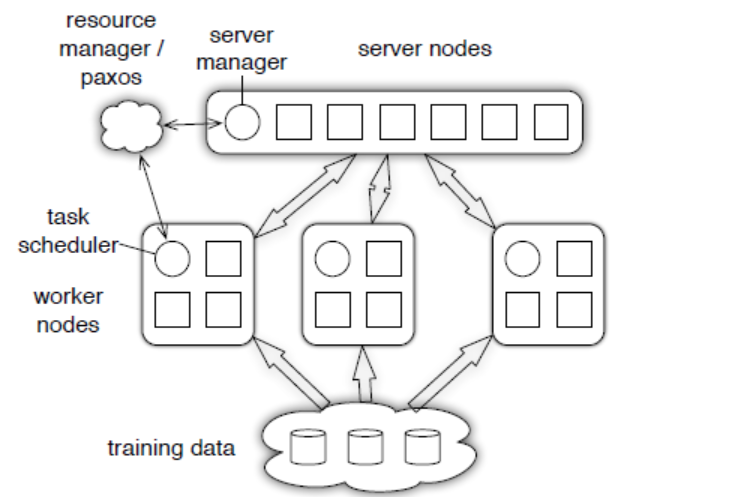
服务器节点组内包含多个server,每个服务器负责维护一部分参数;每个工作节点组对应一个训练任务,worker之间不通信,worker只与server通信。
parameter的分布式训练流程
- 每个worker载入一部分训练数据
- worker从server拉取最新的模型参数
- worker节点利用本节点数据计算局部梯度
- worker几点将计算好的梯度push到server节点
- server节点汇总梯度更新模型
- 跳转到第二步进行迭代,直至模型收敛或者达到迭代次数上限
一致性与并行效率的取舍
spark mllib同步阻断式的并行梯度下降是“一致性”最强的梯度下降方法,与串行计算的结果完全一致;
parameter server用“异步非阻断式”代替“同步阻断式”,比如下图中iter10还没有完成push和pull,iter11就开始计算了,也就还用的iter10的参数,这样就是异步非阻断的,节点间不相互影响都在并行工作,不会被一个节点的delay所阻断。但是这样会导致模型一致性的损失,和原来单点串行的结果不一致,会对模型收敛速度有影响。
考虑到模型一致性的损失,parameter server提供了任务依赖方式的选择,这相当与一个超参数,是一致性与并行效率之间的取舍。
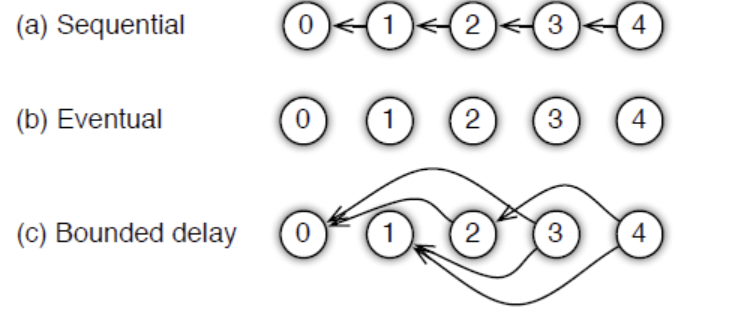
- sequential:所有task一个接一个的执行,这个和单线程实现对等;
- eventual:与1正好相反,完全并行;
- bounded delay:设置一个最大延时时间,当前worker在这个最大延迟时间内参数必须更新一次,否则就停下来等待pull最新参数
TensorFlow
Tensorflow技术要点
- 主要原理是将模型训练过程转换成任务关系图;
- 基于任务关系图进行任务调度和并行计算;
- 对与分布式的tensorflow来说,并行训练分两层,一层是基于parameter server架构的数据并行训练过程,另一层是每个worker节点内部,cpu+gpu任务级别的并行计算过程。
深度推荐模型的线上部署
预存推荐结果/embedding结果
在离线环境下生成每个用户的推荐结果,将结果存在redis等线上数据库,线上直接取结果返回给用户。该方式的优缺点:
优点:a. 线上线下解耦 b.线上延迟低
缺点:a. 数据量太大,线上数据库难以支持 b. 无法引入场景类特征
直接存用户和物品的embedding是另一种以存代算的方式,相比直接存推荐结构,存embedding数据量减少了不少,线上直接做相似度计算就可以得到推荐结果,但是同样无法引入场景特征,无法进行复杂模型的线上推断。
自研模型线上服务平台
预训练embedding+轻量级线上模型
双塔模型:分别用复杂网络对“用户特征”和“物品特征”进行embedding化,在最后的交叉层之前,用户侧和物品侧没有交互。完成双塔模型的训练后,可以最终把用户embedding和物品embedding存下,在新型线上推断时,实现最后一层的逻辑回归或者softmax,在最后一层的计算上可以加入场景特征。
利用PMML转换并部署模型
-脱离平台的通用模型部署方式
它用统一的XML格式来描述我们生成的机器学习模型。这样无论模型是sklearn还是Spark MLlib生成的,我们都可以将其转化为标准的XML格式来存储。模型用于部署的时候,可以使用目标环境的解析PMML模型的库来加载模型,并做预测。
可以看出,要使用PMML,需要两步的工作,第一块是将离线训练得到的模型转化为PMML模型文件,第二块是将PMML模型文件载入在线预测环境,进行预测。这两块都需要相关的库支持。
Tensorflow Serving
本质上和PMML工具的流程一致,只不过tensorflow定义了自己的模型序列化标准。要搭建一套tensorflow serving环境其中涉及模型更新、docker container集群的维护和扩展等一系列工程问题。

若有收获,就点个赞吧
0 人点赞
