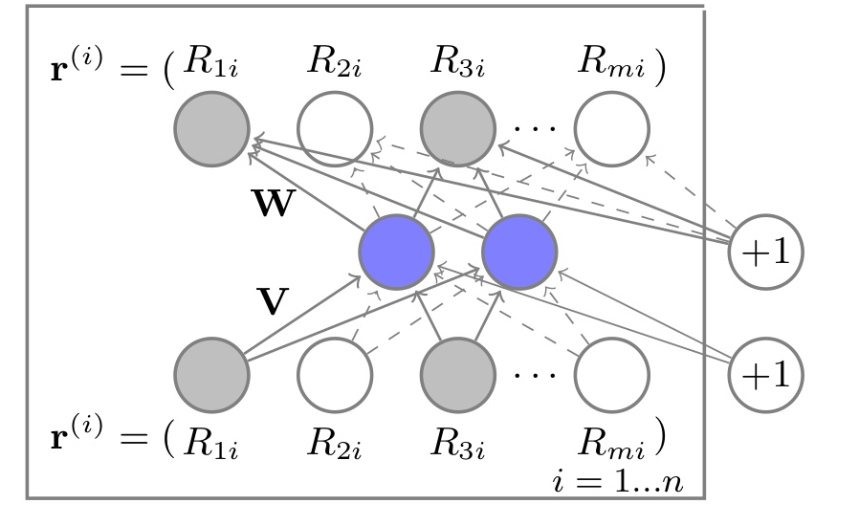
AutoRec-单隐层神经网络
模型结构
优化目标: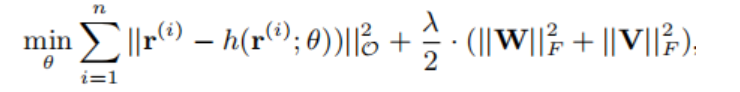
从网络结构和优化目标可以看出,这个模型比较小,参数量也不是很大。
- 该模型可以认为是最原始的深度学习模型,只有一层隐藏层。
- AutoRec是一个自编码器,自编码器:向量r输入通过自编码器后输出r’ 要尽量与输入相近 -> r维降到k维。
- 这里和Word2Vec相似,但是优化目标不一样,使用的方式也不一样。Word2Vec使用的是隐层权重矩阵作为一个查找表,lookup table的一行权重就是一个词的embedding向量;但是这里并不是一个物品/用户对应一个向量,而是用训练好的网络参数来预测输出向量。
- AutoRec在和协同过滤的思想有共通之处,都可以分为基于用户/基于物品两种方式,基于物品的I-AutoRec:
输入有现有用户对物品i的评分向量r输出是所有用户对物品i的评分预测,若用户u未对物品i有过反馈,则输出向量的第u维就是u对i的预测。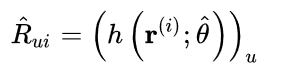
- 如果用I-AutoRec,那么一个用户对所有物品的预测评分要将所有物品的评分向量作为输入进行推断,但是如果用U-AutoRec,要预测u对所有物品的评分只需要将u对物品的评分向量输入,进行一次推断即可。
I-AutoRec & U-AutoRec
推荐列表的生成,预测用户u,I-AutoRec 要进行n(物品的数量)次推断,但是U-AutoRec只需要推断一次;
但是用户向量的稀疏性可能会影响模型效果(一般用户数>>物品数);
相比协同过滤的两两计算相似度,AutoRec使用了全局的评分信息,泛化能力更好。缺陷
结构简单,只利用了共现矩阵的信息,不能加入用户/物品/上下文信息,也无法实现特征之间的交叉。Deep Crossing
模型结构
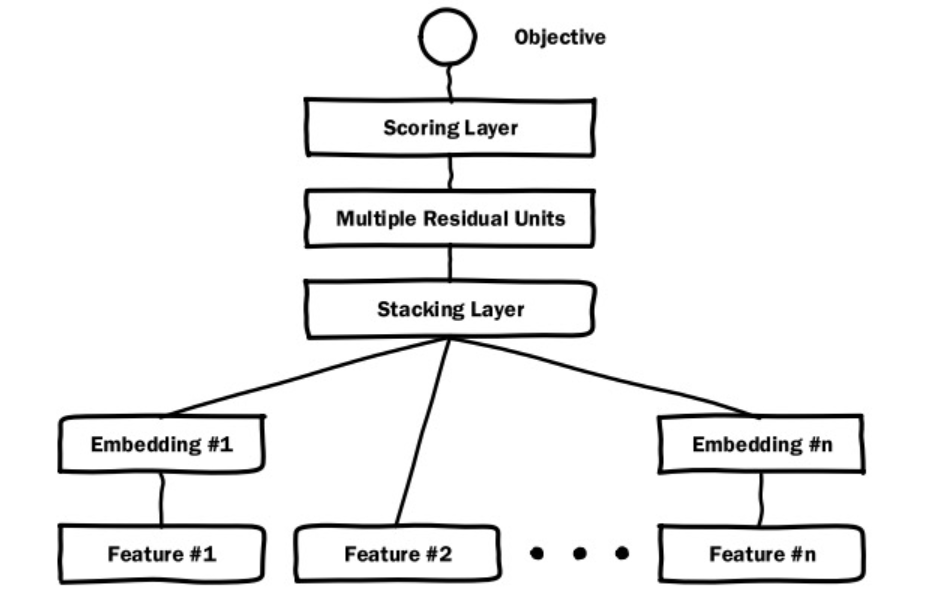
优化目标可以是logloss也可以进行自定义: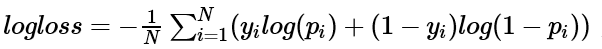
输入特征
2016年由微软提出,优化目标就是准确地预测广告点击率。针对该场景,特征可以分为3类:
- 类别型(可处理成one-hot/multi-hot)
- 数值型
- 需要进一步处理的特征
这些特征都不是独立特征,而是特征组别,这些特征最终需要转换为一个特征向量,作为end-to-end训练的输入。
- 上图中feature#1 表示稀疏(经过one-hot编码)的类别特征,经过embedding层后转换成对应的embedding#1;
- feature#2 表示数值型,可以看出数值型特征不需要经过embedding层;
- Stacking layer 把多个embedding向量和数值型特征进行拼接,一般也称为 concatenate;
- Multiple Residual Units 层就是MLP,只不过这里采用了多层残差网络,残差网络可以对特征向量进行充分交叉组合,下图为残差单元:
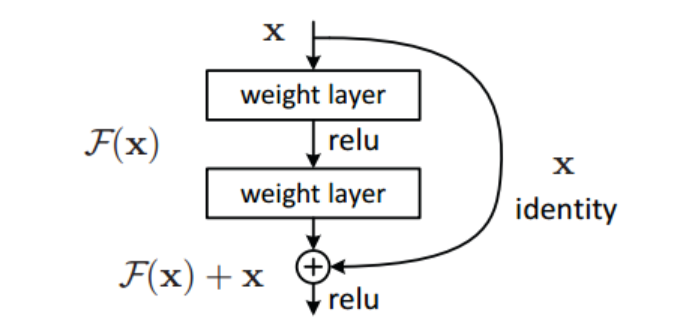
为什么用这种结构?Resnet的出发点是解决网络退化的问题(模型越深表现反而变差,训练和测试loss变高),通过跳层连接,让深层网络学习浅层的一个恒等映射,具体分析需要再参考其他资料,待补充。
- scoring层,对于ctr预估这种二分类一般为逻辑回归

若有收获,就点个赞吧
0 人点赞
