- 1. BufferManager: 与落盘交互的底层内核
- 2. 缓冲锁设计
- define BUF_REFCOUNT_ONE 1
- define BUF_REFCOUNT_MASK ((1U << 18) - 1)
- define BUF_USAGECOUNT_MASK 0x003C0000U
- define BUF_USAGECOUNT_ONE (1U << 18)
- define BUF_USAGECOUNT_SHIFT 18
- define BUF_FLAG_MASK 0xFFC00000U
- define BM_LOCKED (1U << 22) / buffer header is locked /
- define BM_DIRTY (1U << 23) / data needs writing /
- define BM_VALID (1U << 24) / data is valid /
- define BM_TAG_VALID (1U << 25) / tag is assigned /
- define BM_IO_IN_PROGRESS (1U << 26) / read or write in progress /
- define BM_IO_ERROR (1U << 27) / previous I/O failed /
- define BM_JUST_DIRTIED (1U << 28) / dirtied since write started /
- define BM_PIN_COUNT_WAITER (1U << 29) / have waiter for sole pin /
- define BM_CHECKPOINT_NEEDED (1U << 30) / must write for checkpoint /
- define BM_PERMANENT (1U << 31) /* permanent buffer (not unlogged,
1. BufferManager: 与落盘交互的底层内核
1.0. bufferId
- 实际加载到缓冲区的页,会分配一个bufferId,
- 与其说分配,倒不如是可以将缓冲区看做一个数组,每个Slot是一个页,Slot的Index就是bufferId.
1.1. 缓冲区标签
每个文件页在被分配到缓冲区时都会有一个唯一标签,即缓冲区标签,缓冲区标签可以表示所有的关系的页,而将页真正加载到缓冲区后才会有bufferId
结构如下: ```c typedef struct buftag { RelFileNode rnode; / 关系的物理标识 / ForkNumber forNum; / 关系分支编号(0:数据,1:空闲空间映射 …) / BlockNumber blockNum; / 相对于关系开始位置的块号 / } BufferTag;
typedef struct RelFileNode { Oid spcNode; / 表空间 / Oid dbNode; / 数据库 / Oid relNode; / 关系 / }
**举例:**<br />{(16821,16384,37721),1,9}表示: 在表空间 16821的数据库 16384的表37721的1号关系分支(即空间空间映射文件)的第9页.<a name="6dTDl"></a>### 1.3. Backend与BufferManager交互概要**<1> Backend读取页**<br />(1)当读取表或索引页时,后端进程向缓冲区管理器发送请求,请求中带有目标页面的buffer_tag。<br />(2)缓冲区管理器会根据 buffer_tag 返回一个 buffer_id,即目标页面存储在数组中的槽位的序号。如果请求的页面没有存储在缓冲池中,那么缓冲区管理器会将页面从持久存储位置加载到其中一个缓冲池槽位中,然后再返回该槽位的buffer_id。<br />(3)后端进程访问buffer_id对应的槽位(以读取所需的页面)。<br />当后端进程修改缓冲池中的页面时(例如向页面插入元组),这种尚未刷新到持久存储,但已被修改的页面被称为脏页。<br />**<2> 页面置换**<br />8.3以前是LRU,8.3以后用时钟扫描<br />**<3>脏页落盘**<br />在不同情况下通过CheckPoint和flush两个进程刷盘**_PostgreSQL是不支持页不允许直接IO的_**<a name="vGytN"></a>### 1.4. BufferManager的三层架构- 缓冲表 层(buffer table layer), 缓冲描述符层(buffer descriptors layer), 缓冲池(buffer pool layer)- 缓冲表是一个散列表,它存储着页面的buffer_tag 与描述符的buffer_id 之间的映射关系。- 缓冲区描述符是一个由缓冲区描述符组成的数组。每个描述符与缓冲池槽一一对应,并保存着相应槽的元数据。请注意,术语“缓冲区描述符层”只是在本章中为方便起见而使用的术语。- 缓冲池是一个数组。每个槽都存储一个数据文件页,数组槽的索引称为buffer_id。<br />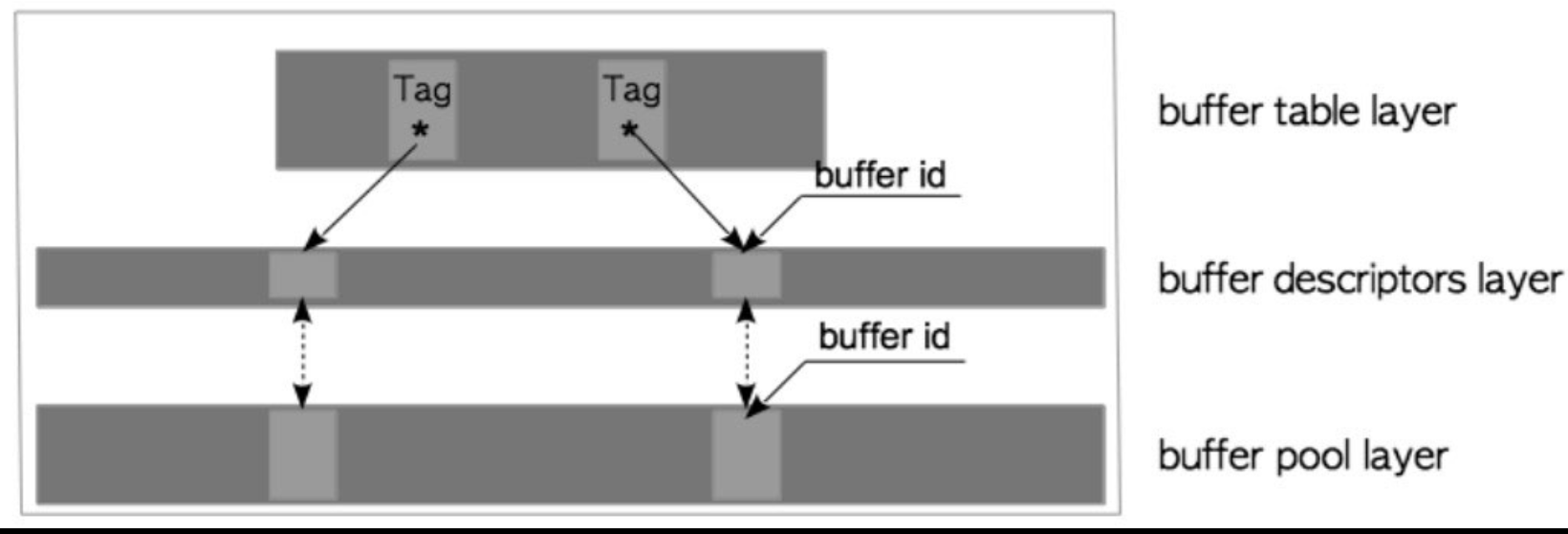**<1> 缓冲表**<br />采用拉链法的HashTable, <Key,Value> => <Buffer_Tag,Buffer_Id>**<2> 缓冲区描述符结构**```c/* src/include/storage/buf_internals.h (before 9.6) *//* 缓冲区描述符的标记位定义(since 9.6)* 注意,TAG_VALID实际上意味着缓冲区散列表中有一条与本tag关联的项目*/#define BM_DIRTY (1 << 0) /* 数据需要写入 */#define BM_VALID (1 << 1) /* 数据有效 */#define BM_TAG_VALID (1 << 2) /* 已经分配标签 */#define BM_IO_IN_PROGRESS (1 << 3) /* 读写进行中 */#define BM_IO_ERROR (1 << 4) /* 先前的I/O失败 */#define BM_JUST_DIRTIED (1 << 5) /* 写之前已经脏了 */#define BM_PIN_COUNT_WAITER (1 << 6) /* 有人等着pin页面 */#define BM_CHECKPOINT_NEEDED (1 << 7) /* 必须在检查点时写入 */#define BM_PERMANENT (1 << 8) /* 永久缓冲(不是unlogged) *//* BufferDesc -- 单个共享缓冲区的共享描述符/共享状态** 注意,读写tag、 flags、 usage_count、refcount、wait_backend_pid等字段时必须持有* buf_hdr_lock锁。buf_id字段在初始化之后再也不会改变,所以不需要锁。freeNext是通过* buffer_strategy_lock来保护的,而不是buf_hdr_lock。LWLocks字段可以自己管好自己* 注意,buf_hdr_lock *不是* 用来控制对缓冲区内数据的访问的** 有一个例外是,如果我们pin了缓冲区,它的标签除了我们自己之外不会被偷偷修改* 所以我们无须锁定自旋锁就可以检视该标签。此外,一次性的标记读取也无须锁定自旋锁,* 当我们期待测试标记位不会改变时,这种做法很常见** 如果另一个后端pin了该缓冲区,我们就无法从磁盘页面上物理移除项目。因此后端需要等待* 所有pin --> unpin。移除时它会得到通知,这是通过将它的PID存到wait_backend_pid,* 并设置BM_PIN_COUNT_WAITER标记位而实现的。就目前而言,每个缓冲区只能有一个等待者** 对于本地缓冲区,我们也使用同样的首部,不过锁字段没用,一些标记位也没用*/typedef struct sbufdesc{BufferTag tag; /* 存储在缓冲区中页面的标识 */BufFlags flags; /* 标记位 */uint16 usage_count; /* 时钟扫描要用到的引用计数 */unsigned refcount; /* 在本缓冲区上持有PIN的后端进程数 */int wait_backend_pid; /* 等着PIN本缓冲区的后端进程PID */slock_t buf_hdr_lock; /* 用于保护上述字段的锁 */int buf_id; /* 缓冲的索引编号 (从0开始) */int freeNext; /* 空闲链表中的链接 */LWLockId io_in_progress_lock; /* 等待I/O完成的锁 */LWLockId content_lock; /* 访问缓冲区内容的锁 */} BufferDesc;
<3> 缓冲区描述符层
- 描述符层介于映射层(缓冲表)与缓冲层之间,管理缓冲层并翻译映射层(缓冲表)
- 描述符层为上述的数据结构为一页的描述,多页的描述共同构成一个数组,数组长度与缓冲层的数组长度一致
- 初始化时缓冲层数组内所有页描述都标记为空格,并且有一个FreeList链表指向数组
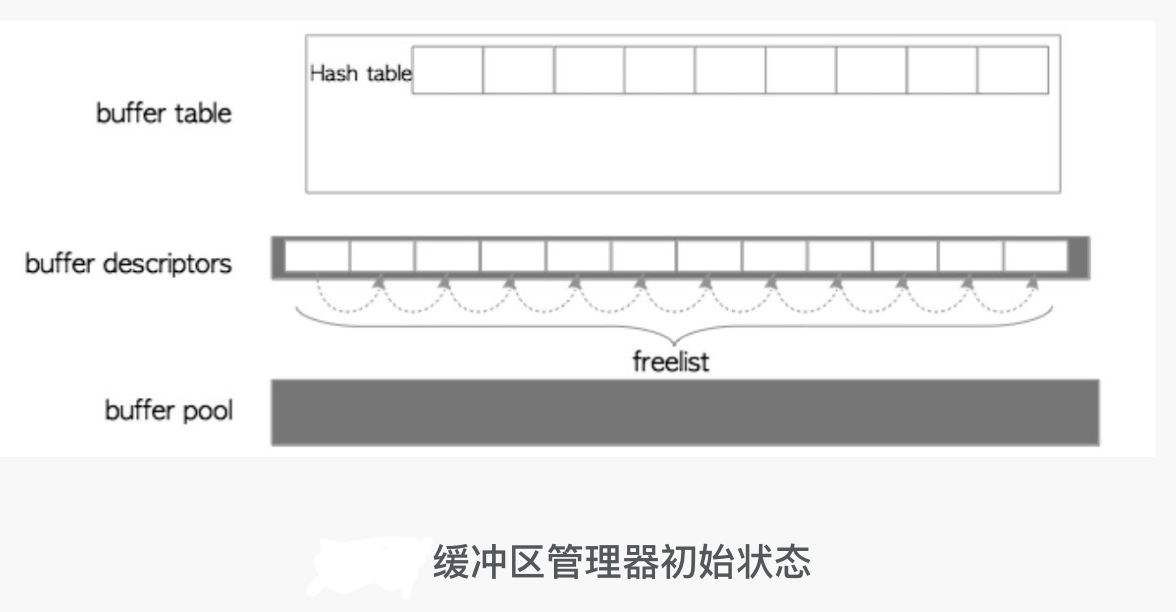
- 请求一个页的流程(即缺页异常): 不考虑页逐出
- 映射层(缓冲表)通过Tag查不到对应的描述符Id,故此页未加载
- 开始加载新页, 从FreeList的head处拿到一个空闲页, pin(page)
- pin(page) —> page:{refcount++, usagecount++}
- 在映射层(缓冲表)put(tag,id)
- 将对应的页从文件中加载到缓冲区
- 将元数据更新到对应的描述符数据结构中
<4> 缓冲区(池)
缓冲区就是一个与页大小(8KB)相同的元素组成的数组,下标即buff_id,没啥特别的
2. 缓冲锁设计
2.0 前情提要
- 缓冲表锁
- 映射层的全局轻量锁,可以共享(读锁)或排他(写锁)
- 锁会分段,默认128分区,减少争抢
- 缓冲表自旋锁, 用自旋锁进行原子删除
- 缓冲描述符层锁
- 内容锁(content_lock): 粒度为每个描述符项, 类型为读(读取页)/写(插入元组,移除元组,冻结元组)锁
- IO锁: 在load/flush页面时,上此锁
自旋锁:修改描述符的大部分元数据字段(例如refcount, usage_count, 脏位等标记位)使用自旋锁
2.2. 原子操作替代锁(9.2版本以后的改动)
将ref_count,usage_count,flags,以及除了content_lock外的所有锁,全部集中到一个 atomic_int32里面 ```c /
/*
Flags for buffer descriptors /
define BM_LOCKED (1U << 22) / buffer header is locked /
define BM_DIRTY (1U << 23) / data needs writing /
define BM_VALID (1U << 24) / data is valid /
define BM_TAG_VALID (1U << 25) / tag is assigned /
define BM_IO_IN_PROGRESS (1U << 26) / read or write in progress /
define BM_IO_ERROR (1U << 27) / previous I/O failed /
define BM_JUST_DIRTIED (1U << 28) / dirtied since write started /
define BM_PIN_COUNT_WAITER (1U << 29) / have waiter for sole pin /
define BM_CHECKPOINT_NEEDED (1U << 30) / must write for checkpoint /
define BM_PERMANENT (1U << 31) /* permanent buffer (not unlogged,
* or init fork) */
typedef struct BufferDesc { BufferTag tag; / ID of page contained in buffer / int buf_id; / buffer’s index number (from 0) /
/ state of the tag, containing flags, refcount and usagecount / pg_atomic_uint32 state;
int wait_backend_pgprocno; / backend of pin-count waiter / int freeNext; / link in freelist chain / LWLock content_lock; / to lock access to buffer contents / } BufferDesc; ```
- 0~17bit: ref_count
- 18~21bit: usage_count
- 22~31bit: flags
3. 环形缓冲
- 场景
- 在一次读取大量页时,默认是读取数据大于缓冲池1/4时会建立256KB的环形缓冲
- 在执行注入COPY FROM等大量数据读取时建立16MB的环形缓冲
- 原理
- 环形缓冲就是一个环形数组
- 环形数组是临时的,为了避免大量页读取造成页逐出风暴导致缓存雪崩
- 环形数组的256KB是L2Cache大小,为了让当前的短时间的读取页更快
- 一般大量数据的读取都是一次性的,短时间很难再用上的
4. 页逐出
采用时钟算法,与MunninPageCache完全一致,此处暂时略.

若有收获,就点个赞吧
0 人点赞
