文件系统的实现
文件系统的结构
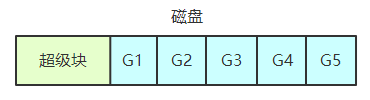
文件系统在磁盘上将磁盘分成块(block),这些块大多数用于存储用户数据,将用于存放用户数据的磁盘区域称为数据区域(data region)。文件系统必须记录每个文件的信息,这类信息在文件系统中使用 inode 结构来存储。
除了存储文件的信息,还需要一些分配结构来记录 inode 或数据块是空闲还是已分配,例如空闲列表或数据位图。文件系统中还有一些超级块(superblock),包含关于该特定文件系统的信息,例如文件系统中有多少个 inode 和数据块、inode 表的位置和文件系统类型等。
inode
inode 是 index node(索引结点)的缩写,是许多文件系统中使用的通用名称,用于描述保存给定文件的元数据的结构。在每个 inode 中保存了所有关于文件的信息,这些信息称之为元数据(matadata)。主要有:文件类型、文件大小、分配给它的块数、文件权限、时间信息,以及有关其数据块驻留在磁盘上的位置的信息(如某种类型的指针)。
设计 inode 时最重要的问题是:如何引用数据块的位置,一种简单的方法是在 inode 中有一个或多个直接指针,指向属于该文件的一个磁盘块,但是如果文件太大则直接指针的指向范围会很有限。为了支持更大的文件,文件系统可以使用间接指针(indirect pointer),它不是指向包含用户数据的块,而是指向包含更多指针的块,每个指针指向用户数据。
目录组织
通常文件系统将目录视为特殊类型的文件,因此目录有一个 inode。目录具有由 inode 指向的数据块,也一样存在于文件系统的数据块区域中。我们的磁盘结构因此保持不变。一个目录基本上只包含一个二元组(条目名称,inode 号)的列表,通常还有会记录长度字段。
删除一个文件是,会在目录中间留下一段空白空间,因此应该有一些方法来标记它,使用记录长度字段更便于删除操作的执行。
空闲空间管理
空闲空间管理(free space management)是很重要的功能,一位文件系统必须记录哪些 inode 和数据块是空闲的,这样在分配新文件或目录时,就可以为它找到空间。管理空闲空间可以有很多方法,例如位图、空闲列表和 B 树(B-tree)等。
当创建一个文件时,必须为该文件分配一个 inode,文件系统将通过搜索一个空闲的内容,并将其分配给该文件。然后将这个 inode 标记为已使用,并最终用正确的信息更新磁盘上的数据结构。
一些 Linux 文件系统(如 ext2 和 ext3)在创建新文件并需要数据块时,会采用预分配(pre-allocation)策略。首先先寻找一系列空闲块,然后将它们分配给新创建的文件,文件系统保证文件的一部分将在磁盘上并且是连续的,从而提高性能。
文件读写
读取文件
读取文件时提供给文件系统的是完整的路径名,因此文件系统必须遍历(traverse)路径名来查找所需的 inode。所有遍历都从文件系统的根开始,即根目录(root directory)。具体的过程如下:
- 从根目录的 inode 开始遍历,从而获取一些基本信息;
- 在 inode 查找指向数据块的指针,用这些磁盘上的指针来读取目录;
- 递归遍历路径名,直到找到所需文件的 inode;
- 进行权限检查,在每个进程的打开文件表中,为此进程分配一个文件描述符返回给用户。
写入文件
写入文件是一个类似的过程,首先先打开文件,接着应用程序更新文件,最后关闭该文件。当写入一个新文件时,每次写入操作不仅需要将数据写入磁盘,还必须首先决定将哪个块分配给文件,从而相应地更新磁盘的其他结构。因此每次写入文件在逻辑上会导致 5 个 I/O:
- 读取数据位图,标记新分配的块被使用;
- 写入位图,将它的新状态存入磁盘;
- 读取 inode;
- 写入 inode,用新块的位置更新;
-
创建文件
文件创建是,写入的工作量更大,因为文件系统不仅要分配一个 inode,还要在包含新文件的目录中分配空间。
读取 inode 位图,查找空闲 inode;
- 写入 inode 位图,将其标记为已分配;
- 写入新的 inode,进行初始化;
- 写入目录的数据,将文件的高级名称链接到它的 inode 号;
- 读写目录 inode,进行更新;
-
缓存和缓冲
读取和写入文件的开销很大,会导致磁盘的增加许多 I/O 请求,大多数文件系统积极使用系统内存(DRAM)来缓存重要的块。引入缓存后,第一次打开可能会产生很多 I/O 请求,来读取目录的 inode 和数据,但是随后打开同一文件时大部分会命中缓存,因此不需要 I/O。
尽管可以通过足够大的缓存完全避免读取 I/O,但写入的内容必须进入磁盘才能存储。写缓冲(write buffering)技术是通过延迟写入,文件系统可以将一些更新编成一批(batch),放入一组较小的 I/O 中,以减少 I/O 的次数。同时如果应用程序创建文件并将其删除,则将文件创建延迟写入磁盘,可以完全避免写入。不过如果系统在更新传递到磁盘之前崩溃,更新就会丢失。快速文件系统
伯克利的一个小组设计了快速文件系统(Fast File System,FFS),思路是让文件系统的结构和分配策略考虑磁盘的特性,从而提高性能。
性能问题
直接实现的文件系统将磁盘当成随机存取内存,数据遍布各处,而不考虑保存数据的介质特点。例如文件的数据块通常离其 inode 非常远,因此每当第一次读取 inode 然后读取文件的数据块时,就会导致昂贵的寻道。
第二个问题是文件系统最终会变得非常碎片化(fragmented),缺乏空闲空间管理的空闲列表最终会指向遍布磁盘的一堆块。结果导致在磁盘上来回访问逻辑上连续的文件,从而降低了性能。例如以下是 3 个文件在系统中的分配情况:
此时如果删除了文件 B,并存放占用 4 个块的文件 D,这个连续的文件将被拆成 2 部分放入不相邻的空闲区域中。
柱面组
FFS 将磁盘划分为一些柱面组(cylinder group),对于在同一组中的两个文件,FFS 可以使先后访问它们不会导致穿越磁盘的长时间寻道。出于可靠性原因,每个组中都有超级块(super block),在每个组中也同样需要分配结构、数据区域和 inode。
FFS 将相关的东西放一起来提高性能,也就是将相关的东西置于同一个区块组内。对于是目录的放置,FFS 优先选择分配数量少的柱面组和大量的自由 inode 来放置。它将文件的数据块尽量分配到与其 inode 相同的组中,从而防止 inode 和数据之间的长时间寻道(如在老文件系统中)。其次它将位于同一目录中的所有文件,放在它们所在目录的柱面组中。大文件存储
对于大文件的放置需要特别的规则,如果特别对待,大文件将填满它首先放入的块组。以这种方式妨碍了随后的“相关”文件放置在该块组内,可能破坏文件访问的局部性。

对于大文件,FFS 将其分为多个部分,分别放入多个柱面组中。如果大块大小足够大,大部分时间仍然花在从磁盘传输数据上,而在大块之间寻道的时间相对较少。每次开销做更多工作,从而减少开销,这个过程称为摊销(amortization)。
子块
为了尽可能减少内部碎片(internal fragmentation),FFS 引入子块(sub-block)来解决。假设每个块大小为 4KB,而每个子块有 512 字节。一开始若文件大小为 1KB,则它将占据 2 个子块。如果文件发生了增长,文件系统将继续为其分配 512 字节的子块,直到它达到完整的 4KB 数据。此时 FFS 将找到一个 4KB 块,将子块的内容复制到其中,然后释放子块。
这个过程效率低下,因为文件系统需要大量的额外工作。因此 FFS 修改 libc 库来实现缓冲写入,以 4KB 块的形式将它们发送到文件系统。优化磁盘布局
对于未优化的磁盘布局,磁盘在顺序读取期间可能会有较长的旋转时延。例如 FFS 读取块 0,当读取完成时如果要继续读取块 1,往往此时块 1 已在磁头下方旋转,不得不等磁盘转完一圈。
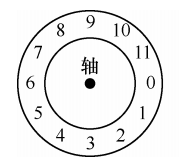
FFS 使用参数化技术优化磁盘布局,该技术会找出磁盘的特定性能参数,确定特定磁盘在布局时应跳过多少块,以避免额外的旋转。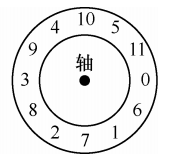
不过现代磁盘更加智能了,它们在内部读取整个磁道并将其缓冲在内部磁盘缓存中,在对轨道的后续读取中,磁盘就从其高速缓存中返回所需数据。其他改进
FFS 是允许长文件名的第一个文件系统之一,而不是传统的固定大小;
- 引入了符号链接的新概念,允许用户为系统上的任何其他文件或目录创建“别名”,更加灵活;
-
文件系统检查程序
崩溃一致性
文件系统面临的一个主要挑战在于,如何在出现断电(power loss)或系统崩溃(systemcrash)的情况下,更新持久数据结构。由于磁盘一次只为一个请求提供服务,如果在一次写入完成后系统崩溃或断电,则磁盘上的结构将处于不一致(inconsistent)的状态。
例如写入一个文件,就需要分别写入 inode、位图和数据块,此时可以排列组合得到 6 种崩溃场景: 只将数据块写入磁盘:数据在磁盘上,但是没有指向它的 inode 和表示块已分配的位图;
- 只有更新的 inode 写入了磁盘:由于 DB 未写入,如果我们信任该 inode,将从磁盘读取垃圾数据;
- 只有更新后的位图写入了磁盘:由于没有指向它的 inode,文件系统永远不会使用这个块;
- 写入了 inode 和位图,但没有写入数据:该 inode 将从磁盘读取垃圾数据;
- 写入了 inode 和数据块,但没有写入位图:inode 和位图的旧版本之间存在不一致;
- 写入了位图和数据块,但没有写入 inode:不知道数据块属于哪个文件,因为没有 inode 指向。







在文件系统数据结构中可能存在不一致性,理想的做法是将文件系统从一个一致状态,原子地(atomically)移动到另一个状态,这个一般问题称为崩溃一致性问题(crash-consistency problem)。
文件系统检查程序功能
早期的文件系统采用了 fsck 来处理崩溃一致性,它决定让不一致的事情发生,然后再修复它们。fsck 的检查功能包括:
- 首先检查超级块是否合理,若有故障修复方式是使用超级块的备用副本;
- 扫描 inode 生成分配位图,如果位图和 inode 之间存在不一致,则通过信任 inode 内的信息来解决;
- 检查每个 inode 是否存在损坏或其他问题,如果 inode 不易修复,则 inode 会被 fsck 清除,inode 位图相应地更新;
- 验证每个已分配的 inode 的链接数,fsck 从根目录开始扫描整个目录树,若不匹配则修改为正确的计数;
- 检查重复指针,如果重复的 inode 中由某一个有明显故障,会被清除;
- 检查坏块指针,如果指针显然指向超出其有效范围的某个指针,fsck 就将其删除;
对每个目录的内容执行额外的完整性检查,确保层次和 inode 都是正确的。
fsck 的不足
构建 fsck 需要复杂的文件系统知识,编码难度大;
- 运行速度慢,对于非常大的磁盘卷,扫描整个磁盘可能需要几分钟或几小时;
- 扫描整个磁盘,仅修复某些小部分出现的问题的开销是极其大的。
其他恢复技术
除了日志在后文描述,还有一些恢复技术如下:
| 技术 | 简介 |
|---|---|
| 软更新 | 对文件系统的所有写入排序,以确保磁盘上的结构永远不会处于不一致的状态 |
| 写时复制 | 永远不覆写文件或目录,而是对磁盘上以前未使用的位置进行新的更新 |
| 基于反向指针的一致性 | 每个块添加一个反向指针,访问文件时检查正向指针是否指向引用它的块 |
| 乐观崩溃一致性 | 尽可能多地向磁盘发出写入,并利用事务校验和等技术来检测不一致 |
日志
日志的思想源于数据库系统,基本思路是在更新磁盘时,在覆写结构之前写下一些信息描述状态,这些信息构成的集合就是日志。通过将这些信息写入磁盘,可以保证在更新(覆写)正在更新的结构期间发生崩溃时,能够返回并查看你所做的注记,然后重试。
加检查点
数据日志(data journaling)的工作原理是,在将 inode、位图和数据块写入磁盘位置之前,先将它们写入日志。对于这个请求添加事务标记构成一个事务,一旦这个事务安全地存在于磁盘上,就可以覆写文件系统中的旧结构,这个过程称为加检查点(checkpointing)。
但是如果在写入日志期间崩溃,则日志里面的信息也是错误的,系统恢复后不应该继续工作。为避免该问题,文件系统分两步发出事务写入,首先先所有要修改的信息写入日志,写入完成时再进行提交,保证日志的信息是完整正确的。
恢复
如果崩溃发生在事务被安全地写入日志之前,那只需要简单地跳过待执行的更新。如果在事务已提交到日志之后,但在加检查点完成之前发生崩溃,可以在系统引导时,文件系统恢复过程将扫描日志,并查找已提交到磁盘的事务。然后将这些事务重放(replayed),文件系统再次尝试将事务中的块写入它们最终的磁盘位置,称为重做日志(redo logging)。
日志空间管理
日志的大小有限,如果不断向它添加事务将很快占满日志的空间,这样会引发 2 个问题:
- 日志越大恢复时间越长,恢复过程必须重放日志中的所有事务才能恢复;
- 当日志已满或接近满时,不能向磁盘提交进一步的事务,从而影响文件系统的功能。
为了解决这些问题,日志文件系统将日志视为循环数据结构,也就是循环日志。一旦事务被加检查点,文件系统应释放它在日志中占用的空间,允许重用日志空间。
有序日志
尽管恢复很快,但文件系统的正常操作还是很慢,例如在写入日志和写入主文件系统之间存在代价高昂的寻道,这增加了显著的开销。一种更简单的日志形式为有序日志(ordered journaling),它没有将用户数据写入日志,而是先将用户数据写入文件系统,避免重复写入。
至此可以总结出日志的工作步骤:
- 数据写入:将数据写入最终位置,等待完成;
- 日志元数据写入:将开始块和元数据写入日志,等待写入完成;
- 日志提交:将事务提交,等待写入完成;
- 加检查点元数据:将元数据更新的内容写入文件系统中的最终位置;
-
日志结构文件系统
系统原理
日志结构文件系统(Log-structured File System, LFS)的原理是在写入磁盘时,LFS 首先将所有更新缓冲在内存段中。当段已满时,它会在一次长时间的顺序传输中写入磁盘,并传输到磁盘的未使用部分。LFS 永远不会覆写现有数据,而是始终将段写入空闲位置,由于段很大,因此可以有效地使用磁盘。
日志结构文件系统的设计主要源自以下 4 个方面: 内存大小不断增长,可以在内存中缓存更多数据;
- 随机 I/O 性能与顺序 I/O 性能之间存在巨大的差距,且不断扩大;
- 现有文件系统在许多常见工作负载上表现不佳;
- 文件系统不支持 RAID。
写入缓冲
顺序写入磁盘并不足以保证高效写入,假设先向地址 A 写入一个块,然后等待一会儿再向磁盘写入地址 A+1。但是往往在第一次和第二次写入之间,磁盘已经旋转。为了提高性能,LFS 使用写入缓冲(write buffering)技术。在写入磁盘之前,LFS 会跟踪内存中的更新,收到足够数量的更新时,会立即将它们写入磁盘,从而确保有效使用磁盘。inode 查找
老 UNIX 文件系统将所有 inode 保存在磁盘的固定位置,因此要查找特定的 inode 可以基于数组的索引直接找到。而 FFS 将 inode 表拆分为块并在每个柱面组中放置一组 inode,因此在 FFS 中查找给定 inode 号时必须知道每个 inode 块的大小和每个 inode 的起始地址,也很容易。
在 LFS 中查找 inode 比较艰难,因为 inode 分散在整个磁盘上且永远不会覆盖,因此最新版本的 inode 会不断移动。为了解决这个问题,LFS 使用 inode 映射(inode map, imap)这种数据结构,在 inode 号和 inode 之间引入了一个间接层,在此处 imap 将 inode 号作为输入,并生成最新版本的 inode 的磁盘地址。
每次将 inode 写入磁盘时,imap 都需要对 inode 的新位置进行更新,imap 在磁盘上的位置选择也很重要。LFS 将 inode 映射的块放在它写入所有其他新信息的位置旁边,当修改文件块时,inode 和一段 inode 映射会一起写入磁盘。
文件系统必须在磁盘上有一些固定且已知的位置,才能开始文件查找,LFS 在磁盘上设置了固定的检查点区域(checkpoint region, CR)。检查点区域包含指向最新的 inode 映射片段的指针,因此可以通过首先读取 CR 来找到 inode 映射片段。垃圾收集
LFS 存在会反复将最新版本的文件写入磁盘上的新位置的问题,这意味着 LFS 会在整个磁盘中分散旧版本的文件结构,称为垃圾(garbage)。例如一个文件加入了新的数据,在磁盘上占有 2 个数据块,同时会写入一个新的 inode 指向该数据。但是由于旧版本的 inode 依然存在,因此文件之前占有的数据块仍然被旧的 inode 指向。因此 LFS 必须定期清理索引节点和其他结构的旧版本,使磁盘上的块再次空闲,以便在后续写入中使用。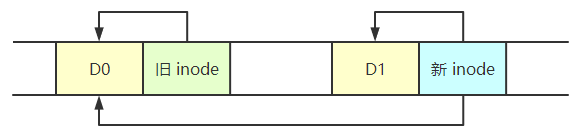
但是如果 LFS 清理程序在清理过程中只是简单地并释放单个数据块,会导致文件系统在磁盘上分配的空间之间混合了一些空闲洞(hole)。此时 LFS 无法找到一个大块连续区域写入,所以写入性能会大幅下降。
所以 LFS 清理程序按段工作,程序定期读入许多旧的段,确定哪些块在这些段中还活着,然后写出一组新的段存放其中活着的块,然后释放旧块用于写入。为了检验是否是旧版本,LFS 在使用了版本号来帮助实现。崩溃恢复
在正常操作期间 LFS 在日志(log)中组织写入操作,将一些写入缓冲在段中,然后当段已满或经过一段时间后将段写入磁盘。如果写入段时发生了崩溃,在重新启动时 LFS 可以通过简单地读取检查点区域、它指向的 imap 片段以及后续文件和目录,从而实现恢复。
但是在一个检查点更新的周期中发生的更新无法通过上述方式恢复,所以 LFS 尝试前滚(roll forward)*的技术重建段。基本思想是从最后一个检查点区域开始,找到日志的结尾,然后使用它来读取下一个段,并查看其中是否有任何有效更新。如果有,LFS 会相应地更新文件系统,从而恢复自上一个检查点以来写入的大部分数据和元数据。参考资料
《操作系统导论》[美]Remzi H.Arpaci-Dusseau,Andrea C.Arpaci-Dusseau 著,王海鹏 译,人民邮电出版社



若有收获,就点个赞吧
0 人点赞
