本书第二章主要介绍深度学习广泛用于推荐系统之前一些主流模型的发展。
2.1 演化关系
2.2 协同过滤(Collaborative Filtering)
共现矩阵:将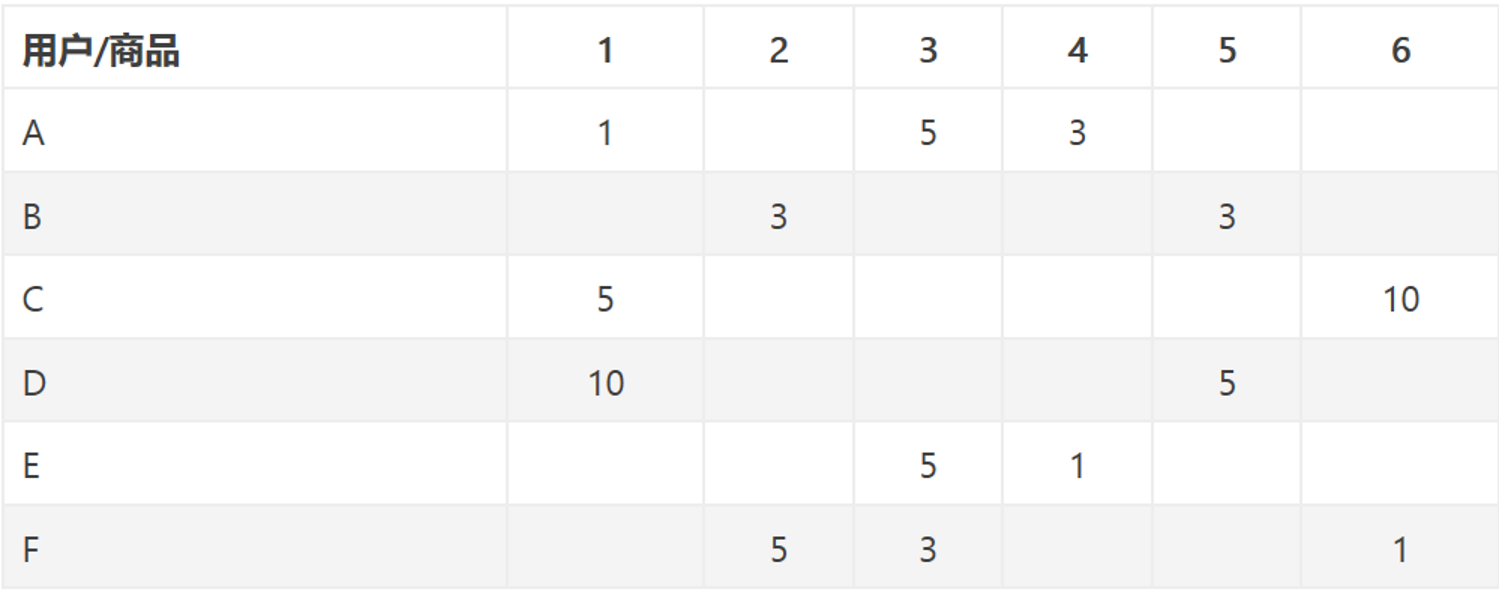
基于用户相似度的协同过滤( UserCF)
- 相似度的计算,相似度计算有很多方式比如余弦相似度,两个用户相似度就是共现矩阵中两个行向量的内积,利用共现矩阵计算相似度矩阵:
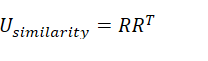
- 得到相似度矩阵就可以得到最终的评分矩阵:
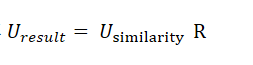
基于物品相似度的协同过滤(ItemCF)
相似度的计算同用户相似度矩阵,只不过两个物品的相似度是两个列向量的内积,利用共现矩阵计算相似度矩阵:
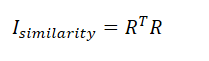
评分矩阵的计算也和UserCF相同:
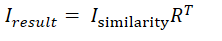
UserCF 、ItemCF对比
- 两种协同过滤分别要维护一个用户相似度/物品相似度矩阵,UserCF在m>>n时(用户数量远大于物品),用户相似度矩阵存储开销高,当n>>m也是同样的道理;
- 大多数用户的行为比较少,矩阵稀疏,即使可以计算相似度,找到相似用户的准确性还是比较低。但是在社交性质强、物品更新快的场景,例如新闻,由于物品更新速度快,物品相似度矩阵需要及时更新,开销就会更大,而UserCF可以根据相似用户发现兴趣偏好,追踪热点;
ItemCF适合用户兴趣相对稳定的场景,比如视频/电商,存在的问题是:物品的相似度是根据用户行为计算出的,如果一个商品很流行,大多数用户都对他有过反馈,那很容易与其他商品产生相似,那么这种相似就缺乏了“证据”,很可能推荐了一个很流行但是与用户兴趣不相关的商品,文中把这个现象称为“头部效应”。
缺点
协同过滤处理稀疏矩阵能力不足,在矩阵稀疏的情况下,相似度的计算缺乏有效数据,并且只局限于计算两两之间的相似度,泛化能力不足。
2.3 矩阵分解算法
主要思想
为用户和物品分别生成隐向量,将用户和物品映射到隐向量空间,通过计算隐向量之间的距离来判断相似度。矩阵分解,矩阵指的是共现矩阵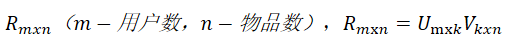 ,通过分解生成用户矩阵U和物品矩阵V,k是超参,k取值越大则隐向量包含的信息越多。在分解完成后,通过用户的隐向量与候选物品隐向量做内积,就可以得到对候选物品的预测评分,最终根据该预测分进行排序。
,通过分解生成用户矩阵U和物品矩阵V,k是超参,k取值越大则隐向量包含的信息越多。在分解完成后,通过用户的隐向量与候选物品隐向量做内积,就可以得到对候选物品的预测评分,最终根据该预测分进行排序。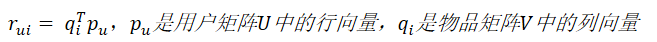
矩阵分解的求解
梯度下降,目标函数定义为真实评分和预测评分的平方损失。
为什么不使用奇异值分解?
1) 奇异值分解要求原始共现矩阵稠密,互联网场景下的稀疏矩阵不满足这一前提;
2) 互联网数据量大,计算复杂度太高。
矩阵分解与协同过滤的对比
协同过滤中由于矩阵的稀疏性质,在计算相似度时很容易得不到有效值(比如两个用户没有相同历史行为、两个商品没有同时被用户购买),只能通过有相似性的用户/物品进行推荐,可利用的信息局限于
缺点
虽然矩阵分解用隐向量来表达用户/物品信息,但和协同过滤一样,无法加入物品/用户/上下文等特征。

若有收获,就点个赞吧
0 人点赞
