2019KDD收录的一篇论文,作者提出了一种新的推荐系统模型,解决了基于少量样本物品来估计user preference的冷启动问题。
一、简要信息
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 论文模型 | MeLU |
| 2 | 所属领域 | 推荐系统 |
| 3 | 研究内容 | Recommender systems; Cold-start problem; User preference esti- mation; Meta-learning |
| 4 | 核心内容 | 冷启问题 |
| 5 | 论文PDF | 2019KDD-MeLU Meta-Learned User Preference Estimator for Cold-Start Recommendation.pdf |
| 6 | GitHub源码 | https://github.com/hoyeoplee/MeLU |
二、研究动机
为了确定用户在冷启动状态下的preference,现有的推荐系统,如Netflix,最初向用户提供一些候选商品,然后根据用户选择的物品进行推荐。以前的推荐研究有两个局限性:1)用户只有非常少量的物品交互数据不足以进行很好的推荐;2)候选物品不充分,不足以较好地反应用户的preference。为了克服这两个限制,我们提出了一种基于元学习的推荐系统MeLU。MeLU可以通过少量几个样本快速适应新任务,通过几个消费商品来估计新用户的偏好。此外,作者提供了一个候选商品选择策略,该策略可确定用于个性化偏好估计的区别项。
三、评价指标
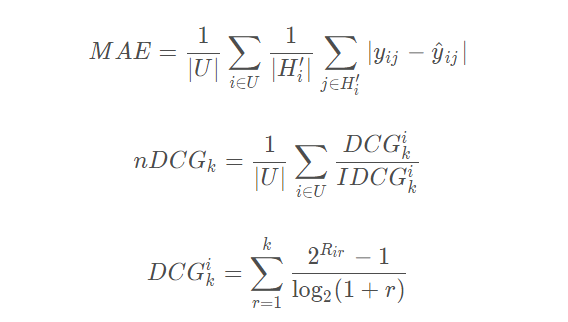
其中 表示第
表示第  个用户所有的
个用户所有的 得分中的最高分,
得分中的最高分, 则表示模型的为用户预测的第
则表示模型的为用户预测的第 个排序的物品的值(一个rate值),
个排序的物品的值(一个rate值), 表示所有的用户集合。
表示所有的用户集合。 ,平均绝对误差(Mean Absolute Error),观测值与真实值的误差绝对值的平均值。
,平均绝对误差(Mean Absolute Error),观测值与真实值的误差绝对值的平均值。 ,归一化折损累计增益。
,归一化折损累计增益。
四、传统方法
在常规冷启动解决方法中,基于内容的方法忽视了用户的偏好、基于混合内容的协同过滤方法当交互信息很稀疏的时候效果很不好,而且用户个人信息是隐私不好处理。还有一些推荐系统先选取一些候选商品给用户,然后通过用户的反馈来预估用户的偏好。
推荐系统通常可分为基于协同过滤,基于内容或混合系统。基于协同过滤的系统通过从众多用户那里收集偏好信息来估计用户行为(response)。预测基于具有与目标用户相似的评分的其他用户的现有评分。但是,由于缺少user-item之间的交互,因此此类系统无法处理新用户(用户冷启动)和新商品(商品冷启动)。引入了基于内容的系统来解决冷启动问题。这样的系统使用用户档案信息(例如,性别,国籍,宗教和政治立场)和商品内容进行推荐。该系统可能有一个限制,即向内容相似的用户建议相同的项目,而与用户已评分的项目无关。基于协同过滤并利用内容信息的混合系统已广泛用于各种应用程序中。但是,当user-item之间交互数据稀疏时,这些系统不适合推荐。此外,由于隐私问题,收集个人信息具有挑战性,这可能会导致用户冷启动问题。
为了避免用户冷启动中出现的隐私问题,许多基于Web的系统(例如Netflix)仅基于最少的用户信息来推荐项目。 Netflix最初向新用户展示流行的电影和电视节目:我们称这些视频为候选商品。 然后,用户从候选者中选择他/她喜欢的视频。 之后,系统会根据用户选择的视频推荐一些程序。 最近,为了提高性能,已经使用深度学习方法提进行推荐。 但是,对于仅对几项评分的新用户来说,冷启动问题仍然存在。
以往的推荐系统受到两个重要问题的限制。首先,系统应该能够向获得一些评分的新用户推荐商品。新用户可能在收到推荐系统最初推荐几个较差的商品后便离开系统。但是,现有系统不仅仅是对少量评分的用户设计的。先前的系统利用用户配置文件信息来改善性能不佳的情况,但是并不能解决局限性。举个例子:两个二十多岁的失业男性用户。一个人看了几部科幻电影,而另一个人看了几部恐怖电影。当提供性别,年龄和职业作为用户信息时,推荐系统可能会向两个男人展示非常相似的电影列表,因为一些电影无法弄清区分他们的偏好。其次,现有系统无法提供可靠的候选商品来估计用户的偏好:它们将受欢迎的商品显示为候选商品。因此不必过多花时间来选择候选商品,因为随着user-item间互动的增加,推荐系统自然会变得健壮。但是,我们必须刻意选择合适的候选商品,以改善对新用户的冷启动问题。
五、主要思想
对于新用户而言,初始的一个较好推荐能够更好地留住用户,MeLU的意图正在于此。
本文提出了一种基于元学习的推荐系统MeLU。元学习侧重于通过仅使用少量训练数据进行学习来改善分类或回归性能。推荐器系统具有与元学习类似的特征,因为它着重于仅基于少量样本来预测用户的偏好。我们考虑与模型无关的元学习(MAML)算法,该算法可以直接基于单个用户的物品消费历史来估计消费者的偏好,即使仅消耗了少量物品也是如此。与基于协同过滤的系统不同(后者是其他用户具有与目标用户相似的评分),MeLU系统仅考虑目标用户物品消费历史。此外,我们建议MeLU使用evidence candidate selection strategy,通过选择区分项以进行自定义的偏好估计,可以显着提高新用户的初始推荐性能。
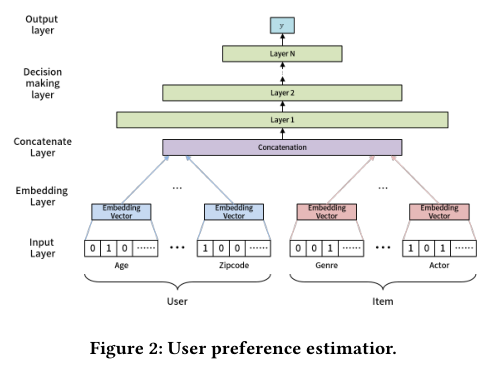
- 输入层(input layer):对于离散变量,使用embedding法映射到连续空间,此处包含的embedding参数;对于连续的变量则跳过embedding层直接与其他向量进行拼接;
- 嵌入层:根据离散的特征,通过嵌入层嵌入到连续的向量空间中;
- 拼接层:将多个特征向量直接拼接起来;
- 决策层:由于用户和物品的向量维度不完全一致,所以无法使用矩阵分解,而使用多层神经网络;
- 输出层:则表示优化的目标,可以是点击率,隐式反馈、停留时长等;
为了很好的描述,我们将输入层和嵌入层作为一个整体,其对应的训练参数用  表示,决策层和输出层作为一个整体,其对应的训练参数用
表示,决策层和输出层作为一个整体,其对应的训练参数用  表示。因此,整个冷启动时的训练如下图以及对应的算法所示:
表示。因此,整个冷启动时的训练如下图以及对应的算法所示: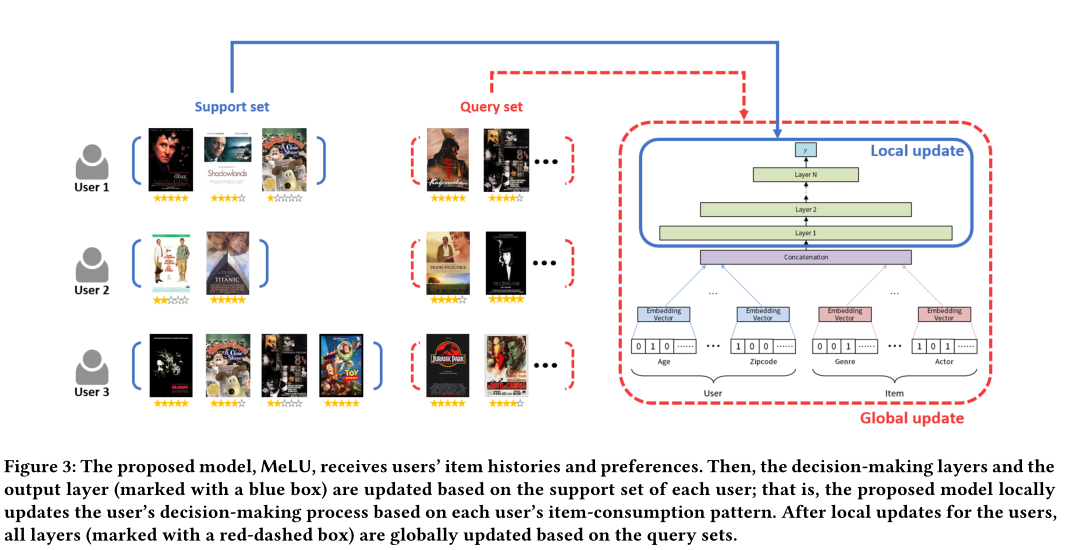

首先初始化两个参数 输入层和嵌入层参数) 和(决策层和输出层参数),然后接下来进行多轮(Epoch)迭代训练。每一轮训练过程中,挑选一定数量的用户,对每个用户(相当于MAML中的Task)进行采样得到支持集,获得少量的交互数据后,计算在支持集上得到的训练loss,并计算对应的梯度实现局部更新。每个用户的局部更新均是在的基础上进行的,如下图的灰色箭头( )。每个用户进行局部更新的目的是,模拟让模型对新的用户进行学习的过程。在全局更新阶段则是对所有用户再次采样得到的查询集上进行的,每个用户的查询集上均可以得到测试loss,并平均后计算梯度,如下图的
)。每个用户进行局部更新的目的是,模拟让模型对新的用户进行学习的过程。在全局更新阶段则是对所有用户再次采样得到的查询集上进行的,每个用户的查询集上均可以得到测试loss,并平均后计算梯度,如下图的  。
。
在测试阶段(或实际应用阶段),当新来一个用户,以及只有少量的交互数据的前提下,只需要进行一次采样得到支持集,进行少量的局部更新后(本文实验证明只需要一次局部更新),即可得到一个适用与该用户的模型,并可以在查询集上得到较好的效果。
六、实验评估
使用的数据集是MovieLens和Bookcrossing两个。统计信息如图所示:

针对四种推荐场景,可以得到相关的结果,其中PPR和Wide&Deep分别是一种基于用户和物品特征的冷启动推荐方法和基于记忆和泛化的推荐模型,MeLU-1和MeLU-5则分别表示局部更新的次数分别是1次和5次。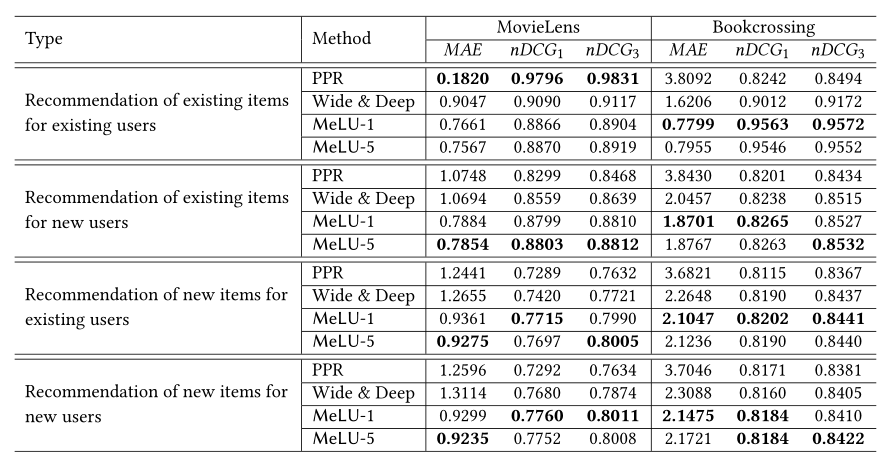
可以发现,当“已有物品推荐给已有用户”的场景时,在MovieLens数据集上PPR的方法的最低,但PPR在另外三种冷启动场景下却非常高,说明PPR方法并不能有效的缓解冷启动问题。另外本文提出的方法在冷启动场景下均达到最好效果,且局部更新的次数越多,提升越大。
下图则表示局部更新的次数与的关系,可知,不论在哪一个数据集上,MeLU均可以在第一次局部更新后就达到一定的效果,因此无需多次更新。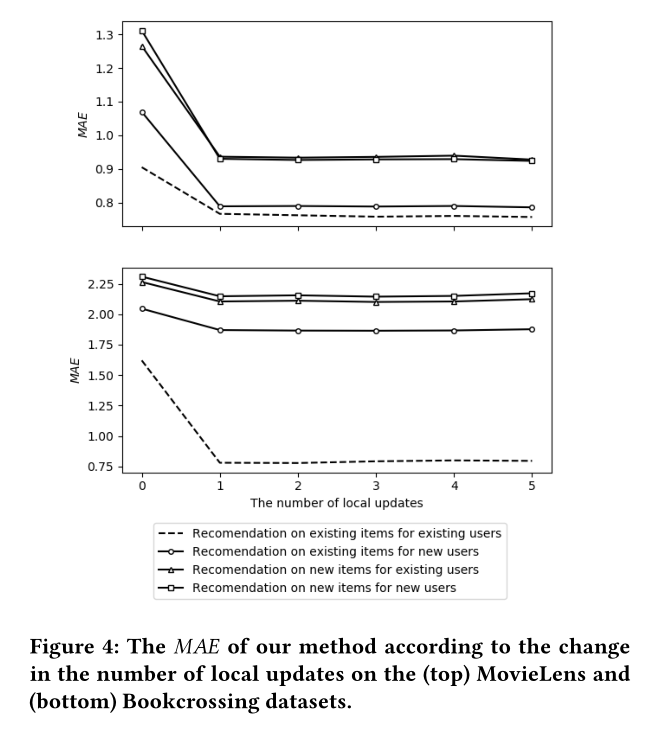
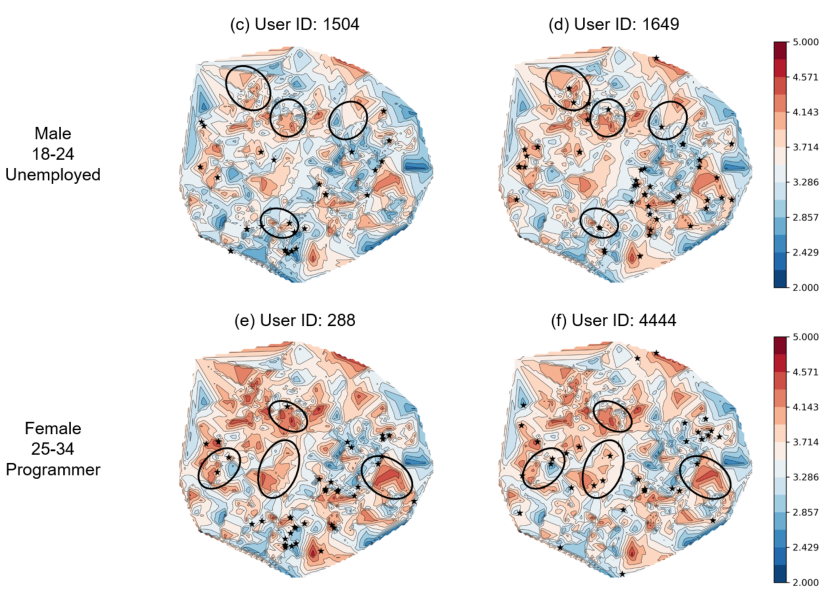
作者还进行了一些额外的实验来验证本文提出的模型可以有效避免基于用户和物品特征冷启动下“相似用户被推荐相似的物品”的问题。如下图,当两个用户有相似的特征时,MeLU依然可以识别出他们不同的偏好,并进行个性化的推荐。图中红色表示用户偏好的物品,蓝色表示不偏好的物品,黑色五角星表示evidence candidate,黑色圆圈则用于展示两个不同用户之间的差异: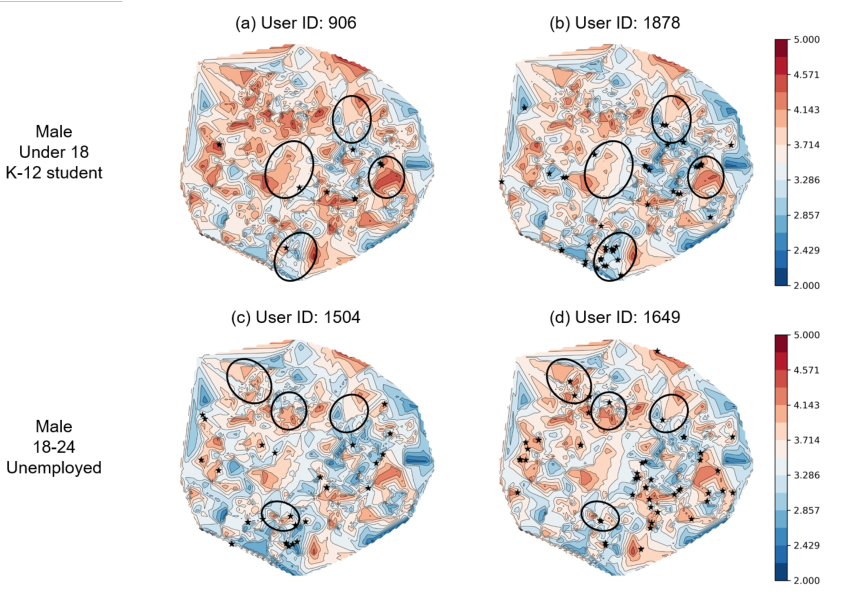
作者还制作了Demo,在MoiveLens数据集上进行了A/B测试。其中第一个page用于用户提交个人信息,第二个页面则用于获取evidence candidate,一共有20部电影,第三个page则基于第二个page获得的交互数据进行推荐(也有20部电影)。如下图。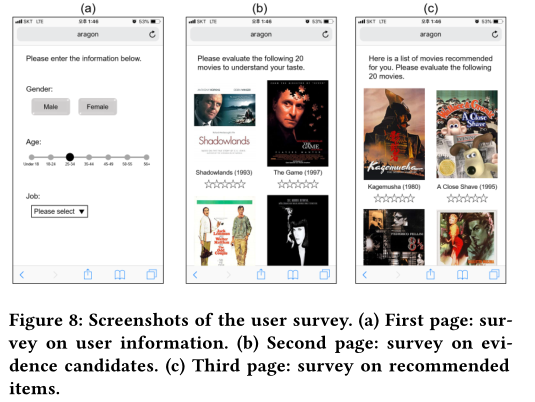
发现,如果基于popularity-based方法得到的候选物品,虽然在最初,用户会选择很多物品,但这些物品可能只是由于热门的因素而被选择,但在实际推荐过程中,并非是用户感兴趣的;而使用本文提出的方法,则可以在很少的交互数据中估计用户的偏好,从而进行个性化的推荐,在推荐过程中,MeLU给出的推荐列表被选中率则高于popularity-based的方法,如下表所示: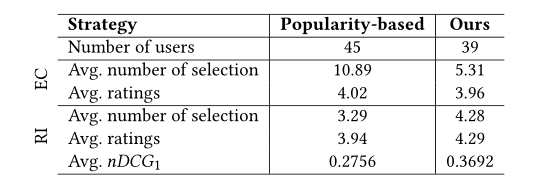
其中EC表示evidence candidate被选择的平均数量,RI表示recommended item被选择的平均数量。
七、Related Work
- PPR通过将用户独热编码和商品内容向量的双线性回归来估计用户偏好。
Wide&Deep可以预测用户是否喜欢某件商品,但我们将其修改为用于估计偏好的回归模型。 Wide&Deep的结构与我们的用户偏好估计模型的结构相同。
八、其他
候选商品选择策略
它可以应用在任何现有的隐语义模型之上,以提供/增强其冷启动能力。实际上不需要修改原始模型,从而最大程度地减少了已经在运行隐语义模型的生产环境的实施障碍。
本文提出基于MeLU的候选商品选择策略。该策略可快速分析系统中新用户的个人偏好的区别项。在本文的模型中,整个用户的个性化渐变的平均Frobenius范数越大,用户偏好之间的区别就越好。在计算梯度时,我们修改|·|表示要反向传播单位误差的输入的绝对值。尽管梯度较大的商品可用于识别用户的偏好,但是当用户不了解商品时,进行适当的评估可能会很困难。因此,我们还考虑了用户对商品的了解。我们假设用户与商品的交互越频繁,用户就越了解该商品。因此,对于每个项目,我们分别使用现有的全量user-item pairs来计算基于梯度的值和基于流行度的值,作为平均Frobenius范数和每个商品的交互次数。为了缩放两个值的单位,我们将值归一化为从零到一的范围,然后通过将两个归一化的值相乘,将得分分配给每个项目。最后,我们将得分最高的前k个项目定义为商品候选者。请注意,分数在进入新用户时会有所不同,这直接影响平均Frobenius范数和user-item交互。不足及改进
不足:
需要计算模型的二阶导数,计算量大,计算需要的内存大,为引入新的模块/设定新的应用场景造成了很大的阻碍。
- 当用一组任务训练元学习器时,它很难拟合出任务的分布,因此,模型从meta-train task向meta-test task generalize时,测试任务必须与训练任务比较相似才能实现generalize,当meta-test task是从完全不同的分布中获得时,模型的表现就更差了。
改进:
- 必须在实际应用之前验证模型更新周期。 尽管元学习擅长学习新事物,但是当新用户出现在推荐系统中时,可能无法保证性能。
- 未来的研究应探索选择商品候选策略的变体。 在计算候选证据的评分时,将不同策略的评分加权求和可能会得出更好的结果。
- 应研究基于元学习的推荐系统的变体。 例如,可以设计基于元学习的协作过滤推荐系统。
数学理论和工具
元学习(meta-learning):元学习旨在训练一个模型可以快速地从一个新的,包含少量样本(训练阶段从未见过的)的数据集上进行学习。
元学习分为三种:基于度量(Metric-based)方法、基于记忆(memory-based)方法和基于优化(optimization-based)的方法;

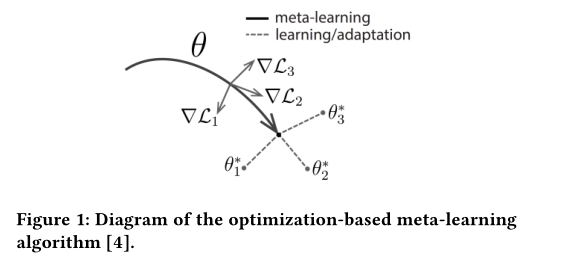
给定一个待优化的模型f和分布数据,给定多个Task,每个Task负责从该数据上进行采样。
基于优化的方法:
(1)局部更新:对于每个Task,从分布数据集中进行采样,并进行局部更新(local-update),每个Task均可以得到对应的训练loss;
(2)全局更新:对于所有的采样Task,每个Task再次采样得到测试集,并在测试集上根据测试loss进行对参数进行更新。
基于优化的元学习主要包含两个集合,分别是支持集(support set)和查询集(query set),两个集合分别用于计算训练loss和测试loss。在局部更新时,主要在支持集(训练过程)上进行参数优化;在全局更新时,在查询集上最小化损失。整个训练的细节可以详情下图:
参考自:元学习,更多详情细节请跳转。
数据集
MovieLens:我们从IMDb1收集了其他电影内容。 我们将电影分为1997年之前和1998年之后发行的电影(大约8:2)。 我们将1997年之前发行的电影视为现有项目,并将1998年之后发行的电影视为新项目,我们随机选择了80%的用户作为现有用户,其余用户则作为新用户。
Bookcrossing:我们将这些书籍分为1997年之前发行的书籍和1998年之后发行的书籍(大约5:5)。 我们将1997年之前发行的图书视为现有项目,将1998年之后发行的图书视为新项目,我们随机选择了一半的用户作为现有用户,其余的作为新用户。

若有收获,就点个赞吧
0 人点赞
