前言
Flink SQL的窗口操作在straming的实现上增添了不少东西。是用起来越来越方便。本篇主要内容:
o Watermark
o 滚动窗口
o 滑动窗口
o 累积窗口函数
o 窗口分组聚合GROUPING SETS
o Clue幂集函数
o Over函数
Watermark
引入
由于实时计算的输入数据是持续不断的,因此我们需要一个有效的进度指标,来帮助我们确定关闭时间窗口的正确时间点,保证关闭窗口后不会再有数据进入该窗口,可以安全输出这个窗口的聚合结果。
而Watermark就是一种衡量Event Time进展的有效机制。随着时间的推移,最早流入实时计算的数据会被处理完成,之后流入的数据处于正在处理状态。处于正在处理部分的和已处理部分的交界的时间戳,可以被定义为Watermark,代表在此之前的事件已经被处理完成并输出。
针对乱序的流,Watermark也至关重要,即使部分事件延迟到达,也不会影响窗口计算的正确性。此外,并行数据流中,当算子(Operator)有多个输入流时,算子的Event Time以最小流Event Time为准。
具体可参考Flink Straming的原理介绍:
Flink的窗口、时间语义,Watermark机制,多代码案例详解,Flink学习入门(三)
watermark策略
Flink SQL提供了几种常用的watermark策略。
1. 严格意义上递增的时间戳,发出到目前为止已观察到的最大时间戳的水印。时间戳小于最大时间戳的行不会迟到。watermark for rowtime_column as rowtime_column
2. 递增的时间戳,发出到目前为止已观察到的最大时间戳为负1的水印。时间戳等于或小于最大时间戳的行不会迟到。watermark for rowtime_column as rowtime_column - INTERVAL ‘1’ SECOND.
3. 有界时间戳(乱序)发出水印,它是观察到的最大时间戳减去指定的延迟, 例如,watermark for rowtime_column as rowtime_column - INTERVAL’5’SECOND是5秒的延迟水印策略。watermark for rowtime_column as rowtime_column - INTERVAL ‘string’ timeUnit.
现常用的语法
watermark [watermarkName] for
| 参数 | 是否必填 | 说明 |
|---|---|---|
| watermarkName | 否 | 标识Watermark的名字。 |
| 是 | ||
| withOffset | 是 | Watermark的生成策略,根据 |
| offset | 是 | Watermark值与Event Time值的偏移量,单位为毫秒。 |
窗口函数
滚动窗口
滚动窗口(TUMBLE)将每个元素分配到一个指定大小的窗口中。通常,滚动窗口有一个固定的大小,并且不会出现重叠。例如,如果指定了一个5分钟大小的滚动窗口,无限流的数据会根据时间划分为[0:00, 0:05)、[0:05, 0:10)、[0:10, 0:15)等窗口。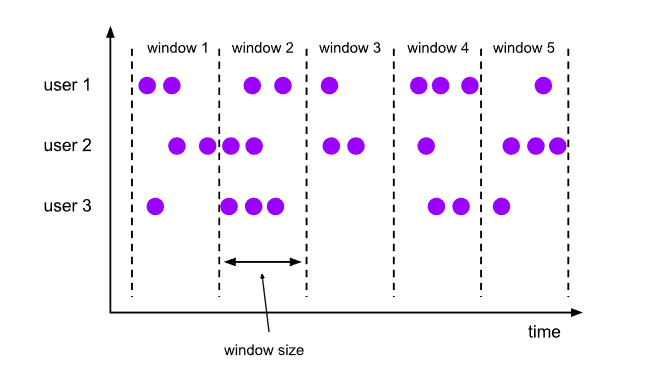
语法
TUMBLE函数用在GROUP BY子句中,用来定义滚动窗口。TUMBLE(< time-attr>, < size-interval>) < size-interval>: INTERVAL ‘string’ timeUnit
< time-attr>参数必须是时间流中的一个合法的时间属性字段
标识函数
使用标识函数选出窗口的起始时间或者结束时间,窗口的时间属性用于下级Window的聚合
| 窗口标识函数 | 返回类型 | 描述 |
|---|---|---|
| TUMBLE_START(time-attr, size-interval) | TIMESTAMP | 返回窗口的起始时间(包含边界)。例如[00:10,00:15)窗口,返回00:10 |
| TUMBLE_END(time-attr, size-interval) | TIMESTAMP | 返回窗口的结束时间(包含边界)。例如[00:00, 00:15]窗口,返回00:15。 |
| TUMBLE_ROWTIME(time-attr, size-interval) | TIMESTAMP(rowtime-attr) | 返回窗口的结束时间(不包含边界)。例如[00:00, 00:15]窗口,返回00:14:59.999。返回值是一个rowtime attribute,即可以基于该字段做时间属性的操作,例如,级联窗口只能用在基于Event Time的Window上,详情请参见级联窗口。 |
| TUMBLE_PROCTIME(time-attr, size-interval) | TIMESTAMP(rowtime-attr) | 返回窗口的结束时间(不包含边界)。例如[00:00, 00:15]窗口,返回00:14:59.999。返回值是一个Proctime Attribute,即可以基于该字段做时间属性的操作。例如,级联窗口只能用在基于Processing Time的Window上,详情请参见级联窗口。 |
新版本语法(简洁)
TUMBLE(TABLE data, DESCRIPTOR(timecol), size)
o data: 是一个表参数。
o timecol: 是一个列描述符指示应该映射到哪个时间的属性列。
o size: 是一个持续时间指定窗口的宽度。
滑动窗口
滑动窗口(HOP),也被称作Sliding Window。不同于滚动窗口,滑动窗口的窗口可以重叠。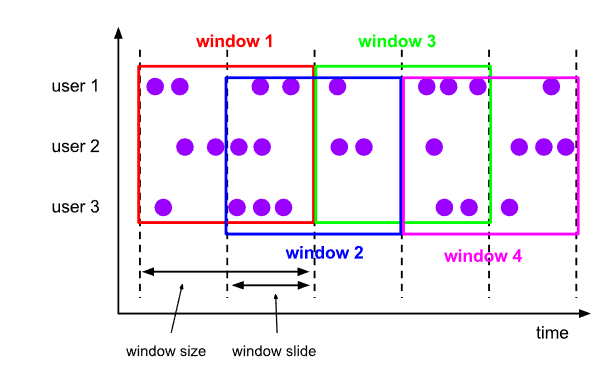
通常,大部分元素符合多个窗口情景,窗口是重叠的。因此,滑动窗口在计算移动平均数(moving averages)时很实用。例如,计算过去5分钟数据的平均值,每10秒钟更新一次,可以设置slide为10秒,size为5分钟。下图为您展示间隔为30秒,窗口大小为1分钟的滑动窗口。
语法
下面不再介绍之前版本的写法,按1.13版本来 HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])
o data: 是一个表参数,数据表。
o timecol: 是一个列描述符指示应该映射到哪个时间的属性列。
o slide: 滑动时间。
o size: 是一个持续时间指定窗口的宽度。
累积窗口函数
累积窗口在某些情况下非常有用,例如在固定的窗口间隔内早期触发的滚动窗口。例如,每日从00:00到每分钟累计计算UV值,10:00的UV值表示00:00到10:00的UV总数。这可以通过累积窗口轻松有效地实现。
累积函数将元素分配给窗口,这些窗口在初始步长间隔内覆盖行,并在每一步扩展到一个更多的步长(保持窗口开始固定),直到最大窗口大小。你可以把累积函数看作是先应用具有最大窗口大小的滚动窗口,然后把每个滚动窗口分成几个窗口,每个窗口的开始和结束都有相同的步长差。所以累积窗口确实有重叠,而且没有固定的大小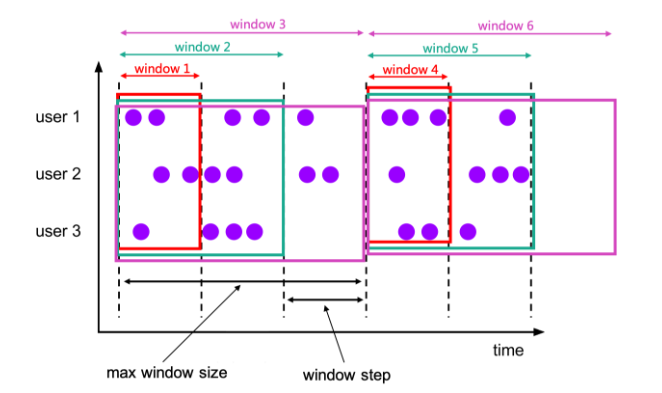
例如,你可以对1小时的步长和1天的最大长度有一个累积窗口,你就会得到窗口 [00:00, 01:00), [00:00, 02:00), [00:00, 03:00), …, [00:00, 24:00)
语法
CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)
o data: 是一个表参数,数据表。
o timecol: 是一个列描述符指示应该映射到哪个时间的属性列。
o step: 步长
o size: 是一个持续时间指定窗口的宽度!
以此为例:数据:goods
| time | price | item |
|---|---|---|
| 2020-04-15 08:05 | 4.00 | C |
| 2020-04-15 08:07 | 2.00 | A |
| 2020-04-15 08:09 | 5.00 | D |
| 2020-04-15 08:11 | 3.00 | B |
| 2020-04-15 08:13 | 1.00 | E |
| 2020-04-15 08:17 | 6.00 | F |
SELECT window_start, window_end, SUM(price)
FROM TABLE(
CUMULATE(TABLE goods, DESCRIPTOR(time), INTERVAL ‘2’ MINUTES, INTERVAL ‘10’ MINUTES))
GROUP BY window_start, window_end
| window_start | window_end | price |
|---|---|---|
| 2020-04-15 08:00 | 2020-04-15 08:06 | 4.00 |
| 2020-04-15 08:00 | 2020-04-15 08:08 | 6.00 |
| 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 |
| 2020-04-15 08:10 | 2020-04-15 08:12 | 3.00 |
| 2020-04-15 08:10 | 2020-04-15 08:14 | 4.00 |
| 2020-04-15 08:10 | 2020-04-15 08:16 | 4.00 |
| 2020-04-15 08:10 | 2020-04-15 08:18 | 10.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 |
窗口分组聚合GROUPING SETS
窗口聚合也支持分组集语法。分组集允许更复杂的分组标准比描述所GROUP by操作。指定行分别分组,每个分组集和聚合计算每组一样简单的group by子句 与下面相同 ROLLUP 汇总是一种速记符号用于指定一个常见类型的分组集。它代表给定的表达式和所有前缀列表的列表,包括空列表。 窗口与汇总需要聚合window_start和window_end列必须在GROUP BY子句,但不是在ROLLUP中条款。
val kafka_sql=
“””
|CREATE TABLE goods (
| item_id VARCHAR,
| item_type VARCHAR,
| event_time varchar,
| on_sell_time AS TO_TIMESTAMP(event_time),
| price DOUBLE,
| WATERMARK FOR on_sell_time AS on_sell_time - INTERVAL ‘1’ SECOND
|) WITH (
| ‘connector’ = ‘kafka’,
| ‘topic’ = ‘testtopic’,
| ‘properties.bootstrap.servers’ = ‘xxxxxx’,
| ‘format’ = ‘json’
|)
|”””.stripMargin
tableEnv.executeSql(kafka_sql)
val query=<br /> """<br /> |SELECT window_start, window_end, item_type, SUM(price) as price<br /> | FROM TABLE(<br /> | TUMBLE(TABLE goods, DESCRIPTOR(on_sell_time), INTERVAL '5' MINUTES))<br /> | GROUP BY window_start, window_end, GROUPING SETS ((item_type), ())<br /> |""".stripMargin<br /> <br /> 或者 <br /> val query=<br /> """<br /> |SELECT window_start, window_end, item_type, SUM(price) as price<br /> | FROM TABLE(<br /> | TUMBLE(TABLE goods, DESCRIPTOR(on_sell_time), INTERVAL '5' MINUTES))<br /> | GROUP BY window_start, window_end, ROLLUP (item_type)<br /> |""".stripMargin
tableEnv.executeSql(query).print()
数据源write(item)方法后发送kafka的消息
def test_over_window(): Array[AnyRef] ={
Array(
Map(
“item_id”->”ITEM001”,
“item_type”->”apple”,
“event_time”->”2020-04-15 10:01:00”,
“price”->20 ),
Map(
“item_id”->”ITEM002”,
“item_type”->”apple”,
“event_time”->”2020-04-15 10:02:00”,
“price”->50 ),
Map(
“item_id”->”ITEM003”,
“item_type”->”apple”,
“event_time”->”2020-04-15 10:03:00”,
“price”->30 ),
Map(
“item_id”->”ITEM004”,
“item_type”->”apple”,
“event_time”->”2020-04-15 10:04:00”,
“price”->60 ),
Map(
“item_id”->”ITEM005”,
“item_type”->”apple”,
“event_time”->”2020-04-15 10:05:00”,
“price”->40 ),
Map(
“item_id”->”ITEM006”,
“item_type”->”apple”,
“event_time”->”2020-04-15 10:06:00”,
“price”->20 ),
Map(
“item_id”->”ITEM007”,
“item_type”->”apple”,
“event_time”->”2020-04-15 10:07:00”,
“price”->10 ),
Map(
“item_id”->”ITEM008”,
“item_type”->”orange”,
“event_time”->”2020-04-15 10:08:00”,
“price”->20 ),
Map(
“item_id”->”ITEM009”,
“item_type”->”orange”,
“event_time”->”2020-04-15 10:09:00”,
“price”->21 ),
Map(
“item_id”->”ITEM010”,
“item_type”->”apple”,
“event_time”->”2020-04-15 10:10:00”,
“price”->22 ),
Map(
“item_id”->”ITEM011”,
“item_type”->”orange”,
“event_time”->”2020-04-15 10:11:00”,
“price”->26 )
)
}
结果:
| window_start | window_end | item_type | price |
|---|---|---|---|
| 2020-04-15 10:00:00.000 | 2020-04-15 10:05:00.000 | apple | 160.0 |
| 2020-04-15 10:00:00.000 | 2020-04-15 10:05:00.000 | (NULL) | 160.0 |
| 2020-04-15 10:05:00.000 | 2020-04-15 10:10:00.000 | apple | 70.0 |
| 2020-04-15 10:05:00.000 | 2020-04-15 10:10:00.000 | orange | 41.0 |
| 2020-04-15 10:05:00.000 | 2020-04-15 10:10:00.000 | (NULL) | 111.0 |
CUBE
CUBE是一种用于指定公共分组集类型的简写符号。它表示给定的列表及其所有可能的子集——幂集
def cube(): Unit ={
val kafka_sql=
“””
|CREATE TABLE goods (
| item_id VARCHAR,
| item_type VARCHAR,
| event_time varchar,
| on_sell_time AS TO_TIMESTAMP(event_time),
| price DOUBLE,
| WATERMARK FOR on_sell_time AS on_sell_time - INTERVAL ‘1’ SECOND
|) WITH (
| ‘connector’ = ‘kafka’,
| ‘topic’ = ‘testtopic’,
| ‘properties.bootstrap.servers’ = ‘xxxxx’,
| ‘format’ = ‘json’
|)
|”””.stripMargin
tableEnv.executeSql(kafka_sql)
val query=<br /> """<br /> |SELECT window_start, window_end,item_id, item_type, SUM(price) as price<br /> | FROM TABLE(<br /> | TUMBLE(TABLE goods, DESCRIPTOR(on_sell_time), INTERVAL '5' MINUTES))<br /> | GROUP BY window_start, window_end, CUBE(item_id,item_type)<br /> |""".stripMargin
tableEnv.executeSql(query).print()<br /> <br /> }<br />数据源write(item)方法后发送kafka的消息<br />def test_clue(): Array[AnyRef] ={<br /> Array(<br /> Map(<br /> "item_id"->"ITEM001",<br /> "item_type"->"apple",<br /> "event_time"->"2020-04-15 10:01:00",<br /> "price"->20 ),<br /> Map(<br /> "item_id"->"ITEM001",<br /> "item_type"->"apple",<br /> "event_time"->"2020-04-15 10:02:00",<br /> "price"->50 ),<br /> Map(<br /> "item_id"->"ITEM001",<br /> "item_type"->"apple",<br /> "event_time"->"2020-04-15 10:03:00",<br /> "price"->30 ),<br /> Map(<br /> "item_id"->"ITEM001",<br /> "item_type"->"apple",<br /> "event_time"->"2020-04-15 10:04:00",<br /> "price"->60 ),<br /> Map(<br /> "item_id"->"ITEM001",<br /> "item_type"->"apple",<br /> "event_time"->"2020-04-15 10:05:00",<br /> "price"->40 ),<br /> Map(<br /> "item_id"->"ITEM002",<br /> "item_type"->"apple",<br /> "event_time"->"2020-04-15 10:06:00",<br /> "price"->20 ),<br /> Map(<br /> "item_id"->"ITEM002",<br /> "item_type"->"apple",<br /> "event_time"->"2020-04-15 10:07:00",<br /> "price"->10 ),<br /> Map(<br /> "item_id"->"ITEM002",<br /> "item_type"->"orange",<br /> "event_time"->"2020-04-15 10:08:00",<br /> "price"->20 ),<br /> Map(<br /> "item_id"->"ITEM002",<br /> "item_type"->"orange",<br /> "event_time"->"2020-04-15 10:09:00",<br /> "price"->21 ),<br /> Map(<br /> "item_id"->"ITEM02",<br /> "item_type"->"apple",<br /> "event_time"->"2020-04-15 10:10:00",<br /> "price"->22 ),<br /> Map(<br /> "item_id"->"ITEM02",<br /> "item_type"->"orange",<br /> "event_time"->"2020-04-15 10:11:00",<br /> "price"->26 )<br /> )<br /> }<br />结果:
| window_start | window_end | item_id | item_type | price |
|---|---|---|---|---|
| 2020-04-15 10:00:00.000 | 2020-04-15 10:05:00.000 | (NULL) | apple | 140.0 |
| 2020-04-15 10:00:00.000 | 2020-04-15 10:05:00.000 | ITEM001 | apple | 140.0 |
| 2020-04-15 10:00:00.000 | 2020-04-15 10:05:00.000 | ITEM001 | (NULL) | 140.0 |
| 2020-04-15 10:00:00.000 | 2020-04-15 10:05:00.000 | (NULL) | (NULL) | 140.0 |
| 2020-04-15 10:05:00.000 | 2020-04-15 10:10:00.000 | (NULL) | apple | 70.0 |
| 2020-04-15 10:05:00.000 | 2020-04-15 10:10:00.000 | ITEM001 | apple | 40.0 |
| 2020-04-15 10:05:00.000 | 2020-04-15 10:10:00.000 | ITEM001 | (NULL) | 40.0 |
| 2020-04-15 10:05:00.000 | 2020-04-15 10:10:00.000 | ITEM002 | orange | 41.0 |
| 2020-04-15 10:05:00.000 | 2020-04-15 10:10:00.000 | (NULL) | orange | 41.0 |
| 2020-04-15 10:05:00.000 | 2020-04-15 10:10:00.000 | ITEM002 | (NULL) | 71.0 |
| 2020-04-15 10:05:00.000 | 2020-04-15 10:10:00.000 | (NULL) | (NULL) | 111.0 |
| 2020-04-15 10:05:00.000 | 2020-04-15 10:10:00.000 | ITEM002 | apple | 30.0 |
over函数
以窗口Top N为例子
def top_n: Unit ={
val kafka_sql=
“””
|CREATE TABLE goods (
| item_id VARCHAR,
| item_type VARCHAR,
| event_time varchar,
| on_sell_time AS TO_TIMESTAMP(event_time),
| price DOUBLE,
| WATERMARK FOR on_sell_time AS on_sell_time - INTERVAL ‘1’ SECOND
|) WITH (
| ‘connector’ = ‘kafka’,
| ‘topic’ = ‘testtopic’,
| ‘properties.bootstrap.servers’ = ‘xxxxx’,
| ‘format’ = ‘json’
|)
|”””.stripMargin
tableEnv.executeSql(kafka_sql)
val query=<br /> """<br /> |SELECT *<br /> | FROM (<br /> | SELECT *, ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY price DESC) as rownum<br /> | FROM (<br /> | SELECT window_start, window_end, item_type, SUM(price) as price, COUNT(*) as cnt<br /> | FROM TABLE(<br /> | TUMBLE(TABLE goods, DESCRIPTOR(on_sell_time), INTERVAL '5' MINUTES))<br /> | GROUP BY window_start, window_end, item_type<br /> | )<br /> | ) WHERE rownum <= 2<br /> |""".stripMargin<br /> tableEnv.executeSql(query).print()<br /> <br /> }<br />数据源也就是上面的test_over_window通过write(item)方法后发送kafka的消息<br />结果:
| window_start | window_end | item_type | price | cnt | rownum |
|---|---|---|---|---|---|
| 2020-04-15 10:00:00.000 | 2020-04-15 10:05:00.000 | apple | 160.0 | 4 | 1 |
| 2020-04-15 10:05:00.000 | 2020-04-15 10:10:00.000 | apple | 70.0 | 3 | 1 |
| 2020-04-15 10:05:00.000 | 2020-04-15 10:10:00.000 | orange | 41.0 | 2 | 2 |
总结:
在Flink SQL窗口中:累积窗口函数, 窗口分组聚合GROUPING SETS,Clue幂集函数, Over函数这些给人眼前一亮,的确是减少了开发工作量。但是需要开发工作者灵活运行才会发挥价值。知识无止境,人生也无止境。

若有收获,就点个赞吧
0 人点赞
