1 Flink CEP 是什么
FlinkCEP - Flink的复杂事件处理。它可以让你在无限事件流中检测出特定的事件模型,有机会掌握数据中重要的那部分
2 Flink CEP 特点
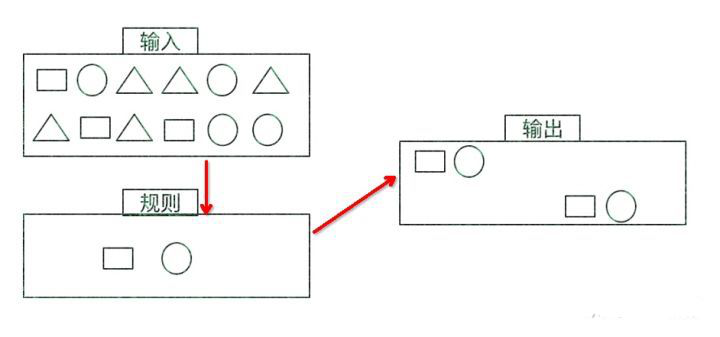
o 目标:从有序的简单事件流中发现一些高阶特征
o 输入:一个或多个由简单事件构成的事件流
o 处理:识别简单事件之间的内在联系,多个符合一定规则的简单事件构成复杂事件
o 输出:满足规则的复杂事件
3 Flink CEP 应用场景
o 风险控制:对用户异常行为模式进行实时检测,当一个用户发生了不该发生的行为,判定这个用户是不是有违规操作的嫌疑。
o 策略营销:用预先定义好的规则对用户的行为轨迹进行实时跟踪,对行为轨迹匹配预定义规则的用户实时发送相应策略的推广。
o 运维监控:灵活配置多指标、多依赖来实现更复杂的监控模式。
4 Flink CEP原理
Flink CEP内部是用NFA(非确定有限自动机)来实现的,由点和边组成的一个状态图,以一个初始状态作为起点,经过一系列的中间状态,达到终态。点分为起始状态、中间状态、最终状态三种,边分为take、ignore、proceed三种。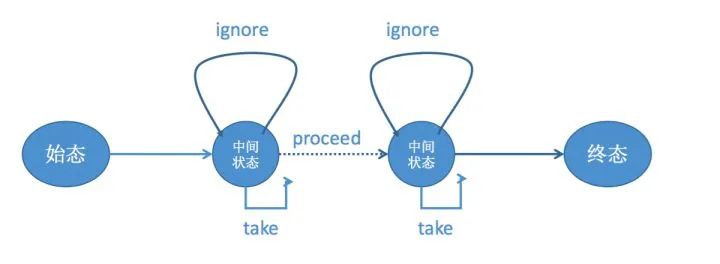
o take:必须存在一个条件判断,当到来的消息满足take边条件判断时,把这个消息放入结果集,将状态转移到下一状态。
o ignore:当消息到来时,可以忽略这个消息,将状态自旋在当前不变,是一个自己到自己的状态转移。
o proceed:又叫做状态的空转移,当前状态可以不依赖于消息到来而直接转移到下一状态。
模式API (Pattern API)
个体模式:组成复杂规则的每一个单独的模式定义,就是“个体模式”
A 量词
在FlinkCEP中,你可以通过这些方法指定循环模式:
o pattern.oneOrMore() 指定期望一个给定事件出现一次或者多次的模式
o pattern.times(#fTimes) 指定期望一个给定事件出现特定次数的模式,例如出现4次A
o pattern.times(#fromTimes, #toTimes) 指定期望一个给定事件出现次数在一个最小值和最大值中间的模式,比如出现2-4次A
o pattern.greedy() 方法让循环模式变成贪心的
o pattern.optional() 方法让所有的模式变成可选的,不管是否是循环模式
// 期望出现4次start.times(4)
// 期望出现0或者4次start.times(4).optional()
// 期望出现2、3或者4次start.times(2, 4)
// 期望出现2、3或者4次,并且尽可能的重复次数多start.times(2, 4).greedy()
// 期望出现0、2、3或者4次start.times(2, 4).optional()
// 期望出现0、2、3或者4次,并且尽可能的重复次数多start.times(2, 4).optional().greedy()
// 期望出现1到多次start.oneOrMore()
// 期望出现1到多次,并且尽可能的重复次数多start.oneOrMore().greedy()
// 期望出现0到多次start.oneOrMore().optional()
// 期望出现0到多次,并且尽可能的重复次数多start.oneOrMore().optional().greedy()
// 期望出现2到多次start.timesOrMore(2)
// 期望出现2到多次,并且尽可能的重复次数多start.timesOrMore(2).greedy()
// 期望出现0、2或多次start.timesOrMore(2).optional()
// 期望出现0、2或多次,并且尽可能的重复次数多start.timesOrMore(2).optional().greedy()
B 条件
对每个模式你可以指定一个条件来决定一个进来的事件是否被接受进入这个模式,指定判断事件属性的条件可以通过
o pattern.where() 增加新的条件,多个条件应该同时满足
pattern.where(event => … / 一些判断条件 /)
o pattern.or() 增加新的条件,多个条件满足任意一个都可以
pattern.where(event => … / 一些判断条件 /)
.or(event => … / 替代条件 /)
o pattern.until() 为循环模式指定一个停止条件。意思是满足了给定的条件的事件出现后,就不会再有事件被接受进入模式了。如”(a+ until b)” (一个或者更多的”a”直到”b”)
pattern.oneOrMore().until(event => … / 替代条件 /)
以上这些可以是可迭代的
o subtype(subClass) 为当前模式定义一个子类型条件。一个事件只有是这个子类型的时候才能匹配到模式
pattern.subtype(classOf[SubEvent])
o oneOrMore() 指定模式期望匹配到的事件至少出现一次。默认(在子事件间)使用松散的内部连续性。关于内部连续性的更多信息可以参考连续性。提示:推荐使用until()或者within()来清理状态。
pattern.oneOrMore()
o timesOrMore(#times) 指定模式期望匹配到的事件正好出现的次数。默认(在子事件间)使用松散的内部连续性。关于内部连续性的更多信息可以参考连续性。
pattern.timesOrMore(2)
o optional() 指定这个模式是可选的,也就是说,它可能根本不出现。这对所有之前提到的量词都适用。
pattern.oneOrMore().optional()
o greedy() 指定这个模式是贪心的,也就是说,它会重复尽可能多的次数。这只对量词适用,现在还不支持模式组。
pattern.oneOrMore().greedy()
迭代条件 : 这是最普遍的条件类型。使用它可以指定一个基于前面已经被接受的事件的属性或者它们的一个子集的统计数据来决定是否接受时间序列的条件。
pattern.oneOrMore()
.subtype(classOf[SubEvent])
.where(
(value, ctx) => {
lazy val sum = ctx.getEventsForPattern(“middle”).map(_.getPrice).sum
value.getName.startsWith(“foo”) && sum + value.getPrice < 5.0
}
)
组合模式:很多个体模式组合起来,就形成了整个的模式序列
FlinkCEP支持事件之间如下形式的连续策略
| 策略 | 说明 | 方法 |
|---|---|---|
| 严格连续 | 期望所有匹配的事件严格的一个接一个出现,中间没有任何不匹配的事件 | next notNext |
| 严松散连续 | 忽略匹配的事件之间的不匹配的事件 | followedBy notFollowedBy |
| 不确定的松散连续 | 更进一步的松散连续,允许忽略掉一些匹配事件的附加匹配。可以使用下面的方法来指定模式之间的连续策略 | followedByAny |
// 严格连续val strict: Pattern[Event, _] = start.next(“event”).where(…)
// 松散连续val relaxed: Pattern[Event, _] = start.followedBy(“event”).where(…)
// 不确定的松散连续val nonDetermin: Pattern[Event, _] = start.followedByAny(“event”).where(…)
// 严格连续的NOT模式val strictNot: Pattern[Event, _] = start.notNext(“not”).where(…)
// 松散连续的NOT模式val relaxedNot: Pattern[Event, _] = start.notFollowedBy(“not”).where(…)
松散连续意味着跟着的事件中,只有第一个可匹配的事件会被匹配上,而不确定的松散连接情况下,有着同样起始的多个匹配会被输出。举例来说,模式”a b”,给定事件序列”a”,”c”,”b1”,”b2”,会产生如下的结果:
“a”和”b”之间严格连续:{} (没有匹配),”a”之后的”c”导致”a”被丢弃。
“a”和”b”之间松散连续:{a b1},松散连续会”跳过不匹配的事件直到匹配上的事件”。
“a”和”b”之间不确定的松散连续:{a b1}, {a b2},这是最常见的情况。
也可以为模式定义一个有效时间约束。例如,你可以通过pattern.within()方法指定一个模式应该在10秒内发生。这种时间模式支持处理时间和事件时间.
next.within(Time.seconds(10))
循环模式中的连续性
对于循环模式(例如oneOrMore()和times())),默认是松散连续。如果想使用严格连续,你需要使用consecutive()方法明确指定, 如果想使用不确定松散连续,你可以使用allowCombinations()方法。
consecutive
与oneOrMore()和times()一起使用, 在匹配的事件之间施加严格的连续性, 也就是说,任何不匹配的事件都会终止匹配(和next()一样)。如果不使用它,那么就是松散连续(和followedBy()一样)
Pattern.begin(“start”).where(.getName().equals(“c”))
.followedBy(“middle”).where(.getName().equals(“a”))
.oneOrMore().consecutive()
.followedBy(“end1”).where(_.getName().equals(“b”))
输入:C D A1 A2 A3 D A4 B,会产生下面的输出:
如果施加严格连续性: {C A1 B},{C A1 A2 B},{C A1 A2 A3 B}不施加严格连续性: {C A1 B},{C A1 A2 B},{C A1 A2 A3 B},{C A1 A2 A3 A4 B}
allowCombinations
与oneOrMore()和times()一起使用, 在匹配的事件中间施加不确定松散连续性(和followedByAny()一样)。如果不使用,就是松散连续(和followedBy()一样)
Pattern.begin(“start”).where(.getName().equals(“c”))
.followedBy(“middle”).where(.getName().equals(“a”))
.oneOrMore().allowCombinations()
.followedBy(“end1”).where(_.getName().equals(“b”))
输入:C D A1 A2 A3 D A4 B,会产生如下的输出:
如果使用不确定松散连续:
{C A1 B},{C A1 A2 B},{C A1 A3 B},{C A1 A4 B},{C A1 A2 A3 B},{C A1 A2 A4 B},{C A1 A3 A4 B},{C A1 A2 A3 A4 B}
如果不使用:{C A1 B},{C A1 A2 B},{C A1 A2 A3 B},{C A1 A2 A3 A4 B}
5 匹配后跳过策略
对于一个给定的模式,同一个事件可能会分配到多个成功的匹配上。为了控制一个事件会分配到多少个匹配上,你需要指定跳过策略AfterMatchSkipStrategy。有五种跳过策略,如下:
o NO_SKIP: 每个成功的匹配都会被输出。
o SKIP_TO_NEXT: 丢弃以相同事件开始的所有部分匹配。
o SKIP_PAST_LAST_EVENT: 丢弃起始在这个匹配的开始和结束之间的所有部分匹配。
o SKIP_TO_FIRST: 丢弃起始在这个匹配的开始和第一个出现的名称为PatternName事件之间的所有部分匹配。
o SKIP_TO_LAST: 丢弃起始在这个匹配的开始和最后一个出现的名称为PatternName事件之间的所有部分匹配。
val skipStrategy =
AfterMatchSkipStrategy.skipToFirst(“patternName”).throwExceptionOnMiss()
Pattern.begin(“patternName”, skipStrategy)
例如,给定一个模式b+ c和一个数据流b1 b2 b3 c,不同跳过策略之间的不同如下:
| 跳过策略 | 结果 | 描述 |
|---|---|---|
| NO_SKIP | b1 b2 b3 c b2 b3 c b3 c |
找到匹配b1 b2 b3 c之后, 不会丢弃任何结果 |
| SKIP_TO_NEXT | b1 b2 b3 c b2 b3 c b3 c |
找到匹配b1 b2 b3 c之后, 不会丢弃任何结果, 因为没有以b1开始的其他匹配 |
| SKIP_PAST_LAST_EVENT | b1 b2 b3 c | 找到匹配b1 b2 b3 c之后, 会丢弃其他所有的部分匹配。 |
| SKIP_TO_FIRST | b1 b2 b3 c b2 b3 c b3 c |
找到匹配b1 b2 b3 c之后, 会尝试丢弃所有在b1之前开始的部分匹配, 但没有这样的匹配, 所以没有任何匹配被丢弃。 |
| SKIP_TO_LAST | b1 b2 b3 c b3 c |
找到匹配b1 b2 b3 c之后 ,会尝试丢弃所有在b3之前开始的部分匹配, 有一个这样的b2 b3 c被丢弃。 |
6 模式的检测
在指定了要寻找的模式后,该把它们应用到输入流上来发现可能的匹配了。为了在事件流上运行你的模式,需要创建一个PatternStream。给定一个输入流input,一个模式pattern和一个可选的用来对使用事件时间时有同样时间戳或者同时到达的事件进行排序的比较器comparator
object Cep {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment =
StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val loginDS: DataStream[LoginInfo] = env.fromElements("")<br /> .map(data => {<br /> val datas: Array[String] = data.split(",")<br /> LoginInfo(datas(0), datas(1), datas(2).toInt,datas(3).toLong)<br /> }<br /> )<br /> // 创建规则<br /> val pattern: Pattern[LoginInfo, LoginInfo] = Pattern.begin[LoginInfo]("start")<br /> // 增加新的条件,多个条件应该同时满足 .where(_.age > 1)<br /> .where(_.age < 12)<br /> // 应用规则:将规则应用到数据流中 val loginPS: PatternStream[LoginInfo] = CEP.pattern(loginDS,pattern)// 获取规则的结果 val ds: DataStream[String] = loginPS.select(<br /> map => {<br /> map.toString<br /> })<br /> ds.print()<br /> env.execute()<br /> }<br />}<br />case class LoginInfo(<br /> id:String,<br /> name:String,<br /> age:Int,<br /> loginTime:Long<br /> )
7 从模式中选取
创建 PatternStream 之后,就可以应用 select 或者 flatselect 方法,从检测到的事件序列中提取事件了
select() 方法需要输入一个 select function 作为参数,每个成功匹配的事件序列都会调用它
select() 以一个 Map[String,Iterable [IN]] 来接收匹配到的事件序列,其中 key 就是每个模式的名称,而 value 就是所有接收到的事件的 Iterable 类型
val loginPS: PatternStream[LoginInfo] = CEP.pattern(loginDS,pattern)
val outputTag: OutputTag[String] = OutputTagString
val result: SingleOutputStreamOperator[CompleLogin] =loginPS.select(outputTag){
(pattern: Map[String, Iterable[LoginInfo]], timestamp: Long, out: Collector[TimeoutLogin]) =>
out.collect(TimeoutLogin())
} {
(pattern: mutable.Map[String, Iterable[LoginInfo]], out: Collector[CompleLogin]) =>
out.collect(CompleLogin())
}
val timeoutResult: DataStream[TimeoutLogin] =result.getSideOutput(outputTag)

若有收获,就点个赞吧
0 人点赞
