一、关于Collection与Collections区别:
- Collection:集合层次结构中的根接口。
Collections: 完全由操作或返回集合的静态方法组成,包含操作集合的多态算法。Collections工具类提供了Set、List、Map进行排序、填充、查找元素的辅助方法。
二、集合图
三、关于List、Set、Map接口:
List:
可以允许重复的对象。
- 可以插入多个null元素。
- 是一个有序容器,保持了每个元素的插入顺序,输出的顺序就是插入的顺序。
- 常用的实现类有 ArrayList、LinkedList 和 Vector。ArrayList 最为流行,它提供了使用索引的随意访问,而 LinkedList 则对于经常需要从 List 中添加或删除元素的场合更为合适。
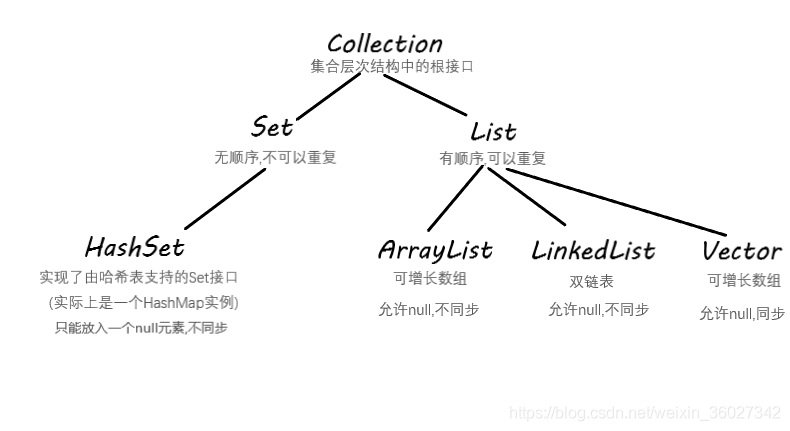
Set:
- 不允许重复对象
- 无序容器,你无法保证每个元素的存储顺序,TreeSet通过 Comparator 或者 Comparable 维护了一个排序顺序。
- 只允许一个 null 元素
- Set 接口最流行的几个实现类是 HashSet、LinkedHashSet 以及 TreeSet。最流行的是基于 HashMap 实现的 HashSet;TreeSet 还实现了 SortedSet 接口,因此 TreeSet 是一个根据其 compare() 和 compareTo() 的定义进行排序的有序容器。
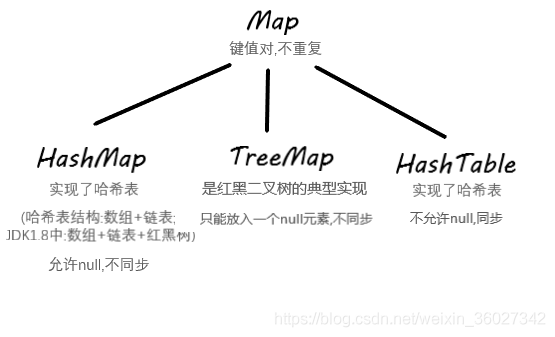
Map:
- Map不是collection的子接口或者实现类。Map是一个接口。
- Map 的 每个 Entry 都持有两个对象,也就是一个键一个值,Map 可能会持有相同的值对象但键对象必须是唯一的。
- TreeMap 也通过 Comparator 或者 Comparable 维护了一个排序顺序。
- Map 里你可以拥有随意个 null 值但最多只能有一个 null 键。
Map 接口最流行的几个实现类是 HashMap、LinkedHashMap、Hashtable 和 TreeMap。(HashMap、TreeMap最常用)
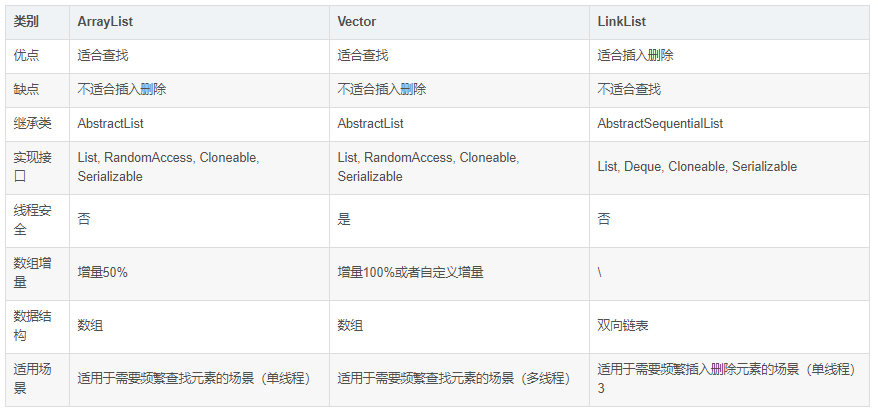
四、关于ArrayList、LinkedList、Vector
ArrayList属于非线程安全,而Vector则属于线程安全。如果是开发中没有线程同步的需求,推荐优先使用ArrayList。因此其内部没有synchronized,执行效率会比Vector快很多。
- 从数据结构的角度分析。ArrayList是一个数组结构(Vector同理),数组在内存中是一片连续存在的片段,在查找元素的时候数组能够很方便的通过内存计算直接找到对应的元素内存。但是它也有很大的缺点。我们假设需要往数组插入或删除数据的位置为i,数组元素长度为n,则需要搬运数据n-i次才能完成插入、删除操作,导致其效率不如LinkedList。
- LinkedList的底层是一个双向链表结构,在进行查找操作的时候需要花费非常非常多的时间来遍历整个链表(哪怕只遍历一半),这就是LinkedList在查找效率不如ArrayList快的原因。但是由于其链表结构的特殊性,在插入、删除数据的时候,只需要修改链表节点的前后指针就可以完成操作,其的效率远远高于ArrayList。
五、关于 HashSet、LinkedHashSet 以及 TreeSet
HashSet
有如下特点:
- 不能保存元素的排列顺序
- 不是同步的
元素可以是null,但是只能设置一个null
当向HashSet结合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据 hashCode值来决定该对象在HashSet中存储位置。<br /> 简单的说,HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值相等。<br />注意,如果要把一个对象放入HashSet中,重写该对象对应类的equals方法,也应该重写其hashCode()方法。其规则是如果两个对象通过equals方法比较返回true时,其 hashCode也应该相同。另外,对象中用作equals比较标准的属性,都应该用来计算 hashCode的值。
TreeSet
可以实现自动排序的类型。
TreeSet判断两个对象不相等的方式是两个对象通过equals方法返回false,或者通过CompareTo方法比较没有返回0。LinkedHashSet
LinkedHashSet集合同样是根据元素的hashCode值来决定元素的存储位置,但是它同时使用链表维护元素的次序。这样使得元素看起 来像是以插入顺 序保存的,也就是说,当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素。

若有收获,就点个赞吧
0 人点赞
