隐语义模型(Latent models)由于其面对大数据时的灵活性能,经常成为构建推荐系统的默认选择。最近的研究又主要集中在对用户-项目交互进行建模,且很少有隐语义模型关注冷启动问题。而深度学习对各种各样的输入数据都有良好的性能,作者提出一个叫做DropoutNet的神经网络隐语义模型通过Dropout和模型优化来解决冷启动问题。
一、简要信息
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 论文模型 | Dropoutnet |
| 2 | 所属领域 | 推荐系统 |
| 3 | 研究内容 | Latent model; recommender system; cold start; DropoutNet |
| 4 | 核心内容 | 用户冷启动 |
| 5 | 论文PDF | 2017NIPS-dropoutnet-addressing-cold-start-in-recommender-systems-Paper.pdf |
| 6 | GitHub源码 | https://github.com/layer6ai-labs/DropoutNet |
二、研究动机
隐语义模型由于其性能和可伸缩性已成为推荐系统的默认选择。但是,该领域的研究主要集中在对user-item交互进行建模,并且很少开发用于冷启动的隐语义模型。而深度学习对各种各样的输入数据都有良好的性能,作者提出一个叫做DropoutNet的神经网络隐语义模型通过Dropout和优化来解决冷启动问题。
三、评价指标
在热启动上拥有了以往Hybrid model的性能,还解决了冷启动问题;不需要引入额外的客观条件增加模型的复杂度,只有一个目标函数,易于实现和优化;可以使模型从冷启动无缝过渡到偏好设置,而无需重新训练并且具有出色的概括性;测试不同条件下的recall@100。
四、传统方法
隐语义模型在解决这类问题的唯一途径是结合额外的内容信息,基础的隐语义模型不能结合内容,所以催生了一大批混合模型。但是大多数混合模型引入了额外的客观条件, 大大复杂化了学习和推理。况且,目标的内容通常是生成性的,这迫使模型“解释”内容,而不是最大化推荐准确性。
五、主要思想
利用content + preference信息,不需要引入额外的内容信息和额外的目标函数,作者在训练DNN的过程中,在mini-batch输入上应用Dropout,DNN模型最终拟合出被Dropout的部分,这就等价于冷启动问题中在用户-项目交互数据中的缺失数据被补回来了。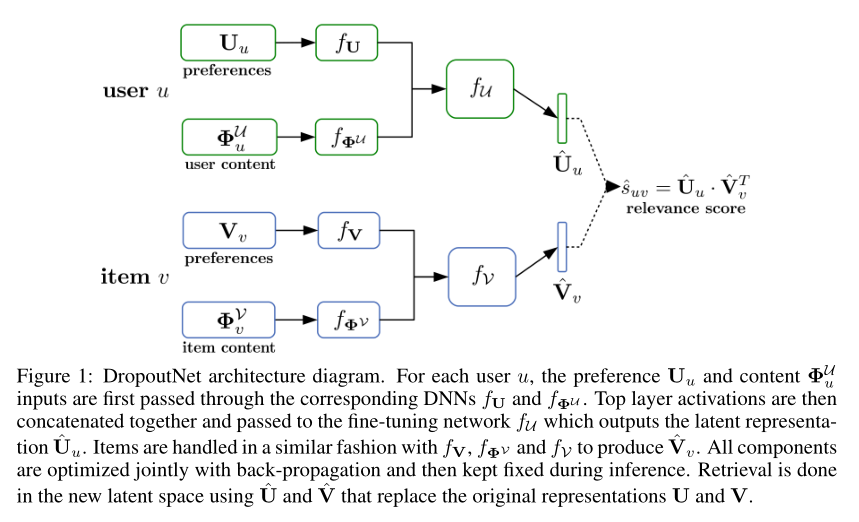
在经典的协同过滤问题中,我们用集合 ,表示
,表示 个用户,
个用户, 表示
表示 个项目。于是可以得到一个交互矩阵
个项目。于是可以得到一个交互矩阵 的交互矩阵,
的交互矩阵, 代表用户
代表用户 对项目
对项目 的喜好。既可以是例如评分,喜欢/不喜欢等显性反馈,也可以是例如浏览,播放或购买等隐性反馈。在线性反馈中经典的
的喜好。既可以是例如评分,喜欢/不喜欢等显性反馈,也可以是例如浏览,播放或购买等隐性反馈。在线性反馈中经典的 包含级联关系(比如1-5分),在隐性反馈中通常只有两个值。作者在工作中将两种情况都考虑到了。当没有可利用的信息的时候
包含级联关系(比如1-5分),在隐性反馈中通常只有两个值。作者在工作中将两种情况都考虑到了。当没有可利用的信息的时候 。
。
作者使用  表示对项目感兴趣的用户集合,
表示对项目感兴趣的用户集合, 表示用户感兴趣的项目集合。当
表示用户感兴趣的项目集合。当 或者
或者 就表示或者遇到了冷启动。
就表示或者遇到了冷启动。
对于user来说,content可以是user的个人资料,如性别、年龄、设备、个人评价等等,也可以是其社交网络的信息,对于item,content可以是一个商品的基本信息,如产地、类型、品牌、评论等等,也可以是相关的图像、视频和声音等资料。这些数据能为推荐模型提供许多有用的信息,特别是对数据稀疏和冷启动的情况。经过相关转换之后这些内容信息大多数能被转变成固定长度的特征向量。作者使用 和
和 表达用户和项目的内容特征。那么这篇文章的目标就是用和内容
表达用户和项目的内容特征。那么这篇文章的目标就是用和内容 、
、 来学习出一个尽可能精确和鲁棒性的推荐模型。理想情况下模型能够处理用户/项目在系统中的所有阶段:从冷启动、到早期的稀疏数据再到后面的数据定义齐全的阶段。
来学习出一个尽可能精确和鲁棒性的推荐模型。理想情况下模型能够处理用户/项目在系统中的所有阶段:从冷启动、到早期的稀疏数据再到后面的数据定义齐全的阶段。
模拟冷启动:
按照一定的抽样比例,让user或者item的preference向量为0,即  或者
或者  为 0。所以,针对冷启动,其目标函数为:
为 0。所以,针对冷启动,其目标函数为:
这个时候,由于preference向量的缺失,所以content会竭尽所能去担起大任,从而可以逼近Latent Model的效果:preference不够,content来凑。
在训练的时候,我们选择的 和 都是有比较丰富的preference信息的向量,在实际推荐中,如果preference信息比较丰富,那么我们只利用这些信息就可以得到很好的推荐效果。在冷启动时利用content信息,是希望能够达到有preference信息时候的性能。所以,当我们有充足的preference信息的时候,训练出的模型给予content内容的权重会趋于0,这样就回归了传统的Latent Model了。
设置dropout的时候,鼓励模型去使用content信息;不设置dropout的时候,模型会尽量使用preference信息。另外,本身Dropout作为一种正则化手段,也可以防止模型过拟合。
Transform:只有少数perference的情况:
文章还提出了在冷启动后,用户或者项目开始产生少数的preference信息的时候应该怎么处理,这样才能让不同阶段无缝衔接。它既不是冷启动,但是可用的preference信息也十分稀少。而更新一次latent model是比较费时的,不能说来一些preference信息就更新一次,再来推荐。所以本文给出了一种简单的方法,用user交互过的那少数几个item的向量的平均,来代表这个user的向量。这个过程为transformation。所以,用户有一些交互之后,先这样transform一下拿去用,后台慢慢地更新latent model,等更新好了,再换成latent model来进行推荐。
六、实验评估
1、在两个公开可用的数据集上进行实验:CiteULike和ACM RecSys 2017挑战数据集;2、测试了冷启动和热启动在不同的dropoutrate、算法、神经网络层数和交互下的recall@100.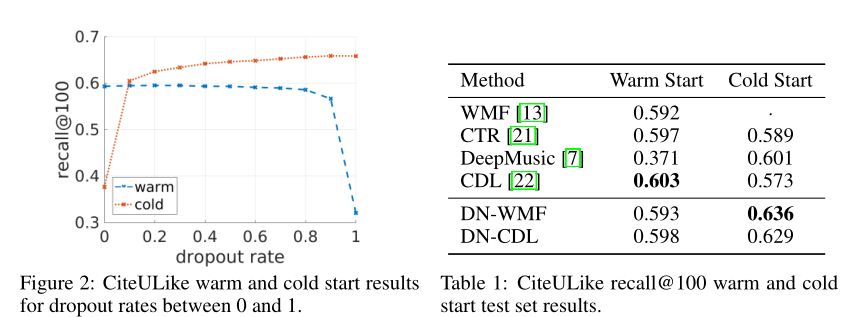
CiteULike的实验结果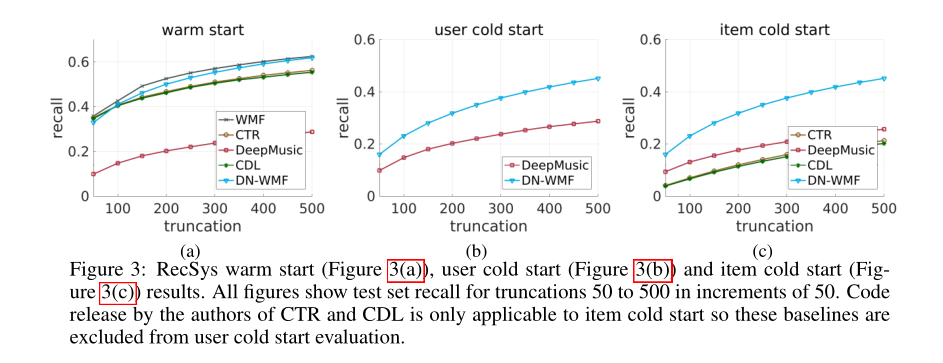
ACM RecSys 2017挑战数据集的实验结果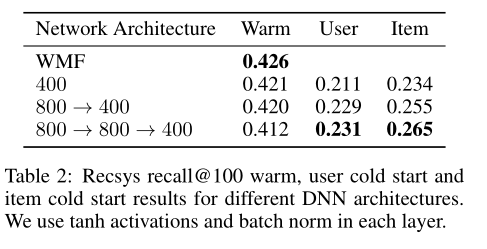
DNN层数寻优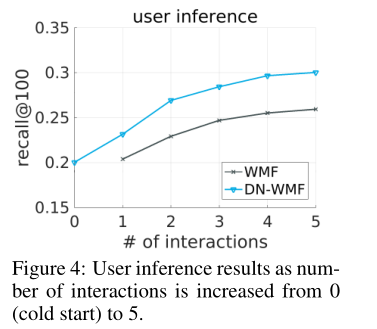
阶段无缝衔接实验结果
七、Related Work
在协同过滤中已经有许多混合隐因子模型被提出用来解决冷启动:
- CTR(Collaborative Topic Regression):结合Latent Dirichlet Allocation (LDA) and Weighted Matrix Factorization (WMF)
- Collaborative Topic Poisson Factorization (CTPF):与CTR类似的插值结构,但是用泊松分布代替了LDA和WMF分量。
- Collaborative Deep Learning (CDL):另一个类似的结构,其中LDA被替换为多层降噪自动编码机(Stacked denoising autoencoders)
除了CDL,DNN结合CF:
- DeepMusic音乐推荐:仅仅用DNN提取音乐内容特征再进行协同推荐。
- YouTube视频推荐:第一部分从上千万上亿个视频中选择少数(几百,几千)个候选视频,然后通过第二部分ranking来对这些候选视频进行详细打分,得分最高的视频作为最终结果呈现给用户。
- Recurrent recommender networks:将item按照时序顺序应用到RNN上,最后隐藏层激活用于潜在表达。
八、其他
其他优点
它可以应用在任何现有的隐语义模型之上,以提供/增强其冷启动能力。实际上不需要修改原始模型,从而最大程度地减少了已经在运行隐语义模型的生产环境的实施障碍。不足之处
1、该方法利用较为简单的方法对用户行为进行表征,但是缺乏对时间因素的考虑与信息充分性和信息最小性的权衡,同时由于模型简单,所以在大数据规模下,模型不易挖掘到更多的信息。
2、模型较为简单,在大数据规模下,模型不易挖掘到更多的信息,并且有过拟合的风险。
3、用户行为集合使得模型对于商品之间的互信息利用不充分,并且时间特征并没有突出对待,使得用户周期性兴趣不易挖掘;过多引入具体任务的特征,不满足表征模型的信息最小性,使得模型不利于表征用户跨域行为,模型的迁移性也较差。数学理论和工具
隐语义模型(LFM):一种基于矩阵分解的用来预测用户对物品兴趣度的推荐算法。
相比USerCF算法(基于类似用户进行推荐)和ItemCF(基于类似物品进行推荐)算法;我们还可以直接对物品和用户的兴趣分类。对应某个用户先得到他的兴趣分类,确定他喜欢哪一类的物品,再在这个类里挑选他可能喜欢的物品。
微调网络、矩阵分解、正则化、梯度下降、Dropout、隐变量、协同过滤、低秩。数据集
CiteULike和ACM RecSys 2017挑战数据集(只有参赛选手才有,目前下载不到)

若有收获,就点个赞吧
0 人点赞
