写流程
数据导入方式
1. Broker Load
说明
Broker Load是异步方式,支持的数据源取决于Broker进程支持的数据源。
适用场景
(1)源数据在Broker可以访问的存储系统中。
(2)数据量在几十到百GB级别 。
原理
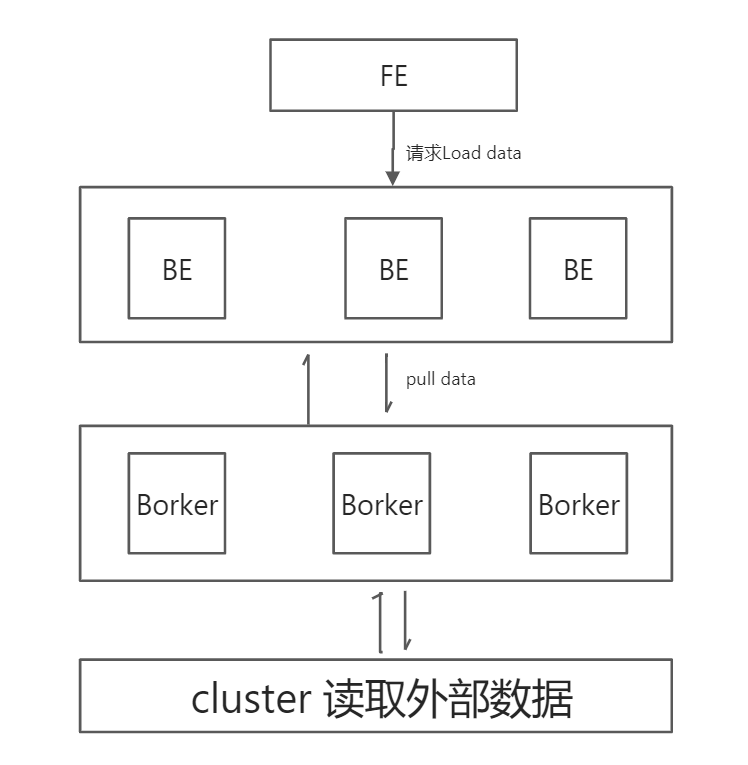
用户在提交导入任务后,FE会生成相应的导入执行计划(plan),BE会执行导入计划将输入导入Doris中,并根据BE的个数和文件的大小,将Plan分给多个BE执行,每个BE导入一部分数据。BE在执行过程中会从Broker拉取数据,在对数据转换之后导入系统。所有BE均完成导入,最终由FE决定导入是否成功。
写入流程
2. Stream Load
说明
Stream Load是一个同步的导入方式,允许用户通过Http访问的方式将CSV格式或JSON格式的数据批量地导入Doris,并返回数据导入的结果。
使用场景
主要适用于导入本地文件,或通过程序导入数据流中的数据。
原理
用户将Stream Load的Http请求提交给FE(在此仅仅提供转发服务),FE会通过 Http 重定向将数据导入请求转发给某一个BE节点,该BE节点将作为本次Stream Load任务的Coordinator。Coordinator负责整个导入作业(负责向Master FE发送事务请求、从FE获取导入执行计划、接收实时数据、分发数据到其他Executor BE节点以及数据导入结束后返回结果给用户)。
写入流程
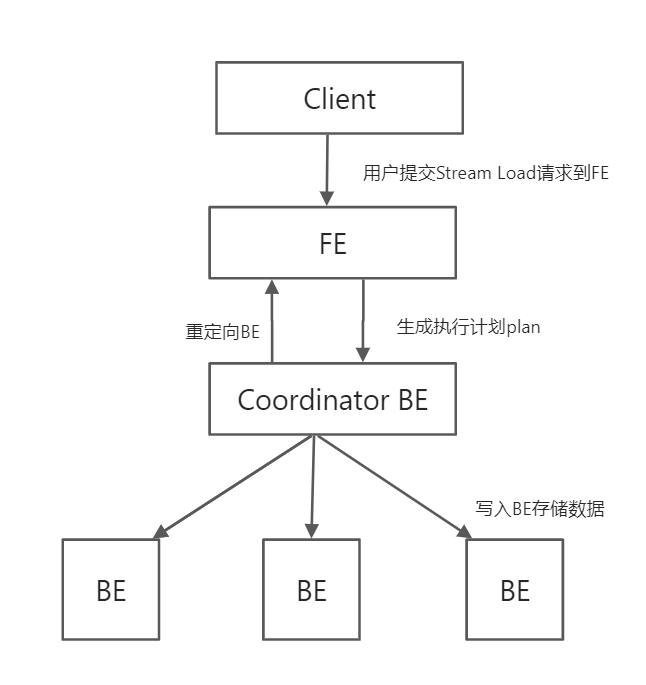
(1)FE 接收用户的写入请求,并随机选出 BE 作为 Coordinator BE。将用户的请求重定向到这个 BE 上。
(2)Coordinator BE 负责接收用户的数据写入请求,同时请求 FE 生成执行计划并对调度、管理导入任务 LoadJob 和导入事务。
(3)Coordinator BE 调度执行导入计划,执行对数据校验、清理之后。
(4)数据写入到 BE的存储层中。在这个过程中会先写入到内存中,写满一定数据后按照存储层的数据格式写入到物理磁盘上。
3. Routine Load
说明
Routine load 同步的数据导入方式,此功能为用户提供了一种自动从指定数据源进行数据导入的功能。
使用场景
(1)支持用户提交一个常驻的导入任务,通过不断的从指定的数据源读取数据,将数据导入到 Doris 中。目前仅支持通过无认证或者 SSL 认证方式,从 Kakfa 导入的数据。
(2)支持导入的数据类型: 文本 和 JSON两种格式.
原理
FE 通过 JobScheduler 将一个导入作业拆分成若干个 Task(经验值一般是和Kafka的Partition数量一致)。每个 Task 负责导入指定的一部分数据。Task 被 TaskScheduler 分配到指定的 BE 上执行。在 BE 上,一个 Task 被视为一个普通的导入任务,通过 Stream Load 的导入方式进行导入。导入结果,向 FE 反馈。FE 中的 JobScheduler 根据反馈结果,继续生成后续新的 Task。
写入流程
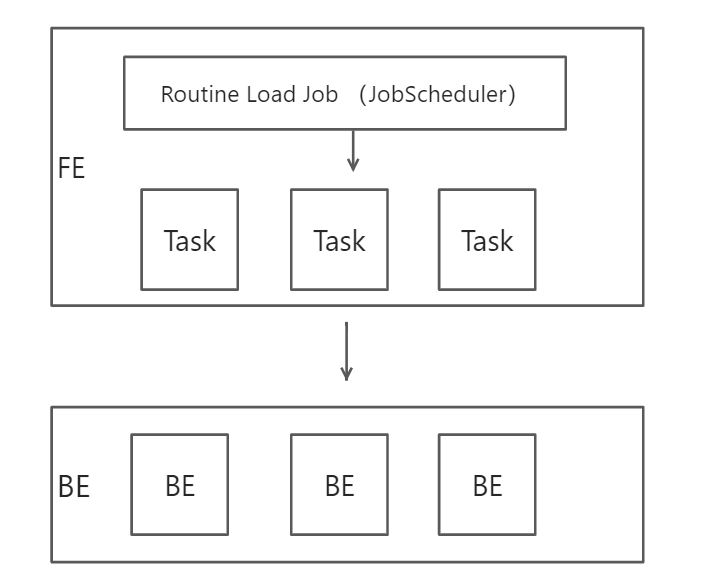
(1)客户端向 FE 提交一个Kafka导入任务。
(2)FE将一个导入任务拆分成若干个Task,每个Task负责导入指定的一部分数据。
(3)每个Task被分配到指定的 BE 上执行。在 BE 上,一个 Task 被视为一个普通的导入任务,通过 Stream Load 的导入机制进行导入。
BE导入完成后,向 FE 反馈。
(4)FE 根据反馈结果,继续生成后续新的 Task,或者对失败的 Task 进行重试。
(5)整个导入作业通过不断的产生新的Task,来完成数据源源不断的数据导入。
4. Insert Into
语法
INSERT INTO table_name [partition_info] [WITH LABEL label] [col_list] [query_stmt] [VALUES]
参数说明
| 参数 | 说明 |
|---|---|
| partition_info | 导入表的目标分区 |
| col_list | 导入表的目标列 |
| query_stmt | 通过查询语句,将结果导入到 Doris 系统中表中 |
| values | 插入一条或者多条数据 |
| with label | INSERT 操作也可以指定一个 label,如果没有,用UUID |
数据分发流程
DeltaWriter
主要负责不断接收新写入的批量数据,完成单个 Tablet 的数据写入。
采用了类似LSM 树的结构,将数据先写到 Memtable 中,当 Memtable 数据写满后,会异步 flush 生成一个 Segment 进行持久化,同时生成一个新的 Memtable 继续接收新增数据导入,这个 flush 操作由 MemtableFlushExecutor 执行器完成。
Memtable
数据采用跳表结构方便对数据进行排序,排序规则使用了按照 schema 的 key 的顺序依次对字段进行比较。这样保证了写入的每一个写入 Segment 中的数据是有序的。如果当前模型为非 DUP 模型(AGG 模型和 UNIQUE 模型)时,还会对相同 key 的数据进行聚合。
RowsetWriter
RowsetWriter 中又分为 SegmentWriter、ColumnWriter、PageBuilder、IndexBuilder等等模块。这些都是在物理存储层面的写入。
RowsetWriter
从整体上完成一次导入 LoadJob 任务的写入,一次导入 LoadJob 任务会生成一个 Rowset,一个 Rowset 表示一次导入成功生效的数据版本。实现上由 RowsetWriter 负责完成 Rowset 的写入。
SegmentWriter
负责实现 Segment 的写入。一个 Rowset 可以由多个 Segment 文件组成。
ColumnWriter
ColumnWriter 包含在 SegmentWriter 中,Segment 的文件是完全的列存储结构,Segment 中包含了各个列和相关的索引数据,每个列的写入由 ColumnWriter 负责写入。
其他
在文件存储格式中,数据和索引都是按 Page 进行组织,ColumnWriter 中又包含了生成数据 Page 的 PageBuilder 和生成索引 Page 的 IndexBuilder 来完成 Page 的写入。
RowsetWriter流程
(1)当一个 Memtable 写满时(默认为 100M),将 Memtable 的数据会 flush 到磁盘上,这时 Memtable 内的数据是按 key 有序的。然后逐行写入到 RowsetWriter 中。
(2)RowsetWriter 将数据同样逐行写入到 SegmentWriter 中,RowsetWriter 会维护当前正在写入的 SegmentWriter 以及要写入的文件块列表。每完成写入一个 Segment 会增加一个文件块对应。
(3)SegmentWriter 将数据按行写入到各个 ColumnWriter 的中,同时写入 ShortKeyIndexBuilder。ShortKeyIndexBuilder 主要负责生成 ShortKeyIndex 的索引 Page 页。
(4)ColumnWriter 将数据分别写入 PageBuilder 和各个 IndexBuilder,PageBuilder 用来生成 ColumnData 数据的 PageBuilder,各个 IndexBuilder 。
(5)添加完数据后,RowsetWriter 执行 flush 操作。
(6)SegmentWriter 的 flush 操作,将数据和索引写入到磁盘。其中对磁盘的读写由 FileWritableBlock 完成。
(7)ColumnWriter 将各自数据、索引生成的 Page 顺序写入到文件中。
(8)SegmentWriter 生成 SegmentFooter 信息,SegmentFooter 记录了 Segment 文件的原数据信息。完成写入操作后,RowsetWriter 会再开启新的 SegmentWriter,将下一个 Memtable 写入新的 Segment,直到导入完成。
读流程
Init流程
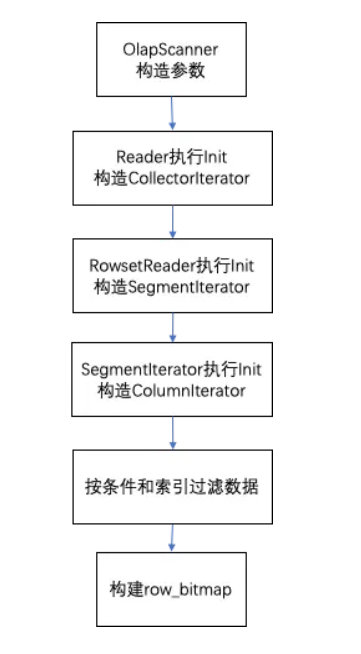
1. OlapScanner
OlapScanner对一个tablet数据读取操作整体的封装,主要内容如下:
(1)根据查询指定的version版本查找出需要读取的RowsetReader。
(2)设置查询信息,包括_tablet、读取类型reader_type=READER_QUERY、是否进行聚合、_version。
(3)设置查询条件信息,包括filter过滤字段、is_nulls字段。
(4)置返回列信息。
(5)设置查询的key_ranges范围。
(6)初始化Reader对象。
2. Reader的Init
(1)Reader对读取的参数进行处理,对不同模型读取方式不同的调整。
(2)初始化conditions查询条件对象。
(3)初始化bloomFilter列集合(eq、in条件,添加了bloomFilter的列)。
(4)初始化delete_handler。包括了tablet中存在的所有删除信息,其中包括了版本和对应的删除条件数组。
(5)初始化传递给下层要读取返回的列,包括了返回值和条件对象中的列。
(6)初始化key_ranges的start key、end key对应的RowCusor行游标对象等。
(7)构建的信息设置RowsetReader、CollectIterator。Rowset对象进行初始化,将RowsetReader加入到CollectIterator中。
(8)调用CollectIterator获取当前行,这里开启读取流程,第一次读取。
3. RowsetReader的Init
RowsetReader则负责了对一个Rowset的读取。
(1)构建SegmentIterator并过滤掉delete_handler中比当前Rowset版本小的删除条件。
(2)构建RowwiseIterator(对SegmentIterator的聚合iterator),将要读取的SegmentIterator加入到RowwiseIterator。当所有Segment为整体有序时采用union iterator顺序读取的方式,否则采用merge iterator归并读取的方式。
4. Segmentlterator的Init
SegmentIterator对应了一个Segment的数据读取,Segment的读取会根据查询条件与索引进行计算找到读取的对应行号信息,seek到对应的page,对数据进行读取。
(1)初始化ReadableBlock,用来读取当前的Segment文件的对象,实际读取文件;
(2)初始化_row_bitmap,用来存储通过索引过滤后的行号,使用bitmap结构;
(3)构建ColumnIterator,这里仅是需要读取列;
(4)如果Column有BitmapIndex索引,初始化每个Column的BitmapIndexIterator;
(5)通过SortkeyIndex索引过滤数据。当查询存在key_ranges时,通过key_range获取命中数据的行号范围。
(6)通过各种索引按条件过滤数据。条件包括查询条件和删除条件过滤信息。
(7)使用row_bitmap构造BitmapRangerInterator迭代器,用于后续读取数据。
next_block获取数据块的流程
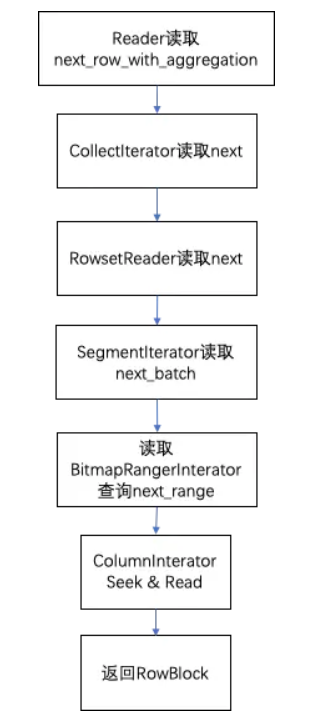
1. Reader读取next_row_with_aggregation
在reader读取时预先读取一行,记录为当前行。在被调用next返回结果时会返回当前行,然后再预先读取下一行作为新的当前行。
(1)_dup_key_next_row读取(明细数据模型),返回当前行,再直接读取CollectorIterator读取next作为当前行。
(2)_agg_key_next_row读取(聚合模型),取CollectorIterator读取next之后,判断下一行是否与当前行的key相同,相同时则进行聚合计算,循环读取下一行;不相同则返回当前累计的聚合结果,更新当前行。
(3)_unique_key_next_row读取(unique key模型),与_agg_key_next_row模型方式逻辑相同,但存在一些差异。由于支持了删除操作,会查看聚合后的当前行是否标记为删除行。如果为删除行舍弃数据,直到找到一个不为删除行的数据才进行返回。
2. CollectIterator读取next
使用heap数据结构维护了要读取RowsetReader集合。
(1)CollectIterator从heap中pop出上一个最大的RowsetReader。
(2)pop出的RowsetReader再读取下一个新的row作为RowsetReader的当前行并再放入heap中进行比较。读取过程中调用RowsetReader的nextBlock按RowBlock读取。如果当前取到的块是部分删除的page,还要对当前行按删除条件对行进行过滤。
(3)取队列的top的RowsetReader的当前行,作为当前行返回。
3. RowsetReader读取next
(1)RowsetReader直接读取了RowwiseIterator的next_batch。
(2)RowwiseIterator整合了SegmentIterator。当Rowset中的Segment整体有序时直接按Union方式迭代返回。当无序时按Merge归并方式返回。RowwiseIterator同样返回了当前最大的SegmentIterator的行数据,每次会调用SegmentIterator的next_batch获取数据。
4. SegmentIterator读取next_batch
(1)根据init阶段构造的BitmapRangerInterator,使用next_range每次取出要读取的行号的一个范围range_from、range_to。
(2)先读取条件列从range_from到range_to行的数据。
Compaction
Doris通过Compaction将增量聚合Rowset文件提升性能,Rowset的版本信息中设计了有两个字段first、second来表示Rowset合并后的版本范围。
Compaction任务分为两种,base compaction和cumulative compaction。
当未合并的cumulative rowset的版本first和second相等。Compaction时相邻的Rowset会进行合并,生成一个新的Rowset,版本信息的first,second也会进行合并,变成一个更大范围的版本。另一方面,compaction流程大大减少rowset文件数量,提升查询效率。
1 .base compaction条件
合并过的Rowset,first版本与second版本不同。
(1)当存在大于5个的非cumulative的rowset,将所有非cumulative的rowset进行合并。
(2)版本first为0的base rowset与其他非cumulative的磁盘比例小于10:3时,合并所有非cumulative的rowset进行合并。
2. cumulative compaction条件
从未合并过的增量Rowset,其每个Rowset的first与second版本相同。
(1)选出Rowset集合的segment数量需要大于等于5并且小于等于1000(可配置),进行合并。
(2)当输出Rowset数量小于5时,但存在删除条件版本大于Rowset second版本时,进行合并(让删除的Rowset快速合并进来)。
(3)当累计的base compaction和cumulative compaction都时间大于1天时,合并。
参考
存储层设计介绍 2——写入流程、删除流程分析
https://xie.infoq.cn/article/4cc8416c0054bf6f2cdb8b16c
存储层设计介绍3——读取流程、Compaction流程分析
https://blog.csdn.net/ucanuup_/article/details/114976379
DorisDB企业版文档
https://www.kancloud.cn/dorisdb/dorisdb

若有收获,就点个赞吧
0 人点赞
