判断回溯很简单,拿到一个问题,你感觉如果不穷举一下就没法知道答案,那就可以开始回溯了。
模版
回溯法(探索与回溯法)是一种选优搜索法,又称为试探法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为“回溯点”。
解决一个回溯问题,实际上就是一个决策树的遍历过程。只需要思考3个问题:
- 路径:也就是已经做出的选择。
- 选择列表:也就是你当前可以做的选择。
- 结束条件:也就是到达决策树底层,无法再做选择的条件。
回溯算法的框架
res = []def dfs(路径, 选择列表):if 满足结束条件:result.append(路径)returnfor 选择 in 选择列表:# 为了结果不重复,一般得加下面这个判断if i > 0 and num[i] == num[i-1]:continue# 做选择路径.append(选择)dfs(路径, 选择列表)# 撤销选择路径.pop(选择)
核心:就是 for 循环里面的递归,在递归调用之前「做选择」,在递归调用之后「撤销选择」。写 backtrack 函数时,需要维护走过的「路径」和当前可以做的「选择列表」,当触发「结束条件」时,将「路径」记入结果集。
无重复列表全排列
给定一个没有重复数字的序列,返回其所有可能的全排列。
输入: [1,2,3]
输出:
[
[1,2,3],
[1,3,2],
[2,1,3],
[2,3,1],
[3,1,2],
[3,2,1]
]
class Solution(object):def permute(self, nums):# 方法一:套模版,需要撤销# 定义全局变量保存最终结果res = []# 定义状态变量保存当前状态path = []def dfs(nums, path):# 结束条件if len(path) == len(nums):res.append(path[:])for i in nums:# 如果在当前排列中已经有i了,就continue,相当于分支限界,即不对当前节点子树搜寻了if i in path:continue# 做选择path.append(i)dfs(nums, path)# 撤销选择path.pop()dfs(nums, path)return res# 方法二:不撤销,运用另一套模版res = []path = []def dfs(nums, path):if len(path) == len(nums):res.append(path[:])for i in nums:# 如果在当前排列中已经有i了,就continue,相当于分支限界,即不对当前节点子树搜寻了if i in path:continuedfs(nums, path + [i])dfs(nums, path)return res
有重复列表全排列
给定一个可包含重复数字的序列,返回所有不重复的全排列。
输入: [1,1,2]
输出:
[
[1,1,2],
[1,2,1],
[2,1,1]
]
class Solution(object):def permuteUnique(self, nums):res = []path = []# 务必记录长度n = len(nums)def dfs(nums, path):# 需要满足条件才能append,也就长度得是3,还不能重复if len(path)==n and path not in res:res.append(path[:])for i in range(len(nums)):# 由于题目数据有重复,所以得passif i > 0 and nums[i] == nums[i-1]:continue# 将当前遍历到的元素删除dfs(nums[:i] + nums[i+1:], path + [nums[i]])dfs(nums, path)return res
无重复字符串的排列组合
无重复字符串的排列组合。编写一种方法,计算某字符串的所有排列组合,字符串每个字符均不相同。
输入:S = “qwe”
输出:[“qwe”, “qew”, “wqe”, “weq”, “ewq”, “eqw”]
输入:S = “ab”
输出:[“ab”, “ba”]
# 待定class Solution(object):def permutation(self, S):nums = Sres = []path = []def dfs(nums, path):if len(path) == len(nums):res.append(''.join(path))for i in nums:# 如果在当前排列中已经有i了,就continue,相当于分支限界,即不对当前节点子树搜寻了if i in path:continuedfs(nums, path + [i])dfs(nums, path)return res
有重复字符串的排列组合
有重复字符串的排列组合。编写一种方法,计算某字符串的所有排列组合。
输入:S = “qqe”
输出:[“eqq”,”qeq”,”qqe”]
输入:S = “ab”
输出:[“ab”, “ba”]
class Solution(object):def permutation(self, S):# 方法一:比较好理解,和上面的列表全排列类似nums = list(sorted(S))res = []path = []# 务必记录长度n = len(nums)def dfs(nums, path):# 需要满足条件才能append,也就长度得是3,还不能重复if len(path)==n and ''.join(path) not in res:res.append(''.join(path))for i in range(len(nums)):# 由于题目数据有重复,所以得passif i > 0 and nums[i] == nums[i-1]:continue# 将当前遍历到的元素删除dfs(nums[:i] + nums[i+1:], path + [nums[i]])dfs(nums, path)return res# 方法二:需要用散列表去重,不太好理解s = list(s)res = []def dfs(x):if x == len(s) - 1:res.append(''.join(s)) # 添加排列方案returndicts = {}for i in range(x, len(s)):if s[i] in dicts:continue # 重复,因此剪枝dicts[s[i]] = is[i], s[x] = s[x], s[i] # 交换,将 s[i] 固定在第 x 位dfs(x + 1) # 开启固定第 x + 1 位字符s[i], s[x] = s[x], s[i] # 恢复交换dfs(0)return res
无重复子集
给你一个整数数组 nums ,数组中的元素互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
输入:nums = [0]
输出:[[],[0]]
class Solution(object):def subsets(self, nums):res = []path = []def dfs(nums, index):# 因为长的短的都要,所以append放外面了res.append(path[:])if len(path) == len(nums):returnfor i in range(index, len(nums)):path.append(nums[i])dfs(nums, i+1)path.pop()dfs(nums, 0)return res
有重复子集
给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。返回的解集中,子集可以按 任意顺序 排列。
输入:nums = [1,2,2]
输出:[[],[1],[1,2],[1,2,2],[2],[2,2]]
输入:nums = [0]
输出:[[],[0]]
class Solution(object):def subsetsWithDup(self, nums):res = []path = []# 和上一题的第一个区别就是需要排序nums.sort()def dfs(nums, index):# 因为长的短的都要,所以append放外面了res.append(path[:])if len(path) == len(nums) and path not in res:returnfor i in range(index, len(nums)):# 由于题目数据有重复,所以得passif i > index and nums[i] == nums[i-1]:continuepath.append(nums[i])dfs(nums, i+1)path.pop()dfs(nums, 0)return res
电话号码的字母组合(无重复类型)
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
输入:digits = “23”
输出:[“ad”,”ae”,”af”,”bd”,”be”,”bf”,”cd”,”ce”,”cf”]
输入:digits = “”
输出:[]
输入:digits = “2”
输出:[“a”,”b”,”c”]
class Solution(object):def letterCombinations(self, digits):if digits == "":return []dicts = {"2": "abc", "3": "def", "4": "ghi", "5": "jkl", "6": "mno", "7": "pqrs", "8": "tuv", "9": "wxyz"}res = []path = ""def dfs(index, path):# 如果目前path的长度和digits的长度相等,说明已经遍历完一趟,返回结果列表if len(path) == len(digits):res.append(path)return# 遍历当前索引的数字对应的英文列表for i in dicts[digits[index]]:# 递归下一个数字对应的英文列表dfs(index+1, path+i)dfs(0, path)return res
整数的所有组合(无重复类型)
给定两个整数 n 和 k,返回 1 … n 中所有可能的 k 个数的组合。
输入: n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
class Solution(object):def combine(self, n, k):res = []path = []# 两个参数,一个是从1开始一直加到n的整数,一个是暂存的列表。def dfs(index, path):if len(path) == k:res.append(path[:])return# 如果列表长度小于k的话,就进入循环,将j增大1,且暂存列表加入数字jfor j in range(index, n+1):dfs(j+1, path+[j])dfs(1, path)return res
括号生成
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
输入:n = 3
输出:[
“((()))”,
“(()())”,
“(())()”,
“()(())”,
“()()()”
]
class Solution:def generateParenthesis(self, n):# 先把所有组合给生成出来,即DFS所有节点,发现有一些结果是我们不需要的,比如((((,比如))))if n <= 0:return []res = []def dfs(paths):if len(paths) == n * 2: # 因为括号都是成对出现的res.append(paths)return# 这时我增加了left与right参数,分别代表左括号与右括号的数量,每生成一个我就增加一个。dfs(paths + '(')dfs(paths + ')')dfs('')return res## 上面是全排列,下面添加剪枝条件class Solution:def generateParenthesis(self, n):if n <= 0:return []res = []def dfs(paths, left, right):if left > n or right > left:returnif len(paths) == n * 2: # 因为括号都是成对出现的res.append(paths)returndfs(paths + '(', left + 1, right)dfs(paths + ')', left, right + 1)dfs('', 0, 0)return res
有效的括号(不是DFS,属于栈)
给定一个只包括 ‘(‘,’)’,’{‘,’}’,’[‘,’]’ 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
输入:s = “()”
输出:true
输入:s = “()[]{}”
输出:true
输入:s = “(]”
输出:false
class Solution(object):def isValid(self, s):stack = []left = ['{', '[', '(']for c in s:if c in left:stack.append(c)else:if not stack:return Falsetemp = stack.pop()if c == ')':if temp != '(':return Falseif c == ']':if temp != '[':return Falseif c == '}':if temp != '{':return Falsereturn stack == []
最长有效括号(不是DFS,属于栈)
给你一个只包含 ‘(‘ 和 ‘)’ 的字符串,找出最长有效(格式正确且连续)括号子串的长度。
输入:s = “(()”
输出:2
解释:最长有效括号子串是 “()”
输入:s = “)()())”
输出:4
解释:最长有效括号子串是 “()()”
class Solution(object):def longestValidParentheses(self, s):# 压栈if not s:return 0res = 0# 入栈条件为1.栈为空 2.当前字符是'(' 3.栈顶符号位')',因为三种条件都没办法消去成对的括号。stack = [-1]for i in range(len(s)):if s[i] == "(":stack.append(i)else:stack.pop()if not stack:stack.append(i)else:res = max(res, i-stack[-1])return res
矩阵中的路径
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。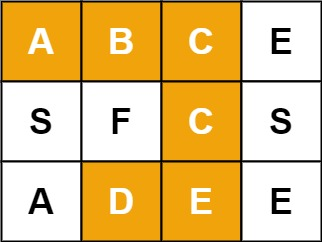
例如,在下面的 3×4 的矩阵中包含单词 “ABCCED”(单词中的字母已标出)。
输入:board = [[“A”,”B”,”C”,”E”],[“S”,”F”,”C”,”S”],[“A”,”D”,”E”,”E”]], word = “ABCCED”
输出:true
输入:board = [[“a”,”b”],[“c”,”d”]], word = “abcd”
输出:false
class Solution(object):def exist(self, board, word):def dfs(board, i, j, word):if len(word) == 0: # 如果单词已经检查完毕return True# 如果路径出界或者矩阵中的值不是word的首字母,返回Falseif i < 0 or i >= len(board) or j < 0 or j >= len(board[0]) or word[0] != board[i][j]:return False# 标记一下,代表此元素已访问过,防止之后搜索时重复访问。tmp = board[i][j]board[i][j] = '#'# 上下左右四个方向搜索res = dfs(board, i+1, j, word[1:]) or dfs(board, i-1, j, word[1:]) or dfs(board, i, j+1, word[1:]) or dfs(board, i, j-1, word[1:])# 还原当前矩阵元素board[i][j] = tmpreturn resfor i in range(len(board)):for j in range(len(board[0])):if dfs(board, i, j, word):return Truereturn False
岛屿数量
给你一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
输入:grid = [
[“1”,”1”,”1”,”1”,”0”],
[“1”,”1”,”0”,”1”,”0”],
[“1”,”1”,”0”,”0”,”0”],
[“0”,”0”,”0”,”0”,”0”]
]
输出:1
输入:grid = [
[“1”,”1”,”0”,”0”,”0”],
[“1”,”1”,”0”,”0”,”0”],
[“0”,”0”,”1”,”0”,”0”],
[“0”,”0”,”0”,”1”,”1”]
]
输出:3
class Solution(object):def numIslands(self, grid):# 方法一:深度优先遍历DFS,这种好理解def dfs(grid, i, j):if not 0 <= i < len(grid) or not 0 <= j < len(grid[0]) or grid[i][j] == '0':return# 将岛屿所有节点删除,以免之后重复搜索相同岛屿grid[i][j] = '0'dfs(grid, i + 1, j)dfs(grid, i, j + 1)dfs(grid, i - 1, j)dfs(grid, i, j - 1)count = 0for i in range(len(grid)):for j in range(len(grid[0])):if grid[i][j] == '1':# 从 (i, j) 向此点的上下左右 (i+1,j),(i-1,j),(i,j+1),(i,j-1) 做深度搜索dfs(grid, i, j)count += 1return count# 方法二:广度优先遍历 BFSdef bfs(grid, i, j):queue = [[i, j]]while queue:[i, j] = queue.pop(0)if 0 <= i < len(grid) and 0 <= j < len(grid[0]) and grid[i][j] == '1':grid[i][j] = '0'queue += [[i + 1, j], [i - 1, j], [i, j - 1], [i, j + 1]]count = 0for i in range(len(grid)):for j in range(len(grid[0])):if grid[i][j] == '0':continuebfs(grid, i, j)count += 1return count
迷路的机器人
设想有个机器人坐在一个网格的左上角,网格 r 行 c 列。机器人只能向下或向右移动,但不能走到一些被禁止的网格(有障碍物)。设计一种算法,寻找机器人从左上角移动到右下角的路径。网格中的障碍物和空位置分别用 1 和 0 来表示。
输入:
[
[0,0,0],
[0,1,0],
[0,0,0]
]
输出: [[0,0],[0,1],[0,2],[1,2],[2,2]]
class Solution(object):def pathWithObstacles(self, obstacleGrid):stack = []m, n = len(obstacleGrid), len(obstacleGrid[0])# 主要思路是压栈def dfs(x, y):# 出界或者走到障碍物if x < 0 or x == n or y < 0 or y == m or obstacleGrid[y][x] == 1:return False# 添加到总路径,并标记为走过obstacleGrid[y][x] = 1stack.append([y, x])# 如果走到终点了就直接返回Trueif x == n - 1 and y == m - 1:return True# 向右走if dfs(x + 1, y):return True# 向左走if dfs(x, y + 1):return True# 如果在上面都没有被return,那么清除刚添加的总路径,并返回Falsestack.pop()return Falsedfs(0, 0)return stack
迷宫
mete = [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 0, 1, 1, 1, 0, 0, 0, 0, 1],[1, 0, 0, 1, 0, 1, 0, 1, 0, 1],[1, 0, 1, 0, 0, 0, 0, 1, 0, 1],[1, 0, 1, 0, 1, 0, 1, 1, 0, 1],[1, 0, 0, 0, 1, 1, 1, 1, 0, 1],[1, 0, 1, 0, 0, 0, 0, 0, 0, 1],[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]class Solution(object):# 方法一:深度优先,但是不是最优解def dfs_stack(self, start, end, mete):stack = [start]while stack:now = stack[-1]if now == end:print(stack)return Truex, y = nowmete[x][y] = 2if mete[x - 1][y] == 0:stack.append([x - 1, y])continueelif mete[x][y - 1] == 0:stack.append([x, y - 1])continueelif mete[x + 1][y] == 0:stack.append([x + 1, y])continueelif mete[x][y + 1] == 0:stack.append([x, y + 1])continueelse:stack.pop()return False# 方法二:广度优先,最优解def bfs_queue(self, start, end, mete):def dfs(next_x, next_y):if mete[next_x][next_y] == 0:queue.append([next_x, next_y, len(tmp) - 1]) # 如果不统计路径,这个len(tmp) - 1就没用mete[next_x][next_y] = 2x1, y1 = startqueue = [[x1, y1, -1]] # 如果不统计路径,这个1就没用mete[x1][y1] = 2tmp = []while queue:now = queue.pop(0)tmp.append(now)if now[0:2] == end:# 这段代码统计路径路径# path = []# i = len(tmp) - 1# while i >= 0:# path.append(tmp[i][0:2])# i = tmp[i][2]# path = path[::-1]# print(path)return Truedfs(now[0] - 1, now[1])dfs(now[0], now[1] + 1)dfs(now[0] + 1, now[1])dfs(now[0], now[1] - 1)else:return Falsestart = [1, 1]end = [6, 8]A = Solution()print(A.bfs_queue(start, end, mete))print(A.dfs_stack(start, end, mete))

若有收获,就点个赞吧
0 人点赞
