- ">

- 01-04 Hadoop数据存储策略?
- 01-05 HBase中两种缓存机制memstore和blockcach底层实现原理?
- 01-11 Flink 维表join方案?
- 01-17 如果数据量过大,会造成kafka什么问题? 你会怎么处理?
- 01-18 Flink HBase/HDFS/Kafka 怎么支持Exactly once 的?
- 01-19 如果你们业务库的表有更新,你们数仓怎么处理的?
- 01-20 缓慢变化维(SCD)如何处理的?几种方式?
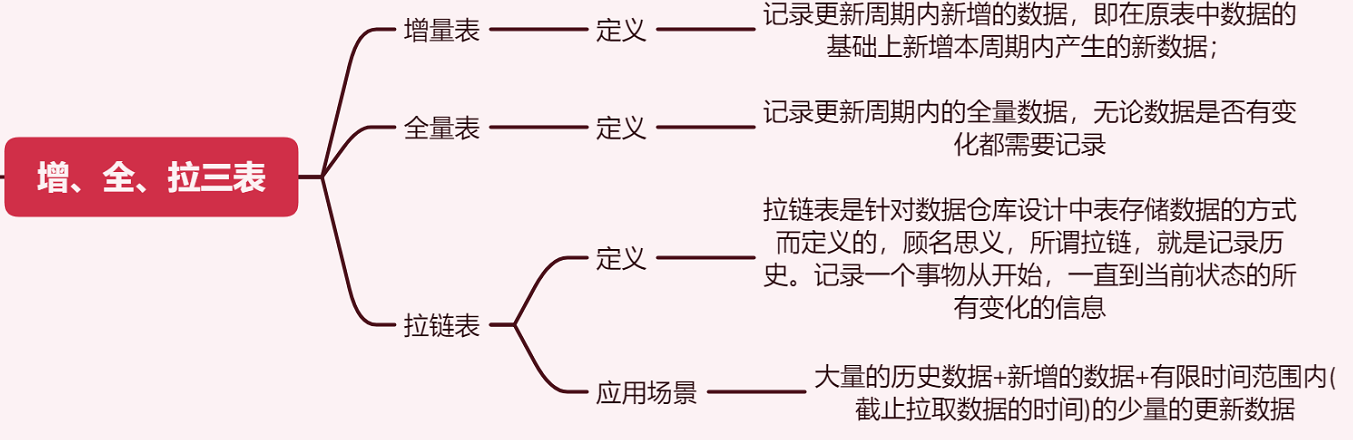
- 01-21 数仓:事实表设计方法,原则和三种类型选择
- 01-24 你做实时数仓的背景?
- 01-25 实时数仓的报警功能,紧急情况怎么处理?
- 01-26 数据模型如何构建,星型、雪花、星座的区别和工作中如何使用?
- 01-27 实时数仓,你怎么确保数据的正确性?
- Flink系列已发号中
- 02-23 如何保证维度数据修改后能和事实数据依然匹配
- 02-24 ThreadLocal解决什么问题?原理是什么?
- 02-25 分区表和分桶表有什么区别,适用什么场景?
- 02-28 简历的技术项你是怎么写的?需要注意什么?
- 03-02 什么样的业务场景你会选择 filesystem,什么样的业务场景你会选 rocksdb 状态后端?
- 03-03 一个 Flink 任务中可以既有事件时间窗口,又有处理时间窗口吗?
- 03-04 ClickHouse的核心特性?
- 03-07 在外地工作,租房怎么找,怎么选择?
- 03-08 实时数仓的数据质量怎么做?
- 03-09 列式存储和行式储存应用场景?优缺点?
- 03-10 湖仓一体怎么做?
- 03-14 ClickHouse MergeTree原理?
- 03-15 如果有100M的数据需要排序,但只有10M的内存如何排序处理
- 03-17 Doris 什么场景用?
- 03-22 大数据平台该怎么研发?具体要实现什么功能,有推荐的吗?
- 03-23 Checkpoint较大或者时间较长的情况? 怎么解决的?
- 03-24 Clickhouse,Hbase,Doris的区别 ?
- 一起学习Doris
01-04 Hadoop数据存储策略?
存储类型
HDFS异构存储支持如下4种类型,分别是:
- RAM_DISK(内存镜像文件系统)
- SSD(固态硬盘)
- DISK(普通磁盘,HDFS默认)
- ARCHIVE(计算能力弱而存储密度高的存储介质,一般用于归档)
以上四种自上到下,速度由快到慢,单位存储成本由高到低。
存储策略
HDFS总共支持Lazy_Persist、All_SSD、One_SSD、Hot、Warm和Cold等6种存储策略。
| 策略 | 说明 |
|---|---|
| Lazy_Persist | 1份数据存储在[RAM_DISK]即内存中,其他副本存储在DISK中 |
| All_SSD | 全部数据都存储在SSD中 |
| One_SSD | 一份数据存储在SSD中,其他副本存储在DISK中 |
| Hot | 全部数据存储在DISK中,默认策略为Hot |
| Warm | 一份数据存储在DISK中,其他数据存储方式为ARCHIVE |
| Cold | 全部数据以ARCHIVE的方式保存 |
查看所有存储策略hdfs storagepolicies -listPolicies指定目录设定存储策略hdfs storagepolicies -setStoragePolicy -path xxx -policy xxx查看指定路径的存储策略hdfs storagepolicies -getStoragePolicy -path /取消存储策略(ps:取消后存储策略就根据上级目录,如果是根目录,那就是hot)hdfs storagepolicies -unsetStoragePolicy -path /user
01-05 HBase中两种缓存机制memstore和blockcach底层实现原理?
HBase中Block
1、Block是HBase中最小的数据存储单元,默认为64K,在建表语句中可以通过参数BlockSize指定。
2、HBase中Block分为四种类型:Data Block,Index Block,Bloom Block和Meta Block。
3、其中Data Block用于存储实际数据,通常情况下每个Data Block可以存放多条KeyValue数据对;
4、Index Block和Bloom Block都用于优化随机读的查找路径,
5、其中Index Block通过存储索引数据加快数据查找,
6、而Bloom Block通过一定算法可以过滤掉部分一定不存在待查KeyValue的数据文件,减少不必要的IO操作;
7、Meta Block主要存储整个HFile的元数据。
MemStore
1、其中MemStore称为写缓存
2、HBase执行写操作首先会将数据写入MemStore,并顺序写入HLog,
3、等满足一定条件后统一将MemStore中数据刷新到磁盘,这种设计可以极大地提升HBase的写性能。
4、MemStore对于读性能也至关重要,假如没有MemStore,读取刚写入的数据就需要从文件中通过IO查找,这种代价显然是昂贵的!
BlockCache
一个 RegionServer 有一个 BlockCache,在 RegionServer 启动的时候完成 BlockCache 的初始化工作。
HBase 提供了几种 BlockCache 方案:
- LruBlockCache
LruBLockCache 在 JVM 堆中,基于客户端对数据的访问频率,定义了三个不同的优先级队列,设计原理类似于 JVM 的堆分区策略。
BlockCahce 分级
single:block 被第一次访问,则该 Block 被放在这一优先级队列中。
multi:如果一个 Block 被多次访问,则从 single 移到 multi 中。
in memory:in memory 由用户指定,在内存中常驻,一般不推荐,只用系统表才使用 in memory 优先级。
分级的好处在于:
首先,通过 in memory 类型缓存,将重要的数据放到 RegionServer 内存中常驻,例如 Meta 或者 namespace 的元数据信息。
其次,通过区分 single 和 multi 类型缓存,可以防止由于 scan 操作带来的 cache 频繁更替。
默认配置下,对于整个 BlockCache,按照以下百分比分配给 single、multi 和 in memory 使用:0.25、0.5和0.25。无论哪个区,都会采用严格的 Least-Recently-Used 算法淘汰机制,最少使用的 Block 会被替换,为新加载的 Block 预留空间。
如果只使用 LruBlockCache,在内存较大时会存在GC的问题导致服务中断。
- SlabCache
为了解决 LRUBlockCache 方案中因为JVM垃圾回收导致的服务中断,SlabCache 方案使用 Java NIO DirectByteBuffer 技术实现了堆外内存存储,不再由JVM管理数据内存。
默认情况下,系统在初始化的时候会分配两个缓存区,分别占整个 BlockCache 大小的80%和20%,其中前者主要存储小于等于 64K Block,后者存储小于等于 128K Block,如果一个 Block 超过128K 则两个区都不会缓存。SlabCache 也使用 LRU 算法对过期 Block 进行淘汰。和 LRUBlockCache 不同的是,SlabCache 淘汰 Block 的时候只需要将对应的 bufferbyte 标记为空闲,后续 block cache 对其上的内存直接进行覆盖即可。
由于以下设计上的原因被废弃:
只能存储两种大小标准的 Block,由于不同表和列族的设置,会有多种类型的 block size,这样会导致内存使用率低,特别是在使用了
DataBlockEncoding 的情况下。
因此,通常会将 SlabCache 和 LRUBlockCache 搭配使用,称为 DoubleBlockCache。Block 会在
SlabCache 和 LruBlockCache 都缓存一份,读操作会先查找 LruBlockCache,后查找
SlabCache,当在 SlabCache 中命中时会把 block 重新放回 LruBlockCache。实际应用中比单独用
LruBlockCache 没有明显改善。
堆外内存的性能没有堆内存高
- BucketCache
SlabCache 方案在实际应用中并没有很大程度改善原有 LruBlockCache 方案的GC弊端,还额外引入了诸如堆外内存使用率低的缺陷。
BucketCache
为了解决了 SlabCache 中存在的问题,首先其支持多种 Cache 方式,通过 hbase.bucketcache.ioengine 配置,有 heap、offheap 和 file 三种:
heap 使用jvm中的heap
offheap 使用堆外内存
file 使用文件的方式,利用SSD硬盘的使用,改进了使用率低的问题。
其次支持了多种不同大小的 bucket,以适应不同大小的 block size。可以通过参数 hbase.bucketcache.bucket.sizes 来配置不同 bucket 的大小。默认是14种,大小分别是4、8、16、32、40、48、56、64、96、128、192、256、384、512KB的block(逗号分隔)。并且,在某一大小类型的 Bucket 空间不足的情况下,系统也会从其他 Bucket 空间借用内存使用,不会出现内存使用率低的情况。
最后,使用堆外内存的性能问题(如拷贝内存)在2.0版本中解决 HBASE-11425
实际实现中,常将 BucketCache 和 LRUBlockCache 搭配使用,称为 CombinedBlockCache。
在 cache block 的时候会将 MetaBlock(包括 META、INDEX、BLOOM 等非DATA block)放入LruBlockCache,将 DataBlock 存储在 BucketCache 中。特殊情况是,表中设置了 CACHE_DATA_IN_L1 => ‘true’ 的 DataBlock 也会存入 LruBlockCache。
- External BlockCache
ExternalBlockCache 提供使用外部的缓存服务来进行缓存,如 memcached 和 redis 等。
01-11 Flink 维表join方案?
- 查找关联(同步,异步)
- 状态编程,预加载数据到状态中,按需取
- 冷热数据
- 广播维表
- Temporal Table Join
- Lookup Table Join
01-17 如果数据量过大,会造成kafka什么问题? 你会怎么处理?
首先,数据量过大,会造成
1 broker 压力大,
2 磁盘压力大,
3 消费者压力大,
4 log 变大.
这时候需要做的就是,
1.扩充 broker,
2.挂载多个磁盘,
3. 增加消费者,增大消费能力,
4 扩分区提升并行能力,
5 增大消息批次大小,减少网络请求压力
01-18 Flink HBase/HDFS/Kafka 怎么支持Exactly once 的?
Flink 通过checkpoint 保证flink内部一致
flink整合其他组件达到端到端精准一次 需要上游有偏移量支持数据回放,
下游有幂等性/
事务的支持
文件比较特殊通过三种文件状态也可以达到精准一次/
也有人说预写日志两阶段提交可以精准一次但是极端情况下是无法保证的
HBase 幂等性
HDFS 三种文件状态
Kafka 偏移量数据回放
详细:
flink精准一次 : https://blog.csdn.net/qq_31425415/article/details/119009369
flink整合kafka精准一次 https://blog.csdn.net/qq_31425415/article/details/122090512
01-19 如果你们业务库的表有更新,你们数仓怎么处理的?
A . 表结构更改1 . 从管理上控制 : 协商要求业务库的开发者更新表结构时需要同步信息给到数仓 , 数仓跟随更新 .2 . 对用不到的新增信息 , 放弃跟随更新3 . 从脚本上控制 : 抽数脚本中的sql不使用select * , 使用select 字段B . 表数据更新1 . 数仓增量更新数据
业务数据表有更新,看得到变更表结构的,比如说增加,删除字段的,其实就可以用扩展表1 优点不影响老业务数据2 扩展表只是扩展的数据部分。支持新业务的。扩展的数据用关联来获取。这样可以把新老业务解耦合。另外业务层面更改表结构风险极大。
1.同步前监控表的schema,与数仓的不一致就刹车,告警,2.同步的时候把字段写死,防止加字段把任务搞崩,3.都击穿了就任务报错的时候告警吧
01-20 缓慢变化维(SCD)如何处理的?几种方式?
01-21 数仓:事实表设计方法,原则和三种类型选择
01-24 你做实时数仓的背景?
离线数仓都是t+1,越来越没办法满足业务上的需求,比如算法部门,做的推荐功能往往都是实时的,他们不能仅仅依赖于离线数仓的死数据更多时候需要实时的一些指标产出不断的优化算法模型,运营也需要根据实时的一些指标及时更变运营策略,等等之类的还很多
01-25 实时数仓的报警功能,紧急情况怎么处理?
prometheus + grafana + pushgetwayFlink 内部需要这些下载对应版本的jar拷贝到 <flink home>/lib目录下(如果plugins下面没有)flink-metrics-prometheus-1.13.1.jarhttps://mvnrepository.com/artifact/org.apache.flink/flink-metrics-prometheus也可以不用下载/opt/app/flink-1.13.1/plugins/metrics-prometheus修改Flink配置vim flink-conf.yaml##### 与Prometheus集成配置 #####metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter# PushGateway的主机名与端口号metrics.reporter.promgateway.host: devcdh1metrics.reporter.promgateway.port: 9999# Flink metric在前端展示的标签(前缀)与随机后缀metrics.reporter.promgateway.jobName: flink-metrics-ppgmetrics.reporter.promgateway.randomJobNameSuffix: truemetrics.reporter.promgateway.deleteOnShutdown: falsemetrics.reporter.promgateway.interval: 30 SECONDS
01-26 数据模型如何构建,星型、雪花、星座的区别和工作中如何使用?
1、星型模型由事实表和多个维表组成。事实表中存放大量关于企业的事实数据,元祖个数通常很大,而且非规范化程度很高优点:读取速度快:针对各个维做了大量预处理,如按照维度进行预先的统计、分组合排序等多种数据源,减少异构数据带来的分析复杂性标准性,新员工可快速掌握,数据工程师和分析师比较了解,可促进协作可扩展性,添加的事实表可以重用先有维度向事实表添加更多外键,实现事实表添加新维度2、雪花模型星型模型的扩展,将星型模型的维表进一步层次化,原来的各个维表可能被扩展为小的事实表,形成一些局部的层次区域特点:通过定义多重父类维表来描述某些特殊维表定义特殊的统计信息最大限度的减少数据存储量把较小的维度表联合在一起改善查询性能3、星座模型星型模型的扩展延伸,多张事实表共享维度表,只有一些大型公司使用
星型是非规范化的,没有关联维度,关联维度会冗余到维度中;雪花是规范化的,有关联维度;星座是有公共维度,多个事实表会和相同的维度关联工作中,感觉星型偏多,而且现在存储设备便宜,特别是数仓类,有时候,直接把维度退化到事实表中,做宽表,提高查询效率。
01-27 实时数仓,你怎么确保数据的正确性?
实时数仓还有的解决了时效性的问题,但是在一致性和正确性上面,目前却没有太多的办法,因为目前基于流的计算都是跟着实时需求走的,单个任务实现从明细数据到最终的指标产出,由于产出的逻辑可能存在差异,数据的质量可能存在差异,平台的稳定性不同时段可能不同,导致即使是相同的指标,不同出处可能都会不一致。其次是数据的正确性,在离线数仓投入巨大的人力物力后,如何保障实时数仓的数据的正确性是一个巨大的挑战实时数据也有明细数据,就可以和离线数据进行比对数在实时数仓中, 我们主要关注四个指标, 分别是完整性, 准确性, 一致性, 及时性, 并按n分钟粒度进行统计监控监控系统: 调度系统或者中台的数据质量管理系统 , 准实时的监控 稽查系统监控指标: 阈值, 业务指标阈值, 监控粒度阈值完整性: ODS层数据标准化, ETL任务关键字段是否符合日志格式规范准确性: 结果是否准确, 埋点参数值是否准确,一致性: 实时数仓每层的读入量, 过滤量,输出量, 是否一致 , 可以将kafka的数据都落hive方便排查问题和分析及时性: 通过观察数仓中processtime和eventime的差值来判断数仓的及时性. 或者通过metrics.latency.interval 进行监控, 一般设置30s以上 一是因为延迟监控的频率可以不用太频繁,二是因为 LatencyMarker 的处理也要消耗一定性能。如果是lambda架构的话离线来校对实时, 和以往的阀值做比较 还有就是在ods dwd 层做了全面的数据质量 一次性检测等灰度测试环境上 在库中跑一遍 和 数仓中跑一遍 验证sql 或者代码的准确性
Flink系列已发号中
02-23 如何保证维度数据修改后能和事实数据依然匹配
维度变化 —-缓慢变化维
<br /> 1.重写纬度值维度建模中不需要保留此维度属性历史变化的情况
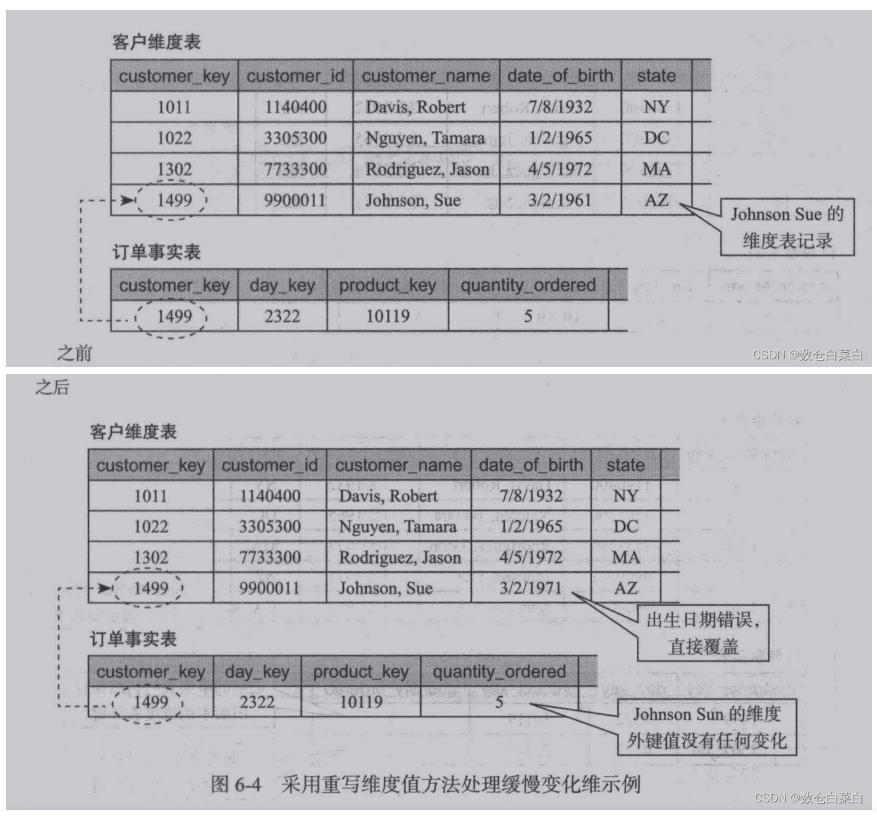
比如1499编号的客户,以前的生日写错了,那么认为修改之后就不再需要以前的生日了,我们直接在原来的数据上进行更改。
2.插入新的维度行
插入新的维度行方法则是通过在维度表中插入新的行来保存和记录变化。
属性改变前的事实表行和旧的维度表行进行关联
属性改变后的事实表和新的维度表进行关联
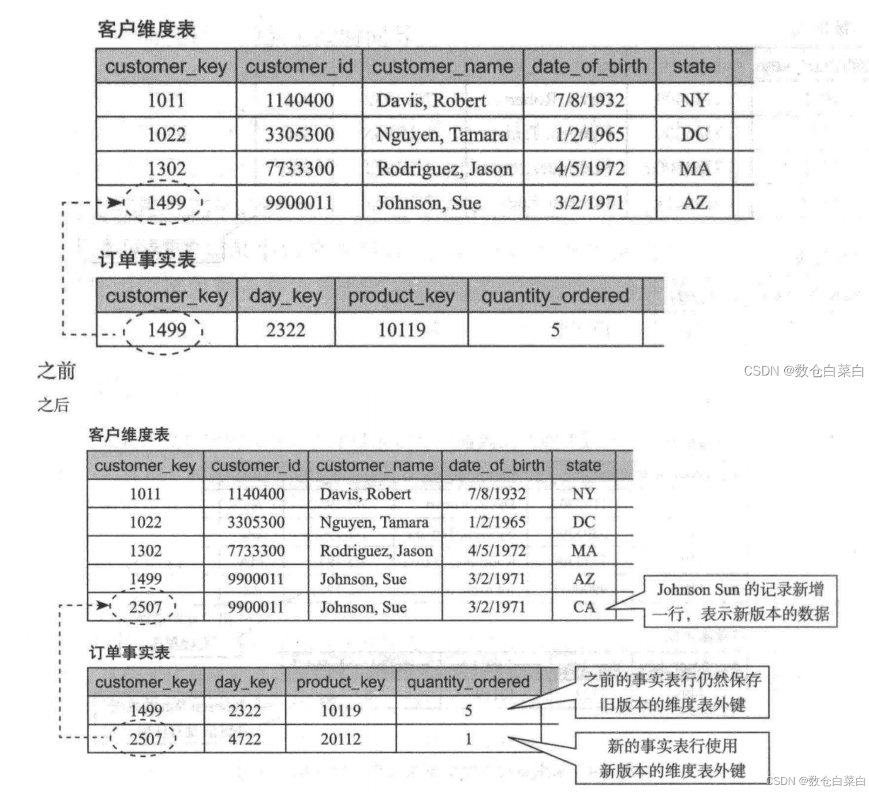
将以前的信息进行保留。<br /> 在维度表中旧的顾客和事实表中旧的购买记录关联,新的顾客和新的购买记录关联。
- 拉链表[
](https://blog.csdn.net/weixin_46300771/article/details/122553017)
02-24 ThreadLocal解决什么问题?原理是什么?
hreadLocal 提供了线程本地的实例。它与普通变量的区别在于,每个使用该变量的线程都会初始化一个完全独立的实例副本。ThreadLocal 变量通常被private static修饰。当一个线程结束时,它所使用的所有 ThreadLocal 相对的实例副本都会被回收。ThreadLocal 适用于如下两种场景每个线程需要有自己单独的实例实例需要在多个方法中共享,但不希望被多线程共享对于第一点,每个线程拥有自己实例,实现它的方式很多。例如可以在线程内部构建一个单独的实例。ThreadLocal 可以以非常方便的形式满足该需求。对于第二点,可以在满足第一点(每个线程有自己的实例)的条件下,通过方法间引用传递的形式实现。ThreadLocal 使得代码耦合度更低,且实现更优雅。
public class ThreadLocalDemo {public static void main(String[] args) throws InterruptedException {int threadNum = 3;CountDownLatch countDownLatch = new CountDownLatch(threadNum);for (int i = 1; i <= threadNum; i++) {new Thread(() -> {for (int j = 0; j <= 2; j++) {MyUtil.add(String.valueOf(j));MyUtil.print();}MyUtil.set("hello world");countDownLatch.countDown();}, "thread - " + i).start();}countDownLatch.await();}private static class MyUtil {public static void add(String newStr) {StringBuilder str = StringBuilderUtil.stringBuilderThreadLocal.get();StringBuilderUtil.stringBuilderThreadLocal.set(str.append(newStr));}public static void print() {System.out.printf("Thread name:%s , ThreadLocal hashcode:%s, Instance hashcode:%s, Value:%s\n",Thread.currentThread().getName(),StringBuilderUtil.stringBuilderThreadLocal.hashCode(),StringBuilderUtil.stringBuilderThreadLocal.get().hashCode(),StringBuilderUtil.stringBuilderThreadLocal.get().toString());}public static void set(String words) {StringBuilderUtil.stringBuilderThreadLocal.set(new StringBuilder(words));System.out.printf("Set, Thread name:%s , ThreadLocal hashcode:%s, Instance hashcode:%s, Value:%s\n",Thread.currentThread().getName(),StringBuilderUtil.stringBuilderThreadLocal.hashCode(),StringBuilderUtil.stringBuilderThreadLocal.get().hashCode(),StringBuilderUtil.stringBuilderThreadLocal.get().toString());}}private static class StringBuilderUtil {// ThreadLocal 变量通常被 private static 修饰private static ThreadLocal<StringBuilder> stringBuilderThreadLocal = ThreadLocal.withInitial(() -> new StringBuilder());}}
ThreadLocal维护线程与实例的映射既然每个访问 ThreadLocal 变量的线程都有自己的一个“本地”实例副本。一个可能的方案是 ThreadLocal 维护一个 Map,键是 Thread,值是它在该 Thread 内的实例。线程通过该 ThreadLocal 的 get() 方案获取实例时,只需要以线程为键,从 Map 中找出对应的实例即可。该方案可满足上文提到的每个线程内一个独立备份的要求。每个新线程访问该 ThreadLocal 时,需要向 Map 中添加一个映射,而每个线程结束时,应该清除该映射。这里就有两个问题:增加线程与减少线程均需要写 Map,故需保证该 Map 线程安全。虽然从ConcurrentHashMap的演进看Java多线程核心技术一文介绍了几种实现线程安全 Map 的方式,但它或多或少都需要锁来保证线程的安全性线程结束时,需要保证它所访问的所有 ThreadLocal 中对应的映射均删除,否则可能会引起内存泄漏。(后文会介绍避免内存泄漏的方法)其中锁的问题,是 JDK 未采用该方案的一个原因。Thread维护ThreadLocal与实例的映射上述方案中,出现锁的问题,原因在于多线程访问同一个 Map。如果该 Map 由 Thread 维护,从而使得每个 Thread 只访问自己的 Map,那就不存在多线程写的问题,也就不需要锁。该方案虽然没有锁的问题,但是由于每个线程访问某 ThreadLocal 变量后,都会在自己的 Map 内维护该 ThreadLocal 变量与具体实例的映射,如果不删除这些引用(映射),则这些 ThreadLocal 不能被回收,可能会造成内存泄漏。ThreadLocal 并不解决线程间共享数据的问题ThreadLocal 通过隐式的在不同线程内创建独立实例副本避免了实例线程安全的问题每个线程持有一个 Map 并维护了 ThreadLocal 对象与具体实例的映射,该 Map 由于只被持有它的线程访问,故不存在线程安全以及锁的问题ThreadLocalMap 的 Entry 对 ThreadLocal 的引用为弱引用,避免了 ThreadLocal 对象无法被回收的问题ThreadLocalMap 的 set 方法通过调用 replaceStaleEntry 方法回收键为 null 的 Entry 对象的值(即为具体实例)以及 Entry 对象本身从而防止内存泄漏ThreadLocal 适用于变量在线程间隔离且在方法间共享的场景
02-25 分区表和分桶表有什么区别,适用什么场景?
Hive分区是将数据表的某一个字段或多个字段进行统一归类,而后存储在在hdfs上的不同文件夹中。Hive分桶是相对分区进行更细粒度的划分。是将整个数据内容按照某列取hash值,对桶的个数取模的方式决定该条记录存放在哪个桶当中;具有相同hash值的数据进入到同一个文件中。分区表的使用场景就是,将数据按照年或者月或者日甚至小时进行分区分桶表主要用于解决数据倾斜的问题取样sampling更高效。没有分桶的话需要扫描整个数据集。提升某些查询操作效率,例如map side join
02-28 简历的技术项你是怎么写的?需要注意什么?
Java/Scala 基础扎实,对面向对象编程思想有深入理解,能灵活运用常见的设计模式解决实际问题。 熟悉 JMM 内存模型,能灵活使用 Java 的多线程及 JUC 并发包工具解决多线程问题,有 JVM 调优经验。 熟练掌握 Flink,对于 Flink 状态计算、CEP、SQL、监控相关生态具有架构和运维的经验,改造增强 Flink SQL Connector 支持 Clickhouse、RocketMQ、接口等支持 Source、Sink 和 Temporal Table Join 的。 熟练掌握 Kafka,具有 Kafka 组件维护能力和 Kafka-SDK 架构经验。 熟练掌握 Hbase 数据存储,读写流程,WAL 订阅和数据同步,了解 Hbase 设计架构原理。 熟练使用 Mysql 关系型数据库,对索引机制及 SQL 性能优化有一定了解,有 SQL 性能调优经验。 熟练掌握 Redis 在项目中的使用,了解 Redis 高级特性及数据结构、缓存的设计和使用。 熟悉实时架构、技术选型、场景运用、监控运维报警等技术生态,具有在大数据高并发场景下读写性能优化经验。 熟悉 Hadoop、Hive、Zookeeper、ClickHouse、Canal、Flume 等大数据生态圈常用组件。 熟练使用 GIT 版本控制,熟练使用 Maven 项目构建及管理工具注意切记熟练,精通,熟悉词语的描述,还有就是写你会的技术栈,其他的知识面可以不会,但是写的要会。
03-02 什么样的业务场景你会选择 filesystem,什么样的业务场景你会选 rocksdb 状态后端?
MemoryStateBackend原理:运行时所需的 State 数据全部保存在 TaskManager JVM 堆上内存中,执行 Checkpoint 的时候,会把 State 的快照数据保存到 JobManager 进程 的内存中。执行 Savepoint 时,可以把 State 存储到文件系统中。适用场景:基于内存的 StateBackend 在生产环境下不建议使用,因为 State 大小超过 JobManager 内存就 OOM 了,此种状态后端适合在本地开发调试测试,生产环境基本不用。State 存储在 JobManager 的内存中。受限于 JobManager 的内存大小。每个 State 默认 5MB,可通过 MemoryStateBackend 构造函数调整。每个 Stale 不能超过 Akka Frame 大小。FSStateBackend原理:运行时所需的 State 数据全部保存在 TaskManager 的内存中,执行 Checkpoint 的时候,会把 State 的快照数据保存到配置的文件系统中。TM 是异步将 State 数据写入外部存储。适用场景:a.适用于处理小状态、短窗口、或者小键值状态的有状态处理任务,不建议在大状态的任务下使用 FSStateBackend。比如 ETL 任务,小时间间隔的 TUMBLE 窗口 b.State 大小不能超过 TM 内存。RocksDBStateBackend原理:使用嵌入式的本地数据库 RocksDB 将流计算数据状态存储在本地磁盘中。在执行 Checkpoint 的时候,会将整个 RocksDB 中保存的 State 数据全量或者增量持久化到配置的文件系统中。适用场景:a.最适合用于处理大状态、长窗口,或大键值状态的有状态处理任务。b.RocksDBStateBackend 是目前唯一支持增量检查点的后端。c.增量检查点非常适用于超大状态的场景。比如计算 DAU 这种大数据量去重,大状态的任务都建议直接使用 RocksDB 状态后端。到生产环境中:⭐ 如果状态很大,使用 Rocksdb;如果状态不大,使用 Filesystem。⭐ Rocksdb 使用磁盘存储 State,所以会涉及到访问 State 磁盘序列化、反序列化,性能会收到影响,而 Filesystem 直接访问内存,单纯从访问状态的性能来说 Filesystem 远远好于 Rocksdb。生产环境中实测,相同任务使用 Filesystem 性能为 Rocksdb 的 n 倍,因此需要根据具体场景评估选择。
03-03 一个 Flink 任务中可以既有事件时间窗口,又有处理时间窗口吗?
一个 Flink 任务可以同时有事件时间窗口,又有处理时间窗口。⭐ 我们其实没有必要把一个 Flink 任务和某种特定的时间语义进行绑定。对于事件时间窗口来说,我们只要给它 watermark,能让 watermark 一直往前推进,让事件时间窗口能够持续触发计算就行。对于处理时间来说更简单,只要窗口算子按照本地时间按照固定的时间间隔进行触发就行。无论哪种时间窗口,主要满足时间窗口的触发条件就行。⭐ Flink 的实现上来说也是支持的。Flink 是使用一个叫做 TimerService 的组件来管理 timer 的,我们可以同时注册事件时间和处理时间的 timer,Flink 会自行判断 timer 是否满足触发条件,如果是,则回调窗口处理函数进行计算。
03-04 ClickHouse的核心特性?
一 一个完整的DBMSCH作为一个DBMS,支持DBMS的基本特性:DDL:可以动态创建、修改或删除数据库、表和视图,而无需重启服务DML:可以动态查询、插入、修改和删除数据权限控制:支持按照用户粒度设置数据库或表的操作权限数据备份和恢复:提供了数据备份导出和导入恢复机制分布式管理:提供集群模式二 列式存储和数据压缩CH主要的MergeTree引擎下,列与列会由不同的文件分别保存,来自不同列的值被单独存储,来自同一列的数据被存储在一起。数据默认使用LZ4压缩算法,Yandex.Metrica的生产环境下压缩比可以达到8:1三 向量化执行引擎向量化执行是CPU寄存器级别的并行操作。为了实现向量化执行,需要利用CPU的SIMD指令,即用单条指令操作多条数据。在CPU寄存器层面实现数据的并行操作。四 关系模型与完善的SQL查询支持CH使用关系模型描述数据并提供了传统数据库的相关概念(数据库,表,视图和函数等等)。CH完全使用SQL作为查询语言(支持GROUP BY、ORDER BY、JOIN、IN等大部分标准SQL)。五 多线程与分布式CH既支持分区(纵向扩展,利用多线程原理),也支持分片(横向扩展,利用分布式原理),可以说将多线程和分布式技术运用到了极致。六 多主架构HDFS,HBase和ES这类分布式系统,都采用了Master-Slave主从架构,由一个管控节点作为Leader统筹集群。而CH不一样,它是Multi-Master架构,集群中每个节点角色对等,不区分数据节点和计算节点,客户端访问任意一个节点都能得到相同的结果,集群中所有节点功能相同。所以它天然避免了单点故障问题。CH的一些其他特点:数据分片,本地表和分布式表概念支持批量更新(小数据量反而不适合它)不依赖臃肿的Hadoop全家桶,开箱即用CH的一些缺点特性(事实上其他同类型OLAP数据库同样不擅长这些,为了极致查询性能所做的权衡):不支持事务不擅长根据主键按行粒度进行查询(虽然本身支持)不擅长按行删除数据(虽然本身支持)
03-07 在外地工作,租房怎么找,怎么选择?
03-08 实时数仓的数据质量怎么做?
最准确的就是离线数据修补以下是两种架构
Lambda 架构批处理层使用可处理大量数据的分布式处理系统预先计算结果。它通过处理所有的已有历史数据来实现数据的准确性。这意味着它是基于完整的数据集来重新计算的,能够修复任何错误,然后更新现有的数据视图。输出通常存储在只读数据库中,更新则完全取代现有的预先计算好的视图。速度处理层会实时处理新来的大数据。速度层通过提供最新数据的实时视图来最小化延迟。速度层所生成的数据视图可能不如批处理层最终生成的视图那样准确或完整,但它们几乎在收到数据后立即可用。而当同样的数据在批处理层处理完成后,在速度层的数据就可以被替代掉了。本质上,速度层弥补了批处理层所导致的数据视图滞后。比如说,批处理层的每个任务都需要 1 个小时才能完成,而在这 1 个小时里,我们是无法获取批处理层中最新任务给出的数据视图的。而速度层因为能够实时处理数据给出结果,就弥补了这 1 个小时的滞后。所有在批处理层和速度层处理完的结果都输出存储在服务层中,服务层通过返回预先计算的数据视图或从速度层处理构建好数据视图来响应查询。Lambda 架构的不足使用 Lambda 架构时,架构师需要维护两个复杂的分布式系统,并且保证他们逻辑上产生相同的结果输出到服务层中。Kappa 架构我们能不能改进 Lambda 架构中的速度层,使它既能够进行实时数据处理,同时也有能力在业务逻辑更新的情况下重新处理以前处理过的历史数据呢第一步,部署 Apache Kafka,并设置数据日志的保留期(Retention Period)。这里的保留期指的是你希望能够重新处理的历史数据的时间区间。例如,如果你希望重新处理最多一年的历史数据,那就可以把 Apache Kafka 中的保留期设置为 365 天。如果你希望能够处理所有的历史数据,那就可以把 Apache Kafka 中的保留期设置为“永久(Forever)”。第二步,如果我们需要改进现有的逻辑算法,那就表示我们需要对历史数据进行重新处理。我们需要做的就是重新启动一个 Apache Kafka 作业实例(Instance)。这个作业实例将从头开始,重新计算保留好的历史数据,并将结果输出到一个新的数据视图中。我们知道 Apache Kafka 的底层是使用 Log Offset 来判断现在已经处理到哪个数据块了,所以只需要将 Log Offset 设置为 0,新的作业实例就会从头开始处理历史数据。第三步,当这个新的数据视图处理过的数据进度赶上了旧的数据视图时,我们的应用便可以切换到从新的数据视图中读取。第四步,停止旧版本的作业实例,并删除旧的数据视图。与 Lambda 架构不同的是,Kappa 架构去掉了批处理层这一体系结构,而只保留了速度层。你只需要在业务逻辑改变又或者是代码更改的时候进行数据的重新处理。因为 Kappa 架构只保留了速度层而缺少批处理层,在速度层上处理大规模数据可能会有数据更新出错的情况发生,这就需要我们花费更多的时间在处理这些错误异常上面。
03-09 列式存储和行式储存应用场景?优缺点?
1、行式存储结构在分布式系统存储下,表按照行水平分割,每行中所有数据存放在同一个数据块中,数据块又有可能分布在不同的节点上,如果读取行中的一列和二列则需要先读取本地节点上所有符合条件的行,然后过滤出一列和二列。行式存储结构的优点是数据加载速度快,所有数据优先从本地读取,不需要额外的网络开销。缺点是每行中所有列都放在了相同的数据块中,在读取一行数据时会读取当前行的所有列,这样就增加了额外的磁盘I/O开销。并且每一列存储的数据类型不能一样,在数据压缩时不同数据类型压缩效果会很大,这样会导致磁盘利用率低,同样也会导致磁盘I/O加大。2. 列式存储结构列式存储结构将关系表按列垂直分割成多个子关系表,分割后的每组子关系表中的所有数据存放在同一个数据块中,每一列都是独立存储的。列式存储结构的优点是只读取有用的列,能够避免额外的磁盘I/O开销,同一列中的数据类型相同,因此数据压缩时有很好的压缩比,提高了磁盘的空间利用率。缺点是由于列式存储按照列来垂直分割数据,因此不同的列可能分布在不同的节点上,读取不同的列会出现跨界点访问的问题,这样就增加了网络传输所消耗的时间。场景行式存储主要用于查询字段多的场景,因为底层按行存储的,只要找到一个字段其他字段很快就可以查出来,而列式存储是按照列进行存储的,拥有高压缩以及低io,可以更好的做列裁剪,适合查询按列查找。
03-10 湖仓一体怎么做?
湖仓一体具有以下五个关键特性:(1)支持分析结构化和非结构化数据;(2)适用于分析师和数据科学家,不仅支持报表,而且支持机器学习和人工智能相关用例;(3)数据可治理,避免产生沼泽;(4)架构粗暴安全,确保利益相关者能正确访问以数据为中心的安全架构;(5)以合理代价实现有效扩展数据在湖,模型在仓数据的镜源层放在数据湖中,类似于:hudi、iceberg。通过hive、scala、spark进行数据的处理加工,并将处理后的数据放进传统的数据仓库中原文链接:https://blog.csdn.net/naisongwen/article/details/120232318数仓平台结合数据仓库和数据湖各自的优点,将数据仓库的丰富管理功能和跟数据仓库相适应的性能优化能力与支持多种数据格式的低成本存储的数据湖的灵活性结合起来,并引入统一元数据层,不仅统一了基于表的数据访问和基于文件的数据访问方式,还实现了事务管理功能和其他诸如访问控制、版本控制等管理功能,形成lakehouse架构。Lakehouse 是一种结合了数据湖和数据仓库优势的新范式,解决了数据湖的局限性。Lakehouse 使用新的系统设计:直接在用于数据湖的低成本存储上实现与数据仓库中类似的数据架构和数据管理功能。Lakehouse首先基于标准文件格式(如Apache Parquet、ORC等)将数据存储在独立部署的低成本对象存储(例如Amazon S3、Aliyun OSS)中,并允许客户端使用标准文件格式直接从该存储中读取对象,这样许多ML库(例如TensorFlow和Spark MLlib)就可以读取数据湖文件格式(如Parquet)。其次,为了做到事务管理和版本控制,Lakehouse提供了公共元数据层,数据访问通过逻辑表的形式对外暴露,比如lakehouse框架实现之一的Apache Iceberg的表由一系列快照文件组成,每个快照文件(snapshot)存储一个清单列表文件(manifest list),清单列表文件记录1至多个清单文件(manifest file)的路径和相关文件的统计数量信息等,而清单文件记录了组成某个快照的数据文件(data file)列表。每行都是每个数据文件的详细描述,包括数据文件的状态、文件路径、分区信息、列级别的统计信息(比如每列的最大最小值、空值数等)、文件的大小以及文件里面数据的行数等信息。数据文件是 Apache Iceberg 表真实存储数据的文件,可以采用parquet、avro等格式。
03-14 ClickHouse MergeTree原理?
MergeTree引擎以及隶属于MergeTree引擎族的所有引擎是Clickhouse表引擎中最重要, 最强大的引擎.MergeTree引擎族中的引擎被设计用于将大量数据写入表中. 这些数据被快速的写入每个表的每个part, 然后在Clickhouse底层会进行多个parts的合并(merge). 这种形式的处理比在插入过程中不断重写存储中的数据要高效得多.主要的功能点:存储按主键(primary key)排序的数据.这允许用户可以创建一个小型的稀疏索引, 有利于更快的在表中找到索要的数据.如果partitioning key被设置, 分片(partitions)可以被使用.Clickhouse支持某些带分区的操作, 对于同一份数据进行处理, 带有分区的操作会比一般操作更有效. 当在查询语句中指定了分区后, Clickhouse会根据分区信息来进行数据的切分, 这样极大程度上提升了查询的性能.数据副本机制支持(Replication)ReplicatedMergeTree并引擎提供了数据副本机制.支持数据采样如果必要, 可以在表中设置数据采样方式.
03-15 如果有100M的数据需要排序,但只有10M的内存如何排序处理
1. 100M 数据,平均拆分成10个数据块,并在数据块内进行排序得到了10个排序过的数据块,再分别从10个数据块中取出第一个数据放入到内存中2. 在内存中对分别取出的数据进行排序,取出最小的数,这个数就为最小数3. 把最小数放到新的临时空间中,再从第一组数据块中取出一个数据,补到内存中4. 再对内存的数据进行排序,这时最小的数据就为第二个数,放到临时空间中5. 这样依次循环,就可以将数据进行排序
03-17 Doris 什么场景用?
doris 用的比较少,需要资料的可以去找我。
03-22 大数据平台该怎么研发?具体要实现什么功能,有推荐的吗?
保留基本的数据存储业务、组件管理中间件、数据计算框架、UI页面和接口暴露、数据库及其用户权限管理大数据平台应该还是为业务支撑最起码1. 数据处理基础设施生态(比如交换平台 集成平台 资产平台 开发调度平台 数据集市共享 权限管理等等)2.数据处理模型(集成比如onedata数仓或者数据湖方法论到平台中)也可称为数据中台模型3. 后续就是去支撑各业务产品线(业务中台)比如实时计算平台实时调试预览语法和逻辑检查JobPlan字段级血缘分析BI 展示元数据查询实时任务监控实时作业信息数据地图数据源注册参考:https://github.com/DataLinkDC/dlinkhttp://www.dlink.top/#/zh-CN/introduce其他:DSS+Linkis
03-23 Checkpoint较大或者时间较长的情况? 怎么解决的?
1. 计算量大,CPU密集性,导致TM内线程一直在processElement,而没有时间做CP ----过滤掉部分数据;增大并行度2. 数据倾斜3. 频繁FULL GC -- 减少key数量;增大TM内存4. 出现反压减少checkpoint间隔,增量处理用聚合开窗减小内部状态大小设置更短的ttl全量 Checkpoint 和 增量 Checkpoint。全量 Checkpoint 会把当前的 state 全部备份一次到持久化存储,而增量 Checkpoint,则只备份上一次 Checkpoint 中不存在的 state,因此增量 Checkpoint 每次上传的内容会相对更好,在速度上会有更大的优势。Checkpoint 同步阶段慢对于非 RocksDBBackend,可以考虑开启异步 snapshot。如果开启了异步 snapshot 还是慢,需要使用 AsyncProfile 查看整个JVMCheckpoint 异步阶段慢异步阶段,TaskManager 主要将 state 备份到持久化存储 HDFS。对于非 RocksDBBackend,主要瓶颈来自于网络,可以考虑观察网络的 metric,或者使用 iftop 观察对应机器上的网络流量情况。对于 RocksDB,则需要从本地读取文件,写入到远程的持久化存储上 HDFS,所以不仅需要考虑网络的瓶颈,还需要考虑本地磁盘的性能。
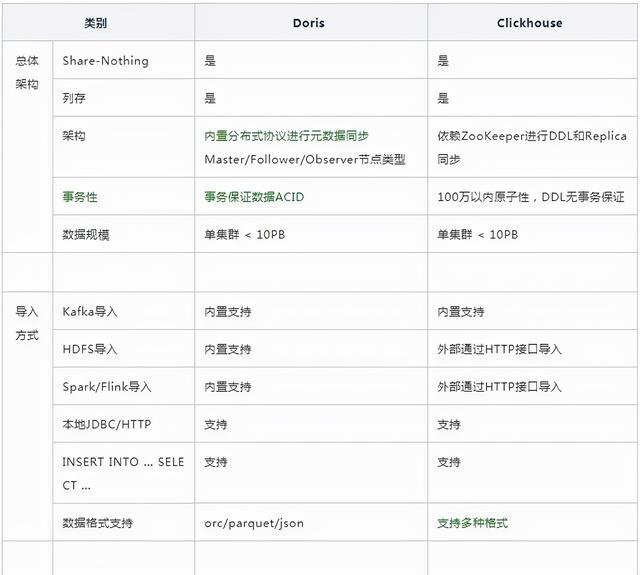
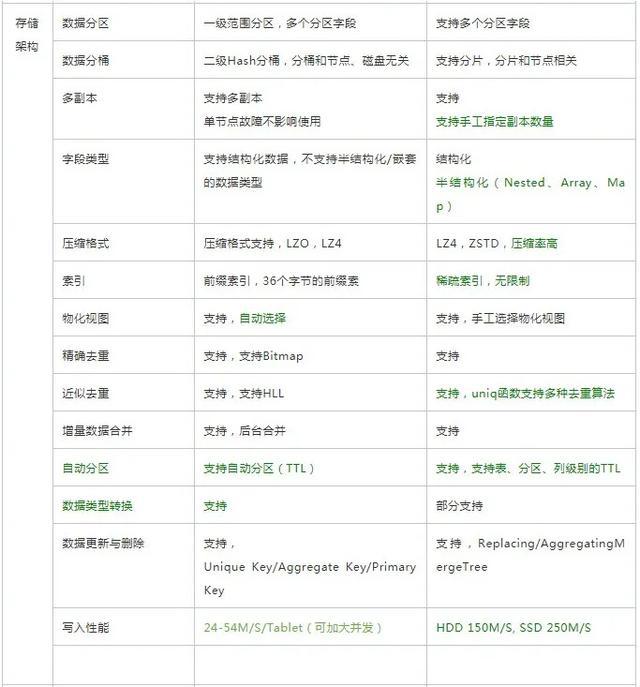
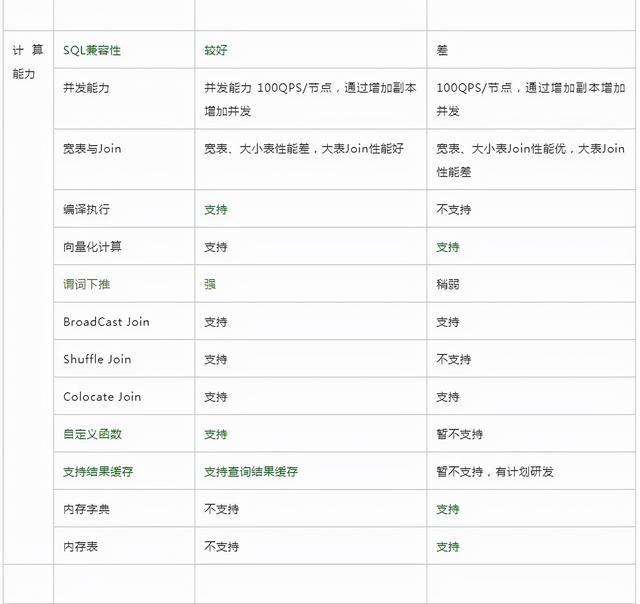
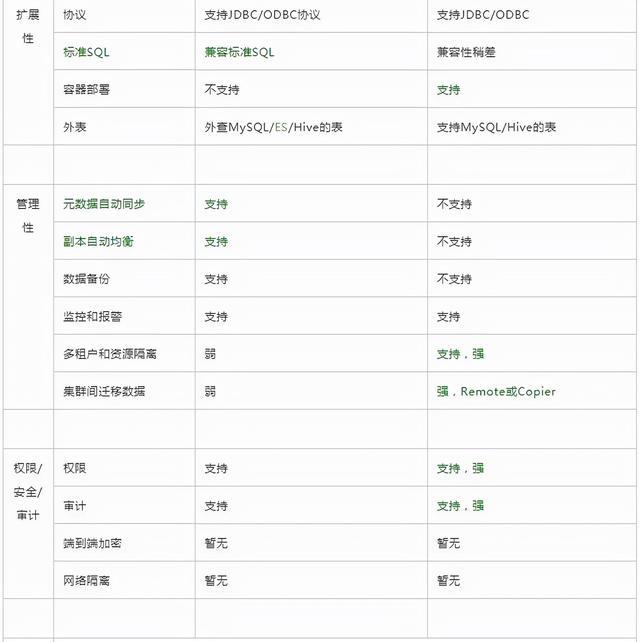
03-24 Clickhouse,Hbase,Doris的区别 ?
Doris更优的方面使用更简单,如建表更简单,SQL标准支持更好, Join性能更好,导数功能更强大运维更简单,如灵活的扩缩容能力,故障节点自动恢复,社区提供的支持更好分布式更强,支持事务和幂等性导数,物化视图自动聚合,查询自动路由,全面元数据管理ClickHouse更优的方面性能更佳,导入性能和单表查询性能更好,同时可靠性更好功能丰富,非常多的表引擎,更多类型和函数支持,更好的聚合函数以及庞大的优化参数选项集群管理工具更多,更好多租户和配额管理,灵活的集群管理,方便的集群间迁移工具那么两者之间如何选择呢?业务场景复杂数据规模巨大,希望投入研发力量做定制开发,选ClickHouse希望一站式的分析解决方案,少量投入研发资源,选择Doris另外, Doris源自在线广告系统,偏交易系统数据分析;ClickHouse起源于网站流量分析服务,偏互联网数据分析,但是这两类场景这两个引擎都可以覆盖。如果说两者不那么强的地方,ClickHouse的问题是使用门槛高、运维成本高和分布式能力太弱,需要较多的定制化和较深的技术实力,Doris的问题是性能差一些可靠性差一些,下面就深入分析两者的差异。

| ** |
Hbase | Kudu | Clickhouse |
|---|---|---|---|
| 数据存储 | Zookeeper保存元数据,数据写入HDFS(非结构化数据) | master保存元数据,数据及副本存储在tserver(强类型数据) | Zookeeper保存元数据,数据存储在本地,且会压缩 |
| 查询 | 查询比较麻烦,Phoenix集成之后比较好点 | 查询比较麻烦,集成Impala之后表现优秀 | 高效的查询能力 |
| 数据读写 | 支持随机读写,删除。更新操作是插入一条新timestamp的数据 | 支持读写,删除,更新 | 支持读写,但不能删除和更新 |
| 维护 | 需要同时维护HDFS、Zookeeper和Hbase(甚至于Phoenix) | CDH版本维护简单,Apache版需要单独维护,额外还有Impala | 额外维护Zookeeper |
一起学习Doris
03-25 一:Doris的总体架构
https://www.yuque.com/wanglegebo/zb3id0/we98u6
03-28 二:Doris 存储结构

若有收获,就点个赞吧
0 人点赞
