05-07 面试对于项目部分从哪些方面去阐述比较好?阐述内容的度怎么把控(是详细?还是简单几句?或者其他)?
项目方面,主要是架构清晰,模块化归类阐述,突出重点,自己负责哪个模块,实现了哪些功能,遇到了哪些问题,自己是怎么解决的,对于内容,亮点,能突出自己的点儿,放大来讲,自己不太熟悉的领域,一句话带过,不会的不要给自己挖坑。
重点能够突出自己的解决问题能力,自己的灵活思维能力,以及对于面试官问的问题要get到他想要的点在哪里。
05-09 作为”程序搬砖人”,你有哪些好的行为习惯?
来自公众号: 程序员库森 《一个优秀的计算机系学生应该有哪些好习惯?》
1、学会使用Google搜索,放弃百度,你会发现Google会搜出更多有用的答案,而百度只能搜出csdn之类的网站!
可以使用Chrome浏览器的谷歌上网助手插件实现Google搜索。
2、读经典书籍,尤其是大黑书系列,如《深入理解计算机系统》、《算法导论》。你会发现那些21天学会XX,一周速成都是什么破玩意,误人子弟。
3、参加计算机类竞赛!!!参加ACM、蓝桥杯、Kaggle、阿里天池、百度之星大赛等,竞赛太重要了,竞赛不仅能得到荣誉,获得奖金,还能为保研、考研复试加分。
4、看国外教材,如《C语言程序设计:现代方法》、《算法4》,抛去谭浩强、严蔚敏这些书籍,你会发现国外教材几页就能讲清楚的知识点,国内的教材绕来绕去的,净是文字概念。
5、学习国外大学的公开课,如像MIT,斯坦福,普林斯顿,伯克利等等都有公开课,而且质量非常的高。比如伯克利的CS61b数据结构,MIT 6.828 的操作系统,斯坦福的CS 144计算机网络
6、补全学校计算机教育缺失的课程,学习Linux、shell脚本、vim、版本控制git、远程服务器访问(SSH)、Docker,这些学校不会教你,但是却是程序员开发必备!
7、学好计算机网络、操作系统、数据结构与算法和计算机组成原理四门计算机核心课程,这四门课就如同盖房子的地基,会使你的编程之路走的更扎实。功利点讲,是考研408的四门课程,是互联网大厂面试必考的知识!
8、做计算机类的项目,创业项目也好,实验室项目、github项目也罢,尽可能折腾,积累项目和实战经验,为将来找工作打好项目基础,还能锻炼实践能力
9、多刷leetcode,多刷leetcode,多刷leetcode,重要的事情说三遍,大二就可以开始,将来不管是去外企还是国内大厂,算法必考,尤其想去外企的,基本每场笔试都要来2、3道算法题。
校招也可以去牛客网刷题,在牛客网刷算法题,会发现遇到互联网公司常考的原题!
10、学会自学编程,自学能力觉得了编程路上可以走多远,因为计算机应用层知识更新换代太快了,就拿java来说,10年前还在用ssh框架,5年前是ssm,现在已经是springboot,springcloud微服务化!
11、利用Mooc、b站、网易云课堂、Coursera等平台自学编程,大学很多老师都是念ppt,有些老师自己都没做过项目,所以不如看一些高质量精品课程,收获更大。
12、考一些有必要的认证,如CCFP认证、浙大的PAT,(至于计算机二级、四级这些就算了),部分名校是考研复试时可以拿来抵机试成绩的,即使没考上研究生,直接去就业,很多企业也是认可的。
13、一定要实习,一定要实习,一定要实习,重要的事情说三遍,尤其是本科要去工作的,不管是日常实习还是暑期实习,最好要参加,秋招时,有实习经历的简直加分太多了!!!
05-10 Flink 如何解决作业资源随着需求的变化而动态调整的?
一部分业务是将 Flink 任务运行在 K8S 容器上的,使用 Flink Reactive Mode 响应模式,将 Flink 集群部署到 K8S 容器中,通过 K8S 的 Pod 水平自动扩缩容组件来实现 Flink 作业资源 TaskManager 的动态改变。 K8S 的 Pod 水平自动缩放组件会监控所有 TaskManager pods 的 CPU 负载来相应的调整副本因子(replication factor)。当 CPU 负载升高时,autoscaler 会增加 TaskManager 资源来平摊压力;当负载降低时,autoscaler 会减少 TaskManager 资源。
背后原理 首先,在 Flink 1.14.0 最新版本中依旧无法做到 Job 在运行时动态调整并行度 不经历重启 直接拉起新的 Task 实例运行,目前都是基于重启恢复机制来实现的,因为涉及到状态管理。 在资源管理中,资源的获取包含两种模式:
- Active 模式:主动式,Flink 可以主动申请、释放资源(通过与资源管理框架集成,如 Yarn、Mesos)。
- Reactive 模式:被动响应式,该模式由外部系统来分配,释放资源,Flink 只是简单地对可用资源进行响应。(这种模式对于基于容器环境相当有意义,如 K8S )
现在 Flink 的资源管理模式是 Active 模式,由用户明确指定 Job 需要的资源,JobMaster 会向 ResourceManager 去请求用户指定的全量资源,当 ResourceManager 无法满足 JobMaster 的申请需求时,该 job 将无法正常启动,它会陷入失败重启->再次尝试申请的循环。 为了能够同时支持 Active/Reactive 这两种模式,Flink 1.13.0 版本引入声明式资源管理设计。 该功能与原先最大差别在于:JobMaster 不再去逐个请求 Slot,而是声明需要的资源情况,对资源要求是弹性范围的,不是固定的。 弹性资源包含四件套:(min, target, max, rs),每个元素的含义如下:
- min : 执行 Job 的最小资源。
- target : JobMaster 期望获得的常规资源需求,它是可变的,这是扩缩容的主要触发机制。
- max : 最大资源期望。
- rs : resource spec(资源描述信息)。
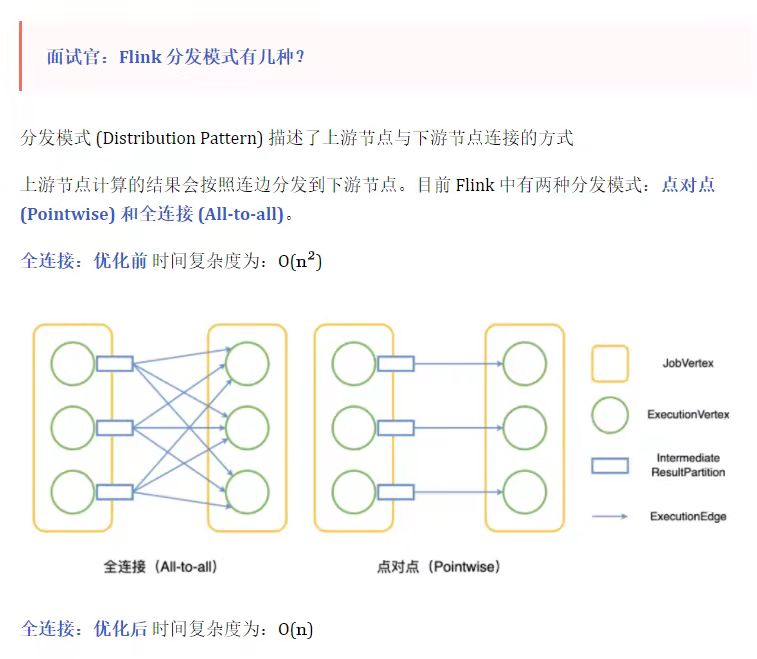
05-11 Flink 分发模式有几种?
分发模式 (Distribution Pattern) 描述了上游节点与下游节点连接的方式。上游节点计算的结果会按照连边分发到下游节点。目前 Flink 中有两种分发模式:点对点 (Pointwise) 和全连接 (All-to-all)。全连接:优化前时间复杂度为O(n2),全连接:优化后 时间复杂度为:O(n);点对点:时间复杂度O(n)。
05-16 Lambda架构和Kappa架构的对比?
Lamdba架构 是批流混合,历史按批处理,实时一套流处理,批处理做流处理的校验,总的数据以批处理(T-1)+流处理(当日)的为统计窗口;当有更新时,需维护两套代码。 Kappa架构 只有一套流处理,维护一套代码即可,需要考虑重算的场景。
05-17 上游新增一个字段,数仓如何应对?
表结构变更
上游的表结构经常会发生变化,新增字段、修改字段、删除字段(除非真的不用这个字段了,通常会选择标识为弃用)。
ods层
对于这种变化,人工处理的话,就是手动在数仓对应的表中增加、修改字段,然后修改同步任务;这个最好可以搞成自动化的,比如,自动监控上游表结构的变更,变化后,自动去修改数仓中的表结构,自动修改同步任务。
再往下层次可能就要影响业务了,这个时候就要权衡新增的字段是否有用(对于维表和事实表),多方面考虑权衡吧
05-18 通过SQL语句怎么对应MR的流程?
一. SQL转化为MapReduce的过程
- SQL词法、语法解析,将SQL转化为抽象语法树AST Tree。
- 遍历AST Tree,抽象出查询的基本组成单元QueryBlock。
- 遍历QueryBlock,翻译为执行操作树OperatorTree。
- 逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量。
- 遍历OperatorTree,翻译为MapReduce任务。
- 物理层优化器进行MapReduce任务的变换,生成最终的执行计划,
二. 以hive为例
如果hive.fetch.task.conversion=more
全局查找、字段查找、过滤查询、limit查询,都不会走MR,直接fetch抓取,提高查询效率
如果hive.fetch.task.conversion=none 任务转化为MR
MR任务的SQL
涉及到key的shuffle,比如JOIN、GROUP BY、DISTINCT等
JOIN转化为MR任务的流程
- Map:生成键值对,以JOIN ON条件中的列作为Key,以JOIN之后所关心的列作为Value,在Value中还会包含表的 Tag 信息,用于标明此Value对应于哪个表。
- Shuffle:根据Key的值进行 Hash,按照Hash值将键值对发送至不同的Reducer中。
- Reduce:Reducer通过 Tag 来识别不同的表中的数据,根据Key值进行Join操作。
GROUP BY转化为MR任务的流程
- Map:生成键值对,以GROUP BY条件中的列作为Key,以聚集函数的结果作为Value。
- Shuffle:根据Key的值进行 Hash,按照Hash值将键值对发送至不同的Reducer中。
- Reduce:根据SELECT子句的列以及聚集函数进行Reduce。
DISTINCT转化为MR任务的流程
和GROUP BY 类似:只是没有聚集函数的GROUP BY,操作相同,只是键值对中的value可为空。
当只有一个distinct字段时,如果不考虑Map阶段的Hash GroupBy,只需要将GroupBy字段和Distinct字段组合为map输出key,利用mapreduce的排序,同时将GroupBy字段作为reduce的key,在reduce阶段保存LastKey即可完成去重。
多个distinct字段,对所有的distinct字段编号,每行数据生成n行数据,那么相同字段就会分别排序,这时只需要在reduce阶段记录LastKey即可去重。
这种实现方式很好的利用了MapReduce的排序,节省了reduce阶段去重的内存消耗,但是缺点是增加了shuffle的数据量。需要注意的是,在生成reduce value时,除第一个distinct字段所在行需要保留value值,其余distinct数据行value字段均可为空。
05-19 如何得到计算任务的Map数量?
map任务个数等于split个数
当在hadopp中,map任务的个数等于split(分片)的个数,一个split对应一个map。
当文件小于split的大小时,一个文件对应一个split;
当文件大小超过split时,该文件将被切分成多个split,文件大小除以split得到split个数。
split大小的设置
max(minimumSize, min(maximumSize, blockSize))
分片公式
goalSize = totalSize / mapred.map.tasks
minSize = max {mapred.min.split.size, minSplitSize}
splitSize = max (minSize, min(goalSize, dfs.block.size))
缓慢变化维度有通过什么逻辑处理?
缓慢变化维处理方式:
- 新数据覆盖旧数据,不保留历史信息
- 快照表,每天对维度表做一个快照,保留所有信息,冗余数据较多
- 新增字段,保留历史值,保存的历史值有限
- 拉链表
05-23 Java多线程你了解多少?

若有收获,就点个赞吧
0 人点赞
