本文针对推荐系统提出了一种新的堆叠和重构图卷积网络(STAR-GCN)结构来学习节点的表征,提高推荐系统的效率,特别是在冷启动场景。STAR-GCN采用堆叠的GCN编码器/解码器与中间监督相结合,以提高最终预测性能。
一、简要信息
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 论文模型 | STAR-GCN |
| 2 | 所属领域 | 推荐系统 |
| 3 | 研究内容 | Graph Convolutional Networks; cold start; Stacked and Reconstructed |
| 4 | 核心内容 | 冷启动问题 |
| 5 | 论文PDF | 2019Arxiv-Star-gcn Stacked and reconstructed graph convolutional networks for recommender systems.pdf |
| 6 | GitHub代码 | https://github.com/jennyzhang0215/star-gcn |
二、研究背景
推荐系统中核心的数学问题就是矩阵分解,在MF中,每一个已知的得分是通过user和item的隐因子表征相乘得到的。近年来,深度学习的发展尤其是图卷积(GCN)对这个问题带来了一些新的解决思路。
GCN将卷积的定义从规则网络推广到不规则网络,像图结构。GCN通过一个局部共享参数算子来生成节点表示。一个图卷积算子通过转换或者聚合某个节点的局部领域节点的特征来生成该节点的表征。通过堆砌多个图卷积算子和非线性函数,构建了一个深度神经网络,可以抽取这个图远处的特征。因为局部邻域集可以看作卷积核的接收场,这类领域聚合方法称为图卷积。
Monti等人针对推荐系统首次提出了基于GCN的方法,在该方法里,GCN用于将user-user和item-item的两个图信息聚合,user和item的隐因子在每次聚合的时候更新,GCN和MF的目标函数通过组合用在这个模型里。此后提出了图卷积矩阵完成模型(GC-MC),GC-MC模型直接将user和item的关系描述为一个二部图。两个多连接卷积层用于聚合user和item的特征。通过预测边的label来估计得分。GC-MC模型取得了很不错的成绩。虽然很强大,但GC-MC模型有两个明显的限制。
- 为了区分每一个节点,GC-MC模型使用one-hot向量作为节点输入,无法应用在大规模图上;
- 模型不能预测训练过程中没有出现过的item和user,因为不能用one-hot表示没出现过的节点。这类任务就是我们熟知的冷启动。
因此,本文提出了新的框架,基于堆积和(或)重构图卷积网络(STAR-GCN)来解决这些问题,不同于GC-MC,STAR-GCN作为一个端到端的模式直接训练习得user和item的低维表征,为了提升模型能力,另外也针对冷启动问题,STAR-GCN盖住了部分或者整个user和item的表征,在训练阶段通过一小块图的编码解码器来重构盖住的部分。这个想法灵感来源于NLP里的 masked language model,我们结合特定于任务的中间监督构建了一组编码器-解码器块,以提高最终性能。
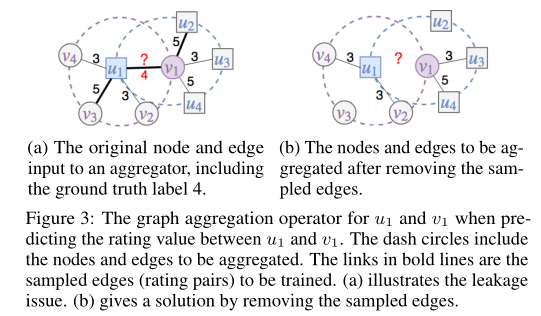
在实施过程中,训练基于GCN的模型进行评级预测时会遇到标签泄漏问题,这会导致过拟合问题并严重降低最终性能。 为避免泄漏问题,我们提供了一个采样-丢弃训练策略,并通过实验证明了其有效性。
三、传统方法
这里简单回顾一下GC-MC。
GC-MC 利用一个多连接图卷积编码器来生成节点表征,每一个连接类型 r rr 赋值为一种特殊的转化。信息按如下方式从 item 传到 user。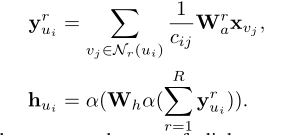
其中, 是一个连接类型
是一个连接类型  的聚合结果,
的聚合结果,  是 item
是 item 的初始化向量,
的初始化向量, 是对打分 的一个
是对打分 的一个  的权重矩阵,将
的权重矩阵,将  维的向量转为
维的向量转为 维,
维,  是标准化常数,
是标准化常数, 是由边值 连接的邻域。
是由边值 连接的邻域。
对于每个 user,会有多个不同的打分 ,首先将打分都为的聚合到一起,得到,然后再将不同打分经过两次非线性变换得到 user 的表征 。
四、模型任务
模型主要聚焦于评分预测任务,与其他基于图方法的协同过滤模型不同,评分预测任务更侧重于连接预测的问题,也就是用户物品交互矩阵的预测。而基于图方法的协同过滤任务希望学习物品与用户的特征进行嵌入尽可能重构还原交互矩阵,两者的侧重点略有不同。
基于GCN的模型将推荐环境当做一个无向二部图,由user  和item
和item  两部分组成。打分集合
两部分组成。打分集合  中每个打分都代表二部图里的一个连接,聚焦于两种类型的打分预测任务:Transductive Rating Prediction和Inductive Rating Prediction,两者主要的区别在于Transductive Rating Prediction在训练时包括所有的测试样本,而Inductive Rating Prediction则为训练集和测试集分离的情况。
中每个打分都代表二部图里的一个连接,聚焦于两种类型的打分预测任务:Transductive Rating Prediction和Inductive Rating Prediction,两者主要的区别在于Transductive Rating Prediction在训练时包括所有的测试样本,而Inductive Rating Prediction则为训练集和测试集分离的情况。
在本文中,I**nductive学习用于解决冷启动问题,即在训练阶段将cold节点完全掩盖,不参与训练,在预测之前会访问其中一些边。(主要是不参与训练,传统方法不重新训练即无法解决此任务)如下图所示。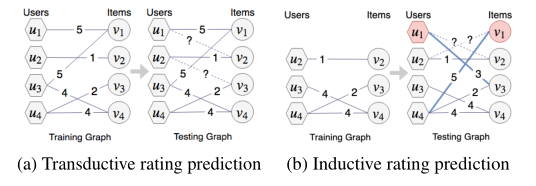
Transductive Rating Prediction
如上图(a)所示,是针对已经存在的 user 和 item 之间的连接。
Inductive Rating Prediction**
如图(b)所示,对新来的user或者item预测,实际上就是冷启动问题。
对比CDL和DropoutNet,STAR-GCN不仅利用节点的内容信息,而且结合了结构信息来学习新节点的表征
五、主要思想
本文提出了一种新的基于堆积重构图卷积网络框架(STAR-GCN),不同于GC-MC,STAR-GCN作为一个端到端的模式直接训练习得user和item的低维表征,为了提升模型能力,另外也针对冷启动问题,STAR-GCN盖住了部分或者整个user和item的表征,在训练阶段通过一小块图的编码解码器来重构盖住的部分。再结合特定于任务的中间监督构建了一组编码器-解码器块,最终提高了性能。
模型框架如下图: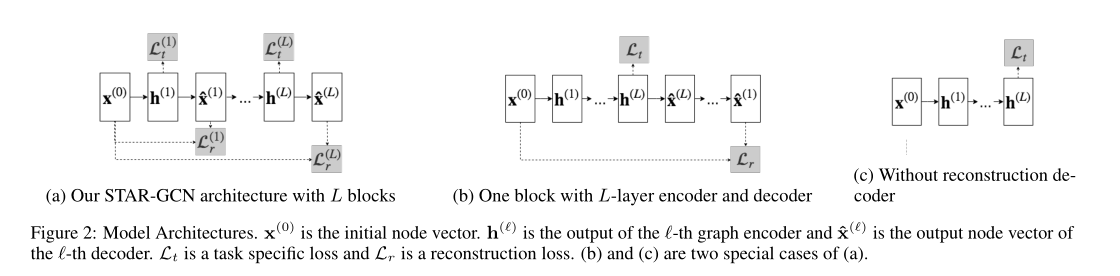
其中, 其中,是初始节点向量,
其中,是初始节点向量,  是第
是第  层图编码器的输出,
层图编码器的输出, 代表第 层图解码器的输出,
代表第 层图解码器的输出, 代表编码器解码器重构损失,
代表编码器解码器重构损失, 代表具体任务的损失函数。
代表具体任务的损失函数。
图2(a)为作者提出的模型的通用框架,包含了多个 编码-解码 块,多个编码块可以堆叠(参数不共享)也可以重构(参数共享)。图2(b)和图2(c)是图2(a)的两种特例,(b)表示每个编码块可以包含多个GCN层,(c)表示可以不解码重构直接用于下游任务。
通用的损失函数形式为: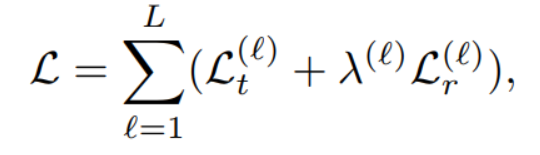
假设我们用一批样本边集合  和两个盖住的节点集合
和两个盖住的节点集合  ,
,  ,则特定的loss 为针对于评分预测任务,具体的
,则特定的loss 为针对于评分预测任务,具体的  和 为:
和 为: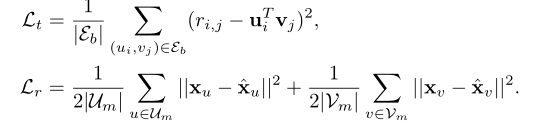
对于打分预测 loss, ,
,  由图编码器输出的线性变换生成,
由图编码器输出的线性变换生成,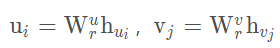 ,其中,
,其中, 。 是预测评分的均方误差,是物品向量和用户向量的重构误差。
。 是预测评分的均方误差,是物品向量和用户向量的重构误差。
mask机制
为了让网络扩展到大规模图,本文用lookup操作将每个节点映射到一个低维的向量, , 在网络中通过端到端训练得到。但是简单的替换one-hot类型向量还是没法解决冷启动问题,因为新节点的embedding不在训练数据里。于是作者采取了一种方法,即随机掩盖一定百分比的输入节点,然后重建新的节点的表征。在每一个batch训练中,会盖住20%的节点,然后重建这部分节点的表征,对于这部分盖住的节点,做以下操作:
在网络中通过端到端训练得到。但是简单的替换one-hot类型向量还是没法解决冷启动问题,因为新节点的embedding不在训练数据里。于是作者采取了一种方法,即随机掩盖一定百分比的输入节点,然后重建新的节点的表征。在每一个batch训练中,会盖住20%的节点,然后重建这部分节点的表征,对于这部分盖住的节点,做以下操作:
- 以概率
 将节点表征初始化为0。
将节点表征初始化为0。 - 以
 概率保持不变。
概率保持不变。
训练masked 表征机制有两个好处:
- 第一,在训练过程中,它可以学习到没被观测到的节点,在冷启动场景,我们初始化新节点为0,通过多个GCN编码器/解码器块逐步完善估计的表征。例如,第一个块通过利用邻域数据(或节点属性,如果可用)来预测新节点的表征。 然后,将预测的表征内容馈送到第二个块,以预测评分和精确的表征内容。 评级和表征预测损失是共同优化的。 因此,STAR-GCN可以通过迭代优化嵌入来解决冷启动问题,并且与GC-MC根本不同。
- 其次,STAR-GCN导致转导环境的改善。 在训练阶段,部分节点嵌入被掩盖,并要求网络重构这些掩盖的嵌入,这要求网络有效地编码用户和项目之间的关系。 因此,重建损失充当提高基本评级预测任务的性能的多任务正则器。其次,STAR-GCN导致转导环境的改善。 在训练阶段,部分节点表征被掩盖,并要求网络重构这些掩盖的表征,这要求网络有效地编码 user 和 item 之间的关系。 因此,重建损失充当了多任务调整器,可提高主要评级预测任务的性能。
图编码器和解码器
图编码器通过聚合不同的打分等级的邻域信息,将输入节点向量 转换为大小为
转换为大小为  的隐状态
的隐状态  ,例如
,例如  ,我们在GC-MC 中选择如方程
,我们在GC-MC 中选择如方程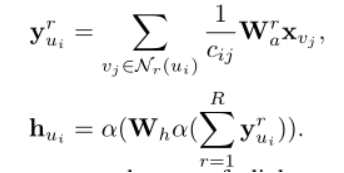 所示的编码器作为多连接GCN聚合器。解码器将结构编码节点表征 转成一个 维的重构表征向量
所示的编码器作为多连接GCN聚合器。解码器将结构编码节点表征 转成一个 维的重构表征向量  ,
, ,用一个两层的神经网络作为解码器,如
,用一个两层的神经网络作为解码器,如  ,其中输出维度都是 。STAR-GCN是带有一堆编码器解码器的通用型框架,任何类型的GCN,如Graph-SAGE,GAT都可以在STAR-GCN中作为编码器或解码器。因此STAR-GCN是一个通用的框架。
,其中输出维度都是 。STAR-GCN是带有一堆编码器解码器的通用型框架,任何类型的GCN,如Graph-SAGE,GAT都可以在STAR-GCN中作为编码器或解码器。因此STAR-GCN是一个通用的框架。
六、实验评估
数据集
Flixste & Douban 经过预处理 (provided by Monti et al. [2017])(视为小数据集)
Movielens(ML-100K(视为小数据集), ML-1M, and ML-10M(视为大数据集))
统计情况如下表: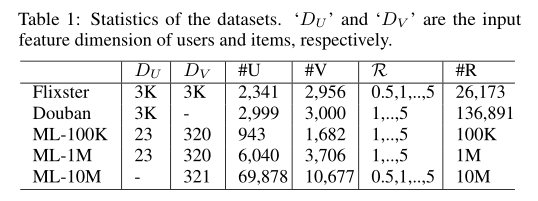
评估指标
RMSE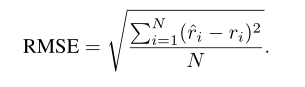
实验设置
 作为LeakyReLU激活函数,其负斜率=0.1,应用了两组超参数,一组用于小型数据集,另一组用于大型数据集。对于输入向量,对于小型数据集,我们将节点嵌入的维数设置为32,对于大型数据集,则为64。合并特征时,对于小型数据集,投影维数
作为LeakyReLU激活函数,其负斜率=0.1,应用了两组超参数,一组用于小型数据集,另一组用于大型数据集。对于输入向量,对于小型数据集,我们将节点嵌入的维数设置为32,对于大型数据集,则为64。合并特征时,对于小型数据集,投影维数 为8,对于大型数据集,投影维数为32。
为8,对于大型数据集,投影维数为32。
关于mask机制,对于transductive prediction,我们随机选择 的节点进行重构,并设置
的节点进行重构,并设置 。对于inductive prediction,我们统一选择
。对于inductive prediction,我们统一选择 的节点并将其掩码为零,即
的节点并将其掩码为零,即 ,以近似测试数据分布。对于编码器,隐藏层大小设置为250。输出层维数的大小为75。我们对GCN层的输入应用一个dropout层,对于小型数据集,其dropout为0.5;对于大型数据集,其dropout为0.3。对于解码器,所有隐藏层大小都固定为节点输入维,即。在预测评分时,我们将投影维数
,以近似测试数据分布。对于编码器,隐藏层大小设置为250。输出层维数的大小为75。我们对GCN层的输入应用一个dropout层,对于小型数据集,其dropout为0.5;对于大型数据集,其dropout为0.3。对于解码器,所有隐藏层大小都固定为节点输入维,即。在预测评分时,我们将投影维数 设置为64。
设置为64。
使用Adam优化器训练STAR-GCN模型,并使用验证集执行学习速率衰减调度器。每次验证RMSE分数未落在100次迭代的窗口中时,初始学习率设置为0.002,然后逐渐减小为0.0005,衰减率为0.5,并且早期停止发生150次迭代。梯度归一化值限制为不大于1.0。对于小型数据集,训练批次大小固定为10K,对于ML-1M,训练批量固定为100K,对于ML-10M,训练批量固定为500K。除了两次ML-10M训练外,我们使用不同的随机种子对模型进行了三次训练,并报告了平均测试RMSE分数和标准差。实验结果
Transductive Rating Prediction
ML-100K——80%训练集,20%测试集,其余90%训练集,10%测试集。
表2总结了基线和STAR-GCN的所有结果。基线分数直接取自Monti等人。 [2017]和Berg等。 [2017]。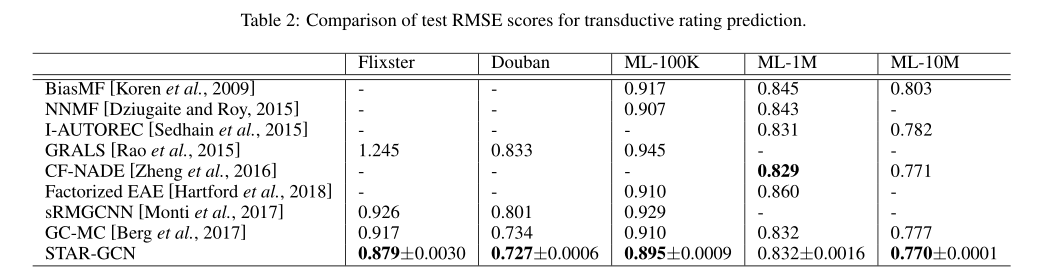
进行消融分析,表3中列出的不同STAR-GCN模型的最佳结果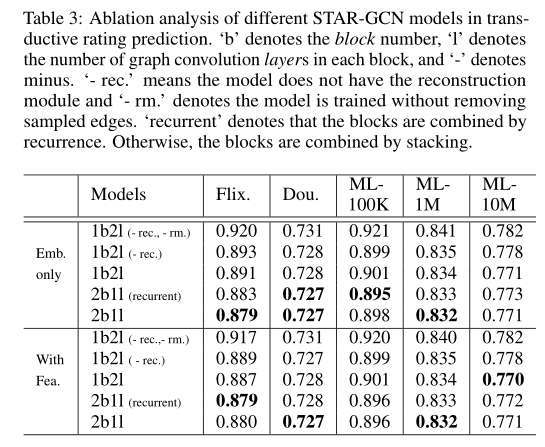
b 代表块数,l 代表每块中的图卷积层数,-rec 代表无重构模块,-rm 表示在不删除采样边的情况下训练了模型。 “recurrent”表示这些区块是通过重复组合而成的。否则,将通过堆叠将块组合在一起。
由表可知,采样-去除策略取得了良好的效果。比较’1b2l(-rec-rm)’和’1b2l(-rec)’的结果,在每次训练中从二部图中删除采样的用户项目对后,我们发现测试RMSE得分显着下降。
将标有“-rec”的模型与没有标签的模型的结果进行比较表明,具有重构模块的模型在不使用相同总数的图编码器进行重构的情况下始终击败该模型,这证明我们的重构机制是有利于最终的预测性能。
比较“ 2b1l(recurrent)”和“ 2b1l”的结果,我们发现循环结构可以用更少的参数获得竞争性结果。
通过比较使用和不使用特征的相同模型的结果,我们注意到,组合外部节点特征并不总是可以产生更好的性能。Inductive Rating Prediction
实验仅使用 Douban, ML-100K, and ML-1M,20%测试集。实验结果如下图所示。50%,30%,10%为保留的训练集数据。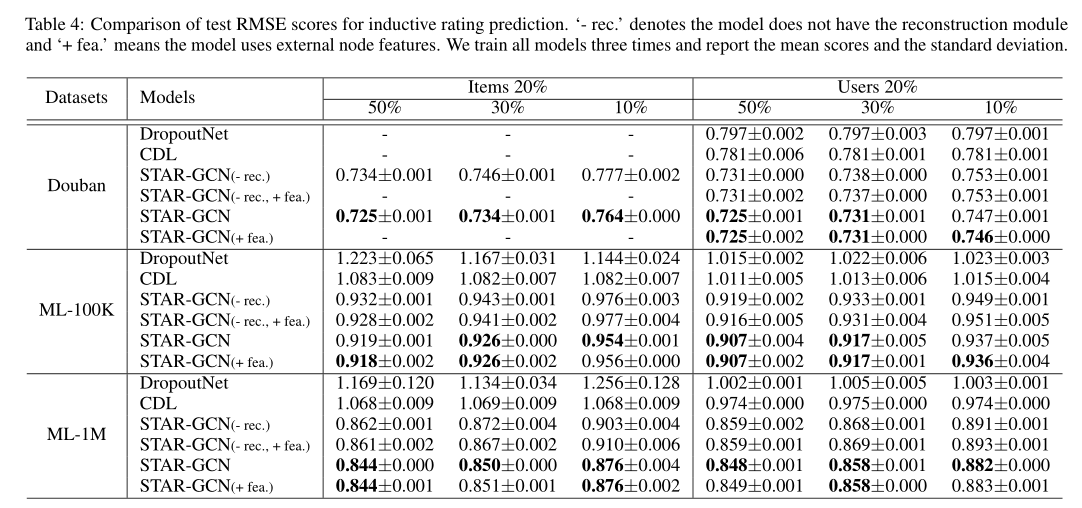
表4列出了实验的RMSE得分。当预测器在测试阶段访问较少的新用户/项目的相邻边时,我们会发现较差的性能趋势。我们表明,我们的STAR-GCN模型产生的结果明显优于两个基线。此外,通过比较使用和不使用重构模块的模型结果,我们发现重构机制在提高最终性能方面起着至关重要的作用。一个有趣的观察是,为新节点合并内容信息并不总是对最终结果有利。原因可能是我们重构的节点嵌入已经包含足够的信息来进行准确的预测,这证明我们的STAR-GCN可以使用结构信息有效地解决冷启动问题。八、其他
总结
本文介绍了一种基于GCN的新架构,并将其应用于Transductive Rating Prediction和Inductive Rating Prediction。STAR-GCN在两项预测任务中均达到了最新水平。我们的体系结构是通用的,可用于其他应用程序,例如异常行为检测,时空预测,线程流行度预测等 。此外,当为评分预测任务实施基于GCN的模型时,我们发现了训练标签泄漏问题。这一发现应提醒人们以后的研究。未来,我们计划改进STAR-GCN以处理具有不同节点类型的异构图,以更好地模拟现实生活场景,并整合排名算法以解决其他推荐任务。数学理论
如何通俗易懂地解释卷积?https://www.zhihu.com/question/22298352
如何理解 Graph Convolutional Network(GCN)?
https://www.zhihu.com/question/54504471/answer/630639025
一文读懂图卷积GCN:https://zhuanlan.zhihu.com/p/89503068
图嵌入的分类:https://zhuanlan.zhihu.com/p/77729049
拉普拉斯公式推倒细节,包括谱分解和傅立叶变换:https://www.zhihu.com/question/54504471/answer/332657604
各种图卷积核比较:https://github.com/conferencesub/ICLR_2020
拉普拉斯矩阵和拉普拉斯算子的关系:https://zhuanlan.zhihu.com/p/85287578
GNN首次被提出的paper:https://persagen.com/files/misc/scarselli2009graph.pdf

若有收获,就点个赞吧
0 人点赞
