2019AAAI收录的一篇论文。零样本学习(Zero-Shot Learning,ZSL)和冷启动推荐(Cold-Start Recommendation,CSR)分别是计算机视觉和推荐系统中具有挑战性的研究问题,它们一般在各自的领域中被独立地研究。而实际上这俩是同一个研究问题不同外延,本质上是一样的。它们的目标都是要预测未知类签且都涉及特征表示空间和支持空间。
这篇文章首次提出使用零样本学习方法解决冷启动推荐问题。具体地,作者提出了一种基于低秩线性自编码器的模型,该模型能够同时缓解领域迁移、伪相关和计算效率问题。该模型包括一个将用户行为映射到用户属性的地址编码器和一个从用户属性重构用户行为的解码器。实验证明,该方法可以同时提升零样本学习和冷启动推荐的精度。
一、简要信息
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 论文模型 | LLAE |
| 2 | 所属领域 | 推荐系统 |
| 3 | 研究内容 | Zero-shot learning; cold-start recommendation; Low- rank Linear Auto-Encoder |
| 4 | 核心内容 | 冷启动问题 |
| 5 | 论文PDF | 2019AAAI-From Zero-Shot Learning to Cold-Start Recommendation.pdf |
| 6 | GitHub代码 | https://github.com/lijin118/LLAE |
二、研究背景
目前,学者们通过引入跨领域信息、个人信息或社交网络信息等来缓解推荐系统中的用户冷启动问题。目前缓解冷启动推荐问题的方法的思路是利用用户偏好来为新用户生成推荐结果。此过程涉及两个空间:属性空间和行为空间,其中属性空间包含用户偏好和个人信息,行为空间包含用户购买行为和历史交互,属性空间用于描述用户偏好,行为空间用于描述用户与目标系统的交互。那么冷启动推荐可以定义为:当行为空间中没有用户的交互数据但属性空间中有关于用户的辅助信息时,如何为一个新用户生成推荐。基于“具有相似偏好的用户往往具有相似的消费行为”假设,可以分两步进行冷启动推荐:1)将行为空间映射到属性空间,使得新/老用户产生联系;2)通过用户属性重构用户行为以产生推荐结果。
基于以上分析,我们可以发现,冷启动推荐问题本质上是零样本学习问题,具体地,零样本学习和冷启动推荐都涉及两个空间,一个用于直接特征表示,另一个用于补充描述,且二者的目标都是通过利用可见类和未知类之间共享的描述空间中的信息,预测属性空间中未知类的标签。
ZSL和CSR的一个例图,如下。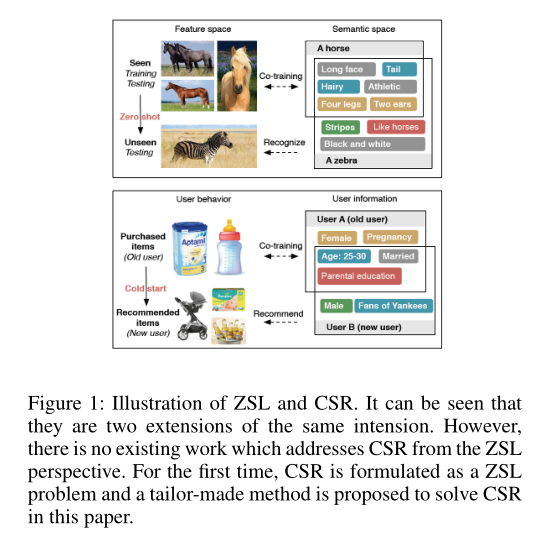
三、评价指标
Accuracy表示预测正确的样本数占总样本书的比例。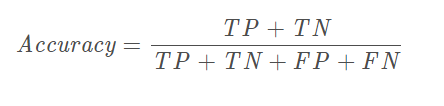
mAP(mean Average Precision):单个主题的平均精度均值是每篇相关文档检索出后的精度的平均值。
四、传统方法
目前缓解冷启动推荐问题的方法的思路是利用用户偏好来为新用户生成推荐结果。此过程涉及两个空间:属性空间和行为空间,其中属性空间包含用户偏好和个人信息,行为空间包含用户购买行为和历史交互,属性空间用于描述用户偏好,行为空间用于描述用户与目标系统的交互。那么冷启动推荐可以定义为:当行为空间中没有用户的交互数据但属性空间中有关于用户的辅助信息时,如何为一个新用户生成推荐。基于“具有相似偏好的用户往往具有相似的消费行为”假设,可以分两步进行冷启动推荐:1)将行为空间映射到属性空间,使得新/老用户产生联系;2)通过用户属性重构用户行为以产生推荐结果。
在常规冷启动解决方法中,基于内容的方法忽视了用户的偏好、基于混合内容的协同过滤方法当交互信息很稀疏的时候效果很不好,而且用户个人信息是隐私不好处理。还有一些推荐系统先选取一些候选商品给用户,然后通过用户的反馈来预估用户的偏好。
五、主要思想
作者提出一个利用零样本学习(ZSL)来解决冷启动(CRS)推荐的模型,名字叫低秩线性自动编码器( Low-
rank Linear Auto-Encoder,LLAE),这个是基于encoder-decoder模式。LLAE是由一个编码器组成,它将用户行为空间映射到了用户属性空间。同时还有一个解码器,这个解码器通过用户的属性空间重构用户行为。重构部分保证可以从用户属性生成用户行为,这样就用户行为与用户属性之间的领域迁移问题就会被缓解。由于效率问题我们把LLAE表示成线性模型。模型计算量与样本数无关,因此它可以用来处理大规模数据集,加快计算效率。此外还部署了一个低秩约束来处理稀疏问题。低秩表示已经被证明从损坏的观测数据中揭示真实数据的问题是有效的。一个行为可能与多个属性相关联,关联的这些属性也有不同的权重,有些属性则非常简单。如果我们把所有属性都考虑进去了,可能会削弱主因素带来的影响,引起过度拟合,降低泛化能力。低秩约束由于其数学上的特性,能够找出主导因素,过滤掉噪点联系,换句话说,就是防止了那些伪关联因素。低秩约束还可以从域适应的角度上来对齐域转移。
六、实验评估
ZSL
数据集
1)aPascal-aYahoo(aP&aY)
2)Animal with Attribute(AwA):http://cvml.ist.ac.at/AwA2/AwA2-data.zip
3)SUN scene attribute dataset (SUN)
4)Caltech-UCSD Birds-200-2011 (CUB)
统计情况如下表: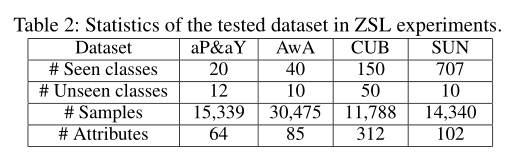
基准
- DAP (Lampert, Nickisch, and Harmeling 2014)
- ESZSL (RomeraParedes and Torr 2015)
- SSE (Zhang and Saligrama 2015)
- JLSE (Zhang and Saligrama 2016)
-
实验结果
CSR
数据集
Flickr:http://yahoolabs.tumblr.com/post/89783581601/one-hundred-million-creative-commons-flickr-images-for
- BlogCatalog
- YouTube:归纳总结Announcing YouTube-8M: A Large and Diverse Labeled Video Dataset for Video Understanding Research
- Hetrec11-LastFM
实验结果
在冷启动推荐任务中的性能如下: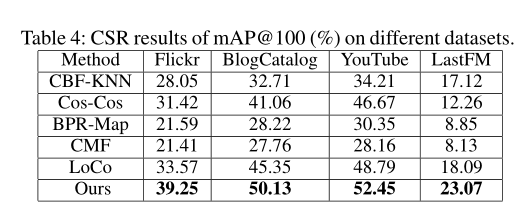
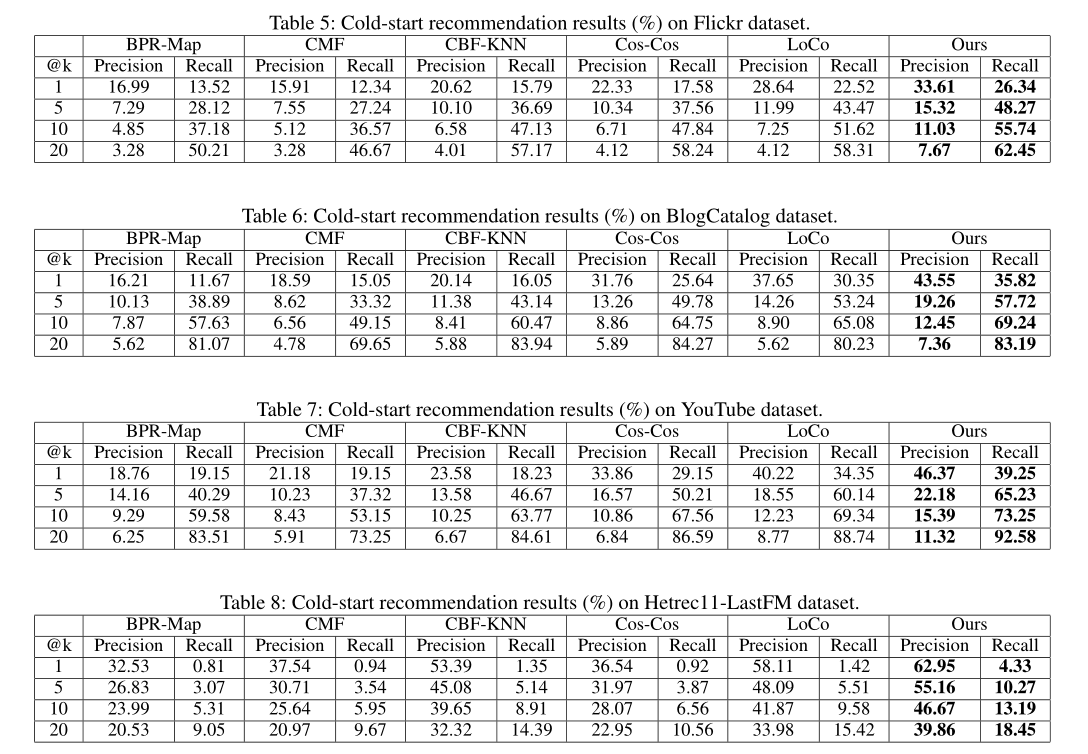
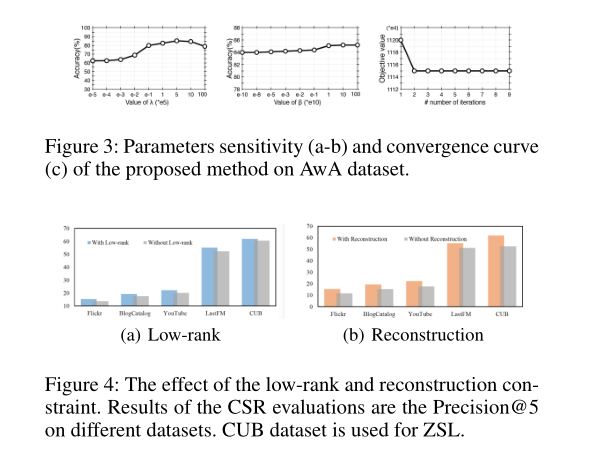
很明显,从以上几个表中可以看得出来,无论是在ZSL还是在CSR问题上,LLAE都表现出比baseline更优秀的性能。而图3显示了模型收敛速度快,图4显示了低秩和重构给模型带来的好处。七、Related Work
Zero-shot learning
传统的视觉识别算法的假设是,测试类的实例要包含在训练集中,所以可以通过训练样本识别其他测试实例。对于大规模数据集,为新对象或者稀有对象收集数据集是非常困难的事情,那么我们是否能像人类一样,用一些语义描述来识别未知物体。因此,零样本学习被提出,通常情况下,零样本学习算法学习了一个将视觉空间映射到语义空间的投影,或者反过来学。基于不同的投影策略提出了不同的模型。总的来说,现在零样本学习被分为三类:
1:学习从视觉空间到语义空间的映射函数。
2:学习从语义空间到视觉空间的映射函数。
3:学习由视觉域与语义域共享的潜在空间。cold-start recommendation
我们关注利用辅助信息解决冷启动推荐问题的研究,辅助信息可以是用户属性、个人信息或用户社交网络数据。这些研究中提出的方法可以大致分为三类:基于相似性的模型、基于矩阵分解的模型和基于特征映射的模型。八、其他
不足及改进
LLAE中的自编码器结构略显简单,发掘特征上可能略显不足,可以采用深度自编码器解决零样本学习和冷启动推荐问题。数学理论及模型结构
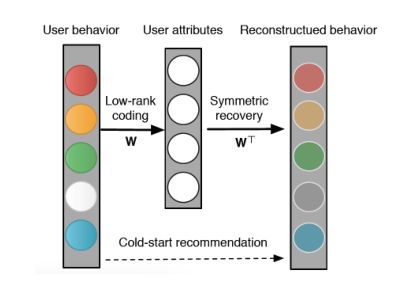
上图是LLAE一个简单说明,首先我们学习一个低秩编码器,我们把用户行为映射到用户属性。然后利用新用户的属性重构用户行为。为了提高效率,编码器与解码器的参数权重是对称的这里就是利用了tied weights算法,注意:编码器可以保证热用户与冷用户在属性空间中能够比较,重构阶段基于用户属性重构用户行为。
上图是一个计算的伪代码。

若有收获,就点个赞吧
0 人点赞
