一、简要信息
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 论文类型 | 综述 |
| 2 | 所属领域 | 推荐系统 |
| 3 | 会议时间 | 2017-ICCCA |
| 4 | 研究内容 | 冷启动 |
| 5 | 核心内容 | 用户冷启动 |
| 6 | 论文PDF | 2017ICCCA-A survey on solving cold start problem in recommender systems.pdf |
| 7 | 思维导图 | 推荐系统冷启动.xmind |
二、摘要
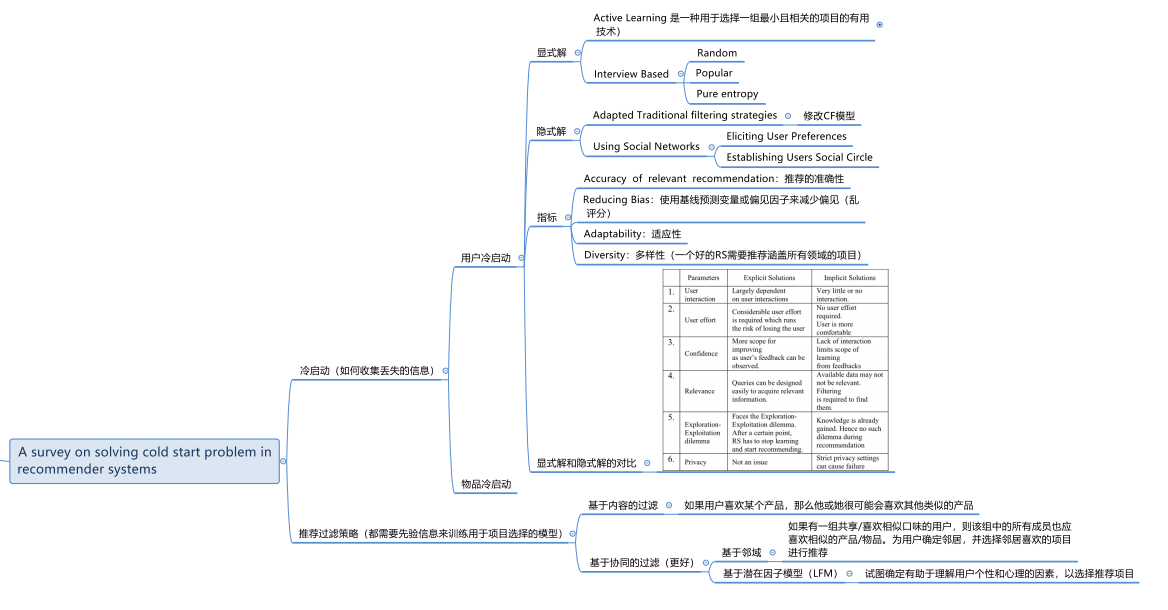
冷启动问题的原因在于推荐系统缺乏足够的相关信息,因此,要解决这个问题就是要收集丢失的信息。在文献中,一些研究人员通过收集丢失的信息解决了这个问题,但是他们的方法在收集丢失的信息方面有所不同。根据有关此问题的文献研究,根据收集缺失信息的性质,解决方案可分为两类:1)显式解决方案;2)隐式解决方案。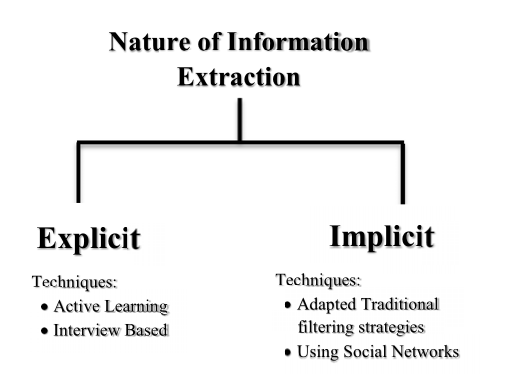
三、Introduction
目前推荐系统(RS)的推荐算法普遍基于过滤策略。有两种广泛使用的过滤策略,即基于内容的过滤(CBF)和基于协同的过滤(CF)。基于内容的过滤策略基于以下假设:如果用户喜欢某个产品,那么他或她很可能会喜欢其他类似的产品。协同过滤使用两种不同的方法,即基于邻域的方法和基于隐因子模型(LFM)的方法。基于邻域的方法认为,如果有一组共享/喜欢相似口味的用户,则该组中的所有成员也应喜欢相似的产品/物品。在这种方法中,为用户确定邻居,并选择邻居喜欢的项目进行推荐。基于LFM的方法试图确定有助于理解用户个性和心理的因素,以选择推荐项目。两种过滤策略都需要先验信息来训练用于项目选择的模型。先验信息通常是评分矩阵的形式,其中包含不同用户对各种项目给出的评分。在性能和易用性方面,协同过滤表现出比基于内容的过滤更好的效果。很少有混合过滤策略将基于内容的策略和协同策略结合在一起,并试图充分发挥这两种策略的优势。当在RS的存储库中添加新项目或新用户与RS进行交互时,RS在提供推荐时会遇到问题;这个问题在RS中称为冷启动问题。RS中有两种不同形式的冷启动问题:(1)新用户冷启动问题(2)新项目冷启动问题。在新用户冷启动问题中,新用户被引入到系统中,并且RS由于没有关于用户的信息而在提供推荐方面面临问题。在新物品的冷启动问题中,系统没有新物品的评分,并且在确定该物品的目标用户方面面临困难。在这两种冷启动问题中,新用户的冷启动问题更加困难,并且已得到广泛研究。文章提供了针对解决RS中新用户冷启动问题的不同解决方案的调查。
四、主要部分
首先,无论如何收集丢失的信息,解决方案都应该具备一下几点:
1)相关推荐的准确性:解决方案需要保持整体准确性。
2)减少偏差:优化乱打分的问题。有偏见的评分妨碍了推荐的个性化。解决方案使用基线预测变量或偏见因子来减少偏见,但是它们需要使用评分历史记录才能准确地对其建模。对于冷启动问题,应该存在合适的方法以从一开始就捕获乱评分的值。
3)适应性:适应性强的解决方案能减少了其与系统兼容所需的工作。
4)多样性:一个好的RS需要推荐涵盖所有领域的项目。为此,它必须学习用户在多个域中的兴趣。
显式解决方案
认识某人的最好方法之一就是询问他们。显式解决方案通过直接与用户交互以收集丢失的信息来实现此想法。在这种方法中,要求用户填写一些问卷或对某些给定项目进行评分。当系统明确收集信息时,它可以控制要求的内容,从而获取更多相关信息。但是,这种方法的挑战之一是,由于所需的时间和精力,用户通常不愿意参与查询过程。选择数量最少但信息量最丰富的问题/项目是解决此问题的一种方法。使用可视化和/或提供激励是其他选择。
显式解决方案主要有两种:1)Active Learning(AL);2)interview based strategies。
A. Active Learning
要求用户对某些项目进行评分是明确获取信息的一种方法。但是,与其选择随机项目,不如选择相关项目,这有助于提高系统对用户偏好的了解。同时,重要的是所选项目的数量应少,以免使用户不知所措。主动学习(AL)是一种用于选择一组最小且最相关的项目的有用技术。预先选择系统训练数据时,其行为就像一个“被动”实体。与此相反,在主动学习中,系统通过选择信息性训练数据(输入)并在学习过程中对其进行适应,来“主动”参与学习过程[11]。 AL技术使用不同的试探法来选择项目,这些试探法试图优化系统的某些方面,例如提高准确性,减少不确定性等[25]。
这里简单介绍一下Active Learning。
真实的数据分析场景中,可以获取海量的数据,但是这些数据都是未标注数据,很多经典的分类算法并不能直接使用。此时人工标注数据标代价是很大的,即便我们只标注几千或者几万训练数据,标注数据的时间和金钱成本也是巨大的。主动学习(active learning),指的是这样一种学习方法:
有的时候,有类标的数据比较稀少而没有类标的数据是相当丰富的,但是对数据进行人工标注又非常昂贵,这时候,学习算法可以主动地提出一些标注请求,将一些经过筛选的数据提交给专家进行标注。这个筛选过程也就是主动学习主要研究的地方了。主动学习的“主动”,指的是主动提出标注请求,也就是说,还是需要一个外在的能够对其请求进行标注的实体(通常就是相关领域人员),即主动学习是交互进行的。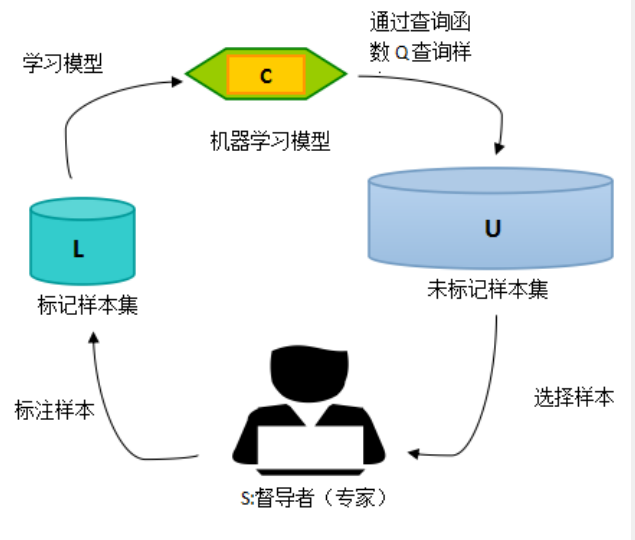
引自https://blog.csdn.net/qq_15111861/article/details/85264109
现有的AL技术是非个性化的或个性化的。非个性化的AL技术仅准备一个项目列表,并向所有用户提供相同的列表以进行评分启发。大多数传统的AL技术都是非个性化的。相反,个性化主动学习策略为不同用户提供了单独的项目列表,以增强个性化。该列表根据用户反馈进行调整。
非个性化技术易于实现,并且通用性强。而在个性化策略中,根据反馈调整项目。这样可以确保个性化,并有助于提高用户对系统的信心。
会话RS以交错方式与用户交互以提供推荐。用户端和系统端都支持交互。 X. Zhao, W. Zhang, and J. Wang, “Interactive Recommender Systems”, in Proc.of CIKM ’13, ACM, San Francisco, USA, 2013, pp. 1411-1420 的作者提出了一种基于“探索-开发”的解决方案,用于对话式RS中的冷启动问题。该解决方案完成了学习用户资料并同时提供相关推荐的任务。
B. Interview Based Approaches
在基于interview的方法中,向用户提供一组项目中的一个项目,并征求他们的意见。通常,可以有三个响应:喜欢,不喜欢或不确定。准备种子项目的初始列表和粗略的用户配置文件,并在整个interview中进行完善。以前,解决方案使用静态采访方式,其中项目列表是固定的。这些解决方案缺乏个性化和吸引力。这导致了自适应采访过程的发展,其中种子项列表是根据用户的响应进行调整的。大多数新的解决方案都使用决策树对自适应采访进行建模。
一个好的interview需要简洁明了。为此,有必要选择数量最少但信息量最丰富的的项目。有多种选择项目的策略,每种策略在两个方面之间都有不同的权衡——信息的准确性和用户的努力。主流三种策略是Popularity,Random和Pure Entropy策略。还可以使用两个或多个策略的组合,例如Popularity Entropy和Log Popularity Entropy等。基于interview的方法是会话式RS的最佳策略,其中用户和系统在整个过程中都进行交互。AL策略并不适合用在interview策略中,这是因为AL启发式尝试优化的预定标准不足以选择在线interview中的问题。
隐式解决方案
A. Adapting Traditional Filtering Strategies
该策略其实就是改进传统的CF模型,使其能够收集丢失的信息。比如后续的Dropoutnet。
B. Using Social Networks
使用相关的社交信息作为side information,解决跨域推荐的一种手段。两种方法:1)使用某些技术手段收集用户的社交信息,例如爬虫。但是需要合法合理。2)建立用户的社交圈。
显式解和隐式解的比较
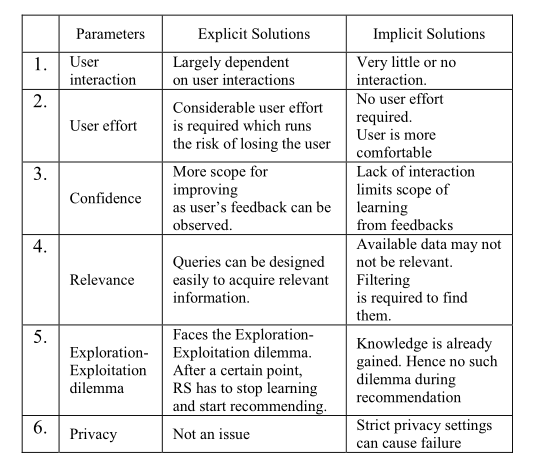
几个指标:
User Interaction:系统与用户的交互来获取用户的preferences
User Effort:指的是用户必须做多少工作才能帮助系统了解他/她的偏好。
Confidence:意味着系统可以通过在推荐过程中从用户的反馈中学习来改善自身
Relevance:它指的是可以获得多少信息数据。
Exploration-Exploitation dilemma:它指示系统如何在推荐允许其了解更多(探索)有关用户的项目或使用户保持兴趣(充分利用)的项目之间进行选择。
Privacy:系统受用户隐私设置限制的程度。
显示解和隐式解各有利弊,两种技术的混合使用是个有趣的问题。
思维导图

若有收获,就点个赞吧
0 人点赞
