作为解决推荐器系统中数据稀疏性和冷启动挑战性问题的一种有前途的方法,跨域推荐最近引起了越来越多的研究兴趣。跨域推荐旨在通过将显式或隐式反馈从辅助域传递到目标域来提高推荐性能。尽管评论文本和物品内容的辅助信息已被证明在推荐中很有用,但是大多数现有工作仅使用一种辅助信息,而无法将该辅助信息与评分深度融合。因此,作者提出了一种基于评论和内容的深度融合模型RC-DFM,用于跨域推荐。我们首先扩展了堆叠降噪自动编码器(SDAE),以有效地将评论文本和物品内容与辅助域和目标域中的评分矩阵融合在一起。通过这种方式,在两个域中学习到的用户和物品的隐因子保留了更多的语义信息以供推荐。然后,利用MLP在两个域之间转移用户隐因子,以解决数据稀疏性和冷启动问题。真实数据集上的实验结果表明,与最新推荐方法相比,RC-DFM具有优越的性能。
一、简要信息
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 论文模型 | RC-DFM |
| 2 | 所属领域 | 推荐系统 |
| 3 | 研究内容 | cold start; Stacked Denoising Autoencoders; Cross-domain recommendation; latent factors |
| 4 | 核心内容 | 冷启动问题 |
| 5 | 论文PDF | 2019AAAI-Deeply fusing reviews and contents for cold start users in cross-domain recommendation systems.pdf |
| 6 | GitHub代码 | 未找到 |
二、研究动机
作为解决冷启动问题的有希望的解决方案,跨域推荐算法近年来受到越来越多的关注。这种算法尝试利用来自多个辅助域的显式或隐式反馈来提高目标域中的推荐性能。诸如评论文本和基本描述之类的辅助信息可能有助于为用户和物品生成更好的潜在特征,从而改善推荐性能。但是,大多数现有的跨域推荐工作仍未充分考虑各种有价值的辅助信息。尽管最近有几篇著作试图利用一种辅助信息,但它们无法将辅助信息与评分矩阵充分而深入地融合。因此,本文既考虑了评论文本,又考虑了物品内容,同时使它们与评分进行深度融合。这些辅助信息既可以改善推荐系统性能,又能提供一定的可解释性。
三、评价指标
:均方根误差,是均方误差的算术平方根。均方误差是指参数估计值与参数真值之差平方的期望值。<br />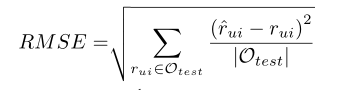<br /> :平均绝对误差。平均绝对误差能更好地反映预测值误差的实际情况。<br /><br />其中,,是测试集的评分,是评分数量,是预测的评分,是观察到的评分
四、传统方法
传统的跨域推荐算法也是利用来自多个辅助域的显式或隐式反馈来提高目标域中的推荐性能。诸如评论文本和基本描述之类的辅助信息可能有助于为用户和物品生成更好的潜在特征,从而改善推荐性能。但是,大多数现有的跨域推荐算法仍未充分考虑各种有价值的辅助信息。尽管最近有几篇著作试图利用一种辅助信息,但它们无法将辅助信息与评分矩阵充分而深入地融合。
五、主要思想
为跨域推荐提出了一种基于评论和内容的深度融合模型,即RC-DFM。具体来说,首先扩展了基本SDAE模型,使其适合跨域推荐中的特征学习场景。然后,将SDAE的几种变体进行集成,以学习辅助域和目标域中更有效的用户和项目的隐因子。在获得两个域中共同用户的隐因子之后,通过映射功能来学习两个域之间的特征映射。基于MLP的非线性映射的性能优于线性映射。因此,我们选择MLP可以更有效地将用户隐因子从辅助域转移到目标域。
模型框架如下图所示。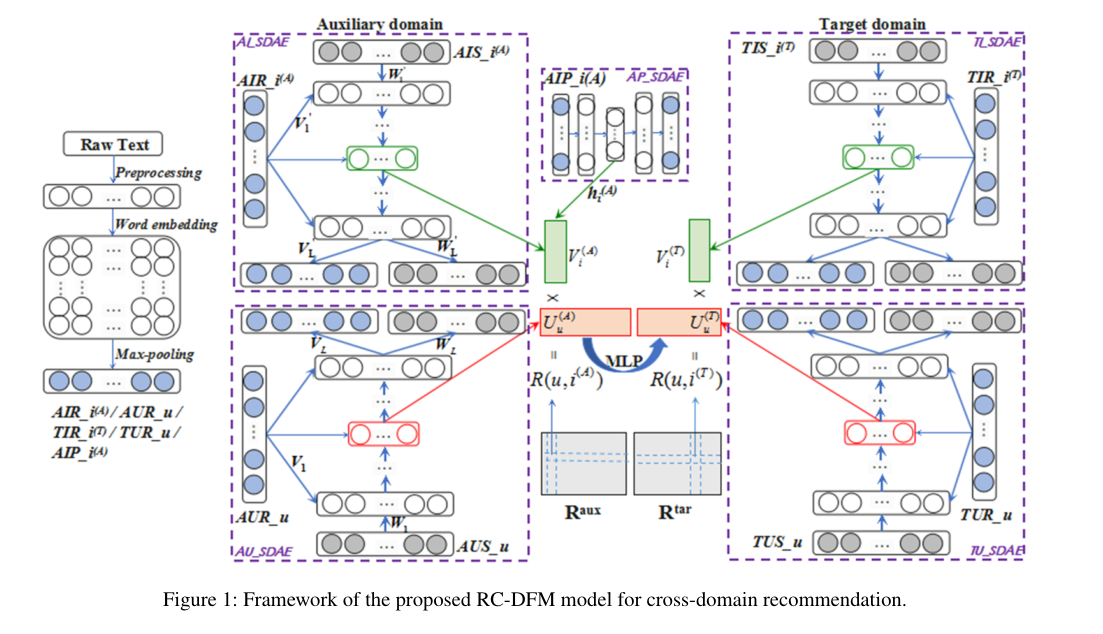
从上图可以看得出来,该模型主要由四个步骤组成:
1、Vectorization of Reviews and Contents
2、Generation of Latent Factors
3、Nonlinear Mapping Based on MLP
4、Cross-Domain Recommendation
六、实验评估
数据集
Amazon dataset:http://jmcauley.ucsd.edu/data/amazon/.
使用亚马逊数据集中的movies、music CDs和books项目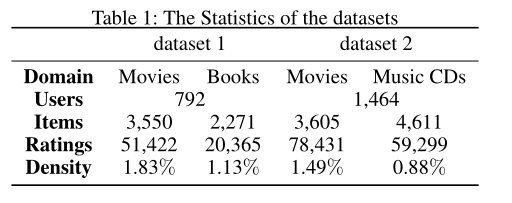
Baseline
- PMF:(Salakhutdinov and Mnih 2007)中引入了概率矩阵分解(PMF),该模型通过高斯分布对用户和项目的隐因子进行建模。
- CMF:集体矩阵分解(CMF)(Singh and Gordon 2008)倾向于通过同时分解多个矩阵来整合不同的信息源。实体的隐因子在辅助域和目标域之间共享。
- EMCDR:在(Man et al。2017)中提出了此模型。它首先采用矩阵分解来学习隐因子,然后利用MLP网络将用户隐因子从辅助域映射到目标域。
- DFM:这是RC-DFM的简化版本,仅考虑评分值,不使用辅助信息。
R-DFM:这也是RC-DFM的简化版本。它以评论文本为辅助信息,而忽略了物品内容。
实验结果
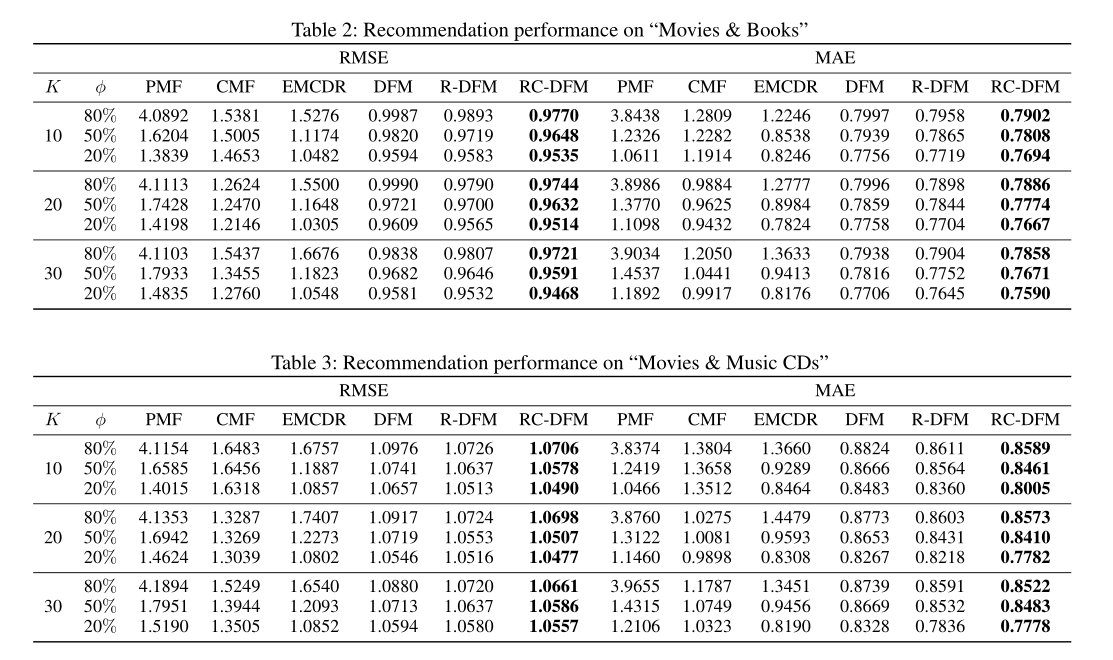
RC-DFM的性能最好。
可以看到,RC-DFM-Full模型的性能最好。从中得知,rating融合了content之后模型会更优秀。七、Related Work
跨域推荐的一些工作基本上都是单域推荐或者只利用了单评分或单边信息,无法有效融合二者:
Zhu(Zhu et al.2018)提出了一个名为DCDCSR的深度框架,用于跨域和跨系统推荐。它考虑了不同域或系统中单个用户和物品的评分稀疏度。
- Ren(Ren et al.2015)提出了一种新颖的概率集群级隐因子(PCLF)模型,以学习跨域共享的通用评分模式,以及捕获用户特定域的评分模式和物品域的聚类。这类工作的性能在很大程度上受到评分矩阵固有的稀疏性的限制。
- Song(Song等人,2017)提出了一个联合张量分解模型,以充分利用从评论中提取的方面因子。
- Fang(Fang等人,2015)提出了一种新颖的方法,可通过传递标签共生矩阵信息来跨多个域利用评分模式,该信息可用于揭示常见的用户模式。
- Li(Li,Kawale和Fu,2015年)提出了一种通用的深层架构,称为DCF,将概率矩阵分解与边缘化降噪堆叠式自动编码器相结合,应用于评分矩阵以及用户和商品的基本描述。
- Wang(Wang,Wang和Y eung,2015年)提出了一种称为CDL的分层贝叶斯模型,以共同执行针对内容信息的深度表示学习和针对评分矩阵的协同过滤。

若有收获,就点个赞吧
0 人点赞
