- spring常用注解,springmvc常用注解,springboot常用注解,项目中用到了哪些?
- bean与component的区别
- mybatis里面嵌套查询和嵌套结果有什么区别
- mybatis里面的#号和$符号的区别
- 是预编译的方式,可以防止sql注入
$是直接拼接;如果分表是通过日期来创建的,可以使用$来拼接表名- 现在有个字符串,统计这个字符串每个字符出现的次数
- servlet的生命周期是什么
- string和stringbuffer和stringbuilder的区别
- 有一张表,主键自增,数据很多,要查询最后一条数据怎么找
- mysql的分页怎么写 传的参数分别代表的是什么
- 前期mysql数据量在100左右使用分页查询,后期数据量在10万左右后,使用分页查询效率低下怎么优化
- jdk1.8的新特性
- http与https的区别
- tcp与udp的区别
- http的常见的状态码
- springmvc的执行流程,前端发送的请求是什么时候映射到对象里面去的
- mybatis的执行器
- mybatis动态sql怎么写
- mybatis里面的插入标签是如何与接口的方法绑定的
- 线程有哪些状态
- 线程的常用方法:
- 创建自定义注解怎么创建
- 线程的实现方式有哪几种?说说项目中是怎么使用的
- TreeSet是怎么去重的
- TreeSet的两种排序方式
- arrlist里面的实现了random access接口有什么作用
- spring是怎么创建对象的
- spring创建对象的作用域
- spring怎么解决循环依赖问题的
- mysql的隔离级别 哪些会产生脏读,哪些会参数幻读
- sql的执行顺序
spring常用注解,springmvc常用注解,springboot常用注解,项目中用到了哪些?
spring常用注解
- @Component 组件,没有明确的角色
- @Service 在业务逻辑层使用(service层)
- @Repository 在数据访问层使用(dao层)
- @Autowired:由Spring提供
Spring MVC的常用注解
1 @Controller 表明这个类是Spring MVC里的Controller,将其声明为Spring的一个Bean,
2 @RequestMapping 是用来映射Web请求(访问路径和参数)、处理类和方法的
3 @RequestBody:注解实现接收http请求的jaon数据,将json数据转换为java对象
4 @ResponseBody:注解实现将controller方法返回对象转化为json响应给客户。SpingBoot的核心注解是哪个?它主要由哪个注解组成?
核心注解是启动类上面的注解@SpringBootApplication,它包含三个注解:
(1)@SpringBootConfiguration:组合了Configuration注解,实现配置文件的功能。
(2)@EnableAutoConfiguration:打开了自动配置的功能,也可以关闭某个自动配 置的选项,如:关闭数据源自动配置功能。
(3)@ComponetScan:Spring组件扫描bean与component的区别
- @Component注解表明一个类会作为组件类,并告知Spring要为这个类创建bean。
- @Bean注解告诉Spring这个方法将会返回一个对象,这个对象要注册为Spring应用上下文中的bean。通常方法体中包含了最终产生bean实例的逻辑。
mybatis里面嵌套查询和嵌套结果有什么区别
mybatis的嵌套查询:是通过select标签中的id属性绑定对应的接口方法名,resultMap属性绑定嵌套查询的结果,写上要查询的sql语句
mybatis的嵌套结果是指返回的结果是一个对象里面包含另一个对象,mybaits需要先通过resultMap标签声明外面的对象属性,里面的对象属性通过association标签声明里面的标签。
<!--嵌套结果 只查一次--><resultMap id="ordersResultMap" type="Orders"><id property="id" column="id"/><result property="user_id" column="user_id"/><result property="number" column="number"/><result property="createtime" column="createtime"/><result property="note" column="note"/><!--<association property="user" javaType="User">--><!--<id property="id" column="user_id"/>--><!--<result property="username" column="username"/>--><!--<result property="address" column="address"/>--><!--</association>--><!--嵌套查询 查2次--><association property="user" select="mapper.UserMapper.mySelectByPrimary2" column="user_id"></association></resultMap><select id="selectByPrimary2" resultMap="ordersResultMap">select o.*, u.username, u.addressfrom orders o,user uwhere o.user_id = u.idand o.id = #{id}</select>
mybatis里面的#号和$符号的区别
是预编译的方式,可以防止sql注入
$是直接拼接;如果分表是通过日期来创建的,可以使用$来拼接表名
现在有个字符串,统计这个字符串每个字符出现的次数
string常用的方法
length()//返回该字符串的长度
charAt(int index)//返回字符串中指定位置的字符;
substring(int beginIndex)//该方法从beginIndex位置起,从当前字符串中取出剩余的字符作为一个新的字符串返回。
equals(Object anotherObject)//比较当前字符串和参数字符串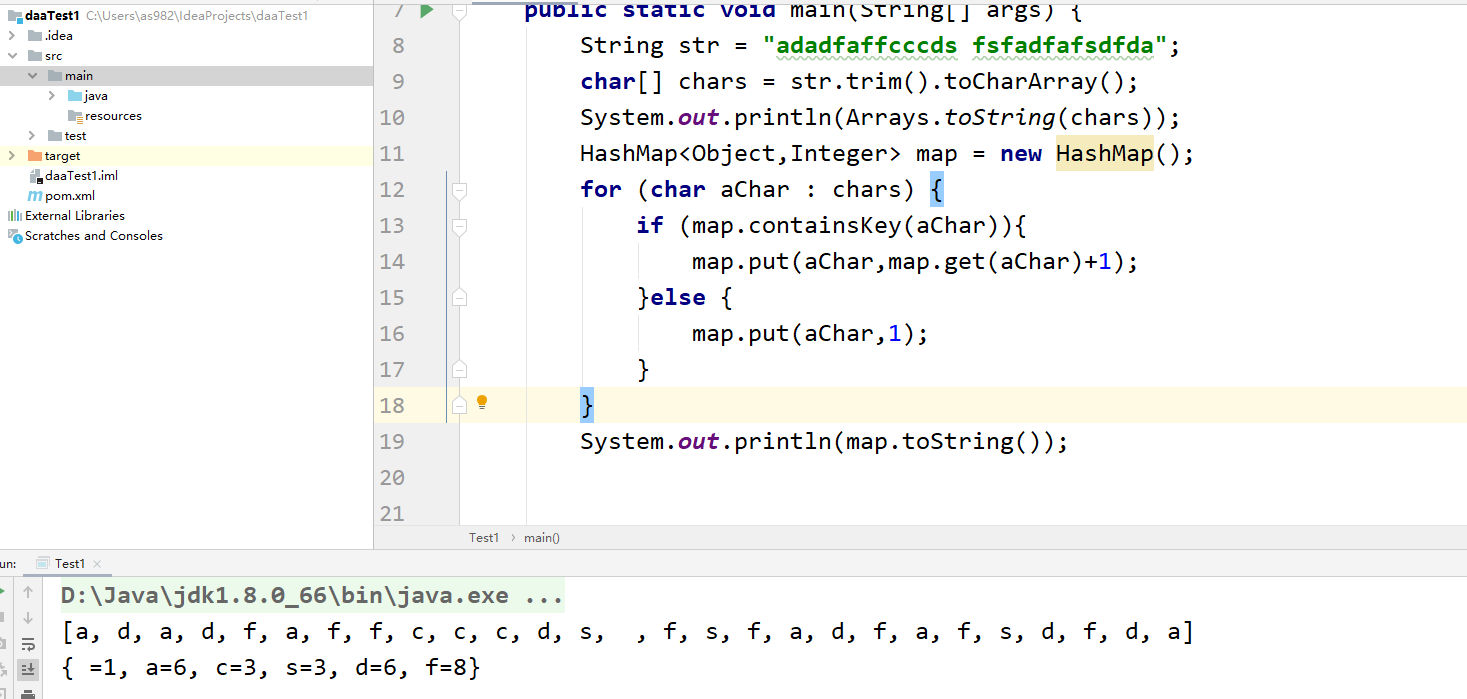
servlet的生命周期是什么
加载类—>实例化(为对象分配空间)—>初始化(为对象的属性赋值)—>请求处理(服务阶段)—>销毁
string和stringbuffer和stringbuilder的区别
String:适用于少量的字符串操作的情况
StringBuilder:适用于单线程下在字符缓冲区进行大量操作的情况
StringBuffer:适用多线程下在字符缓冲区进行大量操作的情况
有一张表,主键自增,数据很多,要查询最后一条数据怎么找
select max(id) from 表名: 先查询这个表最大的id,再根据这个id查询这个数据
mysql的分页怎么写 传的参数分别代表的是什么
前期mysql数据量在100左右使用分页查询,后期数据量在10万左右后,使用分页查询效率低下怎么优化
1、使用覆盖索引
select orderType, orderAmt from order_table limit 10000, 10<br /> 假设我们只需要查询上面两个字段,可以建立联合索引(orderType, orderAmt ),这样可以让查询走联合索 引,加快性能。但是我们这个表有37个字段,这么优化明显不合适,而且这种方式加快性能方式并不明显。
2、使用子查询
select * from order_table where id in (select id from order_table limit 1000000, 100);<br /> select * from order_table where id >= (select id from order_table limit 1000000, 1) limit 100;<br /> select * from order_table t1 join (select id from order_table limit 1000000, 1) t2 on t1.id >= t2.id limit 100<br /> 这种方式之所以能够大幅度优化性能,分析:<br /> 直接分页,不会走索引,全表扫描,其实是遍历主键索引树,但是每次都需要把对应行的数据取出来,要取 1000100条数据,然后丢弃前一百万条,太消耗性能。可以通过explain执行计划查看对应索引情况<br /> 使用子查询,会走主键索引,虽然也是遍历主键索引树,但是只需要取id,不需要取出整行数据,最后外层查询拿到对应的100条id,查询对应数据即可。通过根据索引字段定位后,大大减少了查询的数据量,效率自然大大提升
3、业务优化
真的会有人翻到第100万条数据吗,一般来说翻页不会查过20页,可以通过限制可以翻页的数量解决这个问题。像百度分页最多只能展示76页。还有一种方式,就是使用滚动,和微博一样,没有分页,只能不断下拉,就是使用之前记录上一页最大offset那个方法就可以做到。ES里面可以使用scroll API
jdk1.8的新特性
1、default关键字
在java里面,我们通常都是认为接口里面是只能有抽象方法,不能有任何方法的实现的,那么在jdk1.8里面打破了这个规定,引入了新的关键字default,通过使用default修饰方法,可以让我们在接口里面定义具体的方法实现,如下。
public class NewCharacterImpl implements NewCharacter{
@Override
public void test1() {
}
public static void main(String[] args) {
NewCharacter nca = new NewCharacterImpl();
nca.test2();
}
}
所以说这个default方法是所有的实现类都不需要去实现的就可以直接调用,那么比如说jdk的集合List里面增加了一个sort方法,那么如果定义为一个抽象方法,其所有的实现类如arrayList,LinkedList等都需要对其添加实现,那么现在用default定义一个默认的方法之后,其实现类可以直接使用这个方法了,这样不管是开发还是维护项目,都会大大简化代码量。
2、Lambda 表达式
<br />
//这是常规的Collections的排序的写法,需要对接口方法重写
public void test1(){
List<String> list =Arrays.asList("aaa","fsa","ser","eere");
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o2.compareTo(o1);
}
});
for (String string : list) {
System.out.println(string);
}
}
//这是带参数类型的Lambda的写法
public void testLamda1(){
List<String> list =Arrays.asList("aaa","fsa","ser","eere");
Collections.sort(list, (Comparator<? super String>) (String a,String b)->{
return b.compareTo(a);
});
for (String string : list) {
System.out.println(string);
}
}
//这是不带参数的lambda的写法
public void testLamda2(){
List<String> list =Arrays.asList("aaa","fsa","ser","eere");
Collections.sort(list, (a,b)->b.compareTo(a));
for (String string : list) {
System.out.println(string);
}
3、函数式接口
定义:“函数式接口”是指仅仅只包含一个抽象方法的接口,每一个该类型的lambda表达式都会被匹配到这个抽象方法。jdk1.8提供了一个@FunctionalInterface注解来定义函数式接口,如果我们定义的接口不符合函数式的规范便会报错`<br />`<br />
@FunctionalInterfacepublic interface MyLamda {
public void test1(String y);
//这里如果继续加一个抽象方法便会报错
// public void test1();
//default方法可以任意定义
default String test2(){
return "123";
}
default String test3(){
return "123";
}
//static方法也可以定义
static void test4(){
System.out.println("234");
}
}
5、Date Api更新
_ 5.1 _LocalDate/LocalTime/LocalDateTime
LocalDate为日期处理类、LocalTime为时间处理类、LocalDateTime为日期时间处理类,方法都类似,具体可以看API文档或源码,选取几个代表性的方法做下介绍。
now相关的方法可以获取当前日期或时间,of方法可以创建对应的日期或时间,parse方法可以解析日期或时间,get方法可以获取日期或时间信息,with方法可以设置日期或时间信息,plus或minus方法可以增减日期或时间信息;
_ 5.2_TemporalAdjusters
这个类在日期调整时非常有用,比如得到当月的第一天、最后一天,当年的第一天、最后一天,下一周或前一周的某天等。
5.3DateTimeFormatter
以前日期格式化一般用SimpleDateFormat类,但是不怎么好用,现在1.8引入了DateTimeFormatter类,默认定义了很多常量格式(ISO打头的),在使用的时候一般配合LocalDate/LocalTime/LocalDateTime使用,比如想把当前日期格式化成yyyy-MM-dd hh:mm:ss的形式:LocalDateTime dt = LocalDateTime.now(); DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd hh:mm:ss"); System.out.println(dtf.format(dt));
6、流
http与https的区别
HTTP:是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。
HTTPS:是以安全为目标的HTTP通道,简单讲是HTTP的安全版,即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。
tcp与udp的区别
UDP协议的全称是用户数据报协议,有不提供数据包分组、组装和不能对数据包进行排序的缺点,也就是说,当报文发送之后,是**无法得知其是否安全完整到达的**。<br />UDP的特点:<br />(1)面向无连接:UDP是不需要和TCP一样在发送数据前进行三次握手建立连接,并且也只是数据报文的搬运工,不会对数据报文进行任何拆分和拼接操作。<br />(2)有多种类型的播功能:UDP是支持一对多,多对多,多对一的传输方式。对应一下就是UDP提供单播、多播、广播的功能。<br />(3)面向报文:发送方的UDP对应用程序交下来的报文,在添加首部后就向下交付IP层。<br />(4)不可靠性:UDP并不保证可靠传输,它只是尽最大努力交付的一种协议,UDP只会把想发的数据报文一股脑的丢给对方,并不在意数据有无安全完整到达。UDP 因为没有拥塞控制,一直会以恒定的速度发送数据。即使网络条件不好,也不会对发送速率进行调整。这样实现的弊端就是在网络条件不好的情况下可能会导致丢包,但是优点也很明显,在某些实时性要求高的场景(比如电话会议)就需要使用 UDP 而不是 TCP。<br />(5)头部开销小,传输数据报文效率高哦:UDP 头部的数据源端口(可选字段)和目标端口,数据报文的长度,数据报文的检验和。因此 UDP 的头部开销小,只有八字节,相比 TCP 的至少二十字节要少得多,在传输数据报文时是很高效的。
TCP协议是一种面向连接、可靠、基于字节流的传输层通信协议啊。<br />TCP的特点:<br />(1)面向连接:在发送数据之前先在两端建立连接,就是我们的三次握手啦。<br />(2)单播传输:每条TCP传输连接只能有两个端点,只能进行点对点的数据传输,不支持多播和广播传输方式。<br />(3)面试字节流:以字节流的方式进行传输数据报文。<br />(4)可靠传输:TCP不像UDP那么浪哦,它是保证数据报文是可以交到对方手上,在传输过程中没了,还是会重传的哦。<br />(5)流量控制:A计算机向B计算机发送数据,A计算机发送太快啦,B计算机处理不过来时就会告诉A计算机让其慢一点。<br />(6)拥塞控制:A计算机向B计算机发送数据的过程中,某路段网堵了,那TCP有堵塞避免的机制。<br />(7)全双工通信:TCP允许通信双方的应用程序在任何时候都能发送数据,因为TCP连接的两端都设有缓存,用来临时存放双向通信的数据。
http的常见的状态码
200 OK:表示从客户端发送给服务器的请求被正常处理并返回
204 No Content:表示客户端发送给客户端的请求得到了成功处理,但在返回的响应报文中不含实体的主体部分(没有资源可以返回);
500 Inter Server Error:表示服务器在执行请求时发生了错误,也有可能是web应用存在的bug或某些临时的错误时;
404 Not Found 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置”您所请求的资源无法找到”的个性页面
504 Gateway Time-out 充当网关或代理的服务器,未及时从远端服务器获取请求
springmvc的执行流程,前端发送的请求是什么时候映射到对象里面去的
- 用户发送请求至前端控制器DispatcherServlet
- DispatcherServlet收到请求调用处理器映射器HandlerMapping
- HandlerMapping 根据用户的url请求 查找匹配该url的 Handler,并返回一个执行链
- DispatcherServlet 再请求 处理器适配器(HandlerAdapter) 调用相应的 Handler 进行处理并返回 ModelAndView 给 DispatcherServlet
- DispatcherServlet 将 ModelAndView 请求 ViewReslover(视图解析器)解析,返回具体 View
- DispatcherServlet 对 View 进行渲染视图(即将模型数据填充至视图中)
-
组件说明:
DispatcherServlet:前端控制器
**用户请求到达前端控制器,它就相当于mvc模式中的c,dispatcherServlet是整个流程控制的中心,**<br />** 由它调用其它组件处理用户的请求,dispatcherServlet的存在降低了组件之间的耦合性。**<br />HandlerMapping:处理器映射器
HandlerMapping负责根据用户请求url找到Handler即处理器,springmvc提供了不同的映射器实现不同的映射方式,
例如:配置文件方式,实现接口方式,注解方式等。
- Handler:处理器
Handler 是继DispatcherServlet前端控制器的后端控制器,在DispatcherServlet的控制下Handler对具体的用户请求进行处理。
由于Handler涉及到具体的用户业务请求,所以一般情况需要程序员根据业务需求开发Handler。
- HandlAdapter:处理器适配器
通过HandlerAdapter对处理器进行执行,这是适配器模式的应用,通过扩展适配器可以对更多类型的处理器进行执行。
- ViewResolver:视图解析器
View Resolver负责将处理结果生成View视图,View Resolver首先根据逻辑视图名解析成物理视图名即具体的页面地址,
再生成View视图对象,最后对View进行渲染将处理结果通过页面展示给用户。
- View:视图
springmvc框架提供了很多的View视图类型的支持,包括:jstlView、freemarkerView、pdfView等。我们最常用的视图就是jsp。
一般情况下需要通过页面标签或页面模版技术将模型数据通过页面展示给用户,需要由程序员根据业务需求开发具体的页面。
你画的SpringMVC请求处理过程是从网上抄的吧
mybatis的执行器
Mybatis 支持全局修改执行器, 参数名为: defaultExecutorType. 但是笔者并不推荐这种方式,笔者建议在获取 sqlSession对象时设置. Mybatis 共有三种执行器:
- SIMPLE: 默认的执行器, 对每条sql进行预编译->设置参数->执行等操作
- BATCH: 批量执行器, 对相同sql进行一次预编译, 然后设置参数, 最后统一执行操作
- REUSE: REUSE 执行器会重用预处理语句(prepared statements
mybatis动态sql怎么写
<br /><foreach collection="array" item="id" open="(" close=")" separator=","> #{id} </foreach>mybatis里面的插入标签是如何与接口的方法绑定的
mybatis里面的xml配置接口的权限类名,在通过标签的id绑定方法线程有哪些状态
线程状态有 5 种,新建,就绪,运行,阻塞,死亡线程的常用方法:
Thread.currentThead():获取当前线程对象
getPriority():获取当前线程的优先级
setPriority():设置当前线程的优先级
注意:线程优先级高,被CPU调度的概率大,但不代表一定会运行,还有小概率运行优先级低的线程。
isAlive():判断线程是否处于活动状态 (线程调用start后,即处于活动状态)
join():调用join方法的线程强制执行,其他线程处于阻塞状态,等该线程执行完后,其他线程再执行。有可能被外界中断产生InterruptedException 中断异常。
sleep():在指定的毫秒数内让当前正在执行的线程休眠(暂停执行)。休眠的线程进入阻塞状态。
yield():调用yield方法的线程,会礼让其他线程先运行。(大概率其他线程先运行,小概率自己还会运行)
interrupt():中断线程
wait():导致线程等待,进入堵塞状态。该方法要在同步方法或者同步代码块中才使用的(Object中的方法)
notify():唤醒当前线程,进入运行状态。该方法要在同步方法或者同步代码块中才使用的(Object中的方法)
notifyAll():唤醒所有等待的线程。该方法要在同步方法或者同步代码块中才使用的(Object中的方法)
创建自定义注解怎么创建
在类中使用@interface
<1>.作用在属性上注解
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface FiledAnnotation {
String value() default "GetFiledAnnotation";
}
<2>.作用在方法上注解
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface MethodAnnotation {
String name() default "MethodAnnotation";
String url() default "https://www.cnblogs.com";
}
<3>.作用在类上注解
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface TypeAnnotation {
String value() default "Is-TypeAnnotation";
}
线程的实现方式有哪几种?说说项目中是怎么使用的
Java实现多线程的四种方式
方式一:继承Thread类的方式
- 创建一个继承于Thread类的子类
- 重写Thread类中的run():将此线程要执行的操作声明在run()
- 创建Thread的子类的对象
调用此对象的start():①启动线程 ②调用当前线程的run()方法
//方式一 class ThreadTest extends Thread { @Override public void run() { for (int i = 0; i < 10; i++) { System.out.println(Thread.currentThread().getName() + ":" + i); } } } public class Test { public static void main(String[] args) { // 继承Thread ThreadTest thread = new ThreadTest(); thread.setName("方式一"); thread.start(); }方式二:实现Runnable接口的方式
创建一个实现Runnable接口的类
- 实现Runnable接口中的抽象方法:run():将创建的线程要执行的操作声明在此方法中
- 创建Runnable接口实现类的对象
- 将此对象作为参数传递到Thread类的构造器中,创建Thread类的对象
调用Thread类中的start():① 启动线程 ② 调用线程的run() —->调用Runnable接口实现类的run()
// 方式二 class RunnableTest implements Runnable { @Override public void run() { for (int i = 0; i < 10; i++) { System.out.println(Thread.currentThread().getName() + ":" + i); } } } public class Test { public static void main(String[] args) { // 实现Runnable RunnableTest runnableTest = new RunnableTest(); Thread thread2 = new Thread(runnableTest, "方式二"); thread2.start(); } }以下两种方式是jdk1.5新增的!
方式三:实现Callable接口
说明:与使用Runnable相比, Callable功能更强大些
- 实现的call()方法相比run()方法,可以返回值
- 方法可以抛出异常
- 支持泛型的返回值
- 需要借助FutureTask类,比如获取返回结果
- Future接口可以对具体Runnable、Callable任务的执行结果进行取消、查询是否完成、获取结果等。
- FutureTask是Futrue接口的唯一的实现类
FutureTask 同时实现了Runnable, Future接口。它既可以作为Runnable被线程执行,又可以作为Future得到Callable的返回值 ```java // 方式三 class CallableTest implements Callable
{ @Override public Integer call() throws Exception {
int sum = 0; for (int i = 0; i < 10; i++) { System.out.println(Thread.currentThread().getName() + ":" + i); sum += i; } return sum;}
} public class Test { public static void main(String[] args) {
// 实现Callable<> 有返回值
CallableTest callableTest = new CallableTest();
FutureTask<Integer> futureTask = new FutureTask<>(callableTest);
new Thread(futureTask, "方式三").start();
// 返回值
try {
Integer integer = futureTask.get();
System.out.println("返回值(sum):" + integer);
} catch (Exception e) {
e.printStackTrace();
}
}
}
**方式四:使用线程池**<br />说明:
- 提前创建好多个线程,放入线程池中,使用时直接获取,使用完放回池中。可以避免频繁创建销毁、实现重复利用。类似生活中的公共交通工具。
好处:
1. 提高响应速度(减少了创建新线程的时间)
1. 降低资源消耗(重复利用线程池中线程,不需要每次都创建)
1. 便于线程管理
```java
// 方式四
class ThreadPool implements Runnable {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + ":" + i);
}
}
}
public class Test {
public static void main(String[] args) {
// 线程池
ExecutorService pool = Executors.newFixedThreadPool(10);
ThreadPoolExecutor executor = (ThreadPoolExecutor) pool;
/*
* 可以做一些操作:
* corePoolSize:核心池的大小
* maximumPoolSize:最大线程数
* keepAliveTime:线程没任务时最多保持多长时间后会终止
*/
executor.setCorePoolSize(5);
// 开启线程
executor.execute(new ThreadPool());
executor.execute(new ThreadPool());
executor.execute(new ThreadPool());
executor.execute(new ThreadPool());
}
}
TreeSet是怎么去重的
在添加对象将该对象的哈希值和集合中已有对象的哈希值进行比较,如果哈希值都不相同,那么直接把该对象加入集合,如果出现哈希值相同的,那么再调用equals方法,只有equals方法返回true才认为是相同的对象,不加入集合。
TreeSet的两种排序方式
class Demo4
{
public static void main(String[] args)
{
TreeSet ts = new TreeSet();
//在添加时就已经进行排序了
//因为String实现了Comparable接口中的 int compareTo(Object obj)方法
//集合是依据字符串中的这个方法int compareTo(Object obj)来排序的
ts.add("zwoeiuroie");
ts.add("abcedf");// "abcedf".compareTo("zwoeiuroie")
ts.add("wowieur");//"wowieur".compareTo("zwoeiuroie") "wowieur".compareTo("abcedf")
sop(ts);
}
public static void sop(Object obj)
{
System.out.println(obj);
}
}`
自定义排序实现comparable接口,重写compareTo()方法
class Student implements Comparable
{
private String name;
private int age;
Student(){}
Student(String name,int age)
{
this.name = name;
this.age = age;
}
public int compareTo(Object obj)
{
if(!(obj instanceof Student))
throw new ClassCastException();
Student stu = (Student)obj;
int num = this.age-stu.age;//根据年龄从小到大排序
return num==0?this.name.compareTo(stu.name):num;
}
public String getName()
{
return this.name;
}
public int getAge()
{
return this.age;
}
public String toString()
{
return name+","+age;
}
}
如果comparable的排序方式不是我们需要的,自定义比较方式。因为我们不能轻易改动源代码,需要重写一种排序方式。
第二种方式:定义一个类实现comparator接口,并重写compare()方法,并将该类的对象作为TreeSet构造函数的参数传入。
class ComByName implements Comparator
{
public int compare(Object obj1,Object obj2)
{
if(!(obj1 instanceof Student))
throw new ClassCastException("类型转换异常");
if(!(obj2 instanceof Student))
throw new ClassCastException("类型转换异常");
Student stu1 = (Student)obj1;
Student stu2 = (Student)obj2;
int num = stu1.getName().compareTo(stu2.getName());
return num==0?stu1.getAge()-stu2.getAge():num;
}
}
class Demo5
{
public static void main(String[] args)
{
ComByName cbn = new ComByName();//创建自定义的排序方式对象
TreeSet ts = new TreeSet(cbn);//再创建集合对象时就得确定排序方式
//自定义的排序方式优先被使用
ts.add(new Student("zhangsan",23));
ts.add(new Student("lisi",21));//new Student("lisi",21).compareTo(new Student("zhangsan",23))
ts.add(new Student("wangwu",26));
ts.add(new Student("pengfei",20));
ts.add(new Student("zhaosi",23));
sop(ts);
}
public static void sop(Object obj)
{
System.out.println(obj);
}
}
arrlist里面的实现了random access接口有什么作用
RandomAccess接口这个空架子的存在,是为了能够更好地判断集合是否ArrayList或者LinkedList,从而能够更好选择更优的遍历方式,提高性能!
spring是怎么创建对象的
- 通过构造器创建对象
- 通过工厂模式创建对象
- 通过xml中的bean标签创建对象
- 通过注解bean创建对象
spring创建对象的作用域
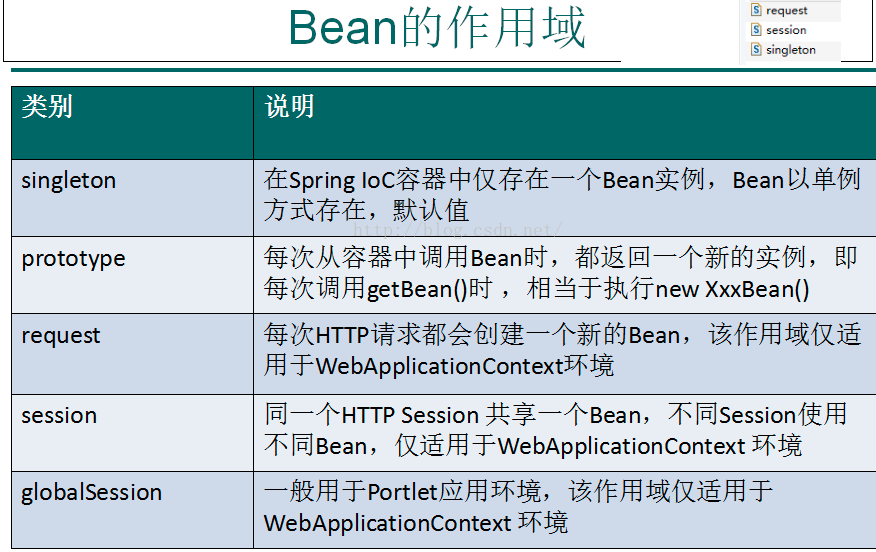
spring怎么解决循环依赖问题的
通过三级缓存来解决mysql的隔离级别 哪些会产生脏读,哪些会参数幻读
事务的ACID
(1)Atomic:原子性,就是一堆SQL,要么一起成功,要么都别执行,不允许某个SQL成功了,某个SQL失败了,这就是扯淡,不是原子性。 (2)Consistency:一致性,这个是针对数据一致性来说的,就是一组SQL执行之前,数据必须是准确的,执行之后,数据也必须是准确的。别搞了半天,执行完了SQL,结果SQL对应的数据修改没给你执行,那不是坑爹么。 (3)Isolation:隔离性,这个就是说多个事务在跑的时候不能互相干扰,别事务A操作个数据,弄到一半儿还没弄好呢,结果事务B来改了这个数据,导致事务A的操作出错了,那不就搞笑了。 (4)Durability:持久性,事务成功了,就必须永久对数据的修改是有效的,别过了一会儿数据自己没了,不见了,那就好玩儿了。
事务隔离级别
隔离级别:
READ UNCOMMITTED 读未提交
READ COMMITTED 读以提交
REPEATABLE READ 可重复读
SERIALIZABLE 串行化
隔离级别造成3个问题:
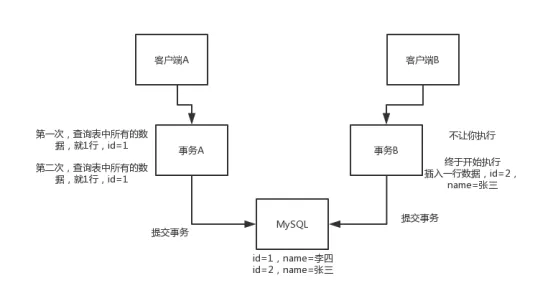
脏读:一个事务处理过程里读取了另一个未提交的事务中的数据。
不可重复读:一个事务内读取表中的某一行数据,多次读取结果不同。
幻读:指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致
(1)读未提交,Read Uncommitted:这个很坑爹,就是说某个事务还没提交的时候,修改的数据,就让别的事务给读到了,这就恶心了,很容易导致出错的。这个也叫做脏读。 (2)读已提交,Read Committed(不可重复读):这个比上面那个稍微好一点,但是一样比较尴尬 就是说事务A在跑的时候, 先查询了一个数据是值1,然后过了段时间,事务B把那个数据给修改了一下还提交了,此时事务A再次查询这个数据就成了值2了,这是读了人家事务提交的数据啊,所以是读已提交。
这个也叫做不可重复读,就是所谓的一个事务内对一个数据两次读,可能会读到不一样的值。如图:
(3)可重复读,Read Repeatable:这个比上面那个再好点儿,就是说事务A在执行过程中,对某个数据的值,无论读多少次都是值1;哪怕这个过程中事务B修改了数据的值还提交了,但是事务A读到的还是自己事务开始时这个数据的值。如图:
(4)幻读:不可重复读和可重复读都是针对两个事务同时对某条数据在修改,但是幻读针对的是插入
比如某个事务把所有行的某个字段都修改为了2,结果另外一个事务插入了一条数据,那个字段的值是1,然后就尴尬了。第一个事务会突然发现多出来一条数据,那个数据的字段是1。
那么幻读会带来啥问题呢?因为在此隔离级别下,例如:事务1要插入一条数据,我先查询一下有没有相同的数据,但是这时事务2添加了这条数据,这就会导致事务1插入失败,并且它就算再一次查询,也无法查询到与其插入相冲突的数据,同时自身死活都插入不了,这就不是尴尬,而是囧了。
(5)串行化:如果要解决幻读,就需要使用串行化级别的隔离级别,所有事务都串行起来,不允许多个事务并行操作。如图:
(6)MySQL的默认隔离级别是Read Repeatable,就是可重复读,就是说每个事务都会开启一个自己要操作的某个数据的快照,事务期间,读到的都是这个数据的快照罢了,对一个数据的多次读都是一样的。
sql的执行顺序
(1)from
(3) join
(2) on
(4) where
(5)group by(开始使用select中的别名,后面的语句中都可以使用)
(6) avg,sum….
(7)having
(8) select
(9) distinct
(10) order by

若有收获,就点个赞吧
0 人点赞
