一、简要信息
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 论文模型 | ICAN |
| 2 | 所属领域 | 推荐系统 |
| 3 | 研究内容 | multi-channel matching; Internal and contextual at- tention network |
| 4 | 核心内容 | 物品冷启动问题 |
| 5 | 论文PDF | 2020IJCAJ-Internal and Contextual Attention Network for Cold-start Multi-channel Matching in Recommendation.pdf |
| 6 | GitHub代码 | https://github.com/zhijieqiu/ICAN |
二、研究背景
真实世界中的综合推荐系统(例如微信看一看)能够综合不同来源(例如公众号、新闻源、网页)和不同媒体形态(例如文章、微博、长视频、短视频等)的物品进行联合推荐,通常需要从上百万异构物品中进行推荐。直接在百万候选集上使用复杂的推荐算法,往往会引入难以承受的时间成本。一些复杂的user-item pair-wise的推荐算法,如DIN、DeepFM、AutoInt等,需要穷尽所有候选集进行计算。因此,工业级综合推荐系统一般由召回(matching)和排序(ranking)两个模块组成。这种召回-排序结构是现在大规模推荐系统的主流架构。
召回模块负责快速从百万级数据中检索出百级别物品候选,排序模块负责准确对这些召回来的物品候选排序,得到最后的推荐结果。由于推荐物品来源多种多样,特征也不尽相同,同时也为了兼顾多样性,召回部分通常会使用多队列召回(multi-channel matching)策略。
然而,在现实系统中,综合推荐系统经常会引入新的数据源,这部分冷启动的召回通道在行为稀疏时往往表现较差。为了解决这些问题,本文提出一种Internal and contextual attention network (ICAN)模型,通过加强多队列之间特征域(feature field)交互和环境信息,得到更好的(冷启动)召回效果。作者在微信看一看系统上进行了离线和在线实验,均获得显著提升。目前ICAN已部署在微信看一看线上召回系统。
下图给出了看一看场景中综合推荐的示例,包含文章、长视频、短视频三种召回队列(channel)。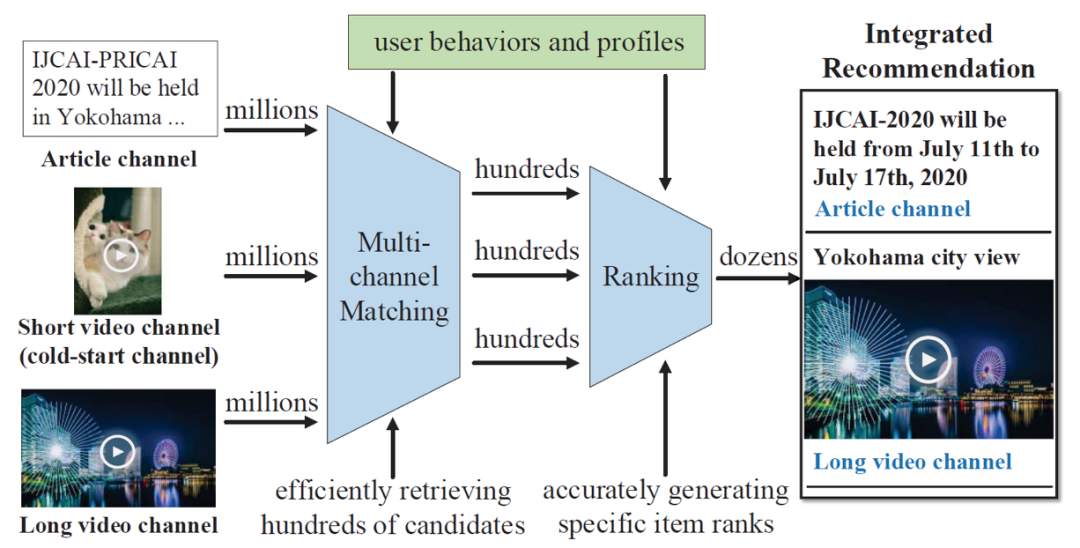
在现实系统中,综合推荐系统经常会引入新的数据源。微信看一看中较主要的信息来源和召回队列就超过了几十个。这部分冷启动的召回通道在建立初期,用户行为往往比较稀疏,基于用户行为的CTR预估模型表现较差。需要注意的是,和针对冷启动用户的推荐算法不同,冷启动召回队列(新信息源的召回队列)中冷启动的是物品和物品所拥有的特征本身。一个直观的方法是使用用户在其它队列上的点击等行为,预测用户在新信息源上物品的偏好,但是不同队列包含的特征域(feature field)可能不一样。不同信息源可能会有特征域上的种类差异,即使是相同特征域(如tag/topic/category),特征含义也很可能不相同(不同数据源的tag/topic/category体系和粒度不同,难以进行直接对应)。模型需要学习到不同特征域之间的映射关系,但是很少有召回工作关注冷启动队列的问题。
在这篇论文中,作者想要提升推荐系统在多队列召回,特别是冷启动召回上的表现。作者提出一种Internal and contextual attention network (ICAN)模型,通过加强多队列之间特征域交互和环境信息,得到更好的(冷启动)召回效果。
三、传统方法
协同过滤(CF)是一种经典而直接的方法,它直接根据相似的项目[Sarwar等,2001]或用户[Breese等,1998]推荐项目。矩阵分解试图分解用户-项目交互矩阵,以学习用户和项目的表示形式[Koren et al。,2009]。因子分解机(FM)[Rendle,2010]和可感知领域的FM [Juan et al。,2016]对二阶特征与相应潜在向量的相互作用进行建模,以缓解数据稀疏性问题。随着深度学习的蓬勃发展,神经网络模型已成功用于推荐排名的CTR预测。 Wide&Deep [Cheng et al。,2016]结合其Wide和Deep架构共同考虑了记忆和概括能力。 DeepFM [Guo et al。,2017]和NFM [He and Chua,2017]结合了神经FM和DNN,而DCN [Wang et al。,2017]和xDeepFM [Lian et al。,2018]旨在捕获高阶交互。 AFM [Xiao et al。,2017]和Autoint [Song et al。,2019]都关注这种相互作用。大多数深度排序模型因其在数百万个候选者上的巨大计算成本而难以用于大规模召回,在这种情况下,甚至连语料库大小的线性复杂度也不可接受。
召回推荐。专注于召回的研究较少。常规的召回模块通常依赖于基于简单信息检索(基于IR)的模型[Khribi等,2008],或由Item-CF [Sarwar等,2001]或FM [Rendle,2010]支持的基于嵌入相似性的模型。 ]。最近,Youtube [Covington等,2016]强调了行业中广泛使用的两步式架构,该架构引入了深度模型来构建用户嵌入以进行匹配。 TDM [Zhu et al。,2018]和JDM [Zhu et al。,2019]将每个项目存储在巨大的树形结构中,以快速选择最接近前k个最相似的项目,将匹配和排名结合在一个模型中。在TDM / JDM中,树的构造对于检索top-k项至关重要,而k项在冷启动通道中会严重缺乏数据稀疏性。
注意力机制和冷启动问题。近年来,在推荐排名中目睹了巨大的成功。 DIN [Zhou et al。,2018b]和DIEN [Zhou et al。,2019]引入了对用户历史行为的注意力机制。 TRank [Zhou et al。,2018a]对用户行为进行自我注意,CSAN [Huang et al。,2018]提出了特征级的自我注意以对更复杂的交互进行建模。对于冷启动问题,大多数作品使用外部信息或转移学习进行排名[Schein et al。,2002; Deldjoo等人,2019年],而很少有工作专注于召回的冷启动渠道。与这些模型不同,我们考虑了成熟渠道中的用户行为来指导冷启动渠道中的推荐。据我们所知,我们是第一个在召回冷启动渠道将内部和上下文关注结合起来的公司。
四、模型框架
这篇论文目的是使用多队列之间的特征域交互,辅助推荐系统在多队列(冷启动)召回上的效果。图2给出了ICAN模型的整体架构。
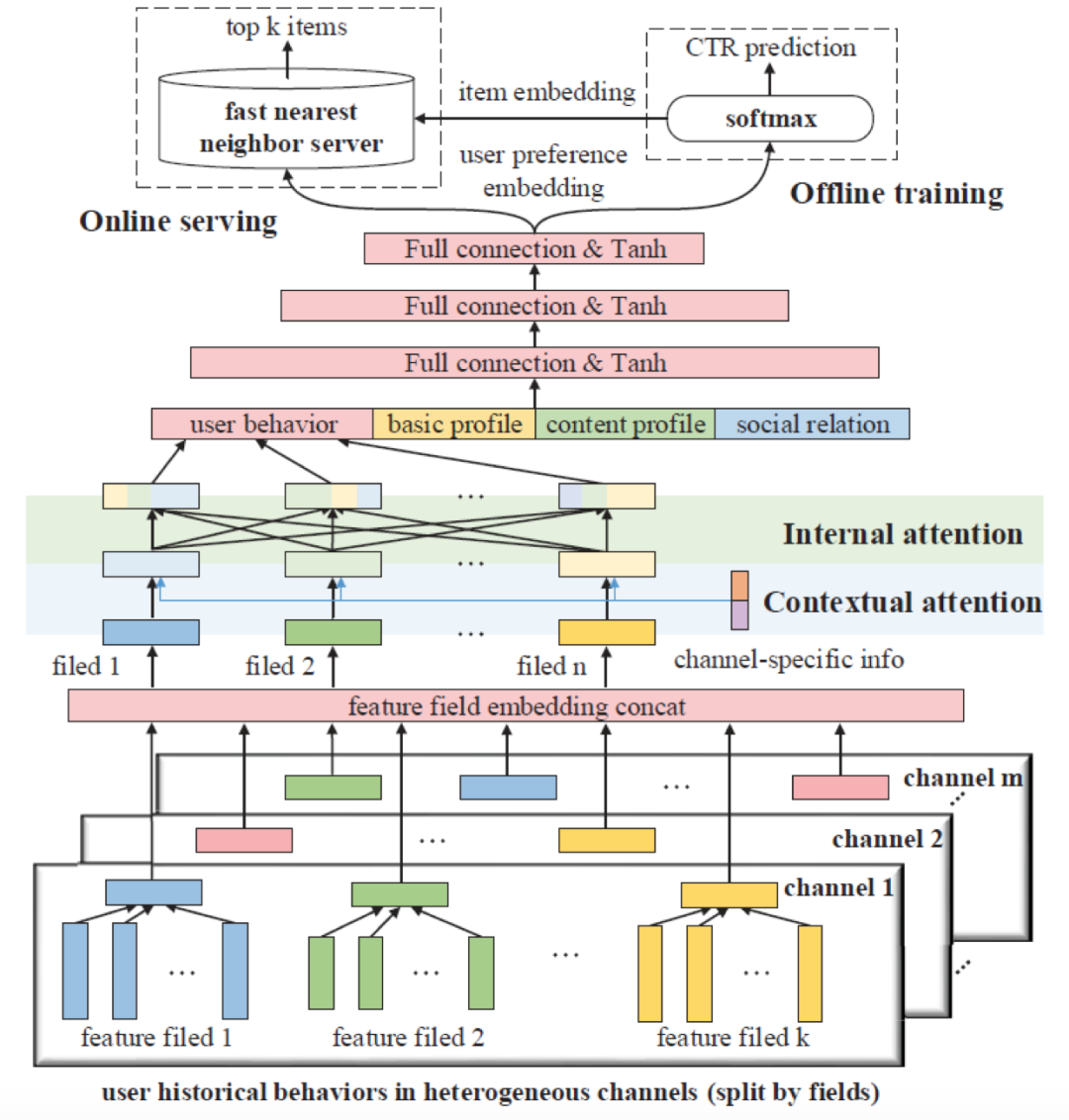
如图2所示,ICAN模型首先将成熟队列和冷启动队列中的用户行为序列同时作为输入,并按照特征域把每个队列中的行为序列拆分成不同的特征域序列。然后,ICAN通过Contextual Attention Layer抽取多队列特征域和环境相关的特征。接下来,ICAN通过Internal Attention Layer中的field-level self-attention挖掘不同队列的不同特征域之间的交互信息。最后,模型融合用户行为、用户基本属性、推荐上下文信息以及用户社交属性信息等,参RecSys2016的Youtube召回模型的训练方式,离线使用softmax基于CTR预估进行训练,在线使用类似基于FAISS的快速召回工具进行召回。这样,线上ICAN召回的时间复杂度就控制在O(log(n))。模型的核心创新点在于针对多队列冷启动召回问题提出的基于特征域的跨队列信息交互。
具体地,在第一步,模型首先将成熟队列和冷启动队列中的用户行为序列同时作为输入。和传统的session-based recommendation不同,ICAN把所有队列中的每个item向量按照其特征域数目拆分成n份,并根据特征域组成n个新的序列。例如在article队列中,每个article的特征域由文章的[ID, tag, category]三个特征域组成,那在ICAN的输入中,用户在article队列上的点击行为即分为ID, tag, category三个序列。每个特征域序列经过encoder得到特征域的向量。
第二步,作者使用Contextual Attention Layer,抽取前述特征域向量中和当前队列的环境(contexts)相关的特征。这里的环境主要有两个因素,其一是当前召回所在的队列,其二是推荐的上下文环境(包括网络状况等因素)。模型通过注意力机制,获得了环境特化的特征域向量: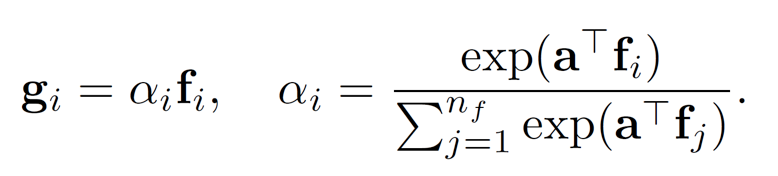
第三步,作者使用Internal Attention Layer,让环境特化后不同队列下的不同特征域之间进行充分的特征交互。这里,作者使用了field-level self-attention模型,进行不同特征域之间的特征交互:
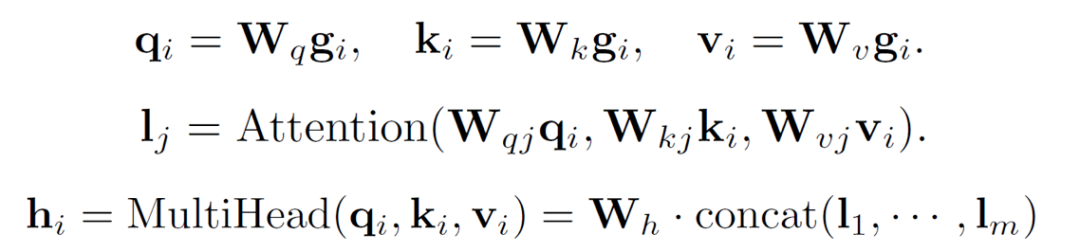
和传统self-attention不同,这里输入的不是item矩阵,而是item按特征域拆分,并在队列内进行序列聚合后的特征域矩阵。这是因为ICAN主要目的是学习到不同队列特征之间的交互信息。这样在冷启动队列中进行推荐时,本队列用户行为不足或本队列特征学习不够充分的情况下,可以借助其他队列的信息学习到用户在冷启动队列中的偏好。另外,在使用其它成熟队列点击进行训练时,模型也可以对冷启动队列的特征进行更新。
第四步,模型融合用户行为、用户基本属性、推荐上下文信息以及用户社交属性信息,通过MLP得到了(环境特化后的)用户向量。模型基于用户向量,使用softmax进行CTR预估。Loss如下: 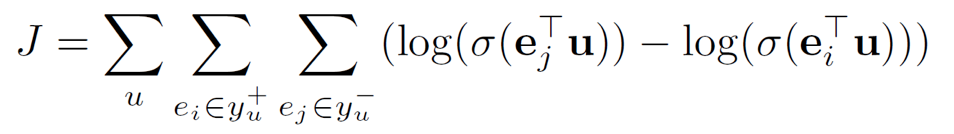
该损失函数认为和用户向量相似的物品向量更可能被点击。因此,在线上进行实时召回时,ICAN只需要使用一次前馈神经网络即可获得用户向量,然后基于类似FAISS的快速召回工具进行K近邻召回即可,相似度使用用户向量和物品向量之间的余弦相似度。这样,线上召回的时间复杂度就控制在O(log(n))内,能够在线快速处理千万级物品候选。
五、实验评估
数据集
由于没有用于多队列召回的大规模开放数据集,因此我们构造了一个从微信看一看中提取的新的异构多队列召回数据集HMM-700M。我们随机选择了三个成熟和冷启动队列中的近3000万用户,并随机抽样了近7亿用户点击行为。我们将前几天的用户行为用作训练集,并将其余部分随机分为验证集和测试集。
我们专注于三个代表性的异构队列,包括文章,长视频和短视频队列,其中短视频队列是冷启动队列,其他队列是成熟队列。长视频频道通常由专业视频(例如纪录片)组成,而短视频频道则包含自制的肖像模式视频,通常少于30秒。我们专注于9个典型功能字段,包括所有三个队列的商品ID,类别和标签。不同队列中的ID /类别/标签被视为不同的功能字段。
统计情况如下表: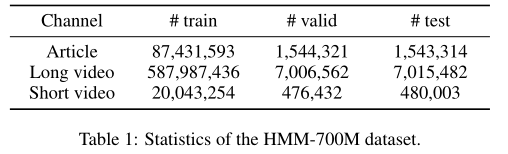
评估指标
HitRate:作者在微信看一看上进行了离线和线上实验。由于是召回模型,离线指标上ICAN更加关注用户可能点击的物品是否被召回,并不在意点击的物品具体排在第几位。因此,在离线指标上,作者没有使用AUC /MAP这类排序指标,而是使用了HitRate作为指标。
在线评估指标:
点击率(CTR),列表式点击率(LCTR),人均平均阅读时间(ART)和人均观看的平均类别数(ACN)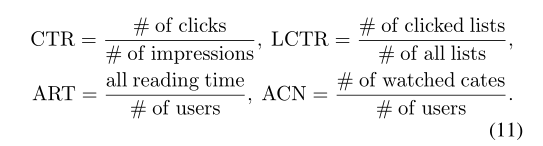
Baseline
Conventional Methods:使用基于信息检索(IR)的方法[Khribi et al。,2008]进行召回是很直观的。我们使用用户历史行为中的标题词构建“查询”,以在目标队列中检索相关项目。我们还实现了Item-CF [Sarwaret al。,2001],该技术可以根据点击的项目检索相似的候选对象。此外,我们从Rendle [2010]进行了改进的FM模型,该模型仅考虑了用户项目的两级交互作用。仅在这种情况下,增强型FM才能使用基于嵌入的top-k最近邻服务器(例如Faiss)进行快速检索。这些模型是经典而有效的方法,已在实践中得到广泛验证,可以处理数百万个匹配的候选对象。
Deep Neural Methods:Youtube的候选生成模型[Covington等,2016]是经典的基于深度的匹配模型。为了验证多队列信息的重要性,我们使用Youtube(Origin)表示仅考虑目标队列中用户行为的原始Youtube模型,并针对具有多个队列中行为的用户使用Youtube(Multi)。我们还进行DeepFM [Guo et al。,2017],NFM [He and Chua,2017]和AFM [Xiao et al。,2017],它们在ICAN中使用相同的用户功能,包括用户多队列行为和用户多样化的配置文件学习用户偏好嵌入。这三种模型遵循与ICAN相同的训练和在线服务策略。
我们应该澄清,所有具有不低于线性复杂度且百万级项目的排序模型在匹配中是不可接受的。因此,大多数深度排名模型(例如DIN和TRANSk)无法处理匹配任务,因为它们不能直接使用基于嵌入的快速检索。此外,我们还尝试了TDM [Zhu et al。,2018],发现它不太适合冷启动多队列召回。 TDM的树结构对于匹配是必不可少的,而在冷启动队列中构建具有稀疏行为的学习良好的树非常困难。
利用ICAN来代表作者的最终模型。为了确认上下文和内部注意力机制的重要性,我们还进行了消融实验,该测试将ICAN(不带内部注意力机制)和ICAN(不带上下文注意力机制)实现为不同的ICAN版本。
实验设置
在ICAN中,我们将每个队列中的20个最新点击行为用作用户历史行为。异构特征,上下文注意和内部注意层中输出嵌入的维度为64。三个用户配置文件的维度也为64。3层MLP中输出嵌入的维度为128、64和64。我们使用Adam负样本数为20,批次大小为512的训练。所有ICAN模型和基线均遵循相同的实验设置,以进行公平比较。
实验结果
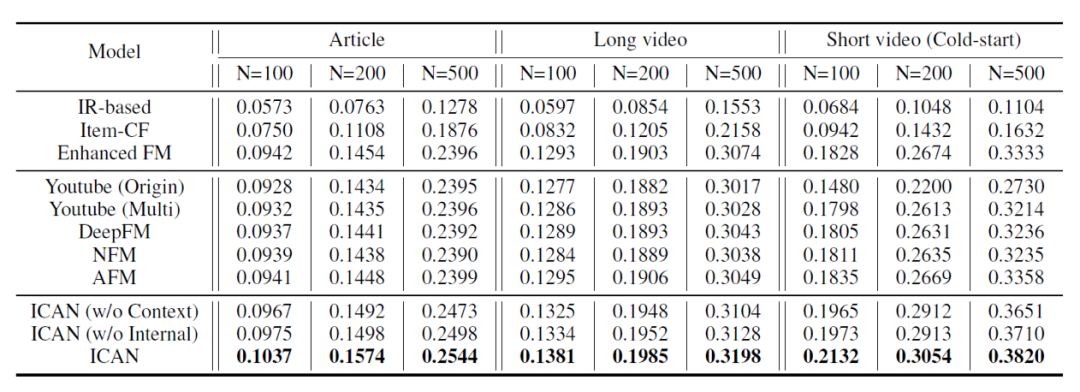
由于线上实际使用top500作为召回结果,作者主要考虑了100,200,500三种情况。结果如下:
在多种指标下,ICAN模型在成熟队列和冷启动队列上都得到了最佳的效果,其中在冷启动队列上提升更为显著。
ICAN的消融实验说明了Contextual Attention Layer和InternalAttention Layer的有效性。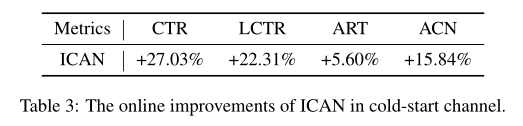
线上实验结果说明ICAN能够提升CTR、list-wise CTR、阅读时长和平均点击类别数(多样性指标)等多项指标,显著提升了线上效果。
除此之外,作者还进行了两种attention的可视化,如图3图4所示。以图3为例,我们可以发现在冷启动队列(短视频队列)中进行召回时,长视频的tag特征域似乎起到了很大的作用,甚至高于短视频自己的category/tag特征域的作用权重。图4也说明在internal attention中,不同特征域之间存在一定的交互范式。这样的结果说明两点:(1)使用成熟队列信息辅助冷启动队列是很有必要的。(2)把队列信息从物品级拆分成特征域级是很有必要,因为不同队列的不同特征域之间交互模式不同。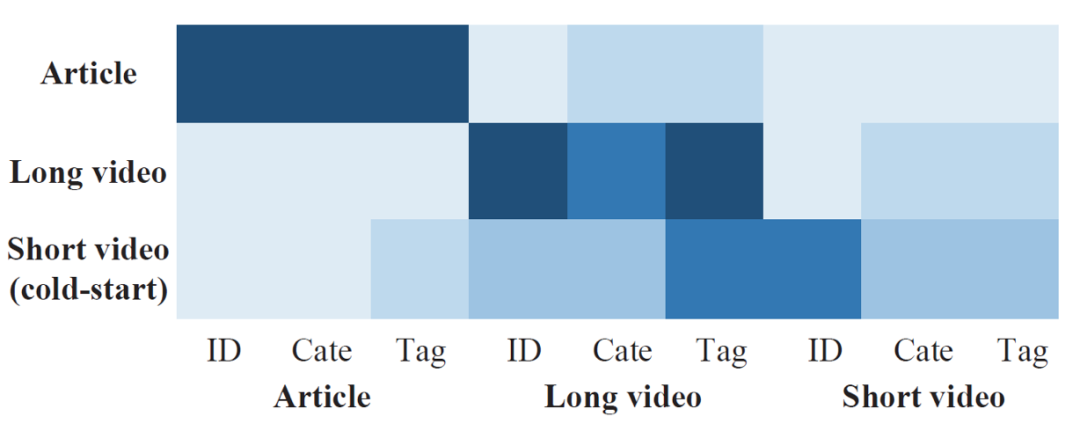
图3:Contextual Attention的heatmap
图3显示了上下文注意力机制的热图。水平轴表示不同通道的特征字段,而垂直轴表示要召回的目标通道。我们观察到:(1)成熟的队列(例如商品)更多地集中在其自己的功能字段(例如商品ID,类别和标签)上。这是因为成熟的队列已经具有足够的用户行为来学习有效的召回模型。长视频队列还关注短视频队列的特征字段,因为它们既是视频又共享更多相似之处。(2)冷启动短视频队列受成熟队列中其他特征字段(例如长视频标签)的强烈影响。它再次确认了在冷启动队列中上下文注意和特征字段交互的重要性。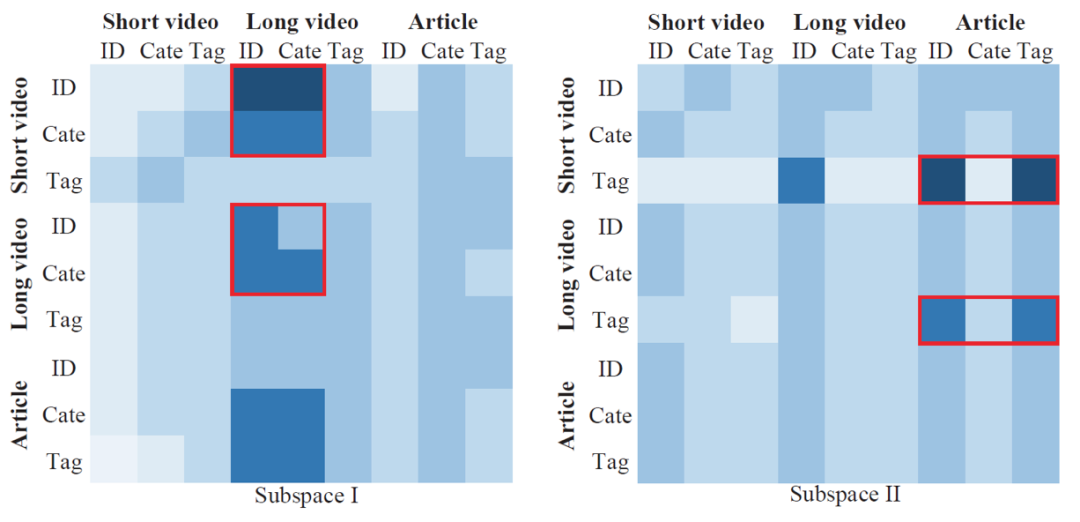
图4:Internal Attention的heatmap
图4显示了两个子空间,它们捕获了来自其他成熟队列的信息。在左侧的热图中,当构建两个视频队列的ID和类别嵌入时,内部注意力机制会放大长视频通道的ID和类别字段。在右侧的热图中,当构建两个视频队列的标签嵌入时,内部注意力机制会突出显示文章队列的标签和ID字段。
八、其他
总结
本文提出了一个ICAN模型,使用多队列之间的特征域交互,辅助提升推荐系统在多队列(冷启动)召回上的效果。模型针对任务进行了特征域级别的拆分,使得不同队列之间的交互变得更为精细。ICAN使用了直观的模型,在工业级大规模推荐数据集和线上系统中均得到了成功的验证。未来,更复杂细致的交互方式和与多任务学习/迁移学习的融合可能会是潜在的研究方向。

若有收获,就点个赞吧
0 人点赞
