1.角色
Proposer:提出者(P),提出请求
Acceptor:决策者(A),接收请求按规则返回决策结果
Learner:学习者(L),决策达成后,学习新的决策值
在高并发下的Muti Paxos会在Proposer当中竞选出Leader:领导者(Le),由ta唯一地提出请求。
2.目的和方法
做出决策是根本目的
而决策的本质就是数据的持久化,在分布式中权衡CAP,让决策的内容(数据)达成共识
读:
Paxos重点在写,读很简单,由Client发出读请求,所有分布式节点返回要读的数据,然后Client取“众数”作为读取的值。
写:
下面“过程”会详细介绍
3. 过程
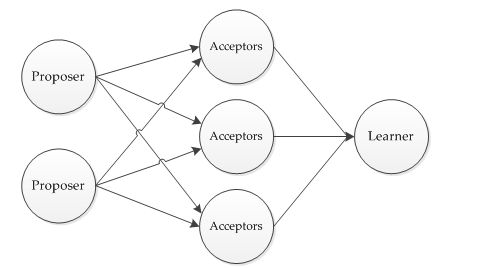
Basic Paxos节点角色的关系如图
1. 需求
当前有两个不同的决策被提出,提出者提出决策,决策携带了决策提案号n和决策值v。
2. 规则
- Prepare: Proposer生成全局唯一且递增的Proposal ID (可使用 时间戳+Server ID),向所有Acceptors发送Prepare请求,这里无需携带提案内容,只携带Proposal ID即可。
- Promise: Acceptors收到Prepare请求后,做出“两个承诺,一个应答”。
两个承诺:
1. 不再接受Proposal ID小于等于(注意:这里是<= )当前请求的Prepare请求。
2. 不再接受Proposal ID小于(注意:这里是< )当前请求的Propose请求。
一个应答:
不违背以前作出的承诺下,回复已经Accept过的提案中Proposal ID最大的那个提案的Value和Proposal ID,没有则返回空值。
- Propose: Proposer 收到多数Acceptors的Promise应答后,从应答中选择Proposal ID最大的提案的Value,作为本次要发起的提案。如果所有应答的提案Value均为空值,则可以自己随意决定提案Value。然后携带当前Proposal ID,向所有Acceptors发送Propose请求。
- Accept: Acceptor收到Propose请求后,在不违背自己之前作出的承诺下,接受并持久化当前Proposal ID和提案Value。
Learn: Proposer收到多数Acceptors的Accept后,决议形成,将形成的决议发送给所有Learners。
3.phase1:Prepare

PA和PB分别提出了(n=2,v=8)和(n=4,v=5)两个决策,横轴是时间AX接收到PA
- AY接收到PA
- AX接收到PB
- AY接收到PB
- AZ接收到PB
- AZ接收到PA
4.phase2:Promise
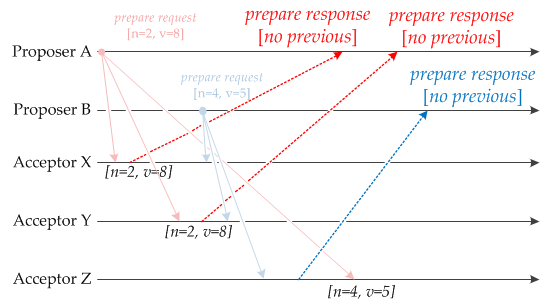
- AX、AY先接收到PA(n=2,v=8),做出承诺并返回已经Accept过的提案中Proposal ID最大的那个提案的Value和Proposal ID,因为没有,所以返回空。
- 同样的,AZ先接收到PB(n=4,v=5),返回空
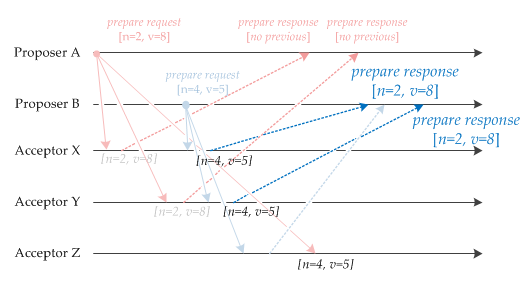
- 接下来AX、AY收到了PB(n=4,v=5),做出承诺并返回已经Accept过的提案中Proposal ID最大的那个提案的Value和Proposal ID(n=2,v=8)
AZ收到了PA(n=2,v=8),由于AZ已经承诺不会再接受Proposal ID<=4的prepare请求,所以不返回
5.phase3:Propose

PB收到了大多数的Promise响应((n/2) +1),于是PB看看自己收到的Promise:
[NULL],[n=2,v=8],[n=2,v=8]
所以PB决定发送Accept Request(n=4,v=8)【当前提案号,收到的最大提案号的值】
- PA页收到了大多数的Promise响应,于是PB看看自己收到的Promise:
[NULL],[NULL]
所以PA决定发送Accept Request(n=2,v=¿)【当前提案号,任意值】
6.phase4:Accept&Learn
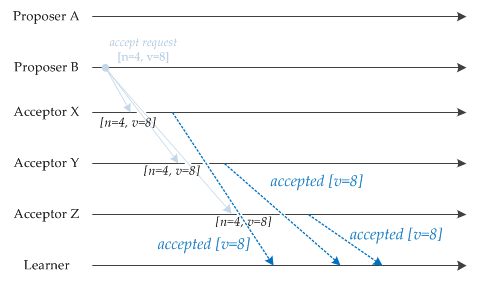
- Acceptors收到了PB的Accept Request(n=4,v=8),符合承诺,持久化存储这个提案(n=4,v=8)
- Acceptors收到了PA的Accept Request(n=2,v=¿),不符合承诺,丢弃
- Acceptors将合法的PB提案(n=4,v=8)的值 v=8 发送给所有Learner,Learner学习
可以再参考下此图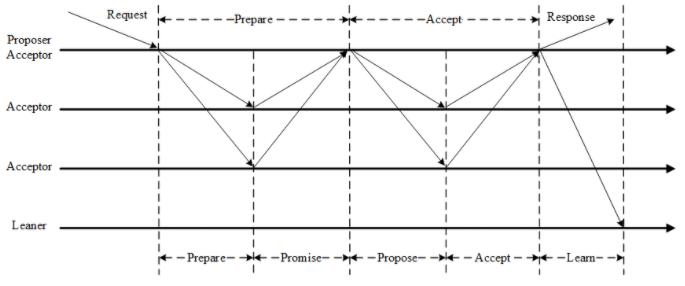
此图Proposer和Acceptor1为同一台机器
4.Multi-Paxos
原始的Paxos算法(Basic Paxos)只能对一个值形成决议,决议的形成至少需要两次网络来回,在高并发情况下可能需要更多的网络来回,极端情况下甚至可能形成活锁。如果想连续确定多个值,Basic Paxos搞不定了。因此Basic Paxos几乎只是用来做理论研究,并不直接应用在实际工程中。
实际应用中几乎都需要连续确定多个值,而且希望能有更高的效率。Multi-Paxos正是为解决此问题而提出。Multi-Paxos基于Basic Paxos做了两点改进:
- 针对每一个要确定的值,运行一次Paxos算法实例(Instance),形成决议。每一个Paxos实例使用唯一的Instance ID标识。
- 在所有Proposers中选举一个Leader,由Leader唯一地提交Proposal给Acceptors进行表决。这样没有Proposer竞争,解决了活锁问题。在系统中仅有一个Leader进行Value提交的情况下,Prepare阶段就可以跳过,从而将两阶段变为一阶段,提高效率。
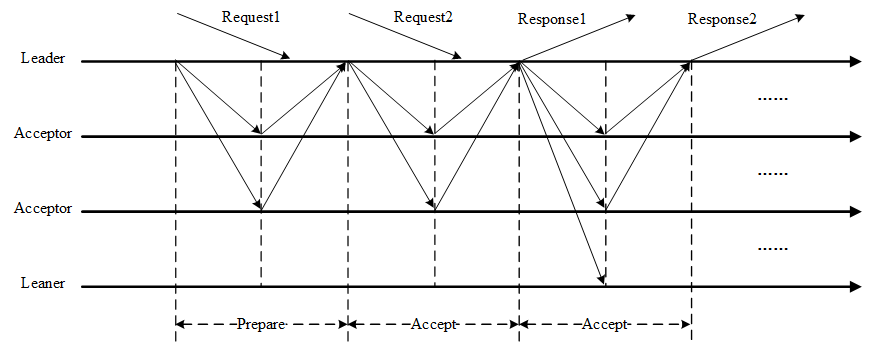
Multi-Paxos首先需要选举Leader,Leader的确定也是一次决议的形成,所以可执行一次Basic Paxos实例来选举出一个Leader。选出Leader之后只能由Leader提交Proposal,在Leader宕机之后服务临时不可用,需要重新选举Leader继续服务。在系统中仅有一个Leader进行Proposal提交的情况下,Prepare阶段可以跳过。
Multi-Paxos通过改变Prepare阶段的作用范围至后面Leader提交的所有实例,从而使得Leader的连续提交只需要执行一次Prepare阶段,后续只需要执行Accept阶段,将两阶段变为一阶段,提高了效率。为了区分连续提交的多个实例,每个实例使用一个Instance ID标识,Instance ID由Leader本地递增生成即可。
Multi-Paxos允许有多个自认为是Leader的节点并发提交Proposal而不影响其安全性,这样的场景即退化为Basic Paxos。
Chubby和Boxwood均使用Multi-Paxos。ZooKeeper使用的Zab也是Multi-Paxos的变形。
我对原著论文分析:
语雀内容

若有收获,就点个赞吧
0 人点赞
