完成本文步骤有以下要求:
- 拥有一个阿里云账号,并且已经在 Flink 全托管产品页面 购买了产品;
- 要求有能执行 docker 命令的本地环境,用于准备 Python 依赖,安装 Docker 可以参考 Docker 官方文档;
- 本文介绍的方案仅支持 PyAlink 1.5.3 及更新的版本。
注意:实时计算 Flink 全托管产品可能在使用过程中向您收取费用!
一、编写脚本并保存
将下面的代码复制,然后保存为本地文件 pyalink_on_vvp.py,之后用于在 VVP 上执行。
import loggingimport osimport numpy as npimport pandas as pdos.environ['ALINK_DEPS_DIR'] = '/flink/usrlib/xxx/' # just set to something, not really usedos.environ['ALINK_PLUGINS_DIR'] = '/flink/usrlib/xxx/' # just set to something, not really used for nowfrom pyalink.alink import *getMLEnv()data = np.array([[1.1, True, "2", "A"],[1.1, False, "2", "B"],[1.1, True, "1", "B"],[2.2, True, "1", "A"]])df = pd.DataFrame({"double": data[:, 0], "bool": data[:, 1], "number": data[:, 2], "str": data[:, 3]})source = BatchOperator.fromDataframe(df, schemaStr='double double, bool boolean, number int, str string')p = "oss://[oss bucket]/path/to/output.csv"sink = CsvSinkBatchOp() \.setFilePath(FilePath(p, FlinkFileSystem(p))) \.setOverwriteSink(True) \.linkFrom(source)BatchOperator.execute()
这段代码简单地从 pandas.DataFrame 创建一个 source,然后写到 OSS 的 csv 文件。代码第 23 行的 “[oss bucket]”需要替换为 VVP 所绑定的 OSS bucket。后面紧跟这的路径可以根据需要填写。
其中,需要特别注意与一般的 PyAlink 脚本不同的地方:
- 代码中使用
getMLEnv(),而不是useLocalEnv或者useRemoteEnv:这样能通过 PyFlink 来执行 PyAlink 的代码。 - 代码中不能出现
print、collectoToDataFrame等语句:因为 VVP 上执行脚本采用的是 DETACHED 模式,不能使用这些方法。 - 代码中 source 和 sink 需要使用
FlinkFileSystem,从 vvp 直接绑定的 OSS bucket 读写数据:其他形式的数据 source 或者 sink 暂时不支持,以后根据适配情况进行调整。 - 代码中额外设置了两个环境变量:
ALINK_DEPS_DIR和ALINK_PLUGINS_DIR:因为 VVP 上安装 whl 包的方式跟一般机器不同,需要设置这两个环境变量避免一些报错,以后可能会根据适配情况进行调整。
二、准备各类资源文件
由于 PyAlink 是以第三方库的形式在 VVP 上运行,因此需要额外添加 PyAlink 包以及 jar 包。官方文档 中介绍了如何添加这些依赖。
准备PyAlink 包
- 在浏览器打开 PyPI 页面,在搜索框中输入
pyalink,单机搜索按钮; - 在搜索结果中,点击想要使用的 pyalink 版本,建议直接使用 Flink-1.13 对应的
pyalink包; - 在左侧导航栏,单击 Download files,然后单击文件名结尾为 whl 的文件下载;
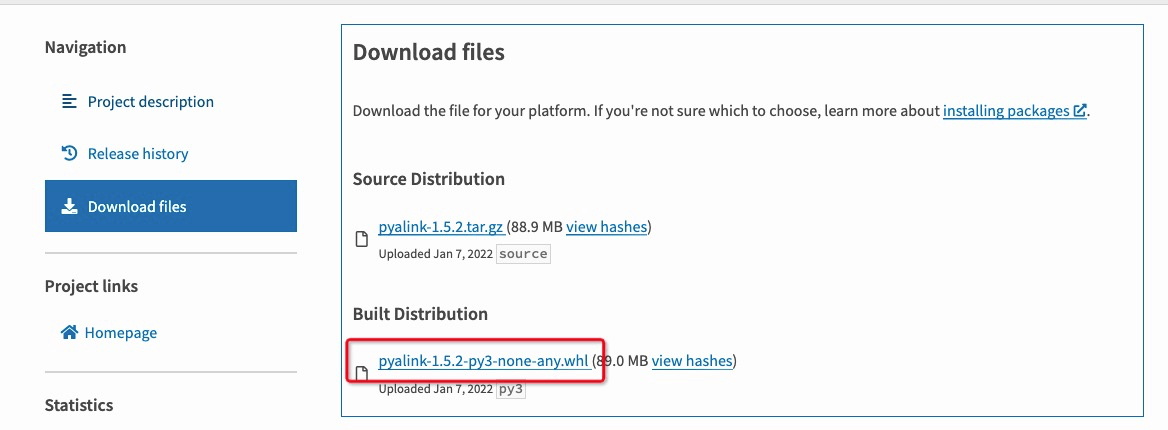
上述步骤完成后,在本机上会有一个 pyalink-1.x.x-py3-non-any.whl 的文件。
准备 PyAlink 包的依赖
这里的步骤参考 官方文档,但略有改变,请注意。
- 在本地新建一个空目录;
复制下面的代码,保存到目录中,文件名为
requirements.txt;pandas>=1.0,<1.2.0jupyterscipyRxtqdmdeprecationpackaging
复制下面的代码,保存到目录中,文件名为
build.sh; ```shell!/bin/bash
set -e -x yum install -y zip
PYBIN=/opt/python/cp37-cp37m/bin
“${PYBIN}/pip” install —target pypackages -r requirements.txt cd pypackages && zip -r deps.zip . && mv deps.zip ../ && cd .. rm -rf pypackages
4. 在终端中执行以下语句:```shelldocker run -it --rm -v $PWD:/build -w /build quay.io/pypa/manylinux2014_x86_64 /bin/bash build.sh
- 语句执行完成后,在目录中能得到一个
deps.zip的文件。
准备 Alink jar 包
在终端中输入下面的命令,解压前文步骤“准备PyAlink 包”中下载的 whl 包;
mkdir jarscd jarstar xvf /path/to/pyalink-1.x.x-py3-none-any.whl
在解压后的文件中,找到
pyalink/lib下的两个 jar 包备用。
三、上传资源文件
- 在 VVP 左边栏点击“资源上传”按钮;
- 将上文中所有准备的文件都拖入页面中间;
- 等待上传完毕。
所有文件上传完之后的效果如下: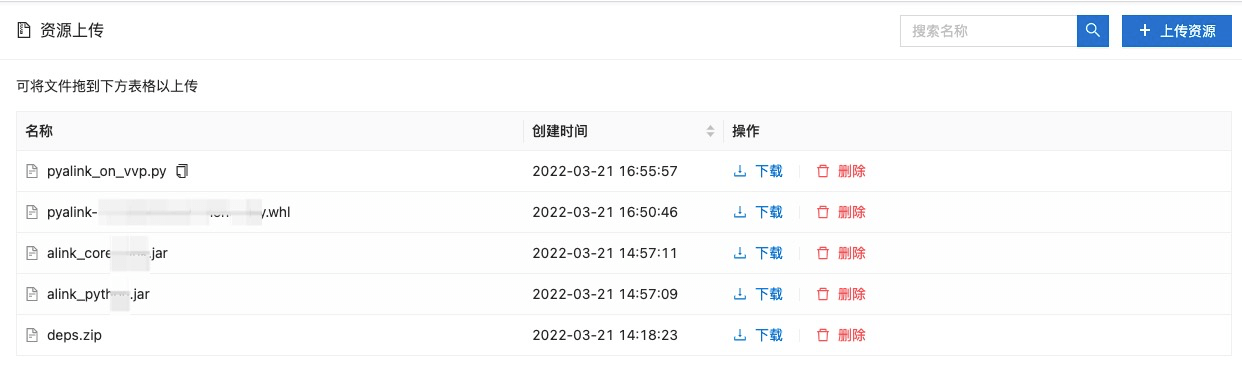
四、创建并配置作业
- 在 VVP 左边栏点击“作业开发”按钮;
- 点击页面中上方的“新建”按钮,在弹出的对话框中输入任意的文件名称,“文件类型”选择“流作业/PYTHON”,点击确认。
- 创建成功后,页面中间显示该作业的配置页面。
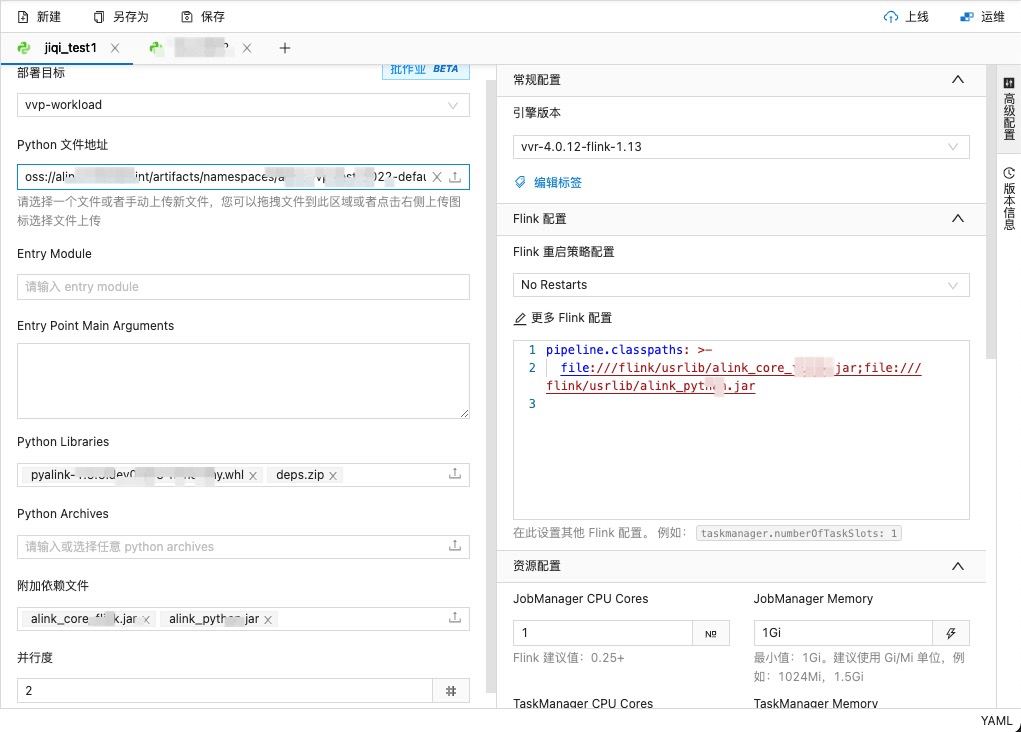
- “Python 文件地址” 选择结尾为 “pyalink_on_vvp.py”的一项;“Python Libraries” 选择“pyalink-1.x.x-py3-none-any.whl”和 “deps.zip”两项;“附加依赖文件”选择 “alink_core_xxxx.jar” 和 “alink_python_xxx.jar”两项;并行度设为 2。(这里的 xxx 会根据用的版本有所不同。)
点击页面右侧的“高级配置”,在“更多 Flink 配置中” 粘贴下面的配置,文件名根据情况对应地修改:
pipeline.classpaths: >-file:///flink/usrlib/alink_core_flink_xxx.jar;file:///flink/usrlib/alink_python_xxx.jar
五、上线并启动作业
点击页面右上角的“上线”按钮,在弹出的对话框点击“确认”;
- 点击页面右上角的“运维”按钮,跳转到运维界面;
- 点击页面右上角的“启动”按钮,启动作业;
- 等待几分钟之后,作业应该正常结束,此时可以从代码中设置的 oss 路径上查看到写出的文件。
运行成功后的页面显示大致如下: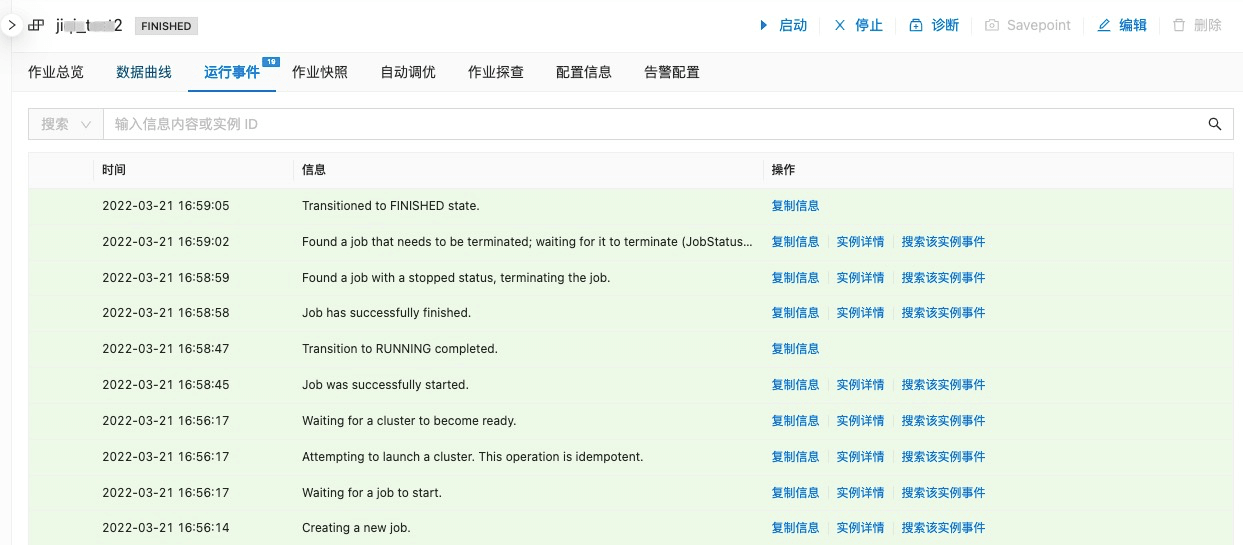
注意事项
- 当前 Alink plugin 功能在全托管 Flink 产品上的支持还不完整,导致部分功能还不可用,请关注最新进展。
- 全托管 Flink 产品使用的是 DETACHED 模型运行作业,所以不支持 print/collect/collectToDataFrame 等操作。

若有收获,就点个赞吧
0 人点赞
