离线评估方法与基本评估指标
离线评估的主要方法
- holdout检验
举个例子:70%用于训练,30%用于验证
缺点:划分具有随机性,导致结论具有随机性,为了消除这种随机性,可以采用交叉验证
- 交叉验证
k-fold交叉验证:所有样本划分为k个大小相等的样本子集,依次其中的一个作为验证集,剩下的子集作为训练集,可以得到k次评估结果,取均值作为最终的评估指标。
留一验证:每次只留下一个样本作为验证集,样本总数n就需要验证n次,当n很大验证的时间开销也比较大。
- 自助法
方法1和方法2都需要对总体数据进行划分,如果数据集比较小,划分后的训练集会更小。这是可以采用自助法(Bootstrap):进行n次有放回的最忌抽样,得到大小为n的训练集,n次采样均没被采样到的作为验证集。
离线评估指标
- 准确率 ACC :Accuracy
分子是被正确分类的样本数,分母是样本总数,即总体样本中能被正确分类的比例,就是准确率。
Acc = (TP+TN)/(TP+FN+FP+TN)
适用场景:正负样本比例接近,如果正负比例极不均匀,假设负样本有90个,正样本有10个,如果将所有样本都预测为负样本,那么混淆矩阵如下图,此时Acc = 90/(10+90)*100% = 90%,显然从这个结果来评价分类器的好坏是极不可靠的。
- 精确率与召回率
在排序模型中,通常采用TopN的结果的精确率和召回率来评估模型性能。
- 精确率:Precision = TP/(TP+FP) -在被预测为正例的样本中,是真正的正例的比例。分母是预测为正例的个数。
- 召回率:Recall = TP/(TP+FN) - 真实正例中被召回(正确预测)的比例。分母是真实正例的个数。
- 调和均值:F-score
已知ACC在正负样本分布不均的情况下不适合用来评估模型的好坏,有时精度和召回率无法同时满足,一个高另一个就低,此时需要总和考虑这两个指标,那么久可以使用两者的调和值(几何均值/算数均值)。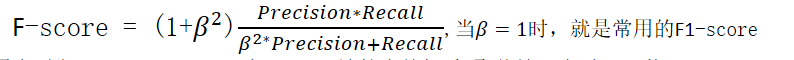
用来平衡Precision,Recall在F-score计算中的权重,取值情况有以下三种:
如果取1,表示Precision与Recall一样重要
如果取小于1,表示Precision比Recall重要
如果取大于1,表示Recall比Precision重要
- 均方根误差RMSE
observed是样本的真实标签,predicted是预测值,n是样本个数。一般情况下,RMSE能很好地反应预测与真实的偏离程度,但是存在偏离程度比较大的离群点的时候,指标会变得比较差。这个时候可以采用MAPE,看公式可以认为是把每个点的误差做了归一化。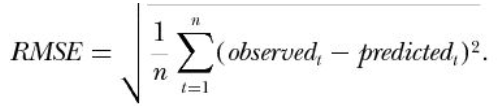

- 对数损失函数Logloss
Logloss是非常适合观察模型收敛情况的评估指标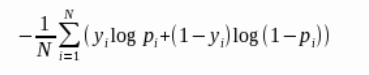

若有收获,就点个赞吧
0 人点赞
