0. 前言
上一篇文章简要概述了PostgreSQL(简称PQ)存储引擎进程(即postmaster根据每个Client连接创建的postgres子进程)的初始化流程.分析的比较简单因为重点不在其多进程架构设计,以后会完善上一篇文章,本篇将详细重点分析存储底层原理,讲述postgres子进程在启动并初始化完成后,执行query的原理.
本篇依然会跳过SQL解析原理分析,待以后研究时重开一篇文章详细概述.
本篇所有解析的前提是,一个SQL语句已经被解析成执行计划.
故本篇将要解析的目标为:
- 执行计划的执行流程(包含DML和DQL)
- 脏数据的生成
- 脏数据缓存
- 脏数据刷盘
- WAL原理等
1. 后端的处理流程
下面看看数据库引擎postgres子进程的处理概要。Backend Process(简称backend)的main函数是PostgresMain (tcop/postgres.c)。
- 接收前端发送过来的查询(SQL字符串)
- SQL文是单纯的文字,电脑是认识不了的,所以要转换成比较容易处理的内部形式构文树parser tree,这个处理的称为构文解析。构文解析的模块称为parser.这个阶段只能够使用文字字面上得来的信息,所以只要没语法错误之类的错误,即使是select不存在的表也不会报错。这个阶段的构文树被称为raw parse tree. 构文处理的入口在raw_parser (parser/parser.c)。
- 构文树解析完以后,会转换为查询树(Query tree)。这个时候,会访问数据库,检查表是否存在,如果存在的话,则把表名转换为OID。这个处理称为分析处理(Analyze), 进行分析处理的模块是analyzer。 另外,PostgreSQL的代码里面提到构文树parser tree的时候,更多的时候是指查询树Query tree。分析处理的模块的入口在parse_analyze (parser/analyze.c)
- PostgreSQL还通过查询语句的重写实现视图(view)和规则(rule), 所以需要的时候,在这个阶段会对查询语句进行重写。这个处理称为重写(rewrite),重写的入口在QueryRewrite (rewrite/rewriteHandler.c)。
- 通过解析查询树,可以实际生成计划树。生成查询树的处理称为‘执行计划处理’,最关键是要生成估计能在最短的时间内完成的计划树(plan tree)。这个步骤称为’查询优化’(不叫query optimize, 而是optimize), 而完成这个处理的模块称为查询优化器(不叫query optimizer,而是optimizer, 或者称为planner)。执行计划处理的入口在standard_planner (optimizer/plan/planner.c)。
- 按照执行计划里面的步骤可以完成查询要达到的目的。运行执行计划树里面步骤的处理称为执行处理‘execute’, 完成这个处理的模块称为执行器‘Executor’, 执行器的入口地址为,ExecutorRun (executor/execMain.c)
- 执行结果返回给前端。
- 返回到步骤一重复执行。
可以发现本篇想要研究底层存储原理,入口query执行流程中非常底层的位置,也就是Executor
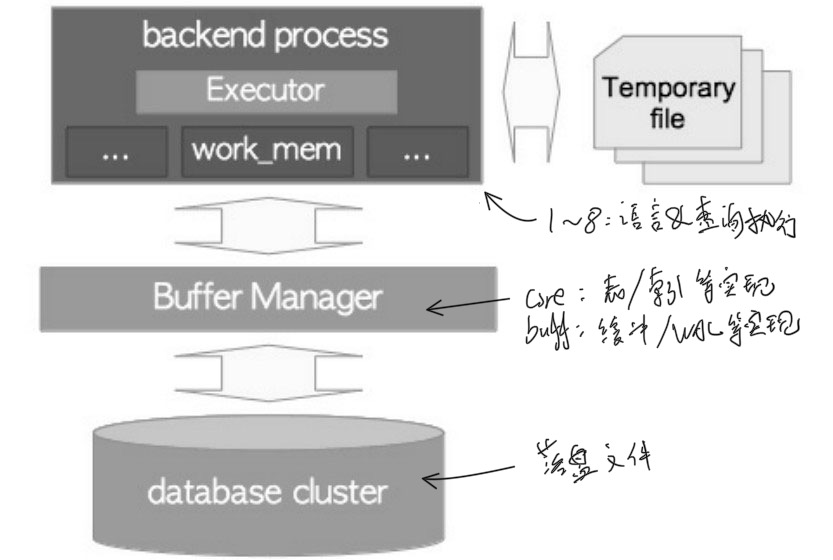
2. 执行计划简述
3. Executor
3.1 ExecutorStart()
ExecutorStart 必须在任何查询计划执行开始时调用 。
3.2 ExecutorRun()
ExecutorRun 接受direction和count两个参数,这些参数指定是否要向前、向后执行计划以及执行多少元组。
在某些情况下,可能会多次调用 ExecutorRun 来处理计划的所有元组。停止执行整个计划也是可以接受的(但仅当它是一个 SELECT 时)。
3.3 ExecutorFinish()
ExecutorFinish 必须在最后的 ExecutorRun 调用之后和 ExecutorEnd 之前调用。这只能在 EXPLAIN 的情况下省略,也确实必须得省略。
4.4 ExecutorEnd()
ExecutorEnd 必须始终在计划执行结束时调用(除非它因错误而中止)。
CRUD简述
脏数据处理
flush
WAL
Schema设计

若有收获,就点个赞吧
0 人点赞
