- 1 环境准备
- 2 安装Zookeeper 3.5.7
- 3 安装Hadoop 3.1.3
- !/bin/bash
hadoop=$HADOOP_HOME
hdfs=bigdata101
yarn=bigdata102
history=bigdata101
case $1 in
“start”)
echo “————-START HDFS———————“
ssh $hdfs “$hadoop/sbin/start-dfs.sh”
echo “————-START YARN———————“
ssh $yarn “$hadoop/sbin/start-yarn.sh”
echo “————-START HISTORY———————“
ssh $history “$hadoop/sbin/mr-jobhistory-daemon.sh start historyserver”
;;
“stop”)
echo “————-STOP HISTORY———————“
ssh $history “$hadoop/sbin/mr-jobhistory-daemon.sh stop historyserver” - 4 安装MySql
- 5 安装MySql 8
- 6 安装Hive 3.1.2
- 11 安装hbase
- 12 安装Kylin(之后再安装phoenix)
- 13 安装Phoenix
- 14 安装Flume
- configure source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /opt/module/apache-flume-1.9.0-bin/position/log_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /tmp/logs/app.+
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1 c2 - interceptor
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = com.dianjue.flume.MyInterceptor$Builders
a1.sources.r1.interceptors.i2.type = com.dianjue.flume.TypeInterceptor$BuilderType - a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.type = replicating
a1.sources.r1.selector.header = topic
a1.sources.r1.selector.mapping.topic_start = c1
a1.sources.r1.selector.mapping.topic_event = c2 - configure channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = bigdata101:9092,bigdata102:9092,bigdata103:9092
a1.channels.c1.kafka.topic = topic_start
a1.channels.c1.parseAsFlumeEvent = false
a1.channels.c1.kafka.consumer.group.id = flume-consumer- source1
a2.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a2.sources.r1.batchSize = 5000
a2.sources.r1.batchDurationMillis = 2000
a2.sources.r1.kafka.bootstrap.servers = bigdata101:9092,bigdata102:9092,bigdata103:9092
a2.sources.r1.kafka.topics=topic_start - source2
a2.sources.r2.type = org.apache.flume.source.kafka.KafkaSource
a2.sources.r2.batchSize = 5000
a2.sources.r2.batchDurationMillis = 2000
a2.sources.r2.kafka.bootstrap.servers = bigdata101:9092,bigdata102:9092,bigdata103:9092
a2.sources.r2.kafka.topics=topic_event - channel1
a2.channels.c1.type = file
a2.channels.c1.checkpointDir = /opt/module/apache-flume-1.9.0-bin/checkpoint/behavior1
a2.channels.c1.dataDirs = /opt/module/apache-flume-1.9.0-bin/data/behavior1
a2.channels.c1.maxFileSize = 2146435071
a2.channels.c1.keep-alive = 6
- source1
- a2.channels.c1.type = memory
#a2.channels.c1.capacity = 1000000
#a2.channels.c1.transactionCapacity = 10000
#a2.channels.c1.byteCapacityBufferPercentage = 20
#a2.channels.c1.byteCapacity = 800000 - a2.channels.c2.type = memory
#a2.channels.c2.capacity = 1000000
#a2.channels.c2.transactionCapacity = 10000
#a2.channels.c2.byteCapacityBufferPercentage = 20
#a2.channels.c2.byteCapacity = 800000
## channel2
a2.channels.c2.type = file
a2.channels.c2.checkpointDir = /opt/module/apache-flume-1.9.0-bin/checkpoint/behavior2
a2.channels.c2.dataDirs = /opt/module/apache-flume-1.9.0-bin/data/behavior2/
a2.channels.c2.maxFileSize = 2146435071
a2.channels.c2.capacity = 1000000
a2.channels.c2.keep-alive = 6- sink1
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = hdfs://bigdata101:8020/djBigData/origin_data/log/topic_start/%Y-%m-%d
a2.sinks.k1.hdfs.filePrefix = logstart-
a2.sinks.k1.hdfs.round = true
a2.sinks.k1.hdfs.roundValue = 10
a2.sinks.k1.hdfs.roundUnit = second - sink2
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://bigdata101:8020/djBigData/origin_data/log/topic_event/%Y-%m-%d
a2.sinks.k2.hdfs.filePrefix = logevent-
a2.sinks.k2.hdfs.round = true
a2.sinks.k2.hdfs.roundValue = 10
a2.sinks.k2.hdfs.roundUnit = second - 不要产生大量小文件
a2.sinks.k1.hdfs.rollInterval = 10
a2.sinks.k1.hdfs.rollSize = 134217728
a2.sinks.k1.hdfs.rollCount = 0 - 控制输出文件是原生文件。
a2.sinks.k1.hdfs.fileType = CompressedStream
a2.sinks.k2.hdfs.fileType = CompressedStream - 拼装
a2.sources.r1.channels = c1
a2.sinks.k1.channel= c1
- sink1
- 15 安装Datax (Python3.6+MySql 8)
- 21 安装Canal + UI + RDS_MySQL
- ################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
canal.user = canal
canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458">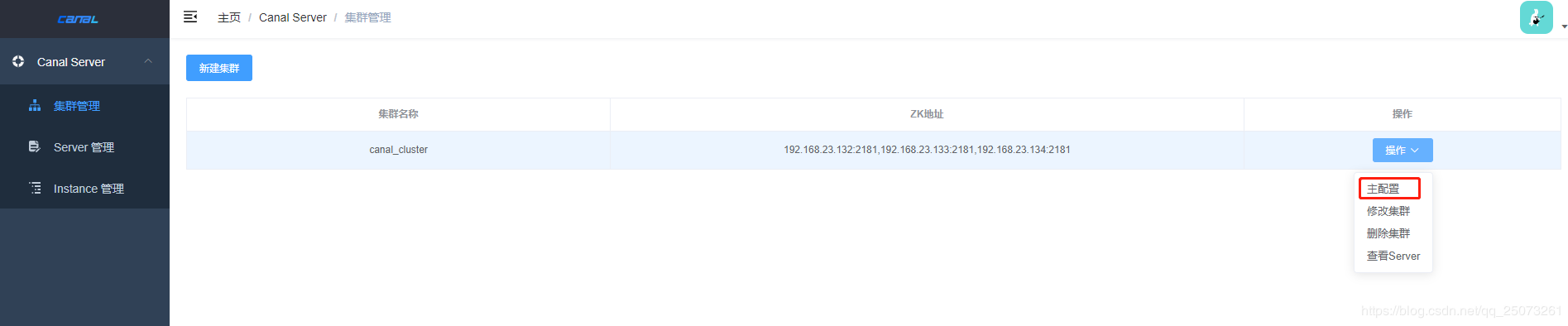 ################################################
################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
canal.user = canal
canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458 - canal admin config
canal.admin.manager = bigdata101:8899
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = xxxxxxx - support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60 - network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30 - binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false - binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB - binlog ddl isolation
canal.instance.get.ddl.isolation = false - parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256 - table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = 123456
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360 - aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =- ###########################################
######### destinations #############
#################################################
canal.destinations = user_topic
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5 - ############################################
######### MQ #############
##################################################
canal.mq.servers = 192.168.1.96:9092,192.168.1.12:9092,192.168.1.14:9092
canal.mq.retries = 0
canal.mq.batchSize = 16384
canal.mq.maxRequestSize = 1048576
canal.mq.lingerMs = 100
canal.mq.bufferMemory = 33554432
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
canal.mq.flatMessage = true
canal.mq.compressionType = none
canal.mq.acks = all
#canal.mq.properties. =
canal.mq.producerGroup = test
# Set this value to “cloud”, if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
# aliyun mq namespace
#canal.mq.namespace = - ############################################
######### Kafka Kerberos Info #############
##################################################
canal.mq.kafka.kerberos.enable = false
canal.mq.kafka.kerberos.krb5FilePath = “../conf/kerberos/krb5.conf”
canal.mq.kafka.kerberos.jaasFilePath = “../conf/kerberos/jaas.conf”
- ###########################################
- 3安装canal服务端
- register ip
canal.register.ip = - ">canal admin config
canal.admin.manager = bigdata101:8899
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = xxxxx
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster = canal_cluster
分别启动服务器上的canal服务
/canal/bin
sh startup.sh
刷新浏览器,点击server管理,发现已自动注入三个实例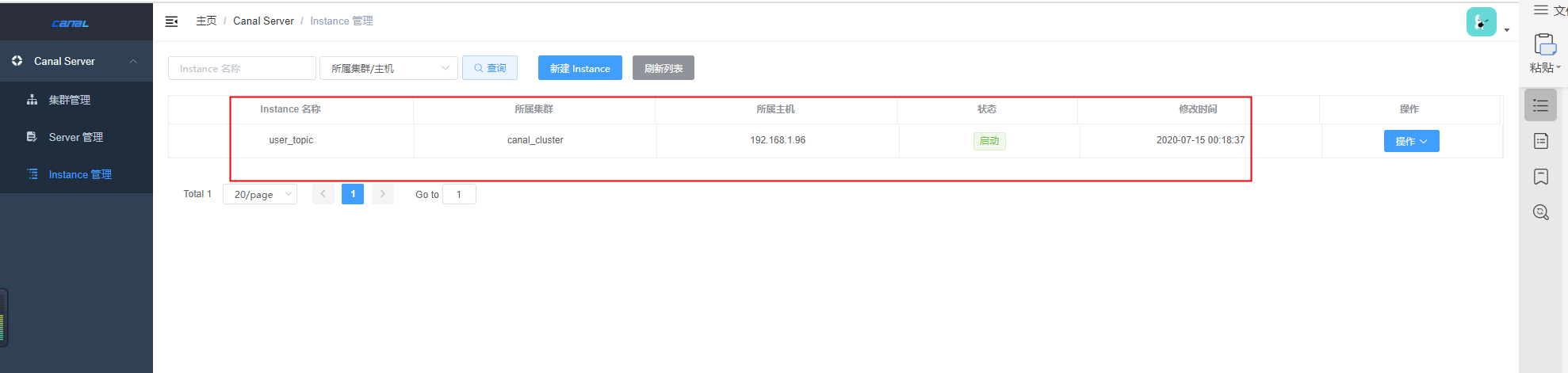
- enable gtid use true/false
canal.instance.gtidon=false - position info
canal.instance.master.address=ddddd:3306
canal.instance.master.journal.name=
canal.instance.master.position=0
canal.instance.master.timestamp=
canal.instance.master.gtid= - rds oss binlog
canal.instance.rds.accesskey=LTAI4Gxxxxxx2jDAYZFk
canal.instance.rds.secretkey=G1fyU1fD62xxxxxxxxXvdMQtieqZ
canal.instance.rds.instanceId=rm-uf68kxxxxxx6h0no3 - table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal - canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid= - username/password
canal.instance.dbUsername=appuser
canal.instance.dbPassword=Ctm56@Long
canal.instance.defaultDatabaseName = test
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ== - table regex
canal.instance.filter.regex=test\.student
# table black regex
canal.instance.filter.black.regex=
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch - mq config
canal.mq.topic=user_topic
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\..,.\..*
#canal.mq.partition=0
# hash partition config
canal.mq.partitionsNum=1
canal.mq.partitionHash=test.student:id - 22 编译与安装
- sudo vim /etc/profile.d/maven.sh
export MAVEN_HOME=/opt/software/apache-maven-3.6.1
export PATH=$PATH:$MAVEN_HOME/bin
MAVEN_OPTS=-Xmx2048m
export JAVA_HOME MAVEN_HOME MAVEN_OPTS JAVA_BIN PATH CLASSPATH - 23 其他配置与总结
- 24 Bug记录
- vim /etc/profile.d/locale.sh
export LC_CTYPE=zh_CN.UTF-8
export LC_ALL=zh_CN.UTF-8 - vim /etc/locale.conf
LANG=zh_CN.UTF-8 - vim /etc/sysconfig/i18n
LANG=zh_CN.UTF-8 - vim /etc/environment
LANG=zh_CN.UTF-8
LC_ALL=zh_CN.UTF-8 - vim /etc/profile.d/locale.sh
export LC_CTYPE=en_US.UTF-8
export LC_ALL=en_US.UTF-8 - vim /etc/locale.conf
LANG=en_US.UTF-8 - vim /etc/sysconfig/i18n
LANG=en_US.UTF-8 - vim /etc/environment
LANG=en_US.UTF-8
LC_ALL=en_US.UTF-8 - 25 SuperSet安装
1 环境准备
1.1虚拟机准备
克隆三台虚拟机(bigdata101、bigdata102、bigdata103),配置好对应主机的网络IP、主机名称、关闭防火墙。
设置bigdata101、bigdata102、bigdata103的主机对应内存分别是:4G、4G、4G
先创建用户,避免直接使用root用户
useradd later//创建用户
passwd later//为用户修改密码
(root用户下) vim /etc/sudoers,改为下图,目的是为later用户配置sudo权限
1.2配置免密登录
- 配置ssh免密登录
[later@bigdata101 ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.101 bigdata101
192.168.1.102 bigdata102
192.168.1.103 bigdata103
[later@bigdata101 ~]# ssh-keygen -t rsa
[later@bigdata101 ~]# ssh-copy-id bigdata101
[later@bigdata101 ~]# ssh-copy-id bigdata102
[later@bigdata101 ~]# ssh-copy-id bigdata102
其余两台机器同样操作一遍
1.3安装jdk
- 卸载linux上原有open jdk,其余两台机器同样操作进行卸载
[later@bigdata101 ~]# rpm -qa | grep jdk
java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64
copy-jdk-configs-3.3-2.el7.noarch
java-1.8.0-openjdk-headless-1.8.0.161-2.b14.el7.x86_64
[later@bigdata101 ~]# rpm -e —nodeps java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64
[later@bigdata101 ~]# rpm -e —nodeps copy-jdk-configs-3.3-2.el7.noarch
[later@bigdata101 ~]# rpm -e —nodeps java-1.8.0-openjdk-headless-1.8.0.161-2.b14.el7.x86_64
- 创建软件包存放目录
[later@bigdata101 ~]# mkdir /opt/software
[later@bigdata101 ~]# cd /opt/software/
(3)上传jdk安装包并进行解压,添加环境变量
[later@bigdata101 software]# mkdir /opt/module
[later@bigdata101 software]# tar -zxvf jdk-8u211-linux-x64.tar.gz -C /opt/module/
/opt/module/jdk1.8.0_211
[later@bigdata101 jdk1.8.0_211]# sudo vim /etc/profile.d/java.sh
把环境变量都分开放置在/etc/profile.d/目录下,可以做到全局使用,同时容易管理
在profile结尾处加上jdk路径
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_211
export PATH=$PATH:$JAVA_HOME/bin
(4)source下
[later@bigdata101 jdk1.8.0_211]# source /etc/profile.d/java.sh
[later@bigdata101 jdk1.8.0_211]# java -version
java version “1.8.0_211”
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
[later@bigdata101 jdk1.8.0_211]#
- 将module包的jdk路径传输到其余两台机器上,并配置jdk环境变量source下
[later@bigdata101 module]# scp -r /opt/module/jdk1.8.0_211/ bigdata101:/opt/module/
[later@bigdata101 module]# scp -r /opt/module/jdk1.8.0_211/ bigdata102:/opt/module/
[later@bigdata101 module]# scp /etc/profile bigdata101:/etc/
[later@bigdata101 module]# scp /etc/profile bigdata102:/etc/
[later@bigdata101 module]# source /etc/profile
[later@bigdata101 module]# java -version
java version “1.8.0_211”
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
[later@bigdata102 ~]# source /etc/profile
[later@bigdata102 ~]# java -version
java version “1.8.0_211”
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
1.4关闭防火墙
[later@bigdata101 ~]# systemctl stop firewalld.service//关闭防火墙
[later@bigdata101 ~]# systemctl disable firewalld.service //开机禁止启动防火墙
[later@bigdata102 ~]# systemctl stop firewalld.service
[later@bigdata102 ~]# systemctl disable firewalld.service
[later@bigdata103 ~]# systemctl stop firewalld.service
[later@bigdata103 ~]# systemctl disable firewalld.service
2 安装Zookeeper 3.5.7
(1)上传压缩包到software文件夹,并进行解压
[later@bigdata101 module]# cd /opt/software/
[later@bigdata101 software]# tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
(2)在zookeeper目录创建zkData目录
[later@bigdata101 module]# cd apache-zookeeper-3.5.7-bin/
[later@bigdata101 apache-zookeeper-3.5.7-bin]# mkdir zkData
- 在zkData目录下创建myid文件,写上对应比编号1并保存
[later@bigdata101 apache-zookeeper-3.5.7-bin]# cd zkData/
[later@bigdata101 zkData]# vim myid
1
(4)配置zoo.cfg
[later@bigdata101 apache-zookeeper-3.5.7]# cd conf/
[later@bigdata101 conf]# mv zoo_sample.cfg zoo.cfg
[later@bigdata101 conf]# vim zoo.cfg
修改数据存储路径
dataDir=/opt/module/apache-zookeeper-3.5.7-bin/zkData
在文件末尾处增加集群配置
server.1=bigdata101:2888:3888
server.2=bigdata102:2888:3888
server.3=bigdata103:2888:3888
(5)分发到各节点
[later@bigdata101 software]# cd /opt/module/
[later@bigdata101 module]# scp -r apache-zookeeper-3.5.7-bin/ bigdata102:/opt/module/
[later@bigdata101 module]# scp -r apache-zookeeper-3.5.7-bin/ bigdata103:/opt/module/
(6)修改其余两台机器的myid,分别为2,3
[later@bigdata102 apache-zookeeper-3.5.7]# vim zkData/myid
2
[later@bigdata103 apache-zookeeper-3.5.7]# vim zkData/myid
3
(7)启动集群
[later@bigdata101 ~]# /opt/module/apache-zookeeper-3.5.7-bin/bin/zkServer.sh start
[later@bigdata102 ~]# /opt/module/apache-zookeeper-3.5.7-bin/bin/zkServer.sh start
[later@bigdata103 ~]# /opt/module/apache-zookeeper-3.5.7-bin/bin/zkServer.sh start
(8)启动脚本
[later@bigdata101 bin]$ pwd(自己建个bin目录,来存放自己的脚本,配置环境变量)
/opt/bin
[later@bigdata101 bin]$ vim zk.sh
#! /bin/bash
case $1 in
“start”){
for i in bigdata101 bigdata102 bigdata103
do
ssh $i “/opt/module/apache-zookeeper-3.5.7-bin/bin/zkServer.sh start”
done
};;
“stop”){
for i in bigdata101 bigdata102 bigdata103
do
ssh $i “/opt/module/apache-zookeeper-3.5.7-bin/bin/zkServer.sh stop”
done
};;
“status”){
for i in bigdata101 bigdata102 bigdata103
do
ssh $i “/opt/module/apache-zookeeper-3.5.7-bin/bin/zkServer.sh status”
done
};;
esac
[later@bigdata101 bin]$ vim xcall.sh
2)在脚本中编写如下内容
#! /bin/bash
for i in bigdata101 bigdata102 bigdata103
do
echo ————- $i —————
ssh $i “$*”
done
3)修改脚本执行权限
[later@bigdata101 bin]$ chmod 777 xcall.sh
4)启动脚本
[later@bigdata101 bin]$ xcall.sh jps
5)分发文件脚本xsync.sh
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if ((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=basename $p1
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=cd -P $(dirname $p1); pwd
echo pdir=$pdir
#4 获取当前用户名称
user=whoami
#5 循环
for((host=102; host<104; host++)); do
echo —————————- bigdata$host ———————
rsync -av $pdir/$fname $user@bigdata$host:$pdir
done
3 安装Hadoop 3.1.3
3.1HDFS HA搭建
- 上传压缩包到software文件夹,并进行解压
[later@bigdata101 module]# cd /opt/software/
[later@bigdata101 software]# tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
- 分发opt目录下hadoop文件夹
[later@bigdata101 software]# cd /opt/module/
[later@bigdata101 module]# scp -r hadoop-3.1.3/ bigdata102:/opt/module/
[later@bigdata101 module]# scp -r hadoop-3.1.3/ bigdata103:/opt/module/
(3)配置hadoop环境变量,结尾处加上hadoop路径,其余两台机器同样操作
[later@bigdata101 hadoop-3.1.3]# #HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[later@bigdata101 hadoop-3.1.3]# source /etc/profile.d/hadoop.sh
[later@bigdata101 hadoop-3.1.3]# hadoop version
Hadoop 3.1.3
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
Compiled by ztang on 2019-09-12T02:47Z
Compiled with protoc 2.5.0
From source with checksum ec785077c385118ac91aadde5ec9799
This command was run using /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar
(4)配置nameservice,编写hdfs-sitx.xml
[later@bigdata101 hadoop-3.1.3]# cd etc/hadoop/
[later@bigdata101 hadoop]# vim hdfs-site.xml
- 编写core-site.xml
3.2ResouceManager HA搭建
- 编写yarn-site.xml
[later@bigdata101 hadoop]# vim yarn-site.xml
3.3启动集群
- 配置workers(老版本为slaves)
[later@bigdata101 hadoop]# vim workers
bigdata101
bigdata102
bigdata103
(2)分发配置文件
[later@bigdata101 hadoop]# cd ..
[later@bigdata101 etc]# scp -r hadoop/ bigdata102:/opt/module/hadoop-3.1.3/etc/
[later@bigdata101 etc]# scp -r hadoop/ bigdata103:/opt/module/hadoop-3.1.3/etc/
(3)在name node各台机器上启动journalnode服务
[later@bigdata101 hadoop-3.1.3]# sbin/hadoop-daemon.sh start journalnode
[later@bigdata102 hadoop-3.1.3]# sbin/hadoop-daemon.sh start journalnode
(4)在nn1上对namenode进行格式化
[later@bigdata101 hadoop-3.1.3]# bin/hdfs namenode -format
(5)编辑hadoop-env.sh,解开注释,添加JAVA_HOME
[later@bigdata101 hadoop-3.1.3]# vim etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_211
[later@bigdata102 hadoop-3.1.3]# vim etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_211
[later@bigdata103 hadoop-3.1.3]# vim etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_211
(6)分发以上.sh文件
[later@bigdata101 hadoop-3.1.3]# scp -r sbin/ bigdata101:/opt/module/hadoop-3.1.3/
[later@bigdata101 hadoop-3.1.3]# scp -r sbin/ bigdata102:/opt/module/hadoop-3.1.3/
(7)同步,启动nn1的namenode,在 nn2和nn3上进行同步
[later@bigdata101 hadoop-3.1.3]# sbin/hadoop-daemon.sh start namenode
[later@bigdata102 hadoop-3.1.3]# bin/hdfs namenode -bootstrapStandby
[later@bigdata102 hadoop-3.1.3]# sbin/hadoop-daemon.sh start namenode
(8)关闭所有hdfs服务
[later@bigdata101 hadoop-3.1.3]# sbin/stop-all.sh
(9)初始化HA在Zookeeper中状态:
[later@bigdata101 hadoop-3.1.3]# bin/hdfs zkfc -formatZK
(10)启动集群服务
[later@bigdata101 hadoop-3.1.3]# sbin/start-all.sh
- 启动hadoop脚本
!/bin/bash
hadoop=$HADOOP_HOME
hdfs=bigdata101
yarn=bigdata102
history=bigdata101
case $1 in
“start”)
echo “————-START HDFS———————“
ssh $hdfs “$hadoop/sbin/start-dfs.sh”
echo “————-START YARN———————“
ssh $yarn “$hadoop/sbin/start-yarn.sh”
echo “————-START HISTORY———————“
ssh $history “$hadoop/sbin/mr-jobhistory-daemon.sh start historyserver”
;;
“stop”)
echo “————-STOP HISTORY———————“
ssh $history “$hadoop/sbin/mr-jobhistory-daemon.sh stop historyserver”
echo “————-STOP HDFS———————“
ssh $hdfs “$hadoop/sbin/stop-dfs.sh”
echo “————-STOP YARN———————“
ssh $yarn “$hadoop/sbin/stop-yarn.sh”
;;
3.4注意问题
如果出现节点为standby,另一个节点没反应,日志显示为通信异常,检查防火墙,并且检查zookeeper集群服务是否正常
4 安装MySql
4.1安装MySql服务端
(1)卸载MySql依赖,虽然机器上没有装MySql,但是这一步不可少
[later@bigdata101 software]# yum remove mysql-libs
- 下载依赖并安装
[later@bigdata101 software]# yum install libaio
[later@bigdata101 software]# yum -y install autoconf
[later@bigdata101 software]# yum -y install net-tools
- 上传mysql的 rpm包,并进行解压
下载地址:https://downloads.mysql.com/archives/community/
[later@bigdata101 software]# tar -xvf mysql-5.7.25-1.el7.x86_64.rpm-bundle.tar
(4)把这些rpm包放到自己建的mysql文件夹下
(5)安装MySql服务端
[later@bigdata101 mysql-libs]#
rpm -ivh mysql-*.rpm或
rpm -ivh MySQL-server-5.6.24-1.el6.x86_64.rpm(所有的都装上) —nodeps —force
(6)启动MySql service mysqld start
[later@bigdata101 mysql-libs]# systemctl start mysqld.service
(7)查看MySql服务状态
[later@bigdata101 mysql-libs]# systemctl status mysqld.service
ERROR! MySQL is not running
(8)查看生产的随机密码
[later@bigdata101 mysql-libs]# sudo grep “password” /var/log/mysqld.log
2020-05-10T03:16:11.458559Z 1 [Note] A temporary password is generated for root@localhost: SYZ&gkaKk5ct
(9)登录MySql
[later@bigdata101 mysql-libs]# mysql -uroot -p
Enter password:SYZ&gkaKk5ct
(10)修改密码
mysql> SET PASSWORD=PASSWORD(‘Dj123456’); 或者
alter user ‘root’@’*’ identified by ‘Dj123456+’;
(11)退出MySql
mysql> exit;
4.3配置User表访问权限
(1)登录MySql,访问库mysql
[later@bigdata101 mysql-libs]# mysql -uroot -p123456
mysql> show databases;
+——————————+
| Database |
+——————————+
| information_schema |
| mysql |
| performance_schema |
| test |
+——————————+
mysql> use mysql
mysql> show tables;
- 修改User表
mysql> select User, Host from user;
mysql> create user ‘root’@’%’ identified by ‘Dj123456+’;
mysql>GRANT ALL PRIVILEGES ON . TO ‘root’@’%’ IDENTIFIED BY ‘Dj123456+’ WITH GRANT OPTION;
- 刷新
mysql> flush privileges;
- 退出
5 安装MySql 8
skip-grant-tables 如果密码忘记,可以在配置文件中加上可以跳过密码验证进入到客户端
前面步骤一个样
1.修改密码
alter user ‘root’@’localhost’ identified by ‘Dj123456+’;
2.创建用户
create user ‘root’@’%’ identified by ‘Dj123456+’;
3.赋权限
grant all privileges on . to ‘root’@’%’ with grant option;
如果外部工具连接不上,更改密码策略
ALTER USER ‘root’@’%’ IDENTIFIED WITH mysql_native_password BY ‘Dj123456+’;
4.flush privileges;
6 安装Hive 3.1.2
- 上传hive压缩包,并进行解压
[later@bigdata101 software]# tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/
- 拷贝MySql驱动到hive lib下
[later@bigdata101 software]# cd mysql-libs/
[later@bigdata101 mysql-libs]# tar -zxvf mysql-connector-java-5.1.27.tar.gz
[later@bigdata101 mysql-libs]# cd mysql-connector-java-5.1.27/
[later@bigdata101 mysql-connector-java-5.1.27]# cp mysql-connector-java-5.1.27-bin.jar /opt/module/apache-hive-3.1.2-bin/lib/
- 配置hive元数据到MySql
[later@bigdata101 mysql-connector-java-5.1.27]# cd /opt/module/apache-hive-3.1.2-bin/conf/
[later@bigdata101 conf]# vim hive-site.xml
<?xml version=”1.0”?>
<?xml-stylesheet type=”text/xsl” href=”configuration.xsl”?>
<property><br /> <name>javax.jdo.option.ConnectionDriverName</name><br /> <value>com.mysql.jdbc.Driver</value><br /> <description>Driver class name for a JDBC metastore</description><br /> </property><property><br /> <name>javax.jdo.option.ConnectionUserName</name><br /> <value>root</value><br /> <description>username to use against metastore database</description><br /> </property><property><br /> <name>javax.jdo.option.ConnectionPassword</name><br /> <value>123456</value><br /> <description>password to use against metastore database</description><br /> </property><br /> <property><br /> <name>hive.metastore.warehouse.dir</name><br /> <value>/user/hive/warehouse</value><br /> <description>location of default database for the warehouse</description><br /> </property><br /> <property><br /> <name>hive.cli.print.header</name><br /> <value>true</value><br /></property>
<property><br /> <name>hive.server2.thrift.bind.host</name><br /> <value>bigdata101</value><br /> </property>
1. 配置hive环境变量,在profile结尾处加上以下内容 [later@bigdata101 apache-hive-3.1.2-bin]# sudo vim /etc/profile.d/hive.sh
#HIVE_HOME
export HIVE_HOME=/opt/module/apache-hive-3.1.2-bin
export PATH=$PATH:$HIVE_HOME/bin
[later@bigdata101 apache-hive-3.1.2-bin]# source /etc/profile.d/hive.sh 1. 替换hive中的guava.jar [later@bigdata101 apache-hive-3.1.2-bin]# cd lib/
[later@bigdata101 lib]# ls |grep guava
guava-19.0.jar
jersey-guava-2.25.1.jar
显示版本好为19.0,再次进入hadoop中查看对应版本
[later@bigdata101 lib]# cd /opt/module/hadoop-3.1.3/share/hadoop/common/lib/
[later@bigdata101 lib]# ls |grep guava
guava-27.0-jre.jar
listenablefuture-9999.0-empty-to-avoid-conflict-with-guava.jar
版本号为27.0,删除hive原有guava的jar包并将hadoop中的guava-27.0-jre.jar复制过去
[later@bigdata101 lib]# cp guava-27.0-jre.jar /opt/module/apache-hive-3.1.2-bin/lib/
[later@bigdata101 lib]# cd /opt/module/apache-hive-3.1.2-bin/lib/
[later@bigdata101 lib]# ls |grep guava
guava-19.0.jar
guava-27.0-jre.jar
jersey-guava-2.25.1.jar
[later@bigdata101 lib]# rm -f guava-19.0.jar
(6)启动元数据服务,后台运行服务
注意hive 2.x版本以上需要启动两个服务 metastore和hiveserver2 否则会报错Exception in thread “main” java.lang.RuntimeException: org.apache.hadoop.hive.ql.metadata.HiveException: javcd /op a.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
[later@bigdata101 apache-hive-3.1.2-bin]# nohup hive —service metastore >metasotre.log>&1 &
[later@bigdata101 apache-hive-3.1.2-bin]# nohup hive —service hiveserver2 >hiveserver2.log >&1 &
(7)启动元数据命令脚本
#!/bin/bash
case $1 in
“start”){
nohup hive —service metastore >/opt/module/apache-hive-3.1.2-binmetasotre.log>&1 &
nohup hive —service hiveserver2 >/opt/module/apache-hive-3.1.2-binhiveserver2.log >&1 &
};;
“stop”){
SIGNAL=${SIGNAL:-TERM}
PIDS=$(jps -lm | grep -i ‘metastore.HiveMetaStore’ | awk ‘{print $1}’)
if [ -z “$PIDS” ]; then
echo “No HiveMetaStore server to stop”
exit 1
else
kill -s $SIGNAL $PIDS
fi PIDS=$(jps -lm | grep -i ‘HiveServer2’ | awk ‘{print $1}’)
if [ -z “$PIDS” ]; then
echo “No HiveServer2 to stop”
exit 1
else
kill -s $SIGNAL $PIDS
fi
};;
esac 1. 启动hive [later@bigdata101 apache-hive-3.1.2-bin]# hive 如果执行show tables或者其他命令时候卡着不动,可能问题是元数据有问题,需要手动导入到mysql中去:
schematool -dbType mysql -initSchema # 7 安装Hue ## 1安装Maven (1)在102机器上进行安装,创建software文件夹,并解压
[later@bigdata102 ~]# mkdir /opt/software
[later@bigdata102 ~]# cd /opt/software/
[later@bigdata102 software]# tar -zxvf apache-maven-3.6.1-bin.tar.gz -C /opt/module/
(2)添加环境变量,在profile文件结尾添加以下内容
/opt/module/apache-maven-3.6.1
[later@bigdata102 software]# vim /etc/profile
#MAVEN_HOME
export MAVEN_HOME=/opt/module/apache-maven-3.6.1
export PATH=$PATH:$MAVEN_HOME/bin
[later@bigdata102 software]# source /etc/profile
(3)测试安装结果
[later@bigdata102 software]# mvn -v
Apache Maven 3.6.1 (d66c9c0b3152b2e69ee9bac180bb8fcc8e6af555; 2019-04-05T03:00:29+08:00)
Maven home: /opt/module/apache-maven-3.6.1
Java version: 1.8.0_211, vendor: Oracle Corporation, runtime: /opt/module/jdk1.8.0_211/jre
Default locale: zh_CN, platform encoding: UTF-8
OS name: “linux”, version: “3.10.0-862.el7.x86_64”, arch: “amd64”, family: “unix” 1. 配置阿里云镜像,注意添加miroor镜像一定要在mirrors标签内,否则无效 [later@bigdata102 software]# cd /opt/module/apache-maven-3.6.1/conf/
[later@bigdata102 conf]# vim settings.xml
[later@bigdata102 software]# wget http://npm.taobao.org/mirrors/node/v8.11.3/node-v8.11.3-linux-x64.tar.gz
[later@bigdata102 software]# tar -zxvf node-v13.9.0-linux-x64.tar.gz -C /opt/module/
(2)建立软链
[later@bigdata102 software]# ln -s /opt/module/node-v8.11.3-linux-x64/bin/npm /usr/local/bin/npm
[later@bigdata102 software]# ln -s /opt/module/node-v8.11.3-linux-x64/bin/node /usr/local/bin/node 1. 查看版本 [later@bigdata102 software]# npm -v
5.6.0 ## 3安装PIP (1)安装pip
[later@bigdata102 software]# curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
[later@bigdata102 software]# python get-pip.py
(2)安装环境
[later@bigdata102 software]$ pip install Werkzeug
[later@bigdata102 software]# pip install windmill
[later@bigdata102 software]# npm install node-inspector -g —unsafe-perm
注意:install node-inspector -g —unsafe-perm 本人在执行这部时虽然后面报错了,但编译可以正常通过了 ## 4安装Hue 可直接使用编译后的hue,修改配置成自己集群配置即可 1. 在102机器上装hue,创建software文件夹,上传压缩包并解压 [later@bigdata102 software]# unzip hue-master.zip -d /opt/module/ 1. 安装环境 [later@bigdata102 software]# cd /opt/module/hue-master/
[later@bigdata102 hue-master]# sudo yum install ant asciidoc cyrus-sasl-devel cyrus-sasl-gssapi cyrus-sasl-plain gcc gcc-c++ krb5-devel libffi-devel libxml2-devel libxslt-devel make mysql mysql-devel openldap-devel python-devel sqlite-devel gmp-devel
(3)编译安装,编译完成后生成build文件夹
[hue@bigdata102 hue-master]# make apps
(4)修改hadoop配置文件,因为集群HA模式,所以采用httpfs模式
[hue@bigdata102 hue-master]# cd /opt/module/hadoop-3.1.3/etc/hadoop/
[hue@bigdata102 hadoop]# vim hdfs-site.xml
[hue@bigdata102 hadoop]# vim core-site.xml
[hue@bigdata102 hadoop]# vim httpfs-site.xml
(5)分发配置文件
[hue@bigdata102 etc]# pwd
/opt/module/hadoop-3.1.3/etc
[hue@bigdata102 etc]scp -r hadoop/ bigdata102:/opt/module/hadoop-3.1.3/etc/
[hue@bigdata102 etc]scp -r hadoop/ bigdata102:/opt/module/hadoop-3.1.3/etc/
(6)修改hue配置文件,集成hdfs
[hue@bigdata102 hadoop]# cd /opt/module/hue-master/desktop/conf
[hue@bigdata102 conf]# vim pseudo-distributed.ini
http_host=bigdata102
http_port=8000
[[[default]]]
# Enter the filesystem uri
fs_defaultfs=hdfs://mycluster:8020
logical_name=mycluster
webhdfs_url=http://bigdata101:14000/webhdfs/v1
hadoop_conf_dir=/opt/module/hadoop-3.1.3/etc/hadoop/conf
(7)集成yarn,以下logic_name需要对应yarn-site.xml文件里的配置,注意:一定要解开HA标签前面的注释,否则会报错
[[yarn_clusters]] [[[default]]]
# Enter the host on which you are running the ResourceManager
## resourcemanager_host=mycluster # The port where the ResourceManager IPC listens on
## resourcemanager_port=8032 # Whether to submit jobs to this cluster
submit_to=True # Resource Manager logical name (required for HA)
logical_name=rm1 # Change this if your YARN cluster is Kerberos-secured
## security_enabled=false # URL of the ResourceManager API
resourcemanager_api_url=http://bigdata103:8088 # URL of the ProxyServer API
## proxy_api_url=http://bigdata101:8088 # URL of the HistoryServer API
## history_server_api_url=http://localhost:19888 [[[ha]]]
# Resource Manager logical name (required for HA)
logical_name=rm2 # Un-comment to enable
submit_to=True # URL of the ResourceManager API
resourcemanager_api_url=http://bigdata102:8088 # …
(8)集成mysql
[[database]]
# Database engine is typically one of:
# postgresql_psycopg2, mysql, sqlite3 or oracle.
#
# Note that for sqlite3, ‘name’, below is a path to the filename. For other backends, it is the database name.
# Note for Oracle, options={“threaded”:true} must be set in order to avoid crashes.
# Note for Oracle, you can use the Oracle Service Name by setting “host=” and “port=” and then “name=
# Note for MariaDB use the ‘mysql’ engine.
engine=mysql
host=bigdata101
port=3306
user=root
password=123456
# conn_max_age option to make database connection persistent value in seconds
# https://docs.djangoproject.com/en/1.9/ref/databases/#persistent-connections
## conn_max_age=0
# Execute this script to produce the database password. This will be used when ‘password’ is not set.
## password_script=/path/script
name=hue
在mysql中创建hue库
[hue@bigdata101 apache-hive-3.1.2-bin]# mysql -uroot -p123456
mysql> create database hue; ## [[[mysql]]]
# Name to show in the UI.
## nice_name=”My SQL DB” # For MySQL and PostgreSQL, name is the name of the database.
# For Oracle, Name is instance of the Oracle server. For express edition
# this is ‘xe’ by default.
name=huemetastore
# Database backend to use. This can be:
# 1. mysql
# 2. postgresql
# 3. oracle
engine=mysql
port=3306
user=root
password=123456 (9)集成hive
[beeswax] # Host where HiveServer2 is running.
# If Kerberos security is enabled, use fully-qualified domain name (FQDN).
hive_server_host=bigdata101
# Port where HiveServer2 Thrift server runs on.
hive_server_port=10000
hive_conf_dir=/opt/module/apache-hive-3.1.2-bin/conf/
(10)停止集群,重启
[later@bigdata101 software]# zk.sh stop
[later@bigdata101 software]# zk.sh start
[later@bigdata101 software]# start-all.sh
(11)启动hive元数据服务
[later@bigdata101 apache-hive-3.1.2-bin]# hive.sh start(脚本见hive安装)
(12)新增用户hue,并修改文件夹权限
[later@bigdata102 hue-master]# useradd hue
[later@bigdata102 hue-master]# passwd hue
[later@bigdata102 hue-master]# chown -R hue:hue /opt/module/hue-master/ 1. 初始化数据库 [later@bigdata102 hue-master]# build/env/bin/hue syncdb
[later@bigdata102 hue-master]# build/env/bin/hue migrate 1. 启动hue,注意启动的时候必须启动hive的两个服务,并且metastore和hiveserver2两个服务必须启动,10000端口占用着 [root@bigdata102 hue-master]# build/env/bin/supervisor (这个启动需要root权限)默认的账号密码都是admin,登录后可以在左下角角色管理创建用户
 # 8 安装Kakfa_2.11-2.4.0
1. 上传压缩包并解压,并进行解压
[later@bigdata101 software]# tar -zxvf kafka_2.11-2.4.0.tgz -C /opt/module/
1. 进入kafka目录,创建log日志文件夹
[later@bigdata101 software]# cd /opt/module/kafka_2.11-2.4.0/
# 8 安装Kakfa_2.11-2.4.0
1. 上传压缩包并解压,并进行解压
[later@bigdata101 software]# tar -zxvf kafka_2.11-2.4.0.tgz -C /opt/module/
1. 进入kafka目录,创建log日志文件夹
[later@bigdata101 software]# cd /opt/module/kafka_2.11-2.4.0/[later@bigdata101 kafka_2.11-2.4.0]# mkdir logs
(3)修改配置文件
[later@bigdata101 kafka_2.11-2.4.0]# cd config/
[later@bigdata101 config]# vim server.properties
输入以下内容:
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志存放的路径
log.dirs=/opt/module/kafka_2.11-2.4.0/logs
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接Zookeeper集群地址
zookeeper.connect=bigdata101:2181,bigdata101:2181,bigdata102:2181/kafka_2.4 注意:zookeeper.connect之所以在zk地址后再加上个kafa_2.4目的在于注册信息不是直接注册到zk根目录下,而是注册到 /kakfa_2.4目录下。对应的kafka 命令zk参数也得跟着变
(4)分发到其他节点并对应修改broker.id。102,103节点分别对应1,2
[later@bigdata101 kafka_2.11-2.4.0]# cd /opt/module/
[later@bigdata101 module]# scp -r /opt/module/kafka_2.11-2.4.0/ bigdata102:/opt/module/
[later@bigdata101 module]# scp -r /opt/module/kafka_2.11-2.4.0/ bigdata103:/opt/module/
[later@bigdata102 config]# pwd
/opt/module/kafka_2.11-2.4.0/config
[later@bigdata102 config]# vim server.properties
broker.id=1
[later@bigdata103 config]# pwd
/opt/module/kafka_2.11-2.4.0/config
[later@bigdata103 config]# vim server.properties
broker.id=2
(5)启动zk集群,再启动kafka
[later@bigdata101 module]# zk.sh start
[later@bigdata101 module]# /opt/module/kafka_2.11-2.4.0/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.11-2.4.0/config/server.properties
[later@bigdata101 config]# /opt/module/kafka_2.11-2.4.0/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.11-2.4.0/config/server.properties
[later@bigdata102 config]# /opt/module/kafka_2.11-2.4.0/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.11-2.4.0/config/server.properties
(6)启动后,可以去zk里看下注册信息
[later@bigdata101 module]# /opt/module/apache-zookeeper-3.5.7-bin/bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[hadoop-ha, kafka_2.4, rmstore, yarn-leader-election, zookeeper]
注册到kafka_2.4中,而不是根目录,可以继续查看里面信息
[zk: localhost:2181(CONNECTED) 1] ls /kafka_2.4
[admin, brokers, cluster, config, consumers, controller, controller_epoch, isr_change_notification, latest_producer_id_block, log_dir_event_notification]
(7)创建topic命令,因为注册信息不是在根目录,所以zk参数得跟着变
[later@bigdata101 module]# /opt/module/kafka_2.11-2.4.0/bin/kafka-topics.sh —zookeeper bigdata101:2181/kafka_2.4 —create —replication-factor 2 —partitions 3 —topic test
Created topic test. 1. kafka启动脚本kk.sh #! /bin/bash case $1 in
“start”){
for i in bigdata101 bigdata102 bigdata103
do
echo “ ————启动 $i Kafka———-“
ssh $i “/opt/module/kafka_2.11-2.4.0/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.11-2.4.0/config/server.properties “
done
};;
“stop”){
for i in bigdata101 bigdata102 bigdata103
do
echo “ ————停止 $i Kafka———-“
ssh $i “/opt/module/kafka_2.11-2.4.0/bin/kafka-server-stop.sh stop”
done
};;
esac # 9 安装kafka-eagle ## 10.1 Kafka Eagle 1.修改kafka启动命令
修改kafka-server-start.sh命令中
if [ “x$KAFKA_HEAP_OPTS” = “x” ]; then
export KAFKA_HEAP_OPTS=”-Xmx1G -Xms1G”
fi
为
if [ “x$KAFKA_HEAP_OPTS” = “x” ]; then
export KAFKA_HEAP_OPTS=”-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70”
export JMX_PORT=”9999”
#export KAFKA_HEAP_OPTS=”-Xmx1G -Xms1G”
fi
注意:修改之后在启动Kafka之前要分发之其他节点
2.上传压缩包kafka-eagle-bin-1.3.7.tar.gz到集群/opt/software目录
3.解压到本地
[later@bigdata102 software]$ tar -zxvf kafka-eagle-bin-1.3.7.tar.gz
4.进入刚才解压的目录
[later@bigdata102 kafka-eagle-bin-1.3.7]$ ll
总用量 82932
-rw-rw-r—. 1 later later 84920710 8月 13 23:00 kafka-eagle-web-1.3.7-bin.tar.gz
5.将kafka-eagle-web-1.3.7-bin.tar.gz解压至/opt/module
[later@bigdata102 kafka-eagle-bin-1.3.7]$ tar -zxvf kafka-eagle-web-1.3.7-bin.tar.gz -C /opt/module/
6.修改名称
[later@bigdata102 module]$ mv kafka-eagle-web-1.3.7/ eagle
7.给启动文件执行权限
[later@bigdata102 eagle]$ cd bin/
[later@bigdata102 bin]$ ll
总用量 12
-rw-r—r—. 1 later later 1848 8月 22 2017 ke.bat
-rw-r—r—. 1 later later 7190 7月 30 20:12 ke.sh
[later@bigdata101 bin]$ chmod 777 ke.sh
8.修改配置文件
######################################
# multi zookeeper&kafka cluster list
######################################
kafka.eagle.zk.cluster.alias=cluster1
cluster1.zk.list=bigdata101:2181,bigdata102:2181,bigdata103:2181/kafka_2.4
######################################
# kafka offset storage
######################################
cluster1.kafka.eagle.offset.storage=kafka
######################################
# enable kafka metrics
######################################
kafka.eagle.metrics.charts=true
kafka.eagle.sql.fix.error=false
######################################
# kafka jdbc driver address
######################################
kafka.eagle.driver=com.mysql.jdbc.Driver
kafka.eagle.url=jdbc:mysql://bigdata101:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
kafka.eagle.username=root
kafka.eagle.password=Dj123456+
9.添加环境变量
export KE_HOME=/opt/module/eagle
export PATH=$PATH:$KE_HOME/bin
注意:source /etc/profile
10.启动
[later@bigdata101 eagle]$ bin/ke.sh start
… …
… …
*
Kafka Eagle Service has started success.
Welcome, Now you can visit ‘http://192.168.1.12:8048/ke‘
Account:admin ,Password:123456
**
*
[later@bigdata101 eagle]$
注意:启动之前需要先启动ZK以及KAFKA
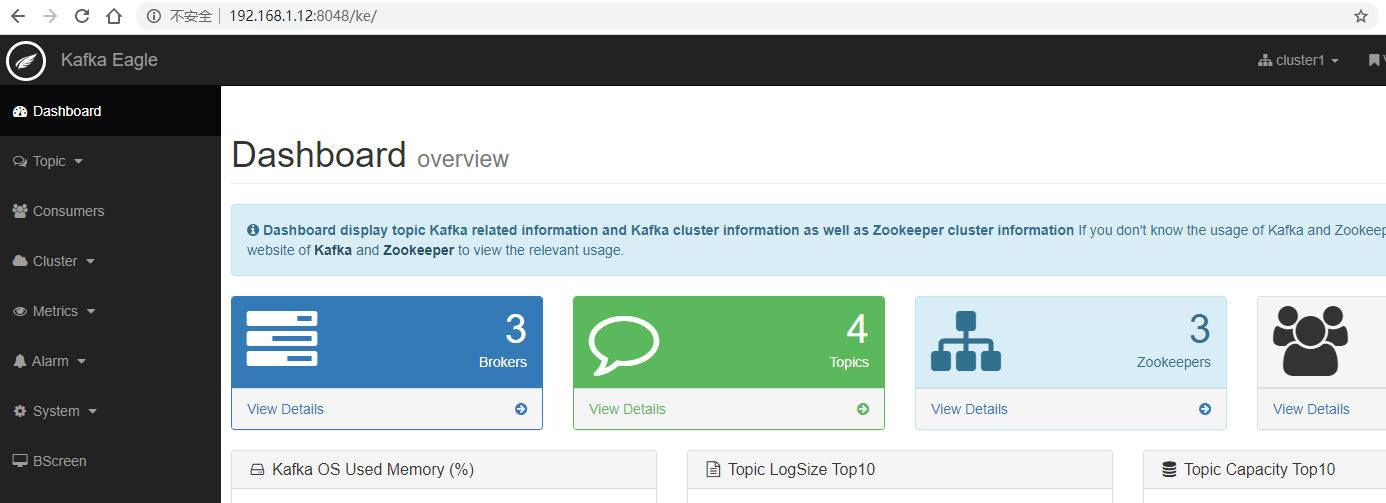
11.登录页面查看监控数据
http://192.168.1.12:8048/ke
 # 10 安装Spark2.4.5
(1)上传并解压
# 10 安装Spark2.4.5
(1)上传并解压 [later@bigdata101 software]# tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz -C /opt/module/
(2)修改spark.env
[later@bigdata101 software]# cd /opt/module/spark-2.4.5-bin-hadoop2.7/conf/
[later@bigdata101 conf]# mv spark-env.sh.template spark-env.sh
[later@bigdata101 conf]# vim spark-env.sh
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
(3)将hive-stie.xml复制导spark的conf目录下
[later@bigdata101 conf]# cp /opt/module/apache-hive-3.1.2-bin/conf/hive-site.xml /opt/module/spark-2.4.5-bin-hadoop2.7/conf/
(4)配置spark环境变量
[later@bigdata101 conf]# vim /etc/profile
#SPARK_HOME
export SPARK_HOME=/opt/module/spark-2.4.5-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
[later@bigdata101 conf]# source /etc/profile
(5)配置日志服务器,修改yarn-site.xml
[later@bigdata101 module]# cd /opt/module/hadoop-3.1.3/etc/hadoop
[later@bigdata101 hadoop]# vim yarn-site.xml
修改mapred-site.xml
mapreduce.framework.name
yarn
指定mr框架为yarn方式
mapreduce.jobhistory.address
bigdata101:10020
历史服务器端口号
mapreduce.jobhistory.webapp.address
bigdata101:19888
历史服务器的WEB UI端口号
(6)分发yarn-site.xml
[later@bigdata101 hadoop]# scp yarn-site.xml bigdata101:/opt/module/hadoop-3.1.3/etc/hadoop/
[later@bigdata101 hadoop]# scp yarn-site.xml bigdata102:/opt/module/hadoop-3.1.3/etc/hadoop/
[later@bigdata101 hadoop]# scp mapred-site.xml bigdata101:/opt/module/hadoop-3.1.3/etc/hadoop/
mapred-site.xml
[later@bigdata101 hadoop]# scp mapred-site.xml bigdata102:/opt/module/hadoop-3.1.3/etc/hadoop/
mapred-site.xml
(7)启动hadoop历史服务器
[later@bigdata101 hadoop]# mr-jobhistory-daemon.sh start historyserver
(8)配置spark-default.conf
[later@bigdata101 hadoop]# cd /opt/module/spark-2.4.5-bin-hadoop2.7/conf/
[later@bigdata101 conf]# mv spark-defaults.conf.template spark-defaults.conf
[later@bigdata101 conf]# vim spark-defaults.conf
spark.yarn.historyServer.address=bigdata101:18080
spark.yarn.historyServer.allowTracking=true
spark.eventLog.dir=hdfs://mycluster/spark_historylog
spark.eventLog.enabled=true
spark.history.fs.logDirectory=hdfs://mycluster/spark_historylog启动spark历史服务节点,(我将spark分发到了3台机器上,非必须步骤)
[later@bigdata101 hadoop]# start-history-server.sh
11 安装hbase
1 HBase的解压
[later@bigdata101 software]$ tar -zxvf hbase-2.0.0-bin.tar.gz -C /opt/module/
2 HBase的配置文件
修改HBase对应的配置文件。
1)hbase-env.sh修改内容:
export JAVA_HOME=/opt/module/jdk1.8.0_211
export HBASE_MANAGES_ZK=false
2)hbase-site.xml修改内容:
<property><br /> <name>hbase.cluster.distributed</name><br /> <value>true</value><br /> </property>
<property> <br /> <name>hbase.zookeeper.quorum</name><br /> <value>bigdata101,bigdata102,bigdata103</value><br /> </property><property> <br /> <name>hbase.zookeeper.property.dataDir</name><br /> <value>/opt/module/apache-zookeeper-3.5.7-bin/zkData</value><br /> </property><property><br /> <name>hbase.unsafe.stream.capability.enforce</name><br /> <value>false</value><br /> </property><br /></configuration><br />3)regionservers:(在hbase2.X版本中,HMaster节点不能启动HRegionServer)<br />bigdata102<br />bigdata103<br />4)软连接hadoop配置文件到HBase:<br />[later@bigdata101 module]$ ln -s /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml /opt/module/hbase-2.0.0/conf/core-site.xml<br />[later@bigdata101 module]$ ln -s /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml /opt/module/hbase-2.0.0/conf/hdfs-site.xml
3 HBase远程发送到其他集群
[later@bigdata101 module]$ xsync.sh hbase-2.0.0/
4 HBase服务的启动
1.启动方式
[later@bigdata101 hbase]$ bin/start-hbase.sh
对应的停止服务:
[later@bigdata101 hbase]$ bin/stop-hbase.sh
提示:如果集群之间的节点时间不同步,会导致regionserver无法启动,抛出ClockOutOfSyncException异常。
修复提示:
a、同步时间服务
请参看帮助文档:《大数据技术之Hadoop入门》
b、属性:hbase.master.maxclockskew设置更大的值
5 查看HBase页面
启动成功后,可以通过“host:port”的方式来访问HBase管理页面,例如:
http://bigdata101:16010
12 安装Kylin(之后再安装phoenix)
1)将apache-kylin-2.6.5-bin-hadoop3.tar.gz上传到Linux
2)解压apache-kylin-2.6.5-bin-hadoop3.tar.gz到/opt/module
[later@bigdata101 sorfware]$ tar -zxvf apache-kylin-2.6.5-bin-hadoop3.tar.gz -C /opt/module/
注意:
1、需要在/etc/profile文件中配置HADOOP_HOME,HIVE_HOME,HBASE_HOME并source使其生效。
2、Kylin的新版本不在自带spark,所以在启动kylin的时候需要指定自己的spark_home,或者下载配套的spark,官网有解释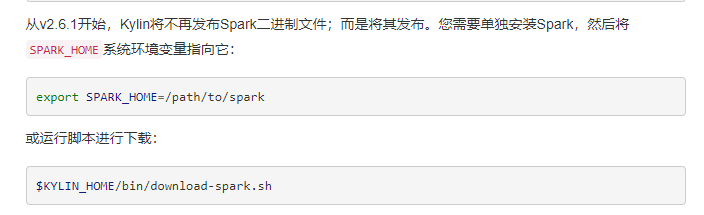
export SPARK_HOME=/path/to/spark
或运行脚本进行下载:
$KYLIN_HOME/bin/download-spark.sh
3)启动
[later@bigdata101 kylin]$ bin/kylin.sh start
启动之后查看各个节点进程:
——————————- hadoop102 ————————
3360 JobHistoryServer
31425 HMaster
3282 NodeManager
3026 DataNode
53283 Jps
2886 NameNode
44007 RunJar
2728 QuorumPeerMain
31566 HRegionServer
——————————- hadoop103 ————————
5040 HMaster
2864 ResourceManager
9729 Jps
2657 QuorumPeerMain
4946 HRegionServer
2979 NodeManager
2727 DataNode
——————————- hadoop104 ————————
4688 HRegionServer
2900 NodeManager
9848 Jps
2636 QuorumPeerMain
2700 DataNode
2815 SecondaryNameNode
注意:启动Kylin之前要保证HDFS,YARN,ZK,HBASE相关进程是正常运行的。
在http://bigdata101:7070/kylin查看Web页面(大概1分钟左右)
用户名为:ADMIN,密码为:KYLIN(系统已填)
4)关闭
[later@bigdata101 kylin]$ bin/kylin.sh stop
5)踩坑
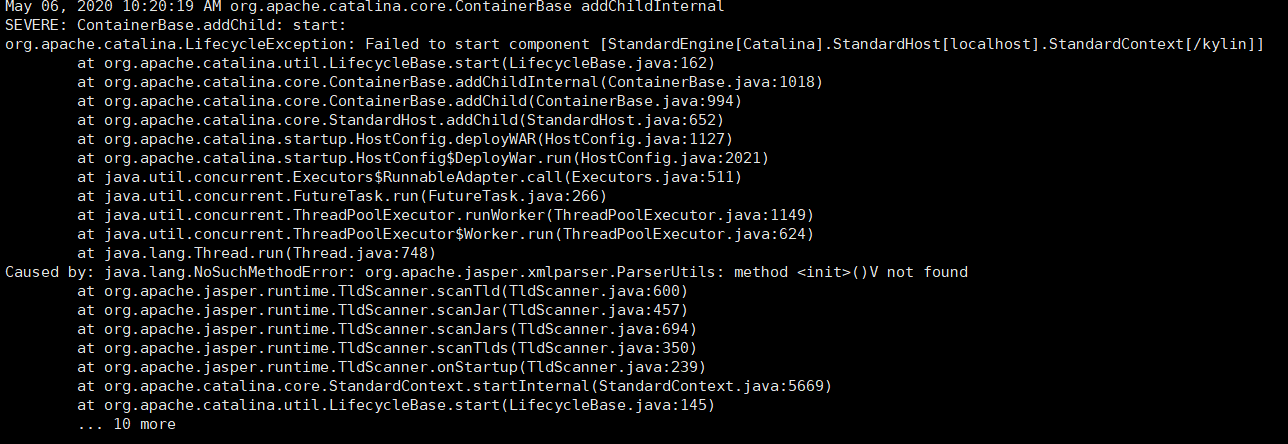
1、安装kylin,如果不能访问http://bigdata101:7070/kylin,先看kylin的日志
如果为缺spark相关的jar包,检查spark_home用的是自己的spark还是系统推荐下载的,使用官网推荐的spark就可以了
- Kylin启动时Tomcat的kylin.war包报错,7070后台无法访问,这种就是版本不匹配,kylin有匹配hadoop2和hadoop3的版本
13 安装Phoenix
1)上传并解压tar包
[later@bigdata101 module]$ tar -zxvf /opt/software/apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz -C /opt/module
- 复制server包并拷贝到各个节点的hbase/lib
只传这一个jar包就可以了,别的不需要
[later@bigdata101 module]$ cd module/apache-phoenix-5.0.0-HBase-2.0-bin/
[later@bigdata101 phoenix]$ cp phoenix-5.0.0-HBase-2.0-server.jar /opt/module/hbase-2.0.0/lib/
[later@bigdata101 phoenix]$ scp phoenix-5.0.0-HBase-2.0-server.jar bigdata102:/opt/module/hbase-2.0.0/lib/
[later@bigdata101 phoenix]$ scp phoenix-5.0.0-HBase-2.0-server.jar bigdata103:/opt/module/hbase-2.0.0/lib/
3)配置环境变量
#phoenix
export PHOENIX_HOME=/opt/module/apache-phoenix-5.0.0-HBase-2.0-bin
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export PATH=$PATH:$PHOENIX_HOME/bin
4)启动Pheonix
[later@hadoop101 phoenix]$ bin/sqlline.py bigdata101,bigdata102,bigdata103:2181
14 安装Flume
1)将apache-flume-1.9.0-bin.tar.gz上传到linux的/opt/software目录下
2)解压apache-flume-1.9.0-bin.tar.gz到/opt/module/目录下
[later@bigdata101 software]$ tar -zxf apache-flume-1.9.0-bin.tar.gz -C /opt/module/
3)将apache-flume-1.9.0-bin/conf下的flume-env.sh.template文件修改为flume-env.sh,并配置flume-env.sh文件
[later@bigdata101 conf]$ mv flume-env.sh.template flume-env.sh
[later@bigdata101 conf]$ vi flume-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
4)在/opt/module/flume/目录下创建job文件夹
[later@bigdata101 flume]$ mkdir job
[later@bigdata101 job]$ vim file-flume-kafka.conf(采集日志)
a1.sources=r1
a1.channels=c1 c2
configure source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /opt/module/apache-flume-1.9.0-bin/position/log_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /tmp/logs/app.+
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1 c2
interceptor
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = com.dianjue.flume.MyInterceptor$Builders
a1.sources.r1.interceptors.i2.type = com.dianjue.flume.TypeInterceptor$BuilderType
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.type = replicating
a1.sources.r1.selector.header = topic
a1.sources.r1.selector.mapping.topic_start = c1
a1.sources.r1.selector.mapping.topic_event = c2
configure channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = bigdata101:9092,bigdata102:9092,bigdata103:9092
a1.channels.c1.kafka.topic = topic_start
a1.channels.c1.parseAsFlumeEvent = false
a1.channels.c1.kafka.consumer.group.id = flume-consumer
a1.channels.c2.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c2.kafka.bootstrap.servers = bigdata101:9092,bigdata102:9092,bigdata103:9092
a1.channels.c2.kafka.topic = topic_event
a1.channels.c2.parseAsFlumeEvent = false
a1.channels.c2.kafka.consumer.group.id = flume-consumer
- 在bigdata102把日志从kafka发到hdfs,所以把flume发送到bigdata102
[later@bigdata101 module]$ scp apache-flume-1.9.0-bin/ bigdata102:/opt/module
[later@bigdata101 job]$ vim kafka-flume-hdfs.conf(发送日志)
注意这里要使用a2,因为这个脚本需要和采集日志脚本同时启动,避免冲突
## 组件
a2.sources=r1 r2
a2.channels=c1 c2
a2.sinks=k1 k2
source1
a2.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a2.sources.r1.batchSize = 5000
a2.sources.r1.batchDurationMillis = 2000
a2.sources.r1.kafka.bootstrap.servers = bigdata101:9092,bigdata102:9092,bigdata103:9092
a2.sources.r1.kafka.topics=topic_start
source2
a2.sources.r2.type = org.apache.flume.source.kafka.KafkaSource
a2.sources.r2.batchSize = 5000
a2.sources.r2.batchDurationMillis = 2000
a2.sources.r2.kafka.bootstrap.servers = bigdata101:9092,bigdata102:9092,bigdata103:9092
a2.sources.r2.kafka.topics=topic_event
channel1
a2.channels.c1.type = file
a2.channels.c1.checkpointDir = /opt/module/apache-flume-1.9.0-bin/checkpoint/behavior1
a2.channels.c1.dataDirs = /opt/module/apache-flume-1.9.0-bin/data/behavior1
a2.channels.c1.maxFileSize = 2146435071
a2.channels.c1.keep-alive = 6
a2.channels.c1.type = memory
#a2.channels.c1.capacity = 1000000
#a2.channels.c1.transactionCapacity = 10000
#a2.channels.c1.byteCapacityBufferPercentage = 20
#a2.channels.c1.byteCapacity = 800000
a2.channels.c2.type = memory
#a2.channels.c2.capacity = 1000000
#a2.channels.c2.transactionCapacity = 10000
#a2.channels.c2.byteCapacityBufferPercentage = 20
#a2.channels.c2.byteCapacity = 800000
## channel2
a2.channels.c2.type = file
a2.channels.c2.checkpointDir = /opt/module/apache-flume-1.9.0-bin/checkpoint/behavior2
a2.channels.c2.dataDirs = /opt/module/apache-flume-1.9.0-bin/data/behavior2/
a2.channels.c2.maxFileSize = 2146435071
a2.channels.c2.capacity = 1000000
a2.channels.c2.keep-alive = 6
sink1
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = hdfs://bigdata101:8020/djBigData/origin_data/log/topic_start/%Y-%m-%d
a2.sinks.k1.hdfs.filePrefix = logstart-
a2.sinks.k1.hdfs.round = true
a2.sinks.k1.hdfs.roundValue = 10
a2.sinks.k1.hdfs.roundUnit = second
sink2
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://bigdata101:8020/djBigData/origin_data/log/topic_event/%Y-%m-%d
a2.sinks.k2.hdfs.filePrefix = logevent-
a2.sinks.k2.hdfs.round = true
a2.sinks.k2.hdfs.roundValue = 10
a2.sinks.k2.hdfs.roundUnit = second
不要产生大量小文件
a2.sinks.k1.hdfs.rollInterval = 10
a2.sinks.k1.hdfs.rollSize = 134217728
a2.sinks.k1.hdfs.rollCount = 0
a2.sinks.k2.hdfs.rollInterval = 10
a2.sinks.k2.hdfs.rollSize = 134217728
a2.sinks.k2.hdfs.rollCount = 0
控制输出文件是原生文件。
a2.sinks.k1.hdfs.fileType = CompressedStream
a2.sinks.k2.hdfs.fileType = CompressedStream
a2.sinks.k1.hdfs.codeC = lzop
a2.sinks.k2.hdfs.codeC = lzop
拼装
a2.sources.r1.channels = c1
a2.sinks.k1.channel= c1
a2.sources.r2.channels = c2
a2.sinks.k2.channel= c2
在这里要使用lzop压缩的话,还需要先配置lzo,因为本身的hadoop不支持lzo压缩,详见编译安装lzo
6)采集日志脚本f1.sh
#! /bin/bash
case $1 in
“start”){
for i in bigdata101
do
echo “ ————启动 $i 采集flume———-“
ssh $i “nohup /opt/module/apache-flume-1.9.0-bin/bin/flume-ng agent —conf-file /opt/module/apache-flume-1.9.0-bin/job/file-flume-kafka.conf —name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/apache-flume-1.9.0-bin/test1 2>&1 &”
done
};;
“stop”){
for i in bigdata101
do
echo “ ————停止 $i 采集flume———-“
ssh $i “ps -ef | grep file-flume-kafka | grep -v grep |awk ‘{print \$2}’ | xargs kill”
done
};;
esac
7)发送日志脚本f2.sh
#! /bin/bash
case $1 in
“start”){
for i in bigdata102
do
echo “ ————启动 $i 采集flume———-“
ssh $i “nohup /opt/module/apache-flume-1.9.0-bin/bin/flume-ng agent —conf conf/ —conf-file /opt/module/apache-flume-1.9.0-bin/job/kafka-flume-hdfs.conf —name a2 -Dflume.root.logger=INFO,LOGFILE>/opt/module/apache-flume-1.9.0-bin/test1 2>&1 &”
done
};;
“stop”){
for i in bigdata102
do
echo “ ————停止 $i 采集flume———-“
ssh $i “ps -ef | grep kafka-flume-hdfs | grep -v grep |awk ‘{print \$2}’ | xargs kill”
done
};;
esac
15 安装Datax (Python3.6+MySql 8)
16 解压
17 把mysql-connector-java-8.0.19.jar分别复制到下面
/datax/plugin/reader/mysqlreader/libs
datax/plugin/writer/mysqlwriter/libs
18 把/datax/bin 下三个文件替换,主要是为了Python3.6执行,如果是2版本可以不用
19 运行自检脚本(注意路径)
Python3.6 datax.py datax/job/job.json
20 增加kafka组件
21 安装Canal + UI + RDS_MySQL
1 安装准备
canal.admin-1.1.4.tar.gz
canal.deployer-1.1.4.tar.gz
下载地址 https://github.com/alibaba/canal/releases/tag/canal-1.1.4/
2 安装canal-admin
A 创建文件夹与安装
mkdir canal_admin
tar -zxvf canal.admin-1.1.4.tar.gz -C /export/servers/canal_admin
B 修改配置application.yml
server:
port: 8899
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: bigdata101:3306
database: canal_manager
username: root
password: Dj123456+
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin
adminPasswd: 123456
C 执行/canal_admin/conf下的sql语句
D 启动canal-admin
canal_admin/bin
sh startup.sh
点击集群管理,新建集群,配置zk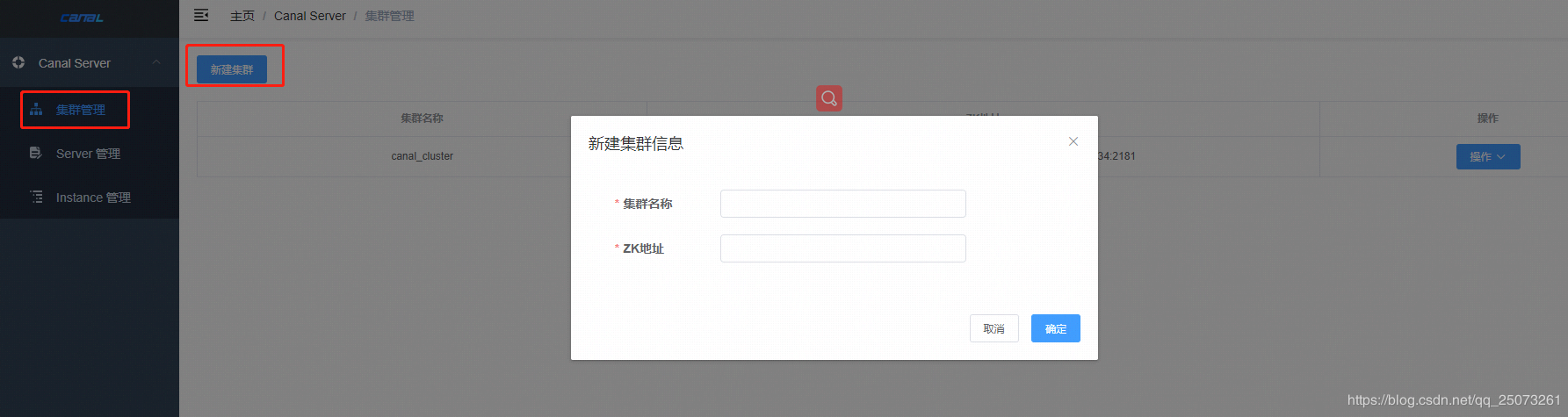
选择编辑集群配置,下拉选择主配置
################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
canal.user = canal
canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
canal admin config
canal.admin.manager = bigdata101:8899
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = xxxxxxx
canal.zkServers = 192.168.1.96:2181,192.168.1.12:2181,192.168.1.14:2181
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, RocketMQ
canal.serverMode = kafka
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
binlog ddl isolation
canal.instance.get.ddl.isolation = false
parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = 123456
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
###########################################
######### destinations #############
#################################################
canal.destinations = user_topic
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = manager
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
#canal.instance.global.spring.xml = classpath:spring/file-instance.xml
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
############################################
######### MQ #############
##################################################
canal.mq.servers = 192.168.1.96:9092,192.168.1.12:9092,192.168.1.14:9092
canal.mq.retries = 0
canal.mq.batchSize = 16384
canal.mq.maxRequestSize = 1048576
canal.mq.lingerMs = 100
canal.mq.bufferMemory = 33554432
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
canal.mq.flatMessage = true
canal.mq.compressionType = none
canal.mq.acks = all
#canal.mq.properties. =
canal.mq.producerGroup = test
# Set this value to “cloud”, if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
# aliyun mq namespace
#canal.mq.namespace =
############################################
######### Kafka Kerberos Info #############
##################################################
canal.mq.kafka.kerberos.enable = false
canal.mq.kafka.kerberos.krb5FilePath = “../conf/kerberos/krb5.conf”
canal.mq.kafka.kerberos.jaasFilePath = “../conf/kerberos/jaas.conf”
3安装canal服务端
mkdir canal
tar -zxvf canal.deployer-1.1.4.tar.gz -C /export/servers/canal
将canal_local.properties文件内容覆盖到canal.properties,并编辑canal.properties
register ip
canal.register.ip =
canal admin config
canal.admin.manager = bigdata101:8899
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = xxxxx
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster = canal_cluster
分别启动服务器上的canal服务
/canal/bin
sh startup.sh
刷新浏览器,点击server管理,发现已自动注入三个实例
4 创建实时同步任务
点击instance管理,新建instance,输入instance名称user_topic,选择canal_cluster集群,点击后面的载入模板,并修改
#################################################
## mysql serverId , v1.0.26+ will autoGen
canal.instance.mysql.slaveId=23
enable gtid use true/false
canal.instance.gtidon=false
position info
canal.instance.master.address=ddddd:3306
canal.instance.master.journal.name=
canal.instance.master.position=0
canal.instance.master.timestamp=
canal.instance.master.gtid=
rds oss binlog
canal.instance.rds.accesskey=LTAI4Gxxxxxx2jDAYZFk
canal.instance.rds.secretkey=G1fyU1fD62xxxxxxxxXvdMQtieqZ
canal.instance.rds.instanceId=rm-uf68kxxxxxx6h0no3
table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
username/password
canal.instance.dbUsername=appuser
canal.instance.dbPassword=Ctm56@Long
canal.instance.defaultDatabaseName = test
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
table regex
canal.instance.filter.regex=test\.student
# table black regex
canal.instance.filter.black.regex=
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
mq config
canal.mq.topic=user_topic
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\..,.\..*
#canal.mq.partition=0
# hash partition config
canal.mq.partitionsNum=1
canal.mq.partitionHash=test.student:id
22 编译与安装
1安装maven+git(配置编译环境)
maven(安装maven,配置环境变量,修改sitting.xml加阿里云镜像)
# tar -zxvf apache-maven-3.6.1-bin.tar.gz
sudo vim /etc/profile.d/maven.sh
export MAVEN_HOME=/opt/software/apache-maven-3.6.1
export PATH=$PATH:$MAVEN_HOME/bin
MAVEN_OPTS=-Xmx2048m
export JAVA_HOME MAVEN_HOME MAVEN_OPTS JAVA_BIN PATH CLASSPATH
修改maven源为阿里源或网易源
# pwd
/opt/software/apache-maven-3.6.1/conf
# vim settings.xml
2编译安装lzo
需要安装
gcc-c++
zlib-devel
autoconf
automake
libtool
通过yum安装即可,yum -y install gcc-c++ lzo-devel zlib-devel autoconf automake libtool
- 下载、安装并编译LZO
wget http://www.oberhumer.com/opensource/lzo/download/lzo-2.10.tar.gz
tar -zxvf lzo-2.10.tar.gz
cd lzo-2.10
./configure -prefix=/usr/local/hadoop/lzo/
make
make install
- 编译hadoop-lzo源码
2.1 下载hadoop-lzo的源码,下载地址:https://github.com/twitter/hadoop-lzo/archive/master.zip
2.2 解压之后,修改pom.xml
2.3 声明两个临时环境变量
export C_INCLUDE_PATH=/usr/local/hadoop/lzo/include
export LIBRARY_PATH=/usr/local/hadoop/lzo/lib
2.4 编译
进入hadoop-lzo-master,执行maven编译命令
mvn package -Dmaven.test.skip=true
2.5 进入target,hadoop-lzo-0.4.21-SNAPSHOT.jar 即编译成功的hadoop-lzo组件
2.6)将编译好后的hadoop-lzo-0.4.20.jar 放入hadoop-3.1.3/share/hadoop/common/
[later@bigdata101 common]$ pwd
/opt/module/hadoop-3.1.3/share/hadoop/common
[later@bigdata101 common]$ ls
hadoop-lzo-0.4.21-SNAPSHOT.jar
3)同步hadoop-lzo-0.4.21-SNAPSHOT.jar到bigdata102、bigdata103
[later@bigdata101 common]$ xsync.sh hadoop-lzo-0.4.21-SNAPSHOT.jar
4)core-site.xml增加配置支持LZO压缩
<?xml version=”1.0” encoding=”UTF-8”?>
<?xml-stylesheet type=”text/xsl” href=”configuration.xsl”?>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
5)同步core-site.xml到bigdata102、bigdata103
[later@bigdata101 hadoop]$ xsync.sh core-site.xml
6)启动及查看集群
[later@bigdata101 hadoop-3.1.3]$ hdya.sh start ## 3编译安装Azkaban(MySql 8版本) ### 3.1修改源码 #### 3.1.1 build.gradle中
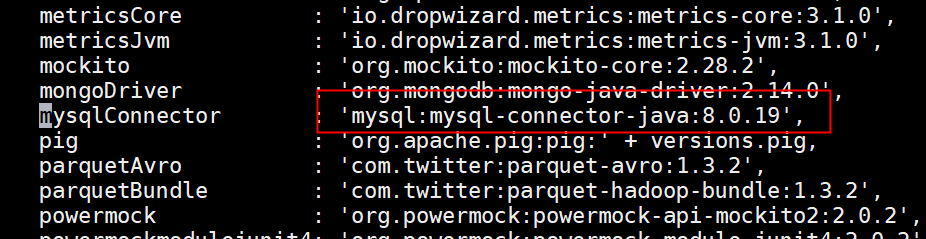 #### 3.1.2 /azkaban-3.88.0/azkaban-db/src/main/java/azkaban/db/MySQLDataSource.java
#### 3.1.2 /azkaban-3.88.0/azkaban-db/src/main/java/azkaban/db/MySQLDataSource.java
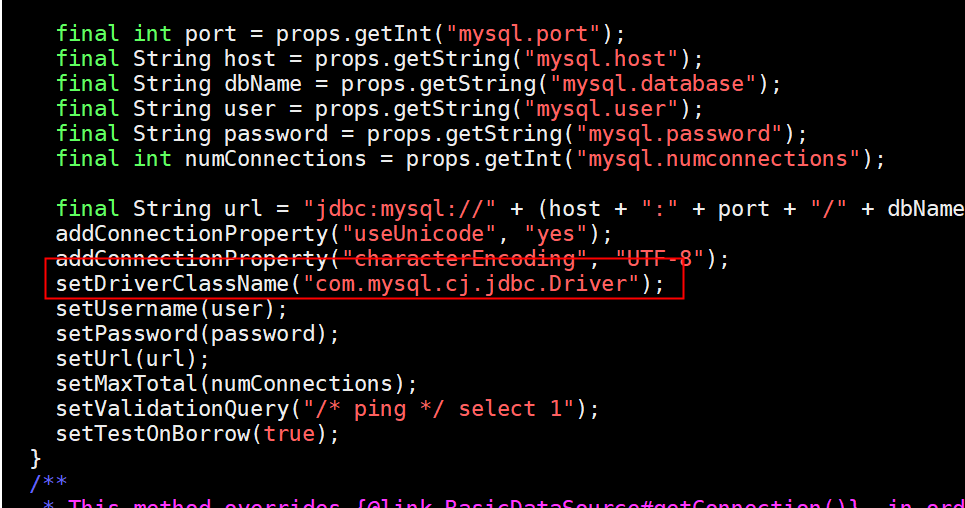 #### 3.1.3 /azkaban-3.88.0/azkaban-common/src/main/java/azkaban/jobExecutor/ProcessJob.java
final boolean isExecuteAsUser = this.sysProps.getBoolean(EXECUTE_AS_USER, true); 里面的true修改为false
### 3.2安装
1、编译成tar包
#### 3.1.3 /azkaban-3.88.0/azkaban-common/src/main/java/azkaban/jobExecutor/ProcessJob.java
final boolean isExecuteAsUser = this.sysProps.getBoolean(EXECUTE_AS_USER, true); 里面的true修改为false
### 3.2安装
1、编译成tar包[root@user azkaban]# cd /opt/azkaban/azkaban-3.88.0/
[root@user azkaban-3.88.0]# ./gradlew distTar #最后会显示:BUILD SUCCESSFUL (如果不是第一次构建需要先clean,执行下面)
[root@user azkaban-3.88.0]# ./gradlew clean 2、把相应的tar包复制出来
[root@user azkaban-3.88.0]# mkdir /usr/local/src/azkaban [root@user azkaban-3.88.0]# cp azkaban-db/build/distributions/azkaban-db-0.1.0-SNAPSHOT.tar.gz /usr/local/src/azkaban/packages [root@user azkaban-3.88.0]# cp azkaban-exec-server/build/distributions/azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz /usr/local/src/azkaban/packages [root@user azkaban-3.88.0]# cp azkaban-solo-server/build/distributions/azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz /usr/local/src/azkaban/packages [root@user azkaban-3.88.0]# cp azkaban-hadoop-security-plugin/build/distributions/azkaban-hadoop-security-plugin-0.1.0-SNAPSHOT.tar.gz /usr/local/src/azkaban/packages [root@user azkaban-3.88.0]# cp azkaban-web-server/build/distributions/azkaban-web-server-0.1.0-SNAPSHOT.tar.gz /usr/local/src/azkaban/packages 3、解压tar包
[root@user azkaban-3.88.0]# cd /usr/local/src/azkaban/ [root@userstack azkaban]# tar zxf packages/azkaban-web-server-0.1.0-SNAPSHOT.tar.gz -C . [root@userstack azkaban]# tar zxf packages/azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz -C . [root@userstack azkaban]# tar zxf packages/azkaban-db-0.1.0-SNAPSHOT.tar.gz -C . [root@userstack azkaban]# tar zxf packages/azkaban-hadoop-security-plugin-0.1.0-SNAPSHOT.tar.gz -C . [root@userstack azkaban]# tar zxf packages/azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz -C . [root@userstack azkaban]# ls
azkaban-db-0.1.0-SNAPSHOT
azkaban-hadoop-security-plugin-0.1.0-SNAPSHOT
azkaban-web-server-0.1.0-SNAPSHOT
azkaban-exec-server-0.1.0-SNAPSHOT
azkaban-solo-server-0.1.0-SNAPSHOT
Packages ### 3.3创建数据库及导入数据结构 这里使用的mysql:
mysql> CREATE DATABASE azkaban; mysql> use azkaban; mysql> source /opt/module//azkaban/azkaban-db-0.1.0-SNAPSHOT/create-all-sql-0.1.0-SNAPSHOT.sql mysql> show tables;
+——————————————-+
| Tables_in_azkaban |
+——————————————-+
| QRTZ_BLOB_TRIGGERS |
| QRTZ_CALENDARS |
| QRTZ_CRON_TRIGGERS |
| QRTZ_FIRED_TRIGGERS |
| QRTZ_JOB_DETAILS |
| QRTZ_LOCKS |
…… ### 3.4配置keystore [root@user azkaban]# cd azkaban-web-server-0.1.0-SNAPSHOT/ [root@user azkaban-web-server-0.1.0-SNAPSHOT]# keytool -keystore keystore -alias jetty -genkey -keyalg RSA
输入密钥库口令: #123456
再次输入新口令: #123456
您的名字与姓氏是什么? #直接回车
[Unknown]:
您的组织单位名称是什么? #直接回车
[Unknown]:
您的组织名称是什么? #直接回车
[Unknown]:
您所在的城市或区域名称是什么? #直接回车
[Unknown]:
您所在的省/市/自治区名称是什么? #直接回车
[Unknown]
该单位的双字母国家/地区代码是什么? #输入 CN
[Unknown]: CN
CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=CN是否正确?
[否]: Y #输入 Y 输入
(如果和密钥库口令相同, 按回车): #直接回车 Warning:
JKS 密钥库使用专用格式。建议使用 “keytool -importkeystore -srckeystore keystore -destkeystore keystore -deststoretype pkcs12” 迁移到行业标准格式 PKCS12。 —————-
完成上述工作后,将在当前目录生成 keystore 证书文件,将keystore 考贝到 azkaban web服务器根目录中,由于我目前在web server目录中,就不用复制了;
[root@user azkaban-web-server-0.1.0-SNAPSHOT]# ls
bin conf keystore lib web ### 3.5配置文件 #### 3.5.1 azkaban web服务器配置 # Azkaban Personalization Settings
azkaban.name=test
azkaban.label=test
azkaban.color=#FF3601
azkaban.default.servlet.path=/index
web.resource.dir=/usr/local/src/azkaban/azkaban-web-server-0.1.0-SNAPSHOT/web/
default.timezone.id=Asia/Shanghai# Azkaban UserManager class
user.manager.class=azkaban.user.XmlUserManager
user.manager.xml.file=/usr/local/src/azkaban/azkaban-web-server-0.1.0-SNAPSHOT/conf/azkaban-users.xml# Loader for projects
executor.global.properties=/usr/local/src/azkaban/azkaban-web-server-0.1.0-SNAPSHOT/conf/global.properties
azkaban.project.dir=projects# Velocity dev mode
velocity.dev.mode=false# Azkaban Jetty server properties.
jetty.maxThreads=25
jetty.port=8081
jetty.ssl.port=8443
jetty.keystore=/usr/local/src/azkaban/azkaban-web-server-0.1.0-SNAPSHOT/keystore
jetty.password=123456
jetty.keypassword=123456
jetty.truststore=/usr/local/src/azkaban/azkaban-web-server-0.1.0-SNAPSHOT/keystore
jetty.trustpassword=123456# Project Manager settings
#project.temp.dir=/temp
#project.version.retention=3# Azkaban Executor settings
executor.port=12321# mail settings
mail.sender=
mail.host=
job.failure.email=
job.success.email=lockdown.create.projects=false
cache.directory=cache# JMX stats
jetty.connector.stats=true
executor.connector.stats=true# Azkaban plugin settings
azkaban.jobtype.plugin.dir=/usr/local/src/azkaban/azkaban-web-server-0.1.0-SNAPSHOT/plugins/jobtypes# Azkaban mysql settings by default. Users should configure their own username and password.
database.type=mysql
mysql.port=3306
mysql.host=172.16.0.109
mysql.database=azkaban
mysql.user=root
mysql.password=123456
mysql.numconnections=100#Multiple Executor
azkaban.use.multiple.executors=true
azkaban.executorselector.filters=StaticRemainingFlowSize,MinimumFreeMemory,CpuStatus
azkaban.executorselector.comparator.NumberOfAssignedFlowComparator=1
azkaban.executorselector.comparator.Memory=1 #### 3.5.2 azkaban-users.xml
添加到下面
default.timezone.id=Asia/Shanghai # Azkaban UserManager class
# Loader for projects
executor.global.properties=/usr/local/src/azkaban/azkaban-exec-server-0.1.0-SNAPSHOT/conf/global.properties
azkaban.project.dir=projects
# Velocity dev mode
velocity.dev.mode=false
# Azkaban Jetty server properties. # mail settings
lockdown.create.projects=false
cache.directory=cache # JMX stats
jetty.connector.stats=true
executor.connector.stats=true # Azkaban Executor settings
executor.maxThreads=50
executor.flow.threads=30 # 这里添加一个端口配置
executor.port=12321
azkaban.execution.dir=executions # Azkaban plugin settings
azkaban.jobtype.plugin.dir=/usr/local/src/azkaban/azkaban-exec-server-0.1.0-SNAPSHOT/plugins/jobtypes
# Azkaban mysql settings by default. Users should configure their own username and password.
database.type=mysql
mysql.port=3306
mysql.host=172.16.0.109
mysql.database=azkaban
mysql.user=root
mysql.password=123456
mysql.numconnections=100 azkaban 启动脚本
#!/bin/bash
case $1 in
“start”){
nohup /usr/local/app/azkaban/executor/bin/start-exec.sh
sleep 5s
mysql -uroot -pDj123456+ -e ‘update azkaban.executors set active=1;’
sleep 5s
nohup /usr/local/app/azkaban/server/bin/start-web.sh
};;
“stop”){
/usr/local/app/azkaban/executor/bin/shutdown-exec.sh
/usr/local/app/azkaban/server/bin/shutdown-web.sh
};;
esac 如果启动报错:executors is no active 需要在mysql中执行下面语句 update azkaban.executors set active=1; ## 4 Hive on Spark ### 4.1 Hive on Spark编译 1)从官网下载Spark源码并解压
下载地址: https://www.apache.org/dyn/closer.lua/spark/spark-2.4.5/spark-2.4.5.tgz
2)上传并解压spark
3)进入spark解压后的目录
4)执行编译命令
[later@hadoop102 spark-2.4.5]$ ./dev/make-distribution.sh —name without-hive —tgz -Pyarn -Phadoop-3.1 -Dhadoop.version=3.1.3 -Pparquet-provided -Porc-provided -Phadoop-provided 1. 等待编译完成,spark-2.4.5-bin-without-hive.tgz为最终文件 ### 4.2 Hive on Spark配置 1)解压spark-2.4.5-bin-without-hive.tgz
[later@hadoop102 software]$ tar -zxf /opt/software/spark-2.4.5-bin-without-hive.tgz -C /opt/module
[later@hadoop102 software]$ mv /opt/module/spark-2.4.5-bin-without-hive /opt/module/spark
2)配置SPARK_HOME环境变量
[later@hadoop102 software]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin
source 使其生效
[later@hadoop102 software]$ source /etc/profile.d/my_env.sh
3)配置spark运行环境
[later@hadoop102 software]$ mv /opt/module/spark/conf/spark-env.sh.template /opt/module/spark/conf/spark-env.sh
[later@hadoop102 software]$ vim /opt/module/spark/conf/spark-env.sh
添加如下内容
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
4)新建spark配置文件
[later@hadoop102 software]$ vim /opt/module/hive/conf/spark-defaults.conf
添加如下内容
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
5)6)步可以省略,发现比不好使,可直接第7)步
5)在HDFS创建如下路径
[later@hadoop102 software]$ hadoop fs -mkdir /spark-history
6)上传Spark依赖到HDFS
[later@hadoop102 software]$ hadoop fs -mkdir /spark-jars [later@hadoop102 software]$ hadoop fs -put /opt/module/spark/jars/ /spark-jars
7)hive-env.sh 添加 export SPARK_HOME=/opt/module/spark-2.4.5-bin-without-hive
export SPARK_JARS=””
for jar in
ls $SPARK_HOME/jars; doexport SPARK_JARS=$SPARK_JARS:$SPARK_HOME/jars/$jar
done
export HIVE_AUX_JARS_PATH=/opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.21-SNAPSHOT.jar$SPARK_JARS 8)修改hive-site.xml
<!—
—>
注意:hive.spark.client.connect.timeout的默认值是1000ms,如果执行hive的insert语句时,抛如下异常,可以调大该参数到10000ms
FAILED: SemanticException Failed to get a spark session: org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create Spark client for Spark session d9e0224c-3d14-4bf4-95bc-ee3ec56df48e
4.3 Hive on Spark测试
1)启动Hive
[later@hadoop102 hive]$ bin/hive
2)创建表
hive (default)> create table student(
id int,
name string);
3)向表中插入数据
hive (default)> insert into student values(1,”zhangsan”);
4)如果没有报错就表示成功了
hive (default)> select * from student;
1 zhangsan
5 Hive on Tez + Tez-UI
https://blog.csdn.net/Hello_Java2018/article/details/106036782
6 DataX 增加kafka组件
https://zhuanlan.zhihu.com/p/63608225
1.首先先将datax从github下载下来
https://link.zhihu.com/?target=https%3A//github.com/alibaba/DataX.git
- 然后去下载kafkawriter
https://link.zhihu.com/?target=https%3A//download.csdn.net/download/qq_37716298/11142069
将datax解压并将kafkawriter放入到com.alibaba.datax.plugin.writer下
在总的pom.xml中modules中加入
在package.xml中加入
将otsstreamreader中pom文件修改
修改成
</dependency
跳过测试打包
mvn -U clean package assembly:assembly -Dmaven.test.skip=true
书写json文件
{
“job”: {
“setting”: {
“speed”: {
“channel”:1
}
},
“content”: [
{
“reader”: {
“name”: “postgresqlreader”,
“parameter”: {
“username”: ““,
“password”: ““,
“connection”: [
{
“querySql”: [
“select 字段名 from test “
],
“jdbcUrl”: [
“jdbc:postgresql://xx.xx.xx.xx:5433/miasdw_dev”
]
}
]
}
},
“writer”: {
“name”: “kafkawriter”,
“parameter”: {
“topic”: “topic名称”,
“bootstrapServers”: “xx.xx.xx.xx:9092”,
“fieldDelimiter”:”,”,
“columns”:”字段名”,
“topicName”:”额外的操作,也放入到kafka中”
}
}
}
]
}
}
23 其他配置与总结
1设置物理核和虚拟核占比
(1)当前虚拟机为处理其为2核,那么虚拟化为4核让他比值为1比2,修改
yarn.nodemanager.resource.cpu-vcores参数,修改为4
[later@bigdata101 module]# cd /opt/module/hadoop-3.1.3/etc/hadoop/
[later@bigdata101 hadoop]# vim yarn-site.xml
2修改单个容器下最大cpu资源申请
任务提交时,比如spark-submit,executor-core参数不得超过4个
[later@bigdata101 hadoop]# vim yarn-site.xml
3设置每个任务容器内存大小和节点内存大小
控制任务提交每个容器内存的上限,以及yarn所可以占用的内存上限,例如当前虚拟机内存为4g那么控制yarn的每个节点内存不能超过4g
[later@bigdata101 hadoop]# vim yarn-site.xml
4配置容量调度器队列
容量调度器默认root队列,现在改为spark, hive两个队列,并设置spark队列资源占比为80%,hive为20%
[later@bigdata101 hadoop]# vim yarn-site.xml
5给hive设置队列
[later@bigdata101 conf]# vim /opt/module/apache-hive-3.1.2-bin/conf/hive-site.xml
[later@bigdata101 hadoop]# vim core-site.xml
7 HDFS配置域名访问
配置这个目的是为了让local模式访问到集群
[later@bigdata101 hadoop]# vim hdfs-site.xml
8 配置HADOOP_MAPRED_HOME(hive跑yarn必须配)
[later@bigdata101 conf]# vim /opt/module/hadoop-3.1.3/etc/hadoop/mapred-site.xml
9总结
(1)分发core-site.xml yarn.xml
[later@bigdata101 hadoop]# scp yarn-site.xml bigdata101:/opt/module/hadoop-3.1.3/etc/hadoop/
[later@bigdata101 hadoop]# scp yarn-site.xml bigdata102:/opt/module/hadoop-3.1.3/etc/hadoop/
[later@bigdata101 hadoop]# scp core-site.xml bigdata101:/opt/module/hadoop-3.1.3/etc/hadoop/
[later@bigdata101 hadoop]# scp core-site.xml bigdata102:/opt/module/hadoop-3.1.3/etc/hadoop/
(2)重启集群,观察 yarn,8088页面,最大内存,最大vcore,容器可调度最大内存都已发生变化
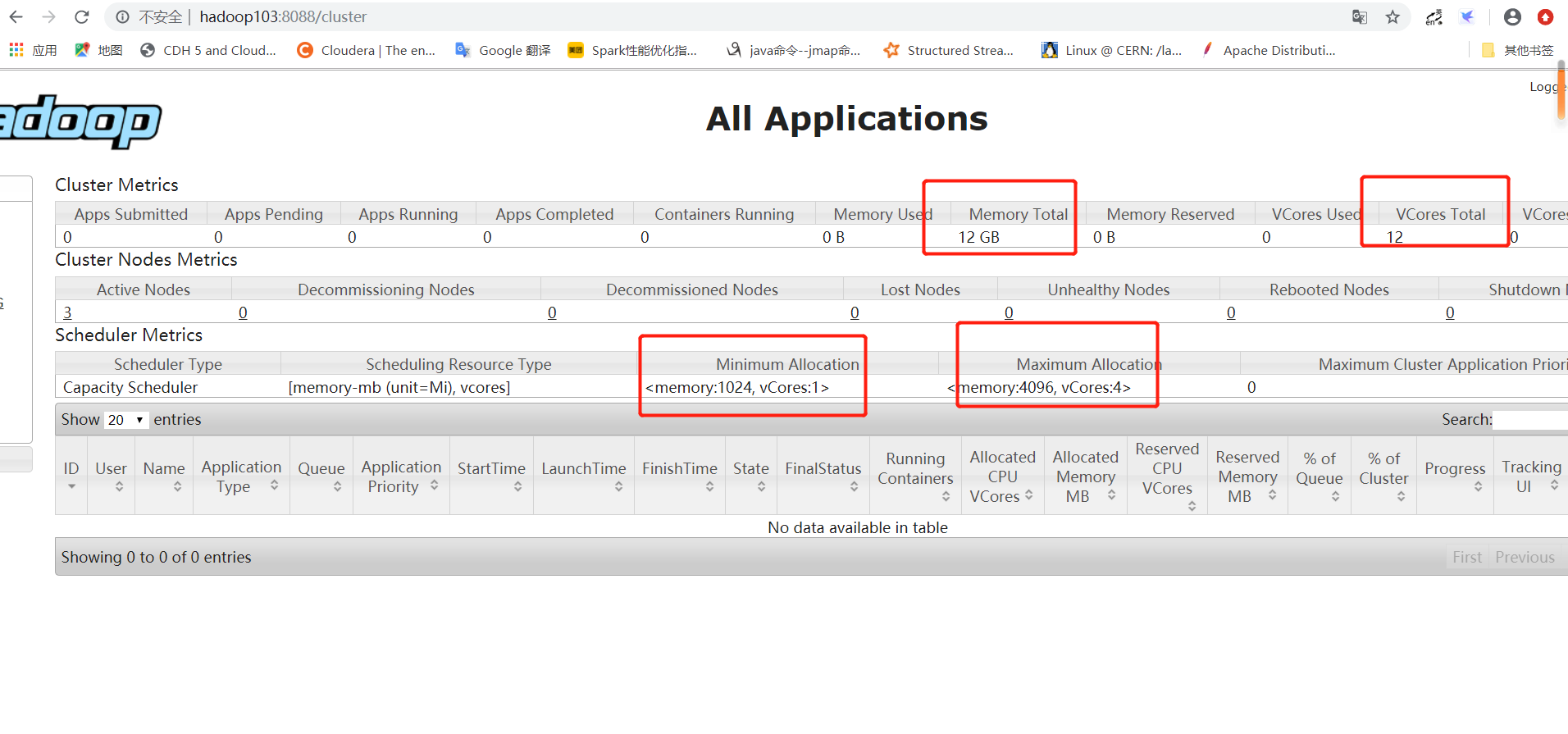
(3)所有启动命令
启动zokeeper
[later@bigdata101 hadoop]# /opt/module/apache-zookeeper-3.5.7-bin/bin/zkServer.sh start
[later@bigdata101 hadoop]# /opt/module/apache-zookeeper-3.5.7-bin/bin/zkServer.sh start
[later@bigdata102 hadoop]# /opt/module/apache-zookeeper-3.5.7-bin/bin/zkServer.sh start
启动kafka
[later@bigdata101 hadoop]# /opt/module/kafka_2.11-2.4.0/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.11-2.4.0/config/server.properties
[later@bigdata101 hadoop]# /opt/module/kafka_2.11-2.4.0/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.11-2.4.0/config/server.properties
[later@bigdata102 hadoop]# /opt/module/kafka_2.11-2.4.0/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.11-2.4.0/config/server.properties
启动hive服务
[later@bigdata101 apache-hive-3.1.2-bin]# nohup hive —service metastore >metasotre.log>&1 &
[later@bigdata101 apache-hive-3.1.2-bin]# nohup hive —service hiveserver2 >hiveserver2.log >&1 &
启动hue
[later@bigdata101 hue-master]# build/env/bin/supervisor
启动hdfs集群
[later@bigdata101 hadoop]# start-all.sh
启动haoop历史服务器
[later@bigdata101 hadoop]# mr-jobhistory-daemon.sh start historyserver
启动spark历史节点
[later@bigdata101 hadoop]# start-history-server.sh
24 Bug记录
1 centos7中文编码问题
中文设置
vim /etc/profile.d/locale.sh
export LC_CTYPE=zh_CN.UTF-8
export LC_ALL=zh_CN.UTF-8
vim /etc/locale.conf
LANG=zh_CN.UTF-8
vim /etc/sysconfig/i18n
LANG=zh_CN.UTF-8
vim /etc/environment
LANG=zh_CN.UTF-8
LC_ALL=zh_CN.UTF-8
英文设置
vim /etc/profile.d/locale.sh
export LC_CTYPE=en_US.UTF-8
export LC_ALL=en_US.UTF-8
vim /etc/locale.conf
LANG=en_US.UTF-8
vim /etc/sysconfig/i18n
LANG=en_US.UTF-8
vim /etc/environment
LANG=en_US.UTF-8
LC_ALL=en_US.UTF-8
设置完成后可能出现一下的情况
-bash: warning: setlocale: LC_CTYPE: cannot change locale (zh_CN.UTF-8): No such file or directory
-bash: warning: setlocale: LC_COLLATE: cannot change locale (zh_CN.UTF-8): No su ch file or directory
-bash: warning: setlocale: LC_MESSAGES: cannot change locale (zh_CN.UTF-8): No s uch file or directory
-bash: warning: setlocale: LC_NUMERIC: cannot change locale (zh_CN.UTF-8): No su ch file or directory
-bash: warning: setlocale: LC_TIME: cannot change locale (zh_CN.UTF-8): No such file or directory
问题解决方案
localedef -c -f UTF-8 -i zh_CN zh_CN.utf8
2 Hive on spark 执行
问题展示
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Failed to execute spark task, with exception ‘org.apache.hadoop.hive.ql.metadata.HiveException(Failed to create Spark client for Spark session 8ffa76f2-907e-4092-987d-6c89279f3c5b)’
FAILED: Execution Error, return code 30041 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Failed to create Spark client for Spark session 8ffa76f2-907e-4092-987d-6c89279f3c5b
图片截图
最后用一下命令查找日志:
hive —hiveconf hive.root.logger=DEBUG,console
找到报错原因:
2020-07-03T05:42:51,624 ERROR [1c9bb3c6-d486-4968-8b94-c35812f50e75 main] spark.SparkTask: Failed to execute spark task, with exception ‘org.apache.hadoop.hive.ql.metadata.HiveException(Failed to create Spark client for Spark session 1afe33ae-3b62-468c-8d2f-f04269421ed7)’
org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create Spark client for Spark session 1afe33ae-3b62-468c-8d2f-f04269421ed7
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.getHiveException(SparkSessionImpl.java:221)
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.open(SparkSessionImpl.java:92)
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionManagerImpl.getSession(SparkSessionManagerImpl.java:115)
at org.apache.hadoop.hive.ql.exec.spark.SparkUtilities.getSparkSession(SparkUtilities.java:136)
at org.apache.hadoop.hive.ql.exec.spark.SparkTask.execute(SparkTask.java:115)
at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:205)
at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:97)
at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:2664)
at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:2335)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:2011)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1709)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1703)
at org.apache.hadoop.hive.ql.reexec.ReExecDriver.run(ReExecDriver.java:157)
at org.apache.hadoop.hive.ql.reexec.ReExecDriver.run(ReExecDriver.java:218)
at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:239)
at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:188)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:402)
at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:821)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:759)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:683)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAcce
截图如下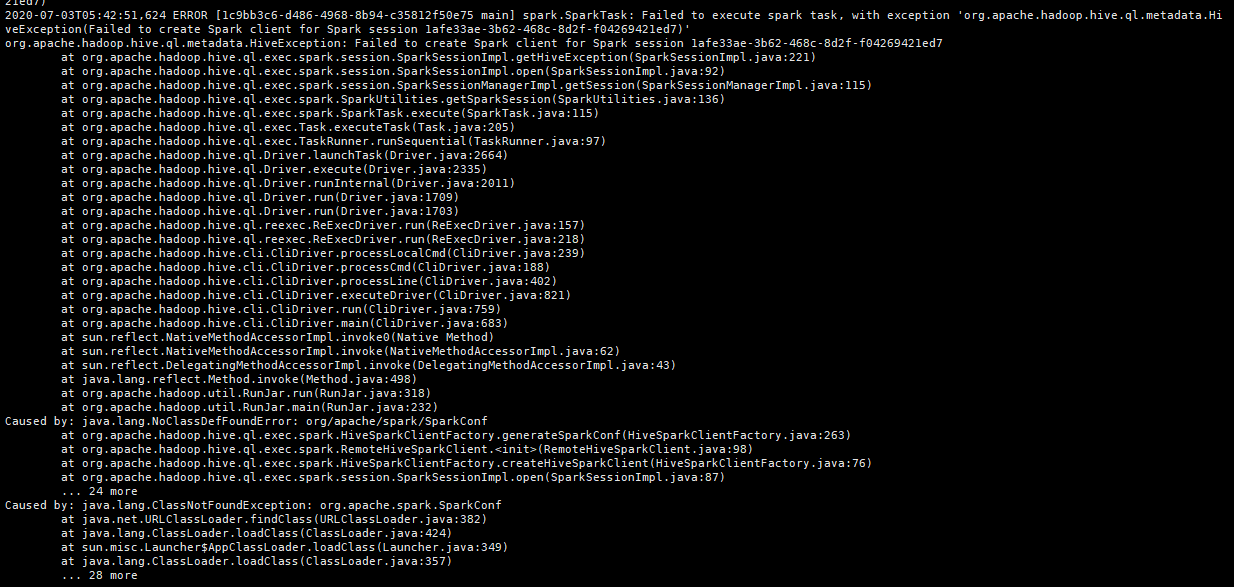
最后分析是因为hive加载不了spark的jars
hive-env.sh 添加
export SPARK_HOME=/opt/module/spark-2.4.5-bin-without-hive
export SPARK_JARS=””
for jar in ls $SPARK_HOME/jars; do
export SPARK_JARS=$SPARK_JARS:$SPARK_HOME/jars/$jar
done
export HIVE_AUX_JARS_PATH=/opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.21-SNAPSHOT.jar$SPARK_JARS
3 namenode不能故障转移
配置了namenode故障自动切换,但kill掉active后,standby并不能切换,只有当复活kill掉的namenode后,standby才会切换为active。
经过查看zkfc日志和journode日志,发现是不能创建ssh连接。
判断原因可能是:centos8 高版本的OpenSSH 解析不了当前版的密钥,所以配置修改如下:
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
4 datanode 不能启动
当我们多次格式化文件系统(hadoop namenode -format)时,会出现DataNode无法启动。
多次启动中发现有NameNode节点,并没有DataNode节点
出现该问题的原因:在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变。
解决办法:
根据日志中的路径,cd /home/hadoop/tmp/dfs(一般设置的dfs.name.dir在本地系统的路径),能看到 data和name两个文件夹。
解决方法一:(推荐)
删除DataNode的所有资料及将集群中每个datanode节点的/dfs/data/current中的VERSION删除,然后重新执行hadoop namenode -format进行格式化,重启集群,错误消失。
解决方法二:
将name/current下的VERSION中的clusterID复制到data/current下的VERSION中,覆盖掉原来的clusterID
5 namenode不能启动
删出journode jn目录和namenode的目录,格式化namenode,其余namenode节点执行同步命令后再启动namenode
1)在各个JournalNode节点上,输入以下命令启动JournalNode服务
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start journalnode
2)在[nn1]上,对其进行格式化,并启动
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -format
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
3)在[nn2]上,同步nn1的元数据信息
[atguigu@hadoop103 hadoop-2.7.2]$ bin/hdfs namenode -bootstrapStandby
4)启动[nn2]
[atguigu@hadoop103 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
6 mysql+canal启动报错
1.当删除binlog.00000x 日志可能mysql再启动不了,需要把binlog.index清空

- Mysql重新安装或者安装高版本的时候,canal启动报错
2020-07-06 07:10:39.236 [destination = example , address = bigdata101/192.168.1.96:3306 , EventParser] ERROR c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - dump address bigdata101/192.168.1.96:3306 has an error, retrying. caused by
java.io.IOException: Received error packet: errno = 1236, sqlstate = HY000 errmsg = Could not find first log file name in binary log index file
解决办法:/opt/module/canal/conf/example/ meta.dat 删除
Mysql8 默认开启binlog和format=row
使用Canal需要在mysql my.conf中增添 service-id
- Canal HA 第二台机器报错
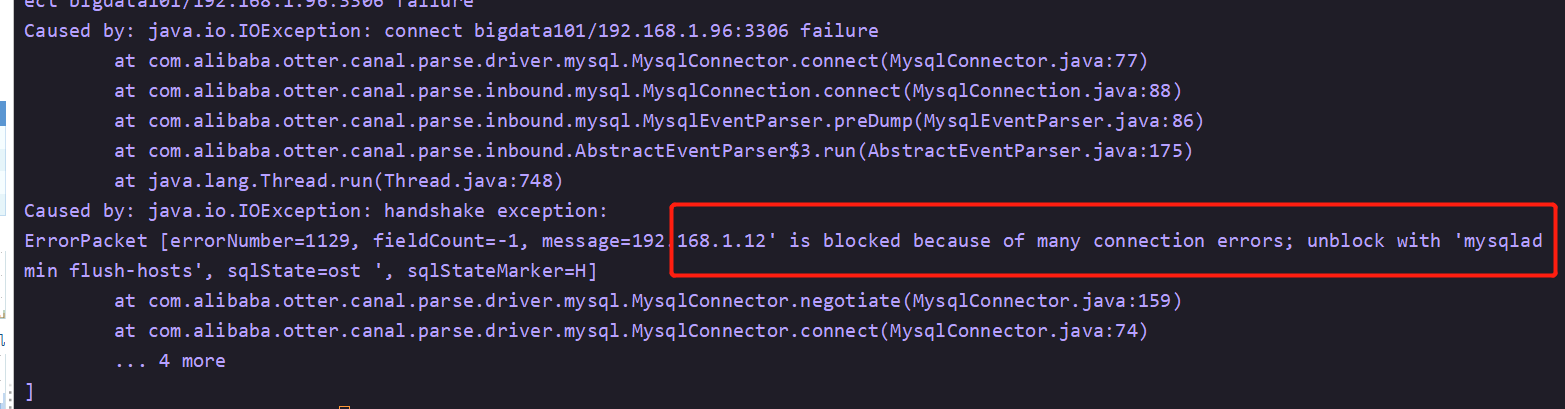
1.提高允许的max_connection_errors数量(治标不治本):
① 进入Mysql数据库查看max_connection_errors: show variables like ‘%max_connection_errors%’;
② 修改max_connection_errors的数量为1000: set global max_connect_errors = 1000;
- 第二步可以在数据库中进行,命令如下:flush hosts;
附加:Canal HA配置
修改canal.properties文件
canal.zkServers=192.168.207.141:2181,192.168.207.142:2181,192.168.207.143:2181
修改instance.properties文件
canal.instance.mysql.slaveId = 1234 #两台不一样
# position info
canal.instance.master.address = 192.168.207.141:3306
canal.instance.dbUsername = root
canal.instance.dbPassword = 123456
# canal.instance.defaultDatabaseName = canal
canal.instance.connectionCharset = UTF-8
7 Datax MySql字段关于date类型的入kafka时间不一致问题
首先看看自己系统时间
/opt/module/dataX/conf/core.json
下的timeZone=CTS 要与系统一直,不然mysql字段关于date类型的进入kafka后自动转换为别的时区时间,导致时间不一致的情况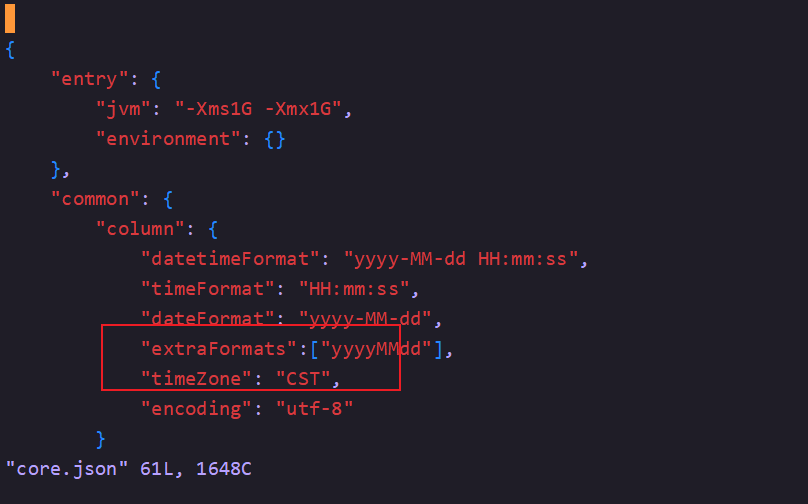
8 hive drop table 一直卡着不动错误记录
解决hive并发多版本错误
先执行:schematool -dbType mysql -initSchema
再启动元数据服务,不然matestore启动后就立马stop
9 dataX到数据到hive与hdfs出错记录
java.lang.IllegalArgumentException: No enum constant com.alibaba.datax.plugin.writer.hdfswriter.SupportHiveDataType.STRING,
10 namenode由于jn写入超时异常
在hdfs-site.xml添加如下配置:
在core-site.xml
ipc.client.connect.timeout = 90000
25 SuperSet安装

若有收获,就点个赞吧
0 人点赞
