FlinkSQL窗口函数篇:易理解与实战案例
原创 左右 大数据左右手 2021-11-08 08:04:54
收录于话题
#Flink
点击上方关注【大数据左右手】
加技术吐槽群,获取更多资料
前言
本篇以通俗的语言来介绍FlinkSQL版的窗口函数。目的是从最容易理解与近实战案例方式去让读者获得收益。
1. Watermark
2. 窗口的划分和触发时机
3. 滚动窗口用法与场景实例
4. 滑动窗口用法与场景实例
5. 会话窗口用法与场景实例
6. 遇到一个问题()
本篇是FlinkSQL实战的开篇,欢迎收藏,转发与持续关注。
Watermark
为什么要引入
由于实时计算的输入数据是持续不断的,因此我们需要一个有效的进度指标,来帮助我们确定关闭时间窗口的正确时间点,保证关闭窗口后不会再有数据进入该窗口,可以安全输出这个窗口的聚合结果。
而Watermark就是一种衡量Event Time进展的有效机制。随着时间的推移,最早流入实时计算的数据会被处理完成,之后流入的数据处于正在处理状态。处于正在处理部分的和已处理部分的交界的时间戳,可以被定义为Watermark,代表在此之前的事件已经被处理完成并输出。
针对乱序的流,Watermark也至关重要,即使部分事件延迟到达,也不会影响窗口计算的正确性。此外,并行数据流中,当算子(Operator)有多个输入流时,算子的Event Time以最小流Event Time为准。
watermark策略
Flink SQL提供了几种常用的watermark策略。
1. 严格意义上递增的时间戳,发出到目前为止已观察到的最大时间戳的水印。时间戳小于最大时间戳的行不会迟到。
watermark for rowtime_column as rowtime_column
2. 递增的时间戳,发出到目前为止已观察到的最大时间戳为负1的水印。时间戳等于或小于最大时间戳的行不会迟到。
watermark for rowtime_column as rowtime_column - INTERVAL ‘1’ SECOND.
3. 有界时间戳(乱序)发出水印,它是观察到的最大时间戳减去指定的延迟。
watermark for rowtime_column as rowtime_column - INTERVAL’5’SECOND
是5秒的延迟水印策略。
watermark for rowtime_column as rowtime_column - INTERVAL ‘string’ timeUnit
语法格式样例
CREATE TABLE Orders (
user BIGINT,
product STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL ‘5’ SECOND
) WITH ( . . . );
窗口的划分和触发时机
窗口划分
源码
/*
Method to get the window start for a timestamp.
@param timestamp epoch millisecond to get the window start.
@param offset The offset which window start would be shifted by.
@param windowSize The size of the generated windows.
@return window start
/
public static long getWindowStartWithOffset(long timestamp, long offset, long windowSize) {
return timestamp - (timestamp - offset + windowSize) % windowSize;
}
计算逻辑
window_start =
timestamp - (timestamp - offset + windowSize) % windowSize
window_end = window_start + windowSize
以左闭右开计算
[window_start,window_end)
介绍
timestamp:进来的时间(event_time)
offset: 窗口启动的偏移量
windowSize:设定的窗口大小
例:第一次进来的时间为
2021-11-06 20:13:00
按3分钟为窗口大小,offset为0,所以:
window_start = 13-(13-0+3)%3 =12
所以这条数据落到
[2021-11-06 20:12:00 2021-11-06 20:15:00)
这个窗口内。
窗口触发计算时机
滚动窗口用法与场景
滚动窗口
定义
滚动窗口(TUMBLE)将每个元素分配到一个指定大小的窗口中。通常,滚动窗口有一个固定的大小,并且不会出现重叠。例如,如果指定了一个5分钟大小的滚动窗口,无限流的数据会根据时间划分为[0:00, 0:05)、[0:05, 0:10)、[0:10, 0:15)等窗口。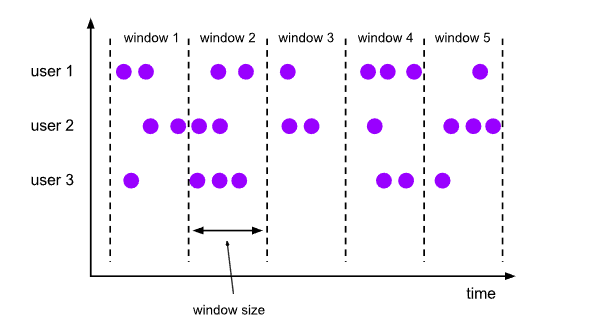
语法
TUMBLE函数用在GROUP BY子句中,用来定义滚动窗口。
TUMBLE(< time-attr>, < size-interval>) < size-interval>: INTERVAL ‘string’ timeUnit
或
TUMBLE(TABLE data, DESCRIPTOR(timecol), size)
data: 是一个表参数。timecol: 是一个列描述符指示应该映射到哪个时间的属性列。size: 是一个持续时间指定窗口的宽度。
用法与场景
用法
创建表
val sql=<br /> """<br /> |CREATE TABLE Bid(<br /> |bidtime STRING,<br /> |price DECIMAL(10, 2),<br /> |item STRING,<br /> |t as TO_TIMESTAMP(bidtime),<br /> |WATERMARK FOR t AS t - INTERVAL '1' MINUTES<br /> |)<br /> |WITH (<br /> | 'connector' = 'kafka',<br /> | 'topic' = 'flink_sql_1',<br /> | 'properties.group.id'='flink_sql_group_1',<br /> | 'properties.bootstrap.servers' = 'xxxx',<br /> | 'format' = 'json'<br /> |)<br /> |""".stripMargin<br /> tableEnv.executeSql(sql)
查询
val query=<br /> """<br /> |SELECT window_start, window_end, SUM(price) price FROM TABLE(<br /> | TUMBLE(<br /> | DATA => TABLE Bid,<br /> | TIMECOL => DESCRIPTOR(t),<br /> | SIZE => INTERVAL '3' MINUTES))<br /> | GROUP BY window_start, window_end<br /> |""".stripMargin<br /> tableEnv.executeSql(query).print()<br /> }
测试数据
{“bidtime”:”2021-11-04 19:05:00.0”,”price”:4,”item”:”A” }
{“bidtime”:”2021-11-04 19:07:00.0”,”price”:4,”item”:”C” }
{“bidtime”:”2021-11-04 19:09:00.0”,”price”:4,”item”:”B” }
{“bidtime”:”2021-11-04 19:11:00.0”,”price”:4,”item”:”D” }
{“bidtime”:”2021-11-04 19:13:00.0”,”price”:4,”item”:”F” }
{“bidtime”:”2021-11-04 19:15:00.0”,”price”:4,”item”:”E” }
{“bidtime”:”2021-11-04 19:17:00.0”,”price”:4,”item”:”E” }
{“bidtime”:”2021-11-04 19:19:00.0”,”price”:4,”item”:”E” }
{“bidtime”:”2021-11-04 19:21:00.0”,”price”:4,”item”:”E” }
结果
+——+————————————-+————————————-+———+
| op | window_start | window_end | price|
+——+————————————-+————————————-+———+
| +I | 2021-11-04 19:03:00.000 | 2021-11-04 19:06:00.000 | 4.00|
| +I | 2021-11-04 19:06:00.000 | 2021-11-04 19:09:00.000 | 4.00|
| +I | 2021-11-04 19:09:00.000 | 2021-11-04 19:12:00.000 | 8.00|
| +I | 2021-11-04 19:12:00.000 | 2021-11-04 19:15:00.000 | 4.00|
| +I | 2021-11-04 19:15:00.000 | 2021-11-04 19:18:00.000 | 8.00|
……
以方便看的时间格式展示(hh:mm)
| 事件时间 | 水位线 | 窗口 | 触发计算的窗口 |
|---|---|---|---|
| 19:05 | 19:04 | [19:03,19:06) | |
| 19:07 | 19:06 | [19:06,19:09) | [19:03,19:06) |
| 19:09 | 19:08 | [19:09,19:12) | |
| 19:11 | 19:10 | [19:09,19:12) | [19:06,19:09) |
| 19:13 | 19:12 | [19:12,19:15) | [19:09,19:12) |
| 19:15 | 19:14 | [19:15,19:18) | |
| 19:17 | 19:16 | [19:15,19:18) | [19:12,19:15) |
| 19:19 | 19:18 | [19:18,19:21) | [19:15,19:18) |
| 19:21 | 19:20 | [19:18,19:21) |
场景或实战
使用场景
分钟级别聚合常用场景。比如:统计每个用户每分钟在指定网站的单击数
实战
创建结构
val kafka_sql=
“””
|CREATE TABLE user_clicks (
| user_name VARCHAR ,
| click_url VARCHAR ,
| update_time BIGINT,
| t as TO_TIMESTAMP(FROM_UNIXTIME(update_time/1000,’yyyy-MM-dd HH:mm:ss’)),
| WATERMARK FOR t AS t - INTERVAL ‘2’ SECOND
|) WITH (
| ‘connector’ = ‘kafka’,
| ‘’topic’ = ‘flink_sql_1’,
| ‘properties.group.id’=’flink_sql_group_1’,
| ‘properties.bootstrap.servers’ = ‘xxxx’,
| ‘format’ = ‘json’
|)
|”””.stripMargin
tableEnv.executeSql(kafka_sql)
查询逻辑
val query=
“””
| SELECT
| user_name,
| count(click_url) as pv,
| TUMBLE_START(t, INTERVAL ‘1’ MINUTE) as t_start,
| TUMBLE_END(t, INTERVAL ‘1’ MINUTE) as t_end
| FROM user_clicks
| GROUP BY TUMBLE(t, INTERVAL ‘1’ MINUTE), user_name
|”””.stripMargin
tableEnv.executeSql(query).print()
数据与结果
{“user_name”:”wang”,”click_url”:”http://weixin.qq.com","ts":"2021-11-06 10:00:00.0”}
{“user_name”:”wang”,”click_url”:”http://weixin.qq.com","ts":"2021-11-06 10:00:10.0”}
{“user_name”:”wang”,”click_url”:”http://weixin.qq.com","ts":"2021-11-06 10:00:49.0”{“user_name”:”wang”,”click_url”:”http://weixin.qq.com","ts":"2021-11-06 10:01:05.0”}
{“user_name”:”wang”,”click_url”:”http://weixin.qq.com","ts":"2021-11-06 10:01:58.0”}
{“user_name”:”bo”,”click_url”:”http://weixin.qq.com","ts":"2021-11-06 10:02:11.0”}
+——+————————————————+———————————+————————————-+————————————-+
| op | user_name | pv | window_start | window_end |
+——+————————————————+———————————+————————————-+————————————-+
| +I | wang | 3 | 2021-11-06 10:00:00.000 | 2021-11-06 10:01:00.000 |
| +I | wang | 2 | 2021-11-06 10:01:00.000 | 2021-11-06 10:02:00.000 |
滑动窗口用法与场景
滚动窗口
定义
滑动窗口(HOP),也被称作Sliding Window。不同于滚动窗口,滑动窗口的窗口可以重叠。
通常,大部分元素符合多个窗口情景,窗口是重叠的。因此,滑动窗口在计算移动平均数(moving averages)时很实用。例如,计算过去5分钟数据的平均值,每10秒钟更新一次,可以设置slide为10秒,size为5分钟。下图为您展示间隔为30秒,窗口大小为1分钟的滑动窗口。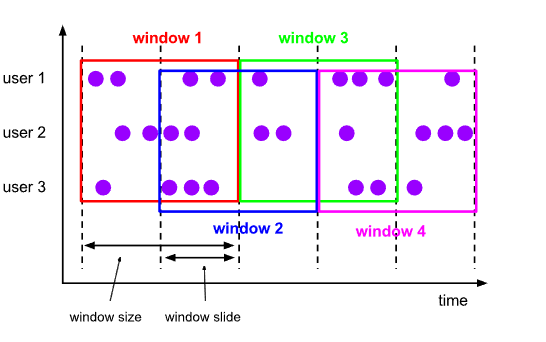
语法
HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])
data: 是一个表参数,数据表。
timecol: 是一个列描述符指示应该映射到哪个时间的属性列。
slide: 滑动时间。
size: 是一个持续时间指定窗口的宽度。
o slide < size,则窗口会重叠,每个元素会被分配到多个窗口。
o slide = size,则等同于滚动窗口(TUMBLE)。
o slide > size,则为跳跃窗口,窗口之间不重叠且有间隙。
具体用法可以参考滚动窗口,以下介绍下实战
场景或实战
使用场景
计算过去5分钟数据的平均值,每10秒钟更新一次,可以设置slide为10秒,size为5分钟。类似这种的都可以去使用滑动窗口。
实战
统计每个用户过去1分钟的单击次数,每30秒更新1次,即1分钟的窗口,30秒滑动1次。
创建结构
val sql=
“””
|CREATE TABLE user_clicks (
| user_name VARCHAR ,
| click_url VARCHAR ,
| ts TIMESTAMP(3),
| WATERMARK FOR ts AS ts - INTERVAL ‘2’ SECOND
|)
|WITH (
| ‘connector’ = ‘kafka’,
| ‘topic’ = ‘flink_sql_1’,
| ‘properties.group.id’=’flink_sql_group_1’,
| ‘properties.bootstrap.servers’ = ‘devcdh1:9092,devcdh2:9092,devcdh3:9092’,
| ‘format’ = ‘json’
|)
|”””.stripMargin
tableEnv.executeSql(sql)
查询逻辑
val query=
“””
|SELECT
| user_name,
| count(click_url) as pv,
| HOP_START (ts, INTERVAL ‘30’ SECOND,INTERVAL ‘1’ MINUTE) as window_start,
| HOP_END (ts,INTERVAL ‘30’ SECOND, INTERVAL ‘1’ MINUTE) as window_end
| FROM user_clicks
| GROUP BY HOP(ts,INTERVAL ‘30’ SECOND, INTERVAL ‘1’ MINUTE), user_name
|”””.stripMargin
tableEnv.executeSql(query).print()
数据与结果
{“user_name”:”wang”,”click_url”:”http://weixin.qq.com","ts":"2021-11-06 10:00:00.0”}
{“user_name”:”wang”,”click_url”:”http://weixin.qq.com","ts":"2021-11-06 10:00:10.0”}
{“user_name”:”wang”,”click_url”:”http://weixin.qq.com","ts":"2021-11-06 10:00:49.0”{“user_name”:”wang”,”click_url”:”http://weixin.qq.com","ts":"2021-11-06 10:01:05.0”}
{“user_name”:”wang”,”click_url”:”http://weixin.qq.com","ts":"2021-11-06 10:01:58.0”}
{“user_name”:”bo”,”click_url”:”http://weixin.qq.com","ts":"2021-11-06 10:02:11.0”}
+——+————————————————+———————————+————————————-+————————————-+
| op | user_name | pv | window_start | window_end |
+——+————————————————+———————————+————————————-+————————————-+
| +I | wang | 2 | 2021-11-06 09:59:30.000 | 2021-11-06 10:00:30.000 |
| +I | wang | 3 | 2021-11-06 10:00:00.000 | 2021-11-06 10:01:00.000 |
| +I | wang | 2 | 2021-11-06 10:00:30.000 | 2021-11-06 10:01:30.000 |
| +I | wang | 2 | 2021-11-06 10:01:00.000 | 2021-11-06 10:02:00.000 |
会话窗口用法与场景
会话窗口
定义
通过SESSION活动来对元素进行分组。会话窗口与滚动窗口和滑动窗口相比,没有窗口重叠,没有固定窗口大小。相反,当它在一个固定的时间周期内不再收到元素,即会话断开时,该窗口就会关闭。
会话窗口通过一个间隔时间(Gap)来配置,这个间隔定义了非活跃周期的长度。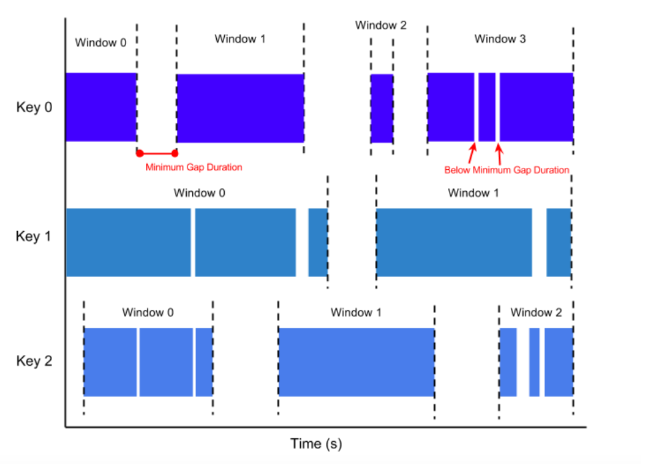
语法
SESSION(
场景或实战
使用场景
例如,一个表示鼠标单击活动的数据流可能具有长时间的空闲时间,并在两段空闲之间散布着高浓度的单击。如果数据在指定的间隔(Gap)之后到达,则会开始一个新的窗口。
实战
统计每个用户在每个活跃会话期间的单击次数,会话超时时长为30秒。
查询逻辑
创建表和上面一样,不再罗列
SELECT
user_name,
count(click_url) as pv,
SESSION_START (ts, INTERVAL ‘30’ SECOND) as window_start,
SESSION_END (ts,INTERVAL ‘30’ SECOND) as window_end
FROM user_clicks
GROUP BY SESSION(ts,INTERVAL ‘30’ SECOND), user_name
结果
+——+————————————————+———————————+————————————-+————————————-+
| op | user_name | pv | window_start | window_end |
+——+————————————————+———————————+————————————-+————————————-+
| +I | wang | 2 | 2021-11-06 10:00:00.000 | 2021-11-06 10:00:40.000 |
| +I | wang | 2 | 2021-11-06 10:00:49.000 | 2021-11-06 10:01:35.000 |
温馨提醒
FlinkSQL window函数与connector kafka结合计算,在本地测试或者在服务器上运行的时候设置了并行度为1,如果遇到在自己理解上,并没有数据print()或者少数据的时候,你考虑下kafka分区的关系。
因为目前FlinkSQL是不支持source/sink并行度配置的,FlinkSQL中各算子并行度默认是根据source的partition数或文件数来决定的,比如常用的kafka source topic的partition是3,那么FlinkSQL任务的并发就是3。
又因为每个task维护单独的watermark。虽然你在全局设置了并行度为1,认为全部数据进入一个task,在某个时刻应该触发了计算,然而实际情况并没有触发计算的,那在这个时候你就要考虑kafka分区带来的影响。
tEnv.getConfig()
.addConfiguration(
new Configuration()
.set(CoreOptions.DEFAULT_PARALLELISM, 1)
);
其他函数
Window Aggregation
Group Aggregation
Over Aggregation
可参考往期
FlinkSQL窗口,让你眼前一亮,是否可以大吃一惊呢
「注:」 本篇案例参考以下
实时计算Flink版:
https://help.aliyun.com/document_detail/62510.html
Flink官网:
https://ci.apache.org/projects/flink/flink-docs-release-1.13/zh/docs/dev/table/sql/queries/window-tvf/
关注回复关键字“加群”你可以提各种技术、产品、管理、认知等问题。
群中特色:每天早上安排一个话题讨论,对学习和后期找工作有大帮助,讨论结果整理在线文档随后发出。在群力群策中形成知识库。
和我联系吧,交流大数据知识,一起成长~~~
动动小手,让更多需要的人看到~

若有收获,就点个赞吧
0 人点赞
