1. 存储结构与落盘文件
1.1. Database Cluster & Database & Table
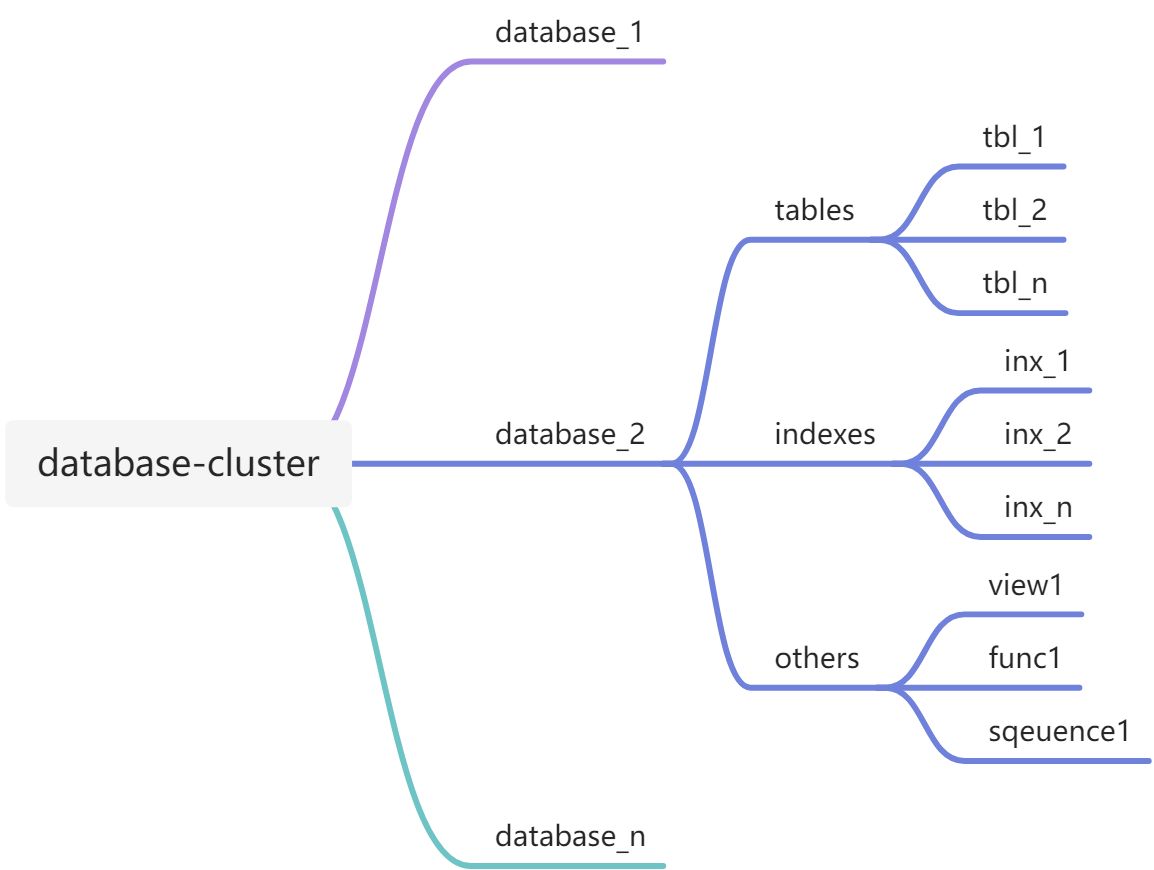
- 在src/bin/initdb编译的initdb进程中,会在指定目录下创建一个db-cluster,也就是PG的home了.
- db-cluster由多个db目录构成,db目录由多个table目录构成,当然还有其他目录,但上述三种目录就是PG基本存储结构了.
1.2. OID
- 所有的database,table,索引等数据库的对象,都有一个唯一标识符 oid
- oid通常对象的物理目录名(通常,不绝对)
- 在 pg_class表中会存储所有对象的oid关系
1.3. 关系(rel,relation)
即文件,数据文件. relfile是PG对数据库目录,表文件等等所有文件的统称.
1.4. 物理存储结构
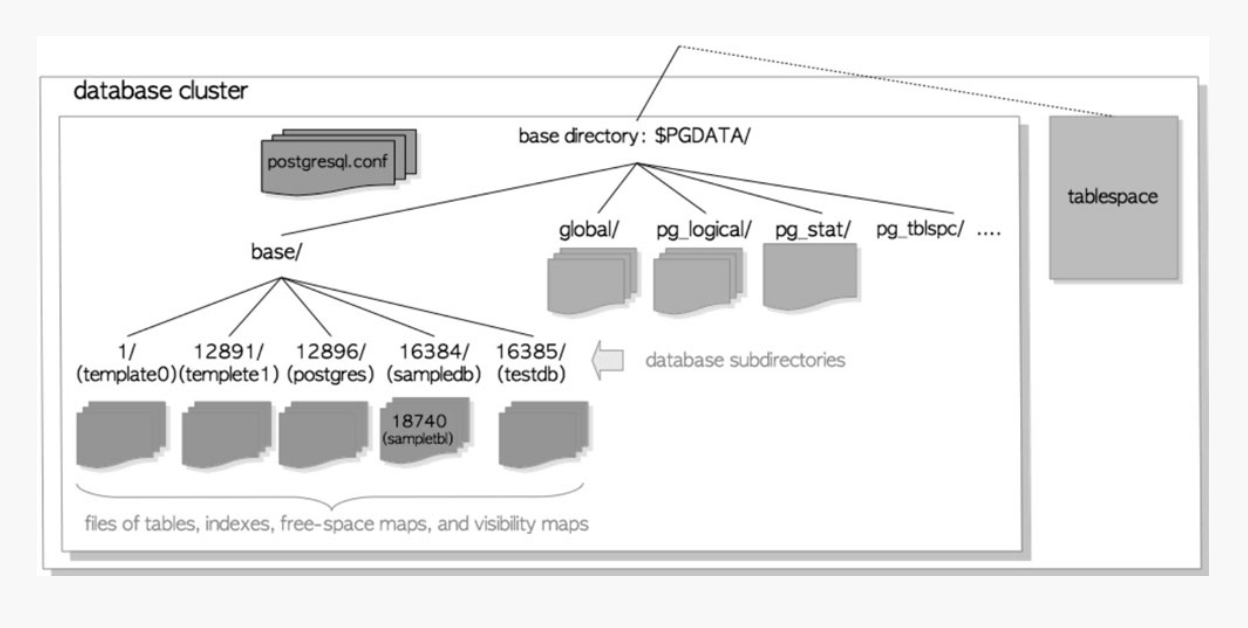
- 全部的文件结构在官方文档中有对目录及其作用的详细描述,此处不赘述,此处重点讲下base目录下的存储
- base/下每一个子目录名称是oid,对应一个db
- base/oid(db)/下每个oid名称的文件就是Table或者index
表文件或索引文件默认大小为1GB,超过1GB则会创建 [oid].1, [oid].2, [oid].n 文件
$ cd $PGDATA$ ls -la -h base/16384/19427*-rw------- 1 postgres postgres 1.0G Apr 21 11:16 data/base/16384/19427-rw------- 1 postgres postgres 45M Apr 21 11:20 data/base/16384/19427.1...
文件名其实并非是oid,而是relfilenode,在第一次创建时 oid === relfilenode,如果文件通过诸如: TRUNCATE,REINDEX,CLUSTER等命令,则会创建一个新的relfilenode并删除旧的,此时oid不会变,但文件名变了.
sampledb=# TRUNCATE sampletbl;TRUNCATE TABLEsampledb=# SELECT relname, oid, relfilenode FROM pg_class WHERE relname = 'sampletbl';relname | oid | relfilenode-----------+-------+-------------sampletbl | 18740 | 18812(1 row)
每个表都有两个与之关联的文件,后缀分别为_fsm 和_vm。这些实际上是空闲空间映射和可见性映射文件
- 主体数据文件、空闲空间映射文件、可见性映射文件等,也被称为相应关系的分支(fork)
- 空闲空间映射是表/索引数据文件的第一个分支(分支编号为1),可见性映射表是数据文件的第二个分支(分支编号为2),数据文件的分支编号为0。
$ cd $PGDATA$ ls -la base/16384/18751*-rw------- 1 postgres postgres 8192 Apr 21 10:21 base/16384/18751-rw------- 1 postgres postgres 24576 Apr 21 10:18 base/16384/18751_fsm-rw------- 1 postgres postgres 8192 Apr 21 10:18 base/16384/18751_vm
1.5. 表文件存储结构
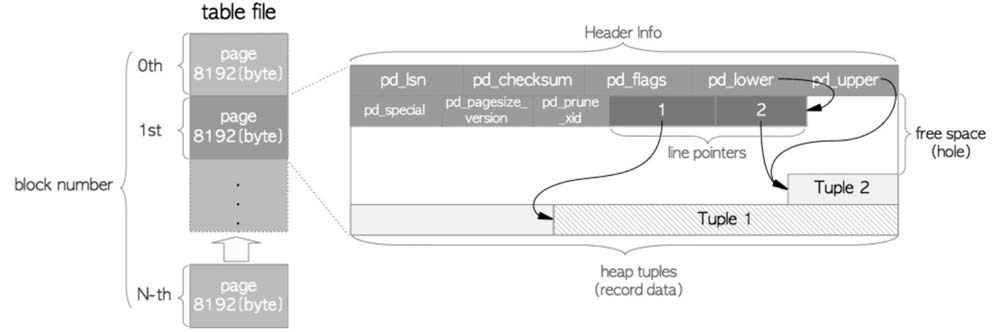
- 以上结构不止是表文件而是所有数据文件比如索引文件等,都是这种结构
- 一个table file由多个page/block组成,每个大小默认8192
- page id从0开始编号
- 每个page由一个Header,一连串行指针数组,以及从尾部堆叠起来的tuple组成
- 行指针数组元素大小为int32
- lp_off(15b):tuple在页中的相对偏移
- lp_flags(2b):tuple的状态
- 0: LP_UNUSED lp_len === 0
- 1: LP_USED lp_len > 0
- 2:LP_REDIRECT 重定向, lp_len === 0
- 3: LP_DEAD 标记元组无效
- lp_len(15b): 元组长度
- Header字段,24B,在代码src/include/storage/bufpage.h中有定义和注释,此处讲几个重要的
- pd_lsn: WAL的安全偏移量
- pd_lower:空闲空间的最低位,也就是行指针数组的末尾
- pd_upper:空闲空间的最高位,也就是最新的元组的首地址
- pd_special:在表文件中指向末尾,无意义,在索引中指向特殊区域例如B+树起始位置
- 可见,页大小最小为64B,即Header+空闲空间+最小tuple大小
- 页大小最大为32KB,因为lp_off与lp_len为15位
- 元组在内部会有一个 TID(Tuple Id), 由一对值组成:
- 写操作:
- 写tupe: put(pd_upper-newTuple.len, newTuple, newTuple.len)
- 写行指针: put(pd_lower, pd_upper-newTuple.len, 4)
- 更新pd_upper: pd_upper-=newTuple.len
- 更新pd_lower: pd_lower+=4
- 更新header其他值,例如checksum,lsn等,此处略
读操作:
- 顺序读: 遍历行指针数组,直到找到目标
- 索引读: 从B+树中通过索引Key找到TID,TID直接找到行指针,然后读取tuple
-
2. 元组详解
2.0. 元组数据结构
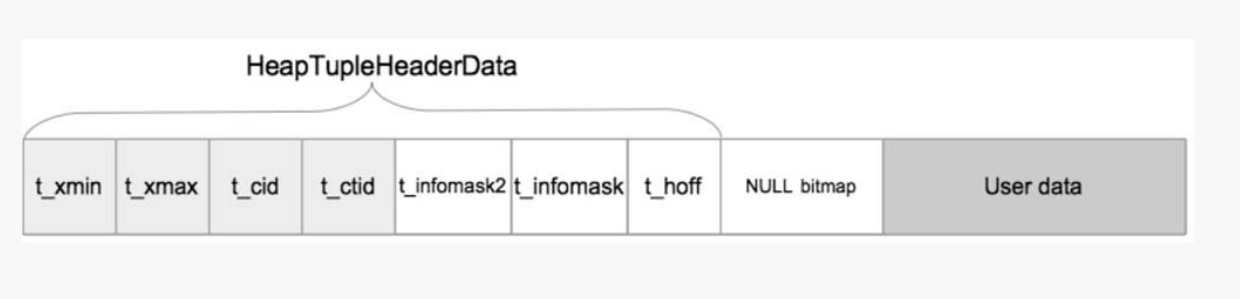
在src/include/access/htup_details.h中定义: ```c typedef struct HeapTupleFields { TransactionId t_xmin; / inserting xact ID / TransactionId t_xmax; / deleting or locking xact ID /union { CommandId t_cid; / inserting or deleting command ID, or both / TransactionId t_xvac; / old-style VACUUM FULL xact ID / } t_field3; } HeapTupleFields;
typedef struct DatumTupleFields { int32 datumlen; / varlena header (do not touch directly!) /
int32 datum_typmod; /* -1, or identifier of a record type */Oid datum_typeid; /* composite type OID, or RECORDOID */
} DatumTupleFields;
struct HeapTupleHeaderData { union { HeapTupleFields t_heap; DatumTupleFields t_datum; } t_choice;
ItemPointerData t_ctid; /* current TID of this or newer tuple (or a* speculative insertion token) *//* Fields below here must match MinimalTupleData! */
define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK2 2
uint16 t_infomask2; /* number of attributes + various flags */
define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK 3
uint16 t_infomask; /* various flag bits, see below */
define FIELDNO_HEAPTUPLEHEADERDATA_HOFF 4
uint8 t_hoff; /* sizeof header incl. bitmap, padding *//* ^ - 23 bytes - ^ */
define FIELDNO_HEAPTUPLEHEADERDATA_BITS 5
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs *//* MORE DATA FOLLOWS AT END OF STRUCT */
};
<a name="BHAyD"></a>### 2.1. 插入| Tuple | t_xmin | t_xmax | t_cid | t_ctid | data || --- | --- | --- | --- | --- | --- || 1 | 99 | 0 | 0 | (0,1) | "A" |- txId=99的事务插入元组1- t_xmax=0,表示此元组为删除或更新- t_cid=0,表示此元组是Tx(99)的第一条操作命令- t_ctid=(0,1),元组指针指向自己,说明自己是最新版本<a name="6yQX8"></a>### 2.2. 删除| Tuple | t_xmin | t_xmax | t_cid | t_ctid | data || --- | --- | --- | --- | --- | --- || 1 | 99 | 100 | 0 | (0,1) | "A" |- 将t_xmax字段更新为删除此元组的txId- Tx(100)提交后,此元组不再需要,即称为了Dead Tuple- Dead Tuple在VACUUM阶段会被清除<a name="ONSu0"></a>### 2.3. 更新**更新相当于先删除在插入****同一事务中两次更新同一字段(第一次)**| Tuple | t_xmin | t_xmax | t_cid | t_ctid | data || --- | --- | --- | --- | --- | --- || 1 | 99 | 100 | 0 | (0,2) | "A" || 2 | 100 | 0 | 0 | (0.2) | "B" |**同一事务中两次更新同一字段(第二次)**| Tuple | t_xmin | t_xmax | t_cid | t_ctid | data || --- | --- | --- | --- | --- | --- || 1 | 99 | 100 | 0 | (0,2) | "A" || 2 | 100 | 100 | 0 | (0.3) | "B" || 3 | 100 | 0 | 1 | (0.3) | "C" |- 删除元组1,即更新元组1的t_xmax为100(在Tx(100)中删除的)- 插入元组2,更新元组1的t_ctid表示有更新的版本(元组1指向元组2)- 元组2的字段与元组1第一次插入时一样---- 删除元组2,即更新元组2的t_xmax为100(在Tx(100)中删除的)- 插入元组3,更新元组2的t_ctid表示有更新的版本(元组2指向元组3)- 元组3的t_cid为1因为是Tx(100)的第二个操作命令- t_ctid指向自己表示最新版本<a name="sXuRD"></a>## 3. VACUUM—清理过程清理过程的主要目标如下:- 清除dead tuple- 以页为单位清除,并将live tuple碎片处理- 移除dead tuple的索引- 冻结旧的事务标识- 冻结旧元组的事务标识- 更新相关视图(即 pg_database & pg_class)- 移除不需要的事务日志- 更新元信息- 更新空闲空间映射(FSM)和可见性映射(VM)- 更新统计信息(诸如pg_stat_all_tables等)<a name="NDJyY"></a>### 3.1. 并发清理过程伪代码每个线程同时处理一张表```sql(1) FOR each table(2) 在目标表上获取 ShareUpdateExclusiveLock 锁/* 第一部分 */(3) 扫描所有页面,定位死元组,如有必要,冻结过早的元组(4) 如果存在,移除指向死元组的索引元组/* 第二部分 */(5) FOR each page of the table(6) 移除死元组,重排本页内的活元组(7) 更新 FSM 与 VMEND FOR/* 第三部分 */(8) 如果可能,截断最后的页面(9) 更新系统数据字典与统计信息释放ShareUpdateExclusiveLock锁END FOR/* 后续处理 */(10) 更新统计信息与系统数据字典(11) 如果可能,移除非必要的文件及CLOG中的文件
(1)从指定的表集中依次处理每一张表。 (2)获取表上的ShareUpdateExclusiveLock锁,此锁允许其他事务对该表进行读取。 (3)扫描表中所有的页面,以获取所有的死元组,并在必要时冻结旧元组。 (4)删除指向相应死元组的索引元组(如果存在)。 (5)对表的每个页面执行步骤(6)和(7)中的操作。 (6)移除死元组,并重新分配页面中的活元组。 (7)更新目标表对应的FSM与VM。 (8)如果最后一个页面没有任何元组,则截断最后一页。 (9)更新与目标表清理过程相关的统计数据和系统视图。 (10)更新与清理过程相关的统计数据和系统视图。 (11)如果可能,移除CLOG中非必要的文件与页面。
3.2. 可见性映射VM在VACUUM中的作用
- 可见性映射文件与表文件对应,记录了表文件中每个页的可见性
- 页的可见性包含了页是否含有死元组
- 如果某页不包含死元组,则VACUUM就可以跳过此页
3.3. 事务的冻结
详见《三、事务》部分
3.4. 自动清理守护进程
PG有个守护进程可配置时间,自动触发VACUMM.
3.5. 完整清理
- 类似JVM复制算法的FullGC,
- 创建一个新的表文件将所有活元组复制到临时空间,
- 删除老的关系文件,重新构建索引, VM, FSM
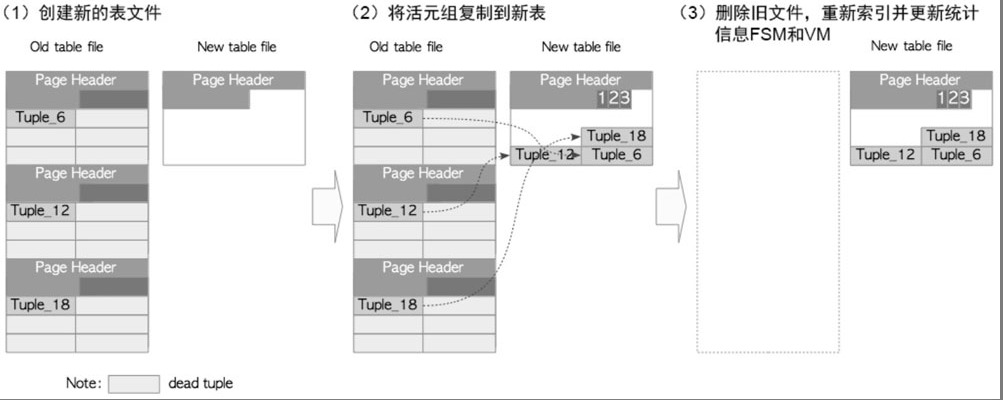
- 类似FullGC,在老文件中大量页的元组被大量清除时,此时大多数的页的FSM空间空间都很高(90%以上), 此时可以触发Full-VACUMM.(Full-VACUMM是主动触发的).
- Full-VACUMM会对相应的表上一个全局排他锁
- 最多使用2倍磁盘空间

若有收获,就点个赞吧
0 人点赞
