Airbnb 基于embedding的实时搜索推荐系统
利用了embedding的两个优势:1. 能够将稀疏特征转换为稠密向量,便于输入深度学习网络;2. 将物品语义进行特征编码,便于直接计算相似度进行搜索
应用场景
用户在airbnb上存在的交互方式:
a. 用户点击click
b. 用户立即预定
c. 用户发出预定请求,房主可能拒绝/同意/不响应
短期兴趣的房源embedding
在用户的一次搜索中 利用session内的点击序列作为用户的“短期兴趣”,序列要满足的条件如下,这里两个条件可以减少噪声,避免非相关序列的产生:
- 在详情页停留大于30
- 如果超过30min没有动作,就放弃该序列
与word2vec优化目标上不同的地方?
- 在session内产生序列后,可以把序列作为一个“句子”,利用word2vec的方法训练出房源的embedding向量。在原始word2vec embedding的基础上,针对业务特点,序列被分为预定会话和探索性会话,预定会话是指最终产生预定行为的预定会话。为了将预定行为加入目标,airbnb的做法是不管这个预定行为在不在窗口中,都假设这个房源与中心房源相关;
- 为了更好得发现同一市场内部房源的差异性,Airbnb计入了另一组负样本,就是在同一市场的房源内进行抽样,加入的形式与之前的负样本一致。
Airbnb在改造目标函数时引入了与业务强相关的目标项,在处理数据稀疏的问题上也是非常具有实践价值的方法。
长期兴趣用户embedding和房源embedding
为了捕捉用户长期偏好,Airbnb采用了预定序列,但是预定行为比点击要稀疏很多,单一用户的预定行为很少(序列长度为1),为了解决数据稀疏的问题,Airbnb基于规则与用户和房源做聚合,用属性组合替换原来的userid和房源,一个userid的预定行为很少,但是某一属性的user的预定行为可以聚合起来,在训练的时候把用户属性和房源属性当做相同的词去训练embedding。但是这个序列按什么规则生成的?
搜索词的embedding
airbnb对搜索词query进行了embedding,把搜索词和房源放在同一向量空间进行训练,发现引入embedding之后,搜索结果甚至可以捕捉到语义信息,更接近用户动机。
Airbnb的实时搜索排序模型和特征工程
基于上述的各种mebedding构造了不同的相关特征,比如EmbClickSim-“候选房源与最近点击过的房源的相似度”,得到这些特征后会将embedding类特征与其他特征一起输入模型,这里Airbnb用的是只是Pairwise Lambda Rank的GBDT模型,这是什么模型。。
YouTube深度学习视频推荐系统
应用场景
特点 1. 商业模式不同,Netfilx等流媒体大部分内容是采购或者自制的影视剧作品等头部内容,但是YouTube的头部效应不明显; 2. 视频内容基数大,用户比较难发现喜欢的内容。
YouTube推荐系统架构
采用两级深度学习模型完成推荐过程:1. 候选集生成模型(召回); 2. 排序模型
候选集生成模型
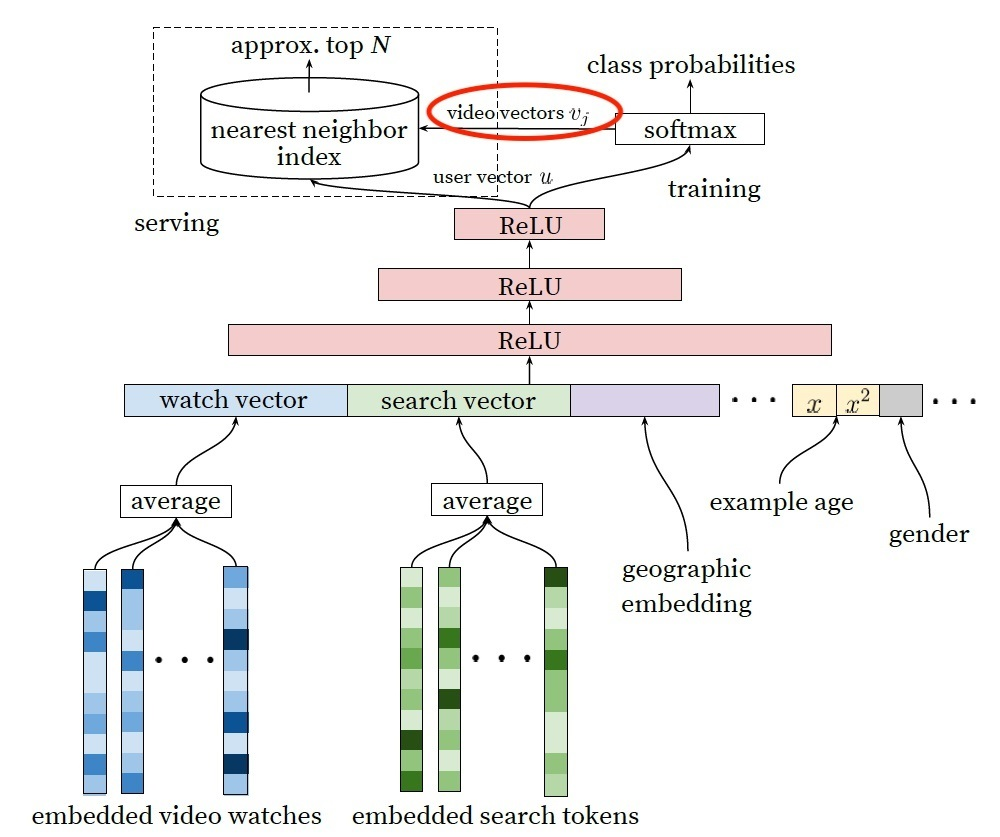
该模型的输入是用户历史观看视频的embedding、搜索词的embedding等其他特征,视频和搜索词embedding可以通过Airbnb的方法训练得到。youtube把候选集生成这一问题看做用户推荐下一模型的概率分布,模型的最终输出是一个在所有候选视频上的概率分布(多分类,最后一层是softmax),是一个标准的利用embedding预训练特征的深度神经网络。
候选集模型在每次请求的时候都推断一次的开销很大,因此把用户向量和视频向量存储到redis,线上模型服务通过mebedding最邻近搜索的方法进行,这样会提高效率。模型结构图中把最后一次的relu输出指向了用户向量,softmax指向了视频向量,这样是为什么/经过该网络生成的视频向量和输入时的embedding向量有什么区别?
排序模型
排序模型的结构和候选集模型结构没什么区别,但是输入和输出变了,排序时的特征更多,输出层的激活函数采用了加权逻辑回归,这里的权重就是正样本的观看时长
训练样本和测试样本的处理
处理样本的工程措施:
- 负采样,减少每次预测的分类数量,加快收敛
- 每个用户提取等量日志,减少高活跃度用户对模型的影响(但是这个等量的量如何确定?
- 用最近一次的观看行为做测试集,避免引入未来数据
处理用户对新视频的偏好
在youtube用户对新视频的偏好明显,对大多数视频来说,刚上线的那段时间是其流量高峰。为了拟合用户对新内容的偏好,引入了Example age这个特征,该特征的定义是训练样本产生的时间距离当前时刻的时间。产生的时间具体是指什么,产生时间和上线时间有什么区别?
阿里巴巴深度学习推荐系统的进化
应用场景
主要功能就是根据用户的历史行为、输入的搜索词及其他商品和用户信息,为用户推荐感兴趣的商品,用户行为一般包含以下阶段:登录->搜索->浏览->点击->加购->支付->购买成功
阿里巴巴推荐模型的进化过程
- 基础深度学习模型:embedding+mlp架构,用户历史行为的embedding简单通过加和池化做叠加,再与其他特征concat之后输入上层神经网络
- DIN模型:利用注意力机制替换原来的sum pooling,为历史行为进行加权后再sum pooling
- DIEN模型:用序列模型在用户行为历史上抽取用户兴趣比模拟用户兴趣的演化过程
- MIMN模型:在DIEN的基础上,把用户兴趣分为不同的兴趣通道

若有收获,就点个赞吧
0 人点赞
