Word2vec
Embedding
Embedding技术在深度学习推荐系统中的作用
类别,id类特征进行one-hot编码,导致样本特征向量维度高并且非常稀疏,在深度学习中使用这种特征会导致参数过多,难以收敛,而embedding技术可以对这类特征进行降维,转换成低维稠密向量;
Embedding本身就是重要的特征向量,包含大量有价值的信息;
Embedding对物品、用户相似度的计算是推荐系统常用的召回技术。
什么是Word2vec?
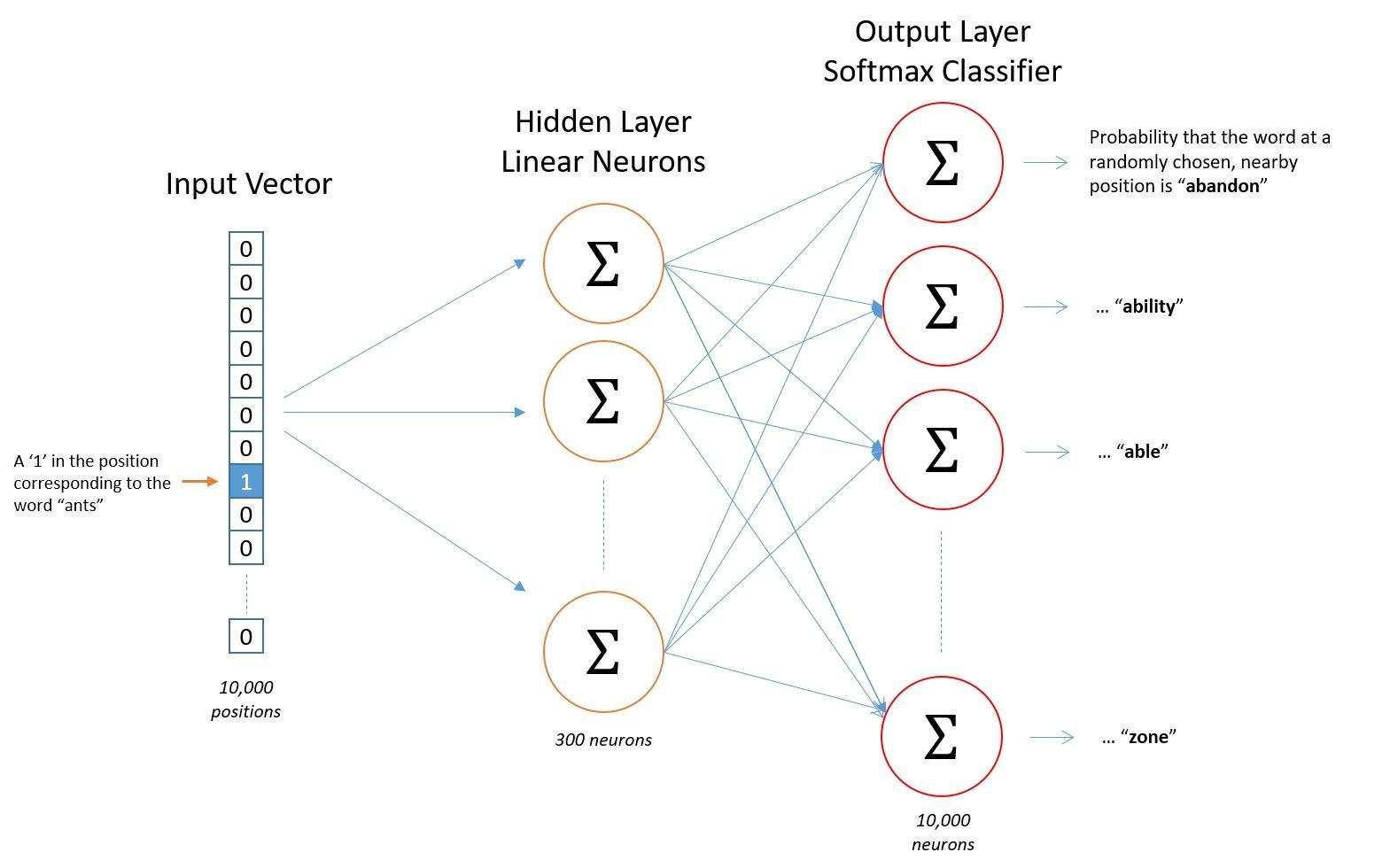
Word2vec模型(以skip-gram为例)
- 训练样本的构造
首先有一个多个句子组合成的语料库,选取一个2c+1长度的窗口,窗口内的中心词为输入,相邻的背景词为输出,一个包含2c+1个词汇的窗口内可构造2c对样本。例如:“今天,的,天气,很,好”这个窗口内有5个词,那么中心词就是“天气”,构造的样本包含以下4对-(天气,的)/(天气,很)/(天气,今天)/(天气,好)
- 优化目标
模型的目标是希望给出“天气”,能够预测(今天,的,很,好)这几个词,假设这些词的出现是相互独立的,那么相当于要让条件概率P(今天|天气)P(的|天气)P(很|天气)P(好|天气)尽可能大,也就是极大似然估计。数学表示如下,取log是为了使数值变大但是不改表本身的单调性: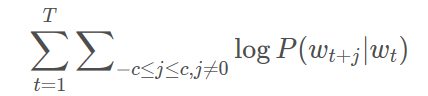
如何定义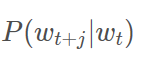 ?
?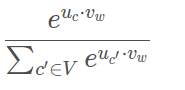 ,w表示中心词,c表示上下文(背景词),c’表示词库中的所有词。这里vw其实就是中心词的向量表达,由于输入是one-hot编码的,所以对应的向量表达就是输入层“1”的单元到隐藏层的参数向量,是输入向量;uc是输出词的向量表达,也就是隐藏层到输出层对应单元的参数向量,这两个向量表达的内积就是输出层对应单元的值,经过softmax函数表示输出是词汇表某个词的概率。将softmax函数带入到上面的条件概率表示的优化目标,可以得到:
,w表示中心词,c表示上下文(背景词),c’表示词库中的所有词。这里vw其实就是中心词的向量表达,由于输入是one-hot编码的,所以对应的向量表达就是输入层“1”的单元到隐藏层的参数向量,是输入向量;uc是输出词的向量表达,也就是隐藏层到输出层对应单元的参数向量,这两个向量表达的内积就是输出层对应单元的值,经过softmax函数表示输出是词汇表某个词的概率。将softmax函数带入到上面的条件概率表示的优化目标,可以得到: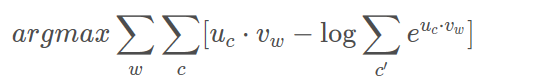
但是每次损失中的第二项计算开销太大,针对这一问题,可以对样本做负采样,将多分类转换为二分类问题,假设隐藏层有300个神经元,输出层10000个神经元,在多分类情况下一次要更新30010000个参数,但是采用负采样之后(假设一个正样本对应采5个负样本)一次只需要更新3006个参数。
- 模型结构
Item2vec
基本原理
- word2vec是对词序列中的词进行embedding,那么用户历史行为序列中的序列item也可以进行embedding。
- 在之前提到的推荐算法例如MF、FM/FFM中,针对用户和物品都生成了隐向量,这个隐向量就可以看做是embedding。
- item2vec的基本原理与word2vec基本相似,区别在于,item2vec中没有提到时间窗口的概念,如果认为item之间有时序关系,则可以按照word2vec的形式来构造样本和训练;如果认为历史行为中的item时序特性较弱,则可以把这些item看成一个集合,那么认为两两物品都是相关的
广义Item2vec
广义上讲,任何能够生成item向量表示的方法都可以称为Item2vec,例如上面提到的FM等,还有双塔模型,其中物品塔就是将物品侧的相关特征经过多层神经网络的变换,最终得到一个表示item的稠密向量。局限性
只能利用序列性数据

若有收获,就点个赞吧
0 人点赞
