- 解题三部曲
- 二叉树的最大深度
- 深度优先(DFS)
- 广度优先(BFS)
- 二叉树的层序遍历">二叉树的层序遍历
- 二叉树的最小深度
- 二叉树的最大深度">二叉树的最大深度
- 验证二叉搜索树">验证二叉搜索树
- 二叉树镜像">二叉树镜像
- 对称二叉树">对称二叉树
- 二叉树中和为某一值的路径">二叉树中和为某一值的路径
- 二叉搜索树中的插入操作">二叉搜索树中的插入操作
- 删除二叉搜索树中的节点">删除二叉搜索树中的节点
- 树的子结构">树的子结构
- 按之字形顺序打印二叉树">按之字形顺序打印二叉树
- 二叉搜索树中第K小的元素">二叉搜索树中第K小的元素
- 二叉树的最近公共祖先">二叉树的最近公共祖先
- 寻找重复的子树">寻找重复的子树
- 二叉搜索树转换为双向链表*">二叉搜索树转换为双向链表*
- 从前序与中序遍历序列构造二叉树">从前序与中序遍历序列构造二叉树
何谓递归?程序反复调用自身即是递归。此处禁止套娃!
以下会举例说明我对递归的一点理解,如果你不想看下去了,请记住这几个问题怎么回答:
- 如何给一堆数字排序? 答:分成两半,先排左半边再排右半边,最后合并就行了,至于怎么排左边和右边,请重新阅读这句话。
- 孙悟空身上有多少根毛? 答:一根毛加剩下的毛。
- 你今年几岁? 答:去年的岁数加一岁,1999 年我出生。
递归代码最重要的两个特征:结束条件和自我调用。自我调用是在解决子问题,而结束条件定义了最简子问题的答案。
解题三部曲
- 找整个递归的终止条件:递归应该在什么时候结束?
- 找返回值:应该给上一级返回什么信息?
- 本级递归应该做什么:在这一级递归中,应该完成什么任务?
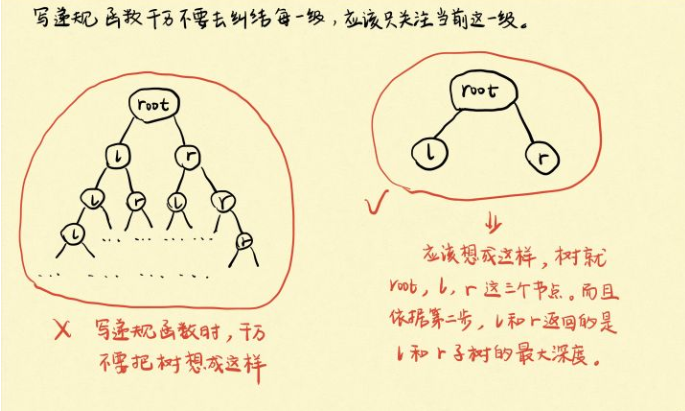
二叉树的最大深度
- 找终止条件。什么情况下递归结束?当然是树为空的时候,此时树的深度为0,递归就结束了。
- 找返回值。应该返回什么?题目求的是树的最大深度,我们需要从每一级得到的信息自然是当前这一级对应的树的最大深度,因此我们的返回值应该是当前树的最大深度,这一步可以结合第三步来看。
- 本级递归应该做什么。首先,还是强调要走出之前的思维误区,递归后我们眼里的树一定是这个样子的,看下图。此时就三个节点:root、left、right,其中根据第二步,left和right分别记录的是root的左右子树的最大深度。那么本级递归应该做什么就很明确了,自然就是在root的左右子树中选择较大的一个,再加上1就是以root为根的子树的最大深度了,然后再返回这个深度即可。
深度优先(DFS)
对于一颗二叉树,深度优先搜索(Depth First Search)是沿着树的深度遍历树的节点,尽可能深的搜索树的分支。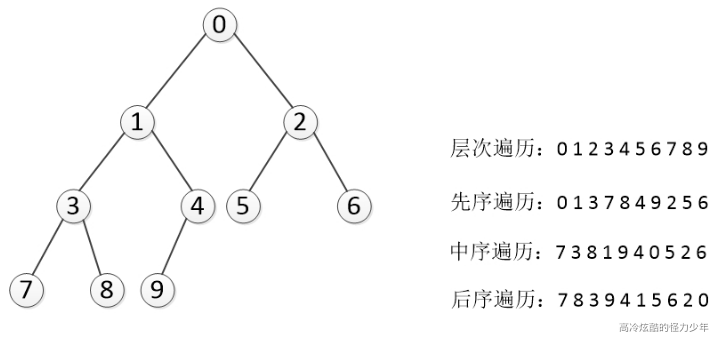
先序遍历(根左右)
class Solution(object):def preorderTraversal(self, root):方法一:递归res = []def dfs(root):if root == None:returnres.append(root.val)dfs(root.left)dfs(root.right)dfs(root)return res方法二:循环+栈迭代实现if not root:returnstack = []node = rootres = []while stack or node:while node:# 先保存当前值res.append(node.val)# 把左边所有都压入栈stack.append(node)node = node.left# 然后再把右边所有都压入栈node = stack.pop()node = node.rightreturn res
中序遍历(左根右)
class Solution(object):def inorderTraversal(self, root):方法一:递归res = []def dfs(root):if not root:returndfs(root.left)res.append(root.val)dfs(root.right)dfs(root)return res方法二:循环+栈迭代实现if not root:returnstack = []node = rootres = []while stack or node:# 先把左边所有都压入栈while node:stack.append(node)node = node.left# 将栈里的节点的值保存到resnode = stack.pop()res.append(node.val)# 然后再把右边所有都压入栈node = node.rightreturn res
后序遍历(左右根)
class Solution(object):def postorderTraversal(self, root):方法一:递归res = []def dfs(root):if not root:returndfs(root.left)dfs(root.right)res.append(root.val)dfs(root)return res方法二:循环+栈迭代if not root:returnstack = []node = rootres = []while stack or node:while node: # 下行循环,直到找到第一个叶子节点stack.append(node)if node.left: # 能左就左,不能左就右node = node.leftelse:node = node.rightnode = stack.pop()res.append(node.val)# 如果当前节点是上一节点的左子节点,则遍历右子节点if stack and node == stack[-1].left:node = stack[-1].rightelse:node = Nonereturn res方法三:投机取巧法,使用逆先序遍历if not root:return []stack = []node = rootres = []while stack or node:while node:res.append(node.val)stack.append(node)node = node.right # 此处和下面的left相反node = stack.pop()node = node.leftreturn res[::-1]
广度优先(BFS)
从树的root开始,从上到下从从左到右遍历整个树的节点
class Solution:def levelOrder(self, root: TreeNode) -> List[int]:# 利用队列实现树的层次遍历if not root:returnres = []queue = [root]while queue:node = queue.pop(0)res.append(node.val)if node.left:queue.append(node.left)if node.right:queue.append(node.right)return res
二叉树的层序遍历
给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)
示例:二叉树:[3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回其层序遍历结果:
[
[3],
[9,20],
[15,7]
]
class Solution(object):def levelOrder(self, root):# 利用队列实现树的层次遍历if not root:return []res = []queue = [root]while queue:# 因为题目要求用子列表表示,这里是和广度优先遍历唯一区别level = []for _ in range(len(queue)):node = queue.pop(0)level.append(node.val)# 如果左子节点存在,入队列if node.left:queue.append(node.left)# 如果右子节点存在,入队列if node.right:queue.append(node.right)res.append(level) # 如果是从下向上遍历,这需要把这里改成头插 res.insert(0, level)return res
二叉树的最小深度
class Solution:# 方法一:递归# 可以通过递归求左右节点的最小深度的较小值,也可以层序遍历找到第一个叶子节点所在的层数。def minDepth(self, root: TreeNode) -> int:if not root:returnif not root.left and not root.right:return 1if not root.right:return 1 + self.minDepth(root.left)if not root.left:return 1 + self.minDepth(root.right)return 1 + min(self.minDepth(root.left), self.minDepth(root.right))# 方法二:BFS利用队列实现树的层次遍历if not root:return 0depth = 1queue = [root]while queue:for i in range(len(queue)):node = queue.pop(0) # 切记要先取出if not node.left and not node.right:return depthif node.left:queue.append(node.left)if node.right:queue.append(node.right)depth += 1return depth
二叉树的最大深度
基本思路就是递归,当前树的最大深度等于(1+max(左子树最大深度,右子树最大深度))
class Solution:def maxDepth(self, root):# 方法一:dfs递归if not root:return 0return 1 + max(self.maxDepth(root.left), self.maxDepth(root.right))# 方法二:BFS利用队列实现树的层次遍历if not root:return 0queue = [root]depth = 0while queue:for i in range(len(queue)):node = queue.pop(0)if node.left:queue.append(node.left)if node.right:queue.append(node.right)depth += 1return depth
验证二叉搜索树
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
假设一个二叉搜索树具有如下特征:
节点的左子树只包含小于当前节点的数。
节点的右子树只包含大于当前节点的数。
所有左子树和右子树自身必须也是二叉搜索树。
输入:
5
/ \
1 4
/ \
3 6
输出: false
解释: 输入为: [5,1,4,null,null,3,6]。根节点的值为 5 ,但是其右子节点值为 4 。
class Solution(object):def isValidBST(self, root):# 方法一:中序遍历stack = []inorder = float('-inf')while stack or root:while root:stack.append(root)root = root.leftroot = stack.pop()# 如果中序遍历得到的节点的值小于等于前一个 inorder,说明不是二叉搜索树if root.val <= inorder:return Falseinorder = root.valroot = root.rightreturn True# 方法二:递归,根据左<中<右的特点判断def dfs(root, left, right):if not root:return Trueelif left < root.val < right:return dfs(root.left, left, root.val) and dfs(root.right, root.val, right)else:return Falsereturn dfs(root,float('-inf'), float('inf'))
二叉树镜像
class Solution:def Mirror(self, root):if not root:return#互换左右孩子的值root.right, root.left = root.left, root.right#递归处理左子树self.Mirror(root.right)#递归处理右子树self.Mirror(root.left)return root
对称二叉树
给定一个二叉树,检查它是否是镜像对称的。
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1
/ \
2 2
/ \ / \
3 4 4 3
但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
1
/ \
2 2
\ \
3 3
class Solution(object):def isSymmetric(self, root):# 方法一:递归算法if not root:return Truedef dfs(left, right):# 递归的终止条件是两个节点都为空# 或者两个节点中有一个为空# 或者两个节点的值不相等if not left and not right:return Trueif not left or not right:return Falseif left.val != right.val:return Falseret1 = dfs(left.left, right.right)ret2 = dfs(left.right, right.left)return ret1 and ret2# 用递归函数,比较左节点,右节点return dfs(root.left, root.right)# 方法二:迭代算法if not root:return Truedeq = deque([root.left, root.right])while deq:root_right = deq.pop()root_left = deq.pop()if root_left == None and root_right == None:continueif root_left == None or root_right == None:return Falseif root_left.val != root_right.val:return Falsedeq.extend([root_left.left, root_right.right, root_left.right, root_right.left])return True
二叉树中和为某一值的路径
输入一棵二叉树和一个整数,打印出二叉树中节点值的和为输入整数的所有路径。从树的根节点开始往下一直到叶节点所经过的节点形成一条路径。
示例:
给定如下二叉树,以及目标和 sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ / \
7 2 5 1
返回:
[
[5,4,11,2],
[5,8,4,5]
]
class Solution(object):def pathSum(self, root, target):# 栈+递归方法lists = []stack = []def dfs(root, nums):if not root:returnstack.append(root.val)nums -= root.valif nums == 0 and not root.left and not root.right:lists.append(list(stack))dfs(root.left, nums)dfs(root.right, nums)stack.pop()dfs(root, target)return lists
二叉搜索树中的插入操作
给定二叉搜索树(BST)的根节点和要插入树中的值,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 输入数据 保证 ,新值和原始二叉搜索树中的任意节点值都不同。
注意,可能存在多种有效的插入方式,只要树在插入后仍保持为二叉搜索树即可。 你可以返回 任意有效的结果 。
输入:root = [4,2,7,1,3], val = 5
输出:[4,2,7,1,3,5]
class Solution(object):def insertIntoBST(self, root, val):if not root:return TreeNode(val)node = root# 思路不难,比较node.val和val,小并且左边没孩子就放左边,大并且右边没孩子就放右边while node:if val < node.val:if not node.left:node.left = TreeNode(val)breakelse:node = node.leftelse:if not node.right:node.right = TreeNode(val)breakelse:node = node.rightreturn root
删除二叉搜索树中的节点
给定一个二叉搜索树的根节点 root 和一个值 key,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
root = [5,3,6,2,4,null,7]
key = 3
5
/ \
3 6
/ \ \
2 4 7
给定需要删除的节点值是 3,所以我们首先找到 3 这个节点,然后删除它。
一个正确的答案是 [5,4,6,2,null,null,7]
# 找到后有四种情况# case0 结点不存在,empty,return root# case1 结点没孩子,直接删除# case2 结点只有一个孩子,是左孩子,让左孩子即位# case3 结点只有一个孩子,是右孩子,让右孩子即位# case4 结点有俩孩子,用 right tree left most 替换待删除结点,然后把right tree left most那个结点删除class Solution:def deleteNode(self, root, key):# 方法一:慢慢找一层一层遍历if root is None:return rootif root.val > key:root.left = self.deleteNode(root.left, key)elif root.val < key:root.right = self.deleteNode(root.right, key)else:# case1 没有孩子,直接删除返回空if not root.left and not root.right:root = Nonereturn root# case2 只有一个孩子,左孩子,让左孩子即位elif root.left and not root.right:tmp = root.leftroot = Nonereturn tmp# case3 只有一个孩子,右孩子,让右孩子即位elif not root.left and root.right:tmp = root.rightroot = Nonereturn tmp# case4 有两个孩子,和右子树 left most交换后在右子树中删除 left mostelse:curr = root.right # 右子树while curr.left: # find left mostcurr = curr.left# 退出while循环时候的curr就是left mostroot.val = curr.val # 即位root.right = self.deleteNode(root.right, curr.val) # 在右子树中删除该结点后作为新的右子树return root# 方法二:递归def dfs(root, key, l):if not root:return lif root.val == key:return dfs(root.right, key, root.left)elif root.val < key:root.right = dfs(root.right, key, l)return rootelse:root.left = dfs(root.left, key, l)return rootreturn dfs(root, key, None)
树的子结构
输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构)
B是A的子结构, 即 A中有出现和B相同的结构和节点值。
给定的树 A:
3
/ \
4 5
/ \
1 2
给定的树 B:
4
/
1
返回 true,因为 B 与 A 的一个子树拥有相同的结构和节点值。
输入:A = [1,2,3], B = [3,1]
输出:false
输入:A = [3,4,5,1,2], B = [4,1]
输出:true
class Solution(object):def isSubStructure(self, A, B):if not A or not B:return Falsedef dfs(A, B):if not B:return Trueif not A:return Falseif A.val != B.val:return Falsereturn dfs(A.left, B.left) and dfs(A.right, B.right)return dfs(A, B) or self.isSubStructure(A.left, B) or self.isSubStructure(A.right, B)
按之字形顺序打印二叉树
请实现一个函数按照之字形打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右至左的顺序打印,第三行按照从左到右的顺序打印,其他行以此类推。
class Solution(object):def zigzagLevelOrder(self, root):# 方法一:按照广度优先的模版套就行了,区别就是正向插入和反向插入if not root:return []# index记录层数奇偶index = 1res = []queue = [root]while queue:# 获取queue的长度,因为队列的长度是在不断变化的,这里需先确定要遍历多少次level = []for _ in range(len(queue)):node = queue.pop(0)level.append(node.val)if node.left:queue.append(node.left)if node.right:queue.append(node.right)# 当index为奇数时,就正向输出if index & 1 == 1:res.append(level)# 当index偶位数时,就反向输出,即先调用一次reverse,再保存else:res.append(level[::-1])index += 1return res# 方法二:使用递归if not root:return []# index记录层数奇偶index = 0res = []def dfs(root, index):if not root:returnif len(res) == index:res.append([])# 当index为偶数时,就直接头插if index & 1 == 0:res[index].append(root.val)# 当index为奇数时,就直接尾插else:res[index].insert(0, root.val)dfs(root.left, index + 1)dfs(root.right, index + 1)dfs(root, index)return res
二叉搜索树中第K小的元素
给定一棵二叉搜索树,请找出其中的第k小的结点。例如,(5,3,7,2,4,6,8)中,按结点数值大小顺序第三小结点的值为4。
class Solution:def kthSmallest(self, root, k):# 方法一:DFS中序遍历递归法,然后根据切片取值res = []def dfs(root):if not root:returndfs(root.left) # 如果求第K大的元素,和下面的right互换即可res.append(root.val)dfs(root.right)dfs(root)return res[k-1]# 方法二:DFS中序遍历循环压栈法stack = []node = rootwhile True:# 先把左边所有都压入栈while node:stack.append(node)node = root.leftnode = stack.pop()# 唯一区别就是这里计数了k -= 1if k == 0:return node.valnode = node.right
二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”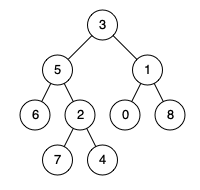
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。
class Solution(object):def lowestCommonAncestor(self, root, p, q):if not root:return None# 边界条件,如果匹配到left或right就直接返回停止递归if root.val == p.val or root.val == q.val:return root# 因为是DFS算法,这个模板可以无脑套用,写上之后可能你思路就清晰很多left = self.lowestCommonAncestor(root.left, p, q)right = self.lowestCommonAncestor(root.right, p, q)# 如果左子树找不到,那就在右子树,如果右子树找不到,那就在左子树if not left:return rightif not right:return leftreturn root
寻找重复的子树
给定一棵二叉树,返回所有重复的子树。对于同一类的重复子树,你只需要返回其中任意一棵的根结点即可。
两棵树重复是指它们具有相同的结构以及相同的结点值。
1
/ \
2 3
/ / \
4 2 4
/
4
下面是两个重复的子树:
2
/
4
和
4
class Solution(object):def findDuplicateSubtrees(self, root):# 递归# “重复”也就是说既需要知道以当前节点为根的子树什么样,也需要知道以其他节点为根的子树长啥样dicts = {}res = []def dfs(root):if not root:return '#'tmp = dfs(root.left) + ',' + dfs(root.right) + ',' + str(root.val)if tmp in dicts:dicts[tmp] += 1else:dicts[tmp] = 1if dicts[tmp] == 2:res.append(root)return tmpdfs(root)return res
二叉搜索树转换为双向链表*
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的循环双向链表。要求不能创建任何新的节点,只能调整树中节点指针的指向。
为了让您更好地理解问题,以下面的二叉搜索树为例: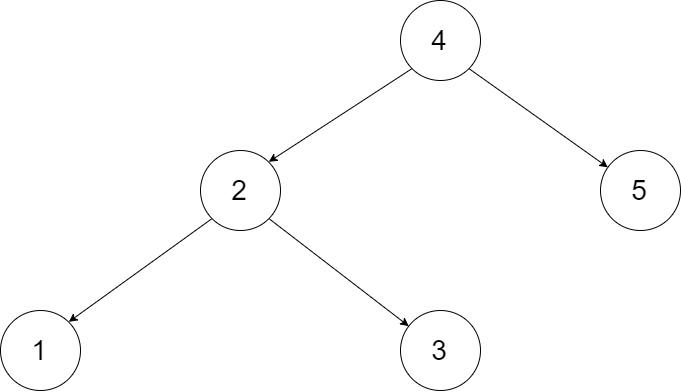
我们希望将这个二叉搜索树转化为双向循环链表。链表中的每个节点都有一个前驱和后继指针。对于双向循环链表,第一个节点的前驱是最后一个节点,最后一个节点的后继是第一个节点。
下图展示了上面的二叉搜索树转化成的链表。“head” 表示指向链表中有最小元素的节点。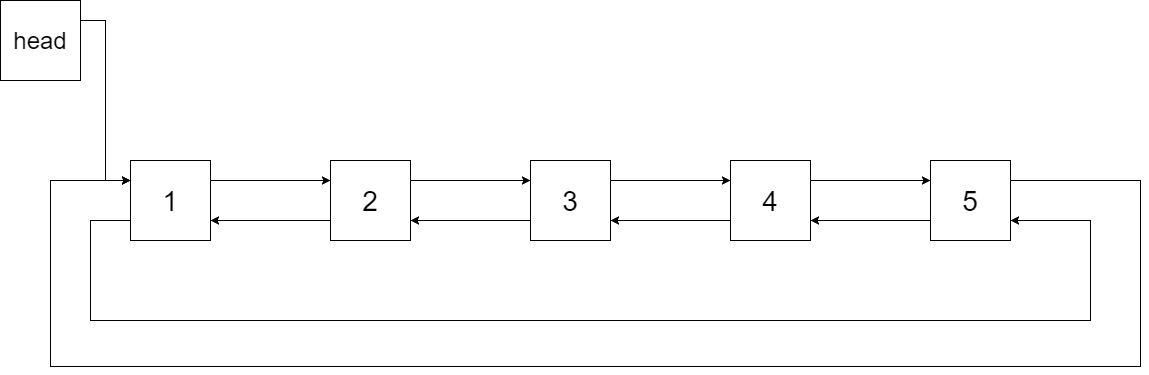
特别地,我们希望可以就地完成转换操作。当转化完成以后,树中节点的左指针需要指向前驱,树中节点的右指针需要指向后继。还需要返回链表中的第一个节点的指针。
class Solution(object):def treeToDoublyList(self, root):# 1.这里定义全局的head和pre。# 2.整体思路按照中序遍历来走,pre如果为空则表示是这棵树左下的节点,那么将其定义为头节点。# 3.如果pre不空的话,就表示当前遍历的节点的左子树的右下节点。# 4.遍历完成后,pre指向这棵树右下的节点。# 5.最后将其首尾连接起来。if not root:returndef dfs(cur):if not cur:returndfs(cur.left) # 递归左子树if self.pre: # 修改节点引用self.pre.right, cur.left = cur, self.preelse: # 记录头节点self.head = curself.pre = cur # 保存 curdfs(cur.right) # 递归右子树self.pre = Nonedfs(root)self.head.left, self.pre.right = self.pre, self.headreturn self.head
从前序与中序遍历序列构造二叉树
根据一棵树的前序遍历与中序遍历构造二叉树。
注意:你可以假设树中没有重复的元素。
前序遍历 preorder = [3,9,20,15,7]
中序遍历 inorder = [9,3,15,20,7]
返回如下的二叉树:
3
/ \
9 20
/ \
15 7
Solution(object):def buildTree(self, preorder, inorder):if len(inorder) == 0:return None# 创建一棵新树root = TreeNode(preorder[0])# 在中序中找到前序第一个节点的位置,中序遍历中mid的左边全是左子树,右边全是右子树mid = inorder.index(preorder[0])# 构建左子树root.left = self.buildTree(preorder[1:mid+1], inorder[:mid])# 构建右子树root.right = self.buildTree(preorder[mid+1:], inorder[mid+1:])return root

若有收获,就点个赞吧
0 人点赞
