在2.5节中介绍Alink在批式任务中定义了Lazy方式,本小节将通过示例演示一些常用使用方式。另外,在后面的2.6节重点介绍了使用Lazy方法显示模型信息;在模型评估阶段也常使用Lazy的方法,具体内容参见分类、回归、聚类等的评估章节。
选择演示的数据集为iris数据集,可以从HTTP链接直接读取。相关代码如下:
source = CsvSourceBatchOp()\.setFilePath("http://archive.ics.uci.edu/ml/machine-learning-databases"+ "/iris/iris.data")\.setSchemaStr("sepal_length double, sepal_width double, petal_length double, "+ "petal_width double, category string")
批式组件间的输出
下面例子是对原始数据使用SelectBatchOp组件进行操作,在组件操作前后可以使用多种方式进行数据和统计结果的输出,帮助我们了解组件操作的效果。完整代码如下:
source\.lazyPrint()\.lazyPrint(title=">>> print with title.")\.lazyPrint(2)\.lazyPrint(2, ">>> print 2 rows with title.")\.lazyPrintStatistics()\.lazyPrintStatistics(">>> summary of current data.")\.lazyCollectToDataframe(lambda df : print("number of rows : " + str(len(df))))\.lazyCollectStatistics(lambda tableSummary :print("number of valid values :"+ str(tableSummary.numValidValue("sepal_length"))+ "\nnumber of missing values :"+ str(tableSummary.numMissingValue("sepal_length"))))\.link(SelectBatchOp()\.setClause("sepal_length, sepal_width, sepal_length/sepal_width AS ratio"))\.lazyPrint(title=">>> final data")\.lazyPrintStatistics(">>> summary of final data.")BatchOperator.execute()
可以看到,lazy系列组件在链式调用过程中,其输出数据与输入数据是一样的,所以可以随时嵌入链式调用过程,或者从链式调用中移除,但不会影响最终的结果,这就给我们调试程序,诊断问题,探索数据等带来了便利。下面将每个lazy操作对应到数据结果,对比了解各个功能。
lazyPrint
lazyPrint方法可以不输入参数,如下所示,当数据过多时,会只打印输出首尾的数据行。
lazyPrint()
输出结果为: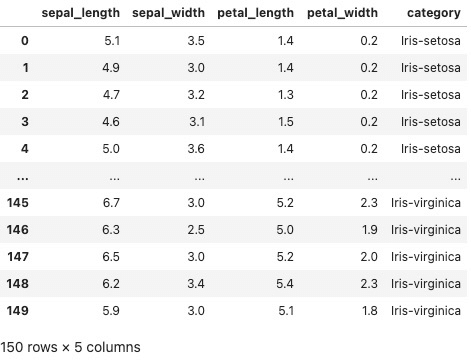
lazyPrint方法可以支持字符串类型参数作为打印内容的标题,如下所示:
lazyPrint(title=">>> print with title.")
输出结果如下,注意最上一行为设置的标题。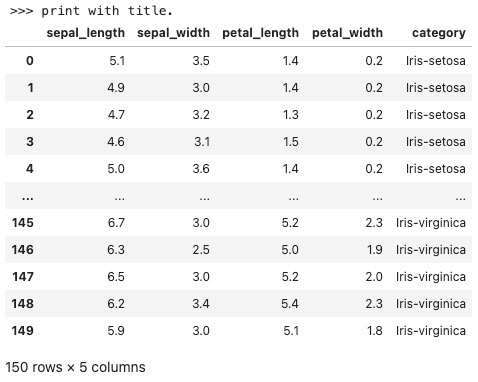
lazyPrint方法可以指定要输出的数据行数,下面代码为输出2行数据,注意参数“-1”表示输出全部数据。
lazyPrint(2)
输出结果如下,2行数据。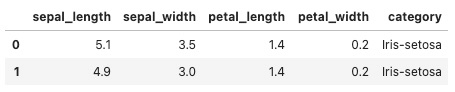
lazyPrint方法也可以同时指定输出行数和标题,如下所示
lazyPrint(2, ">>> print 2 rows with title.")
输出结果为: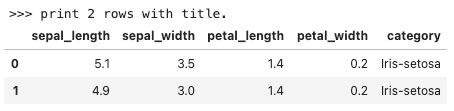
上面的输出操作都在SelectBatchOp组件之前,在该组件后面再接一个输出,代码如下
lazyPrint(title=">>> final data")
运行结果如下,可以看到数据列数发生了变换,保留了sepal_length和sepal_width列,增加了ratio列。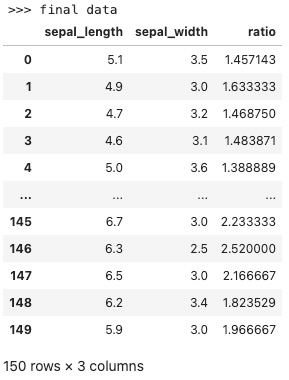
lazyPrintStatistics
lazyPrintStatistics方法可以将数据的基本统计结果打印输出。代码如下所示:
lazyPrintStatistics()
输出结果为:
Summary:| colName|count|missing| sum| mean|variance|min|max||------------|-----|-------|-----|------|--------|---|---||sepal_length| 150| 0|876.5|5.8433| 0.6857|4.3|7.9|| sepal_width| 150| 0|458.1| 3.054| 0.188| 2|4.4||petal_length| 150| 0|563.8|3.7587| 3.1132| 1|6.9|| petal_width| 150| 0|179.8|1.1987| 0.5824|0.1|2.5|| category| 150| 0| NaN| NaN| NaN|NaN|NaN|
lazyPrintStatistics也可以指定标题内容,代码如下:
lazyPrintStatistics(">>> summary of current data.")
输出结果为:
>>> summary of current data.Summary:| colName|count|missing| sum| mean|variance|min|max||------------|-----|-------|-----|------|--------|---|---||sepal_length| 150| 0|876.5|5.8433| 0.6857|4.3|7.9|| sepal_width| 150| 0|458.1| 3.054| 0.188| 2|4.4||petal_length| 150| 0|563.8|3.7587| 3.1132| 1|6.9|| petal_width| 150| 0|179.8|1.1987| 0.5824|0.1|2.5|| category| 150| 0| NaN| NaN| NaN|NaN|NaN|
在在SelectBatchOp组件之后再接一个输出统计结果,代码如下
lazyPrintStatistics(">>> summary of final data.")
运行结果如下,可以看到当前数据的统计结果,保留了sepal_length和sepal_width列,增加了ratio列。对比SelectBatchOp组件前后的统计结果,有助于理解和验证操作的影响。
>>> summary of final data.Summary:| colName|count|missing| sum| mean|variance| min| max||------------|-----|-------|--------|------|--------|------|------||sepal_length| 150| 0| 876.5|5.8433| 0.6857| 4.3| 7.9|| sepal_width| 150| 0| 458.1| 3.054| 0.188| 2| 4.4|| ratio| 150| 0|293.2717|1.9551| 0.159|1.2683|2.9615|
lazyCollect
lazyCollectToDataframe方法可以获取当前的数据,用户能自定义更多的操作,下面代码演示了获取数据总行数并打印输出。
lazyCollectToDataframe(lambda df : print("number of rows : " + str(len(df))))
运行结果为:
number of rows : 150
lazyCollectStatistics方法提供了对统计结果TableSummary的自定义操作,下面代码演示了从统计信息中获取sepal_length列数据中,有效数据的行数及空值的行数。
.lazyCollectStatistics(lambda tableSummary :print("number of valid values :"+ str(tableSummary.numValidValue("sepal_length"))+ "\nnumber of missing values :"+ str(tableSummary.numMissingValue("sepal_length"))))\
输出结果为:
number of valid values :150number of missing values :0
Pipeline中的输出
在Pipeline中也可以输出中间的数据,统计信息和模型信息,便于我们了解Pipeline执行的过程。
还是以iris数据集为例,Pipeline中有两个操作:首先是使用Select组件,选取两列sepal_length和sepal_width,并将这两列的比值作为一个新的数据列,列名为ratio;然后使用StandardScaler组件,对sepal_length和sepal_width列执行标准化操作。具体代码如下:
Pipeline()\.add(Select()\.setClause("sepal_length, sepal_width, sepal_length/sepal_width AS ratio")\.enableLazyPrintTransformData(5, ">>> output data after Select")\.enableLazyPrintTransformStat(">>> summary of data after Select "))\.add(StandardScaler()\.setSelectedCols(["sepal_length", "sepal_width"])\.enableLazyPrintModelInfo(">>> model info")\.enableLazyPrintTransformData(5, ">>> output data after StandardScaler")\.enableLazyPrintTransformStat(">>> summary of data after StandardScaler")\)\.fit(source)\.transform(source)\.lazyPrint(title=">>> output data after the whole pipeline")BatchOperator.execute()
enableLazyPrintTransformData
Pipeline Select阶段的运行结果,可以使用下面方法输出
enableLazyPrintTransformData(5, ">>> output data after Select")
输出内容为: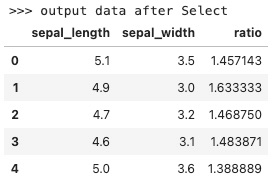
Pipeline StandardScaler阶段的运行结果,可以使用下面方法输出
enableLazyPrintTransformData(5, ">>> output data after StandardScaler")
运行结果如下,可以看到左边两列经过标准化操作后的变化。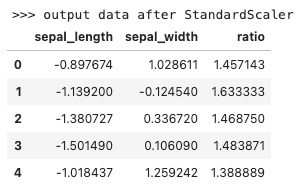
enableLazyPrintTransformStat
使用下面的方法输出Pipeline Select阶段的统计结果,
enableLazyPrintTransformStat(">>> summary of data after Select ")
运行结果为:
>>> summary of data after SelectSummary:| colName|count|missing| sum| mean|variance| min| max||------------|-----|-------|--------|------|--------|------|------||sepal_length| 150| 0| 876.5|5.8433| 0.6857| 4.3| 7.9|| sepal_width| 150| 0| 458.1| 3.054| 0.188| 2| 4.4|| ratio| 150| 0|293.2717|1.9551| 0.159|1.2683|2.9615|
使用下面的方法输出Pipeline StandardScaler阶段的统计结果,
enableLazyPrintTransformStat(">>> summary of data after StandardScaler")
输出统计结果如下,注意:经过标准化操作,sepal_length和sepal_width两列的均值都为0,方差都为1.
>>> summary of data after StandardScalerSummary:| colName|count|missing| sum| mean|variance| min| max||------------|-----|-------|--------|------|--------|-------|------||sepal_length| 150| 0| -0| -0| 1|-1.8638|2.4837|| sepal_width| 150| 0| -0| -0| 1|-2.4308|3.1043|| ratio| 150| 0|293.2717|1.9551| 0.159| 1.2683|2.9615|
enableLazyPrintModelInfo
还可以使用Lazy方法打印输出模型信息,Pipeline StandardScaler阶段的模型打印输出代码如下:
enableLazyPrintModelInfo(">>> model info")
运行结果如下,模型中包含了各列的均值和标准差信息。
>>> model info------------------------- StandardScalerModelInfo -------------------------============================ means information ============================[5.8433, 3.054]===================== standard deviation information =====================[0.8281, 0.4336]

若有收获,就点个赞吧
0 人点赞
