1. 前言
在看Neo4j代码时,发现有个类很奇特,其类注释占了近50行,然而40行都在介绍一只来自北欧神话奥丁肩上的两只乌鸦之一:Munnin
/*** The Muninn {@link org.neo4j.io.pagecache.PageCache page cache} implementation.* <pre>* ....* .;okKNWMUWN0ko,* O'er Mithgarth Hugin and Munin both ;0WMUNINNMUNINNMUNOdc:.* Each day set forth to fly; .OWMUNINNMUNI 00WMUNINNXko;.* For Hugin I fear lest he come not home, .KMUNINNMUNINNMWKKWMUNINNMUNIN0l.* But for Munin my care is more. .KMUNINNMUNINNMUNINNWKkdlc:::::::'* .lXMUNINNMUNINNMUNINXo'* .,lONMUNINNMUNINNMUNINNk'* .,cox0NMUNINNMUNINNMUNINNMUNI:* .;dONMUNINNMUNINNMUNINNMUNINNMUNIN'* .';okKWMUNINNMUNINNMUNINNMUNINNMUNINNMUx* .:dkKNWMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNN'* .';lONMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNWl* .:okXWMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNM0'* .,oONMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNo* .';lx0NMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNMUN0'* ;kKWMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNMWx'* .,kWMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNMXd'* .;lkKNMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNMUNINNMNx;'* .oNMUNINNMWNKOxoc;'';:cdkKNWMUNINNMUNINNMUNINNMUNINNMUNINWKx;'* lkOkkdl:'´ `':lkWMUNINNMUNINNMUNINN0kdoc;'* c0WMUNINNMUNINNMUWx'* .;ccllllxNMUNIXo'* lWMUWkK; .* OMUNK.dNdc,....* cWMUNlkWWWO:cl;.* ;kWO,....',,,.* cNd* :Nk.* cWK,* .,ccxXWd.* dWNkxkOdc::;.* cNNo:ldo:.* 'xo. ..* </pre>* <p>* In Norse mythology, Huginn (from Old Norse "thought") and Muninn (Old Norse* "memory" or "mind") are a pair of ravens that fly all over the world, Midgard,* and bring information to the god Odin.* </p>* <p>* This implementation of {@link org.neo4j.io.pagecache.PageCache} is optimised for* configurations with large memory capacities and large stores, and uses sequence* locks to make uncontended reads and writes fast.* </p>
继续看下去才知道,这个类注释虽然不正经,但是类本身很有意思。
PageCache是Neo4j实现的一套内存缓存映射文件的机制,基于页为单位进行映射以缓存磁盘数据,是不是很眼熟?想到了Linux页缓存?mmap?
2. MunninPageCache构造方法参数
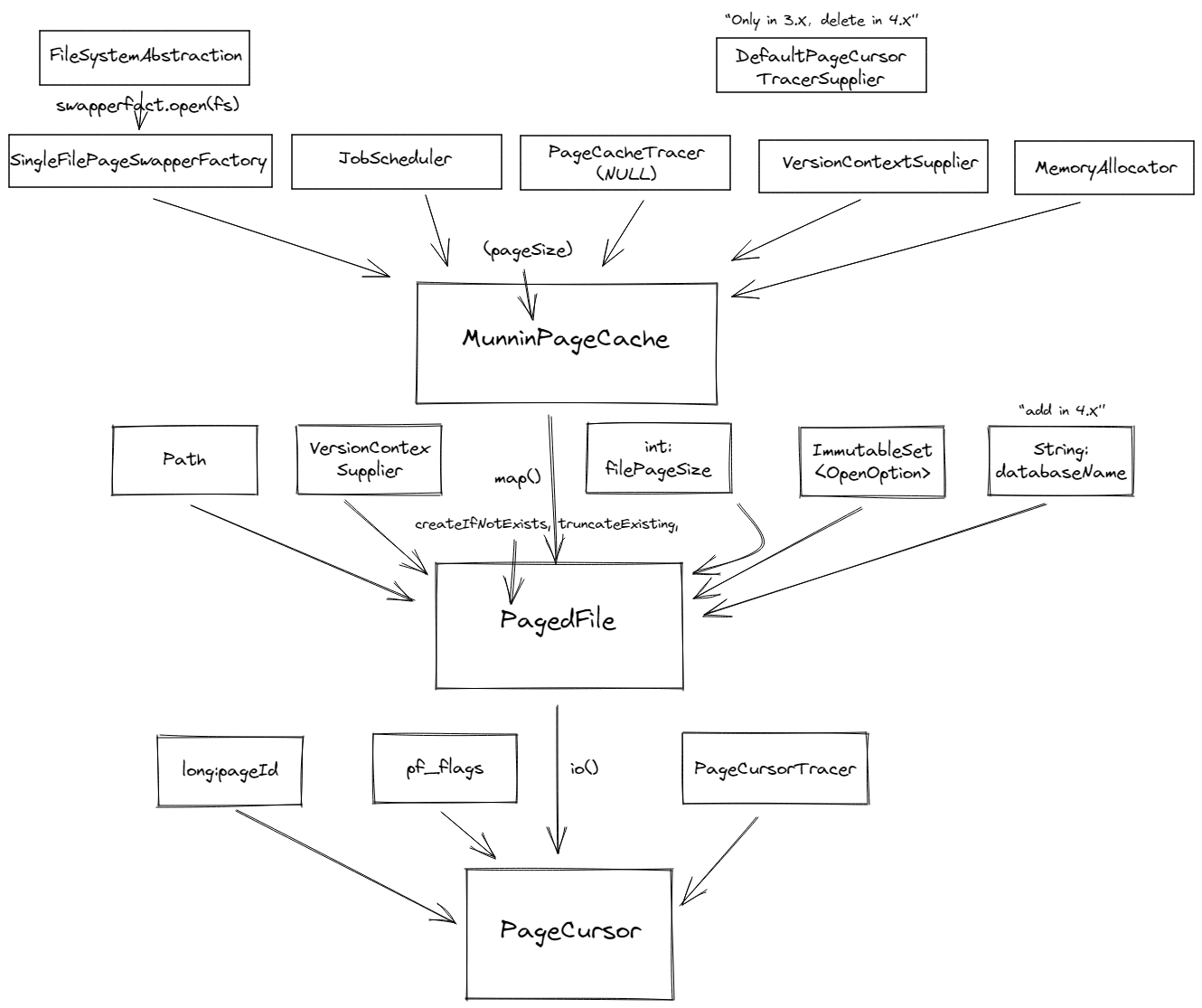
2.1. MunninPageCache
- FileSystemAbstraction:文件操作的抽象,例如mkdir、fileExists等基本操作
- SwapperFactory:实现类:SingleFileSwapperFactory,只有这一个实现类,用于创建Swapper
JobScheduler:Neo4j的一个全局线程池实现模块,通过scheduler.schedule(Group group, //线程组
JobMonitoringParams monitoredJobParams, // 线程描述类<br /> Runnable job) //Task实现<br /> 来快速创建线程
XXXTracer:Neo4j保留的追踪器接口,一般使用PageCache不需要实现Tracer,Tracer接口也有定义好的NULL实现
- MemoryAllactor:Neo4j对Unsafe的Allocate内存相关操作的封装,内含一个Tracer,这样保证内存释放,防止内存泄漏、野指针等
- VersionContextSupplier:Neo4j为了让PageCache适应其事务实现的一个版本检查工具,仅仅是版本检查功能,不包含其他功能,为判断是否回滚等操作提供服务
pageSize:MunninPageCache是以页缓存为底层结构,pageSize默认为 8192Byte
2.2. PagedFile
通过MunninPageCache调用map方法创建PagedFile,是PageCache映射的文件的抽象,类似mmap()函数
Path:文件路径
- filePageSize:这个PagedFile也称之为分页文件,故文件以页为单位分页,文件页大小不大于缓存页
- OpenOption:打开方式,此接口为nio的接口,诸如READ、WRITE、APPEND,是否truncate、createIfNotExists
- BTW:这些被PageCache过滤掉的:
private static final _List
StandardOpenOption.APPEND,
StandardOpenOption.READ,
StandardOpenOption.WRITE,
StandardOpenOption.SPARSE **);
- databaseName:4.X新增,一个命名而已
2.3. PageCursor
PagedFile要访问它,就像nio的FileChannel、DirectByteBuffer一样,需要position进行寻址访问,PageCursor将寻址做到了一个很完善的抽象,调用io()方法创建
- pageId:之前说了PagedFile是分页文件,这里初始化游标可以指定游标的位置在哪一页的header
- pf_flags:
int PF_SHARED_READ_LOCK = 1; // 上读锁int PF_SHARED_WRITE_LOCK = 1 << 1; //上写锁int PF_NO_GROW = 1 << 2;//游标越界时,不允许自动扩张文件大小(扩张页)int PF_READ_AHEAD = 1 << 3;//顺序读信号,优化顺序读int PF_NO_FAULT = 1 << 4;//不允许缺页异常,即缺页不会进行处理int PF_TRANSIENT = 1 << 5; // TBDint PF_EAGER_FLUSH = 1 << 6;//进行实时刷盘,游标离开某页就立刻flush那一页
3. MunninPageCache架构
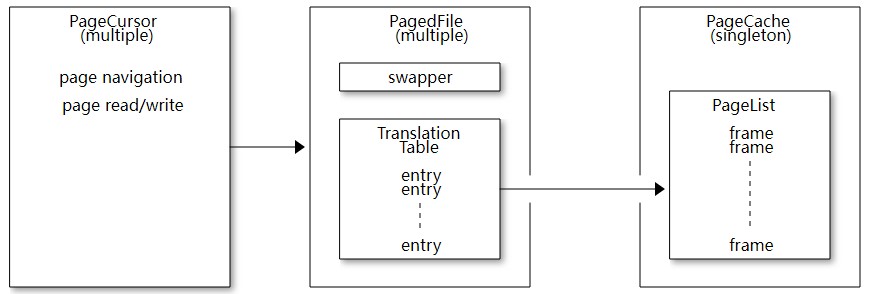
- PageCache:MunninPageCache。是PageCache核心类,其中维护了一个PageList,
- 这些Page就是内存的缓存页,lazy allocate,通过Swapper进行Swap IN 、Swap Out操作,映射文件。
- 每个Page的实现是一个Page frame,仅仅只是一段字节,其中保存了页在堆外内存的物理地址以及Page本身的一些元信息。
- PagedFIle:MunninPagedFile。是PageCache对映射的文件对象实例。
- Swapper在这里得到使用,而PageCache会在PagedFile创建同时创建一个Swapper给它
- TranslateTable是分页文件的文件页对PageCache的缓存页的映射
- PageCursor:MunninPageCursor、MunninReadPageCursor、MunninWritePageCursor。用于访问PagedFile分页文件的文件页,通过页内偏移实现字节级的读写。
4. 关于页缓存相关知识铺垫
这里是对页缓存机制或者说页式内存分配机制的简单诠释,本节中的页与PageCache无关,是OS中的概念
4.1. 什么是页(Page?)
现代操作系统的内存大多按段页式、或纯页式管理,页即为内存的最小单元,再往下就是一个Byte甚至bit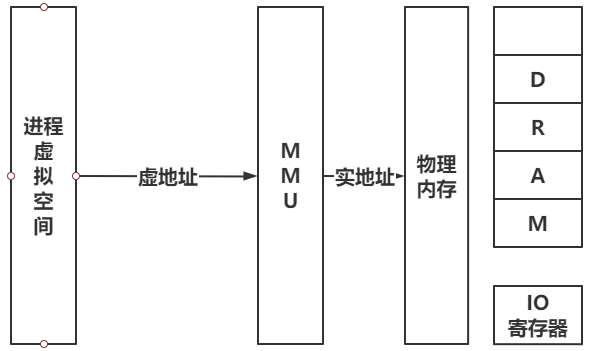
进程访问内存我们知道是虚拟内存地址,通过MMU翻译为实地址也就是物理内存地址来访问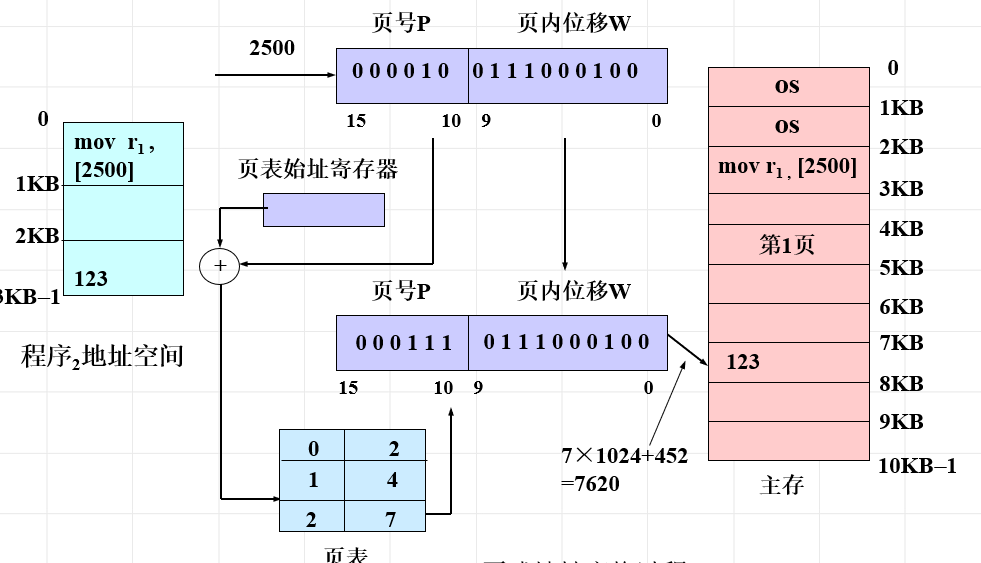
上图描述了一个系统指令 mov r1,2500就是将地址2500的数据传送到r1,这里就触发一次地址转换
- 2500地址二进制前6位是页号,后10位是页内偏移
- 通过页号加上页表地址头找到页表对应PTE,实际页号
- 找到对应物理内存页起始
- 通过偏移量找到对应地址
4.2. 什么是缺页和换页(PageFault?、SWAP?)
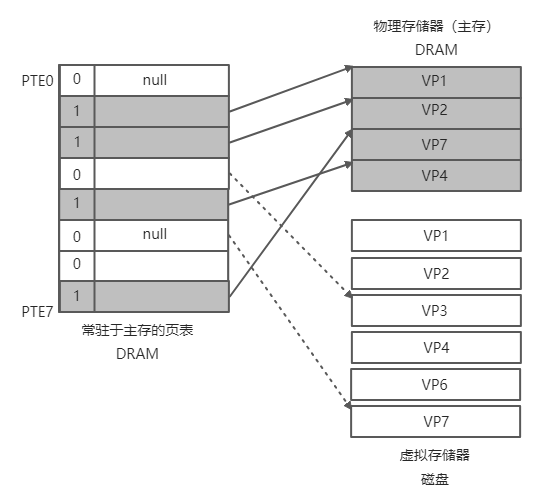
- 我们知道页表映射到了物理页上,此时物理页没有磁盘上的页(磁盘不是页,这里为了方便也这么说,虽然不严谨)大。
- 页表中存储了物理页的情况,此时只有1,2,7,4页在物理内存中,如果要访问3,7等不在物理内存中的,就会引发缺页异常
- 此时缺页异常会通知CPU,先在物理页中选中一个淘汰页(LRU、LFU等)将其驱逐,如果被驱逐的页是脏的,会把脏数据在驱逐前flush到磁盘,这就是SWAP OUT
- 然后把磁盘中对应的页的数据复制到物理内存中,这就是SWAP IN
由此,SWAP就是访问页发现不在内存而引发缺页(PageFault)进而进行的一个换页操作
5. MunninPageCache组件
5.1. 部分名字的解释与替代
Page:指内存中的页,即PageCache的页缓存的页
- FilePage:值分页文件的文件页
- PageFrame:PageList的元素,是一个Page在PageCache中的引用
PageBuffer:指代PageFrame指针指向的内存中的一个Page大小的空间
5.2. PageList
首先PageList在PageCache中其实充当了两个角色:
在PageCache中的页缓存Page
/MunninPageCache.java */ final _PageList pages; _this.pages = _new _PageList( maxPages, cachePageSize, memoryAllocator, _new _SwapperSet(), victimPage, UnsafeUtil.pageSize() );
PagedFile的FilePageList:其实PagedFile继承了PageList类
/MunninPagedFile.java */ _final class _MuninnPagedFile _extends _PageList _implements _PagedFile, Flushable
PageList的元素是PageFrame,PageFrame包含了PageBuffer的引用,是Lazy Allocate的
- PageId是从0开始的递增Id,通过MemoryAllocator初始化的最大内存占用(可配置百分比或Byte数),与PageSize+PageMetaSize(32Byte,下面PageFrame会详细介绍)计算得到Page数量,然后存储一个lastPageId。保证Page初始化数量不超过lastPageId即可,并不需要初始化一个Page数组或列表,节省空间
5.2.1. PageList内存结构
baseAddress ━┓ ┃ [ [pageframe0][pageframe1][…][pageframen] ] : size = PageMetaSize(32B) * PageCount ┃ ┃ V V [PageBuffer] [PageBuffer] PageBufferSize = 8192B(default & configurable)
5.3. PageFrame
PageList的元素是PageFrame,它由32个Byte组成结构如下
OFFSET_LOCK_WORD [OFF=0,LEN=8]: ┏━ [FLS] Flush lock bit
┃┏━ [EXL] Exclusive lock bit
┃┃┏━ [MOD] Modified bit, raise when write lock, down when flush unlock or page evict
┃┃┃ ┏━ [CNT] Count of currently concurrently held write locks, 17 bits.
┃┃┃ ┃ ┏━ [SEQ] 44 bits for the read lock sequence, incremented ┃┃┃ ┃ ┃ on write & exclusive unlock.
┃┃┃ ┏━━━┻━━━━━━━━━━━━━━━━━━━━━━━┓┏━━┻━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
FEMWWWWW WWWWWWWW WWWWSSSS SSSSSSSS SSSSSSSS SSSSSSSS SSSSSSSS SSSSSSSS
1 2 3 4 5 6 7 8 byte**_OFFSET_ADDRESS [OFF=8,LEN=8]:64bit Address point to page buffer_OFFSET_LAST_TX_ID [OFF=16,LEN=8]:64bit LAST TX ID PAGE_BINDING [OFF=24,LEN=8]: ┏━ [FilePageId] ┏━ [SwapperId] ┏━ [UsageCount] ┏━━┻━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓┏━┻━━━━━━━━━━━━━━━━━┓┏┻━┓ FFFFFFFF_FFFFFFFF_FFFFFFFF_FFFFFFFF_FFFFFFFF_SSSSSSSS_SSSSSSSS_SSSSSUUU 1 2 3 4 5 6 7 8 byte**
PageFrame的get()方法:
long deref( int pageId ){long id = pageId; // convert to long to avoid int multiplicationreturn baseAddress + (id * META_DATA_BYTES_PER_PAGE);}
5.3.1.
5.3.2. PAGE_Binding
- 此字段在PageRef偏移量第24个Byte,长度为64位
由三个字段组成
OffHeapPageLock是PageCache对Page的一系列锁实现(注意与缺页锁LatchMap不是一个锁)
- OffHeapPageLock与常用的ReentrantReadWriteLock不同的是,读锁不是共享锁,而是更低级的乐观锁,写锁不再是独占锁,同样降级为共享锁,增加刷盘锁。且不可重入。
锁有四种:
- 乐观读锁(Optimistic read lock):乐观锁不被排斥,在释放时检查Sequence没变且无任何写锁,否则判为乐观锁失败。在实际使用中,乐观锁释放失败提示用户乐观锁周期读取的数据为坏数据,需要用户重新读取,PageCursor的shouldRetry方法即检查读锁。
- 共享写锁(Shared write lock): 被独占锁排斥,成功时WriteLockCount+1。释放时WriteLockCount-1,Sequence+1,注意写锁不会将写锁标志置为0,因为写锁标志准确来说是脏位。
- 刷盘锁(Flush lock):与刷盘锁互斥,被独占锁排斥。释放锁时,如果本次刷盘成功,且刷盘锁周期内Sequence不变且无写锁(即刷盘锁周期内无写操作)则将写锁标志置0
- 独占锁(Exclusive lock):排斥所有锁
| 锁类型 | 排斥 | 被排斥 | 申请锁
(申请锁前会判断Page是否持有被排斥锁,以下略) | 释放锁
| | —- | —- | —- | —- | —- | | O | \ | \ | 记录当前Seq | 检查当前无写、独占锁,且Seq未变化(读锁周期内无写或逐出) | | S | \ | E | MOD位置1,WriteCount+1 | WriteCount-1,Seq+1 | | F | F | F, E | FLS位置1,CAS返回成功或失败 | FLS位置0,如果刷盘操作成功且Seq不变则将NOD位置0 | | E | S, F, E | S,F,E | EXC位置1,CAS返回成功或失败 | Seq+1,EXL位置0,直接volatile写入 |
锁变化
- 写锁—>刷盘锁
- WriteCount+1
- Seq+1
- 检查无FLS和EXL
- FLS+1
- CAS自旋
- 独占锁—>写锁
- Seq+1
- EXL位置0
- WriteCount+1
- MOD位置1
- volatile写入
- 写锁—>刷盘锁
锁用途
- 读锁:
- 在PageCursor读操作时使用,检查失败则重新读
- 在FlushPages收集(Grab)脏页时通过获取、检查读锁来判断脏页是否持有写锁或独占锁,检查失败则重新Grab
- 写锁:
- PageCursor写操作时使用
- 刷盘锁:
- 刷盘时使用,此处包括:主动刷盘、被动刷盘(即脏页被逐出)
- 独占锁:
- 读锁:
PageSwapper是IO的抽象
- IO抽象逻辑是去模仿Linux的lseek()+pread()/pwrite()
- 基于FileChannel,通过Unsafe绕过FileChannel的positionLock进行并发positioned RW
- 反射(tryMakeUninterruptible)设置FileChannel不因线程interrupt而close,提升并发可用性。若失败,则采用reopen方式保证FileChannel存活
- 在页驱逐成功后调用PageSwapper.eviced回调onEvic()以清除PageFile中translate table相关条目
接口简述: ```java public interface PageSwapper{ //指定filePageId读取指定大小(默认filePageSize)数据到bufferAddress中 long read( long filePageId, long bufferAddress, int bufferLength ) throws IOException;
//指定startFilePageId读取多页指定大小(默认filePageSize)数据到多个bufferAddresses中 //此处是将从startFilePageId开始的连续数据从磁盘读取 long read( long startFilePageId, long[] bufferAddresses, int[] bufferLengths,
int length ) throws IOException;
//从bufferAddress写入指定大小(默认filePageSize)数据到指定filePageId中 long write( long filePageId, long bufferAddress, int bufferLength ) throws IOException;
//从bufferAddresses连续多页写入指定大小(默认filePageSize)数据到 //指定startFilePageId中 //此处是将从startFilePageId开始的连续数据从磁盘写入 long write( long startFilePageId, long[] bufferAddresses, int[] bufferLengths,
int length, int totalAffectedPages ) throws IOException;
//驱逐页后调用 void evicted( long pageId );
//调用FileChannel的force()—>fsync(2) void force() throws IOException;
}
- 参数中,filePageId用于转换为磁盘地址,bufferAddress(es)是PageBuffer(s)的地址- Swapper只能一次读写一页或连续多页,不能在一次读写之内跳页<a name="al5Ng"></a>## 5.5. PagedFiles<a name="brAS2"></a>### 5.5.1. TranslationTable(tt)- 由PageCache管理的PagedFIle被表示为文件页面的顺序列表,从第0页开始,一直到文件的结束。- **文件页翻译表存储的是内存页的索引而非指针,因为索引只用32位,而指针要64位,存索引比存指针少一半内存占用**- tt就是一个int二维数组,结构如下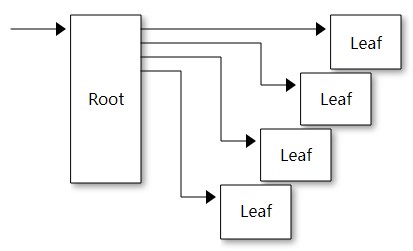- 一级数组称之为Root,Root可扩容,二级数组称之为Leaf,Leaf一旦初始化边不会扩容- Root扩容是将Leaf指针进行Copy-On-Write,这样在并发下,不会影响tt的使用,因为tt的读写操作是发生在filePageId转换为PageId时读操作,更改filePageId映射的PageId位写操作,不会访问到Root,此时新Root与旧Root指向的Leaf为同一个地址,故不会出现并发冲突。```javavolatile int[][] translationTable;public MunninPagedFile{//...//通过filepagesize和文件大小,Swapper会计算需要多少FilePageswapper = swapperFactory.createPageSwapper( path, filePageSize,onEviction, createIfNotExists, useDirectIo );//...//获取到FilePage数量long lastPageId = swapper.getLastPageId();// At least one initial chunk. Always enough for the whole file.int initialChunks = Math.max( 1 + computeChunkId( lastPageId ), 1 );int[][] tt = new int[initialChunks][];for ( int i = 0; i < initialChunks; i++ ){tt[i] = newChunk();}translationTable = tt;//...}
- tt[][]的第二级数组就叫做Chunk
- 一个Chunk默认1<<12,即可以存储4096个FilePage
- 初始化可以看出,tt是将文件按FilePageSize逻辑分页,然后从0页开始写到Chunk中,一直到lastFilePageId,若Chunk写满4096,就换到下一个Chunk
PS:在其文档中提到,非常多的数据结构都采用了volatile和内存屏障(MemoryFence),以及对于一些类的字段操作,比如tt[][]等,都采用了Unsafe操作直接修改,这样做的目的在文中解释道Neo4j想要最大努力减少简介内存访问,也称之为依赖负载(dependent loads)。比如通过index访问ArrayList,你得先获取ArrayList对象的内存地址,然后访问内部的数组。PageCache在设计中很多地方设计都有考虑这一点。
5.5.2. SwapperSet
- 之前提到过,PageList两个实现分别是PagedFile的FilePageList(tt),另外一个PageCache的PageList(pages),pages包含了内存中的所有Page,而这些Page映射着不同的PagedFile,每个PagedFile拥有一个Swapper,但是对于PageCache的pages来说,就是多个Swappers,此时SwapperSet就是方便统一管理的数据结构。
SwapperSet是SwapperId和Swapper对象的映射,结构为:
/* PageList.java */volatile SwapperMapping[] swapperMappings;class SwapperMapping{int id;Swapper swapper;}
因为SwapperSet访问频繁,所以用volatile保证原子性
- 只有在map或unmap时修改Set,用synchronized锁。
- SwapperId为21位,这个大小足矣在消耗完filedescriptors之后才会消耗完SwapperId。但是在未来可能会不足。
- SwapperId在map时+1,在unmap时不会重用SwapperId除非unmap的文件的所有页被逐出,但是文件unmap后不会主动逐出页,且文件重新map进来时这些页也不会重用,因为文件可能更改。
- MunninPageCache实现了free()和vacuum()方法,用于解决上述问题。 free将对应SwapperId标记“墓碑状态”,被调用20次后,free会返回true让调用者考虑可以调用vacuum来进行主动释放SwapperId,通过主动逐出所有与此Id对应Swapper所绑定的页,让SwapperId能够释放并重用
5.6. 缺页异常并发安全——LatchMap
- 核心方法:takeOrAwaitLatch ```java private final Latch[] latches;//默认大小128
private long offset( int index ) { return UnsafeUtil.arrayOffset( index, latchesArrayBase, latchesArrayScale ); }
private Latch getLatch( int index ) { return (Latch) UnsafeUtil.getObjectVolatile( latches, offset( index ) ); }
Latch takeOrAwaitLatch( long identifier ) { //PageId —> latchesIndex,index方法类似一个hash,然后取模(默认大小128) int index = index( identifier ); Latch latch = getLatch( index ); while ( latch == null ) //latch没有被申请过 { latch = new Latch();//创建latch if ( compareAndSetLatch( index, null, latch ) )//CAS到latches { latch.latchMap = this; latch.index = index; return latch; } latch = getLatch( index ); } //如果本线程创建lacth成功,则返回latch表示本线程独占 //如果创建失败即获取到其他线程创建的latch,则进入等待latch被release latch.await(); return null; }
<a name="elCCq"></a>## 5.7. 缺页异常处理(FreeList)1. 流程1. 获取FreePage- FreeList是FreePage的链表- FreeList是一个Object链表,可能是FreePage对象、AtomicInteger或null- 初始阶段是AtomicInteger,记录PageList消耗的Page个数,当全部消耗,证明PageList没有空闲页,此时进入第二阶段- 第二阶段FreeList为FreePage,第二阶段开始时,后台页逐出线程将启动,并尽量维持30个FreePage,缺页异常直接从FreeList中获取FreePage- 第三阶段与第二阶段其实是一个状态,表现为FreeList开始为空,此时需要缺页线程合作驱逐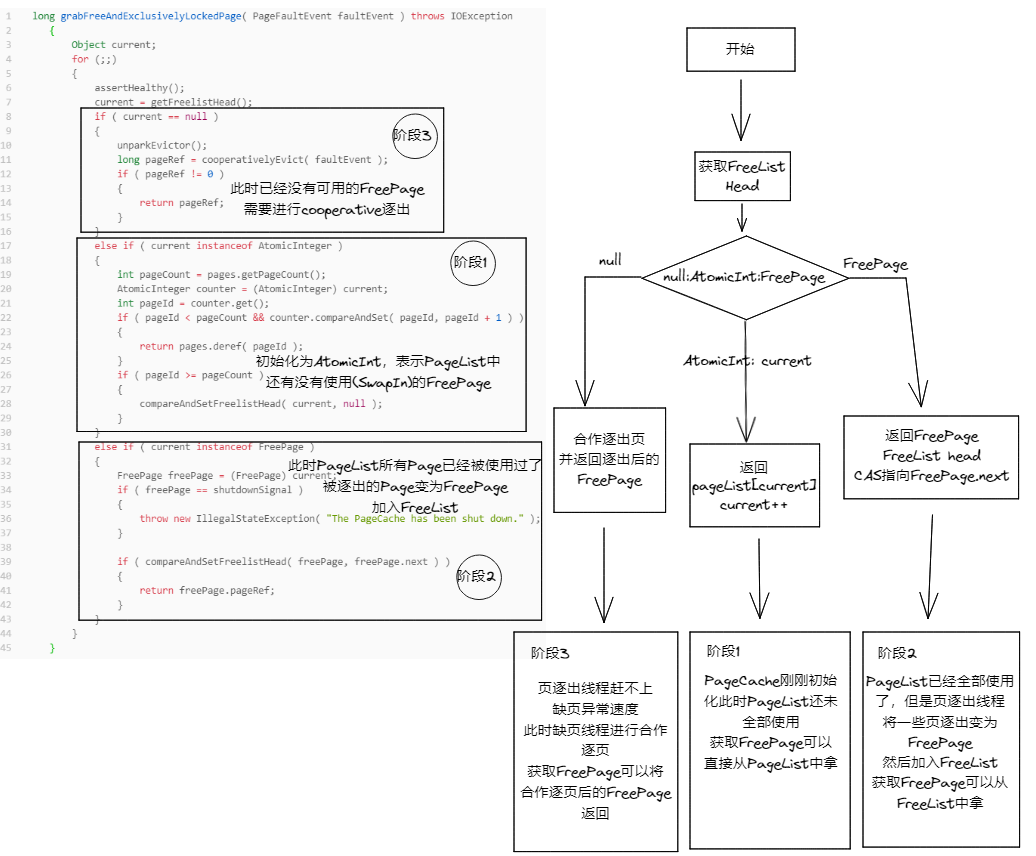<a name="aU2IS"></a>## 5.8. 页面驱逐算法——Clock- 在介绍后台逐出线程前,先介绍一下逐出线程的逐出策略:Clock Arm- 算法是基于环形队列时钟算法的页驱逐机制,目的是尽可能还原LRU且保证CPU占用低。时钟算法是一个常见的处理高并发请求超时计时的算法。通过时钟指针在环形队列游走,每一个指针访问的页,计数器减1,页被访问则加1,驱逐计数0的页。- 如同一个钟一样,指针从0开始旋转一圈回到0,中的每一个刻度就是PageList,指针每指向一个Page就将其UsageCount-1,当UsageCount=0时就会被逐出,PageCursor每次pin到一个页面上,UsageCount+1,最高为41. 为什么是4?在不可预测的随机访问下,Neo4j为了更快地响应FreePage请求更快地逐出页,4这个数字是Neo4j推断出与LRU准确度最接近的参数。2. Clock Arm怎样移动?在环形队列计时器中,Arm是永不停止地定时移动(比如一秒移动一次),计时误差就在一秒之内,以此类推。<br />在PageCache中,则不会进行定时移动,当FreeList小于30时,就开始移动,否则就暂停3. 驱逐线程无法跟上FreePage消耗速度怎么办?在上面FreeList中状态3诠释了这个问题,驱逐线程无法跟上是的FreeList出现null,此时缺页线程会一起加入。逻辑是:为页错误线程随机放置一个Clock指针,和页驱逐线程一样进行游走让页的计数器-1。> **ps:目前来看Clock算法效率还不错,但是缺点是开销大,在环形计时算法中,之所以设定定时移动ClockArm,就是为了降低CPU开销,但是PageCache中Clock是不会定时移动的,在FreeList不大于30时,CPU始终100%。**> **Neo4j未来打算参考_LeanStore_论文中的算法进行优化改进,_LeanStore会追踪cold Pages或逐出候选Pages,而不是跟踪每个页的热度(计时器)_。**<a name="IaIto"></a>## 5.9. 后台页逐出线程```javavoid continuouslySweepPages(){evictionThread = Thread.currentThread();int clockArm = 0;while ( !closed ){//传入30,返回需要驱逐的页面数量//FreeListHead == null返回30//FreeListHead == AtomicInteger返回30 - AtomicInteger//FreeListHead == FreePage返回30 - FreeList.countint pageCountToEvict = parkUntilEvictionRequired( keepFree );//Tracer记录,忽略try ( EvictionRunEvent evictionRunEvent = pageCacheTracer.beginPageEvictions( pageCountToEvict ) ){//逐出(需要驱逐的页面数量,clock指针位置,Tracer记录)clockArm = evictPages( pageCountToEvict, clockArm, evictionRunEvent );}}setFreelistHead( shutdownSignal );}int evictPages( int pageCountToEvict, int clockArm, EvictionRunEvent evictionRunEvent ){while ( pageCountToEvict > 0 && !closed ){if ( clockArm == pages.getPageCount() ){//循环clockArm = 0;}long pageRef = pages.deref( clockArm );//拿到PageFrame// 检查此页还没被逐出 计数器-1,为0返回trueif ( pages.isLoaded( pageRef ) && pages.decrementUsage( pageRef ) ){try{pageCountToEvict--;//注意:这里逐出操作仍然是try,不保证100%逐出成功//可能因为flush抛异常//也可能竞争锁失败if ( pages.tryEvict( pageRef, evictionRunEvent ) ){//成功就清除异常记录,然后将页加入FreeListclearEvictorException();addFreePageToFreelist( pageRef );}}// catch (Exception e)-->Store(e)}clockArm++;}return clockArm;}
何时启动?
- 在第一个文件映射进来,即PagedFile初始化后,线程启动。
- 若PageList的Pages还未没全部使用,FreeList元素为AtomicInteger,线程就会阻塞等待
- 一旦PageList没有可用Page,线程就开始进行逐出,直到有30个FreePage
- FreeList有FreePage计数器,以免遍历整个FreeList计算是否有30个
this.keepFree = Math.min( 30, maxPages / 2 );
何时关闭?
- 线程会持续监控FreeList,直到PageCache关闭,线程都不会关闭
- 为什么要存储异常?
每当执行 IO 时,总是有可能抛出异常。当后台驱逐线程选择要驱逐的页面时,它有时会遇到脏页面。作为驱逐的一部分,必须Flush脏页,因此后台驱逐线程在尝试Flush脏页时可能会遇到异常,此时此页仍然是脏的。
而驱逐线程不会直接抛出异常让线程停止,因为这不会导致数据损坏,仅仅是此次flush失败,最重要的是后台线程异常没有其他方法来处理或向外界传达异常,每次缺页或映射页时会调用assertHealthy进行检查,才会抛出异常(因为这俩操作是用户调用的)。或者等待用户调用flushAndForce成功,则会清除。
5.10. PageCursor
主要接口
//Int,Long Bytespublic abstract void putShort( short value );//Int,Long Bytespublic abstract short getShort();public abstract boolean next() throws IOException;public abstract boolean next( long pageId ) throws IOException;public abstract boolean shouldRetry() throws IOException;public abstract int copyTo( int sourceOffset, PageCursor targetCursor, int targetOffset, int lengthInBytes );public abstract void setOffset( int offset );public abstract int getOffset();
游标在页内访问时是一个与ByteBuffer的position读取很像的机制,页之间的访问则是类似迭代器的模式(next)
游标在初始化时(PagedFile.io(filePageId))永远指向-1,所以当调用next()是才会是初始化所指定的FilePageId或默认0
try (final PageCursor cursor = pagedFile.io(page(addr), PagedFile.PF_SHARED_READ_LOCK)) {//初始化为-1//必须调用next才是指定页Id,否则访问出现游标OutOfBound异常即访问victim pagecursor.next();do {res = cursor.getInt(off);} while (cursor.shouldRetry());//读操作永远要判断读锁是否有效}
5.11. 其他组件
5.11.1. VictimPage
VictimPage在MunninPageCache初始化时就会创建,大小为一个Page
- 其作用相当于Linux的0地址,即NULL或无效指针的替代。
当Cursor初始化或访问Page发生越界时,Cursor会指向VictimPage以防止真的越界。
static synchronized long getVictimPage( int pageSize, MemoryTracker memoryTracker ){if ( victimPageSize < pageSize ){// Note that we NEVER free any old victim pages. This is important because we cannot tell// when we are done using them. Therefor, victim pages are allocated and stay allocated// until our process terminates.victimPagePointer = UnsafeUtil.allocateMemory( pageSize, memoryTracker );victimPageSize = pageSize;}return victimPagePointer;}
5.11.2. IOLimiter
PagedFile 和 PageCache 上的flushAndForce 方法采用IOLimiter 参数。 这样做的目的实际上是降低Flush脏页时执行的 IO 速率。 我们这样做的原因是,直到最近,当操作系统页面缓存中的脏页面百分比过高时,Linux 可能会表现出较差的系统范围 IO 性能,并且回写内核进程开始承担优先级。 在云设置中,这也可能是相关的,因为 IO 可以被速率限制,并且我们不希望 IO 繁重的后台进程(如检查点)垄断 IO 子系统及其配额。
5.11.3. Prefetcher
预读取机制
- 通过监视Cursor的CurrentPageId进行预计并预加载Page
这里考虑到CurrentPageId的volatile性质,所以PageCursor通过StoreCurrentPageId方法,基于Unsafe.putOrderedLong(即putLongVolatile)来更新CurrentPageId
5.11.4. VersionContext
适应Neo4j事务的,基本上就是一个版本检验以便可能回滚之类的操作
- 每次写操作会更新那个页的事务Id
- 每次读操作开始和结束会对比事务Id是否被更新
- 页面被驱逐时,页面事务Id比映射文件的事务Id新,则会更新页面文件的事务Id
6. PageCache使用流程和原理
6.1. 整体过程
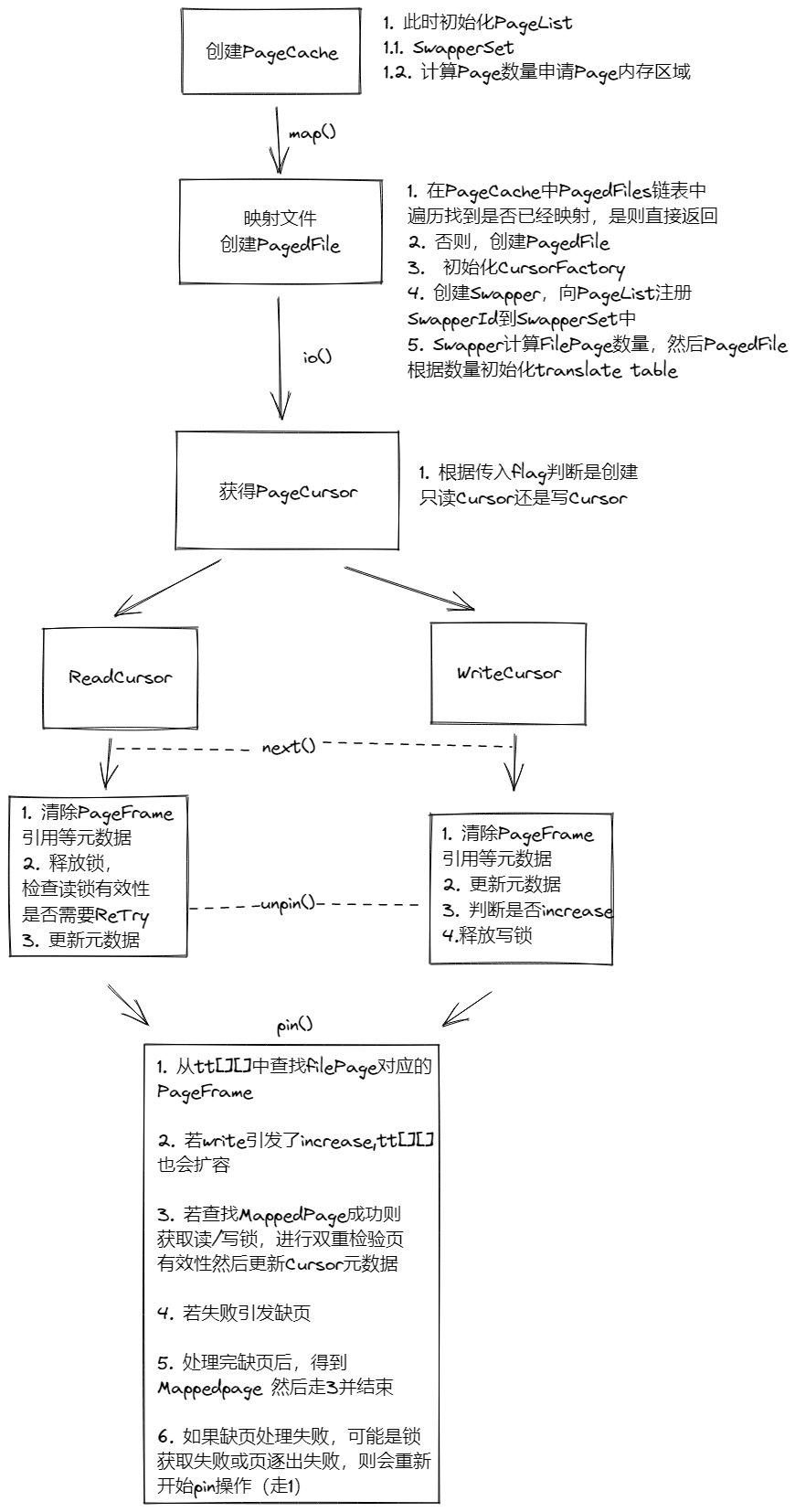
6.2. 页面驱逐
- 首先,检查页面是否已加载,并且使用计数器减少到零。未绑定或未加载的页面是空闲的,驱逐空闲页面毫无意义。
- 然后获取页面上的排他锁。
- 然后我们再次检查页面是否仍是Loaded。这是一个双重检查锁定模式,并确保我们不会在第一次 isLoaded 检查和获取页面上的排他锁之间对被驱逐的页面进行驱逐。
A. 如果页面不再加载,那么我们中止驱逐操作,并释放我们获得的排他锁。 - 如果页面是脏的,则将其Flush,并显式降低脏位。Flush发生在排他锁下,因此脏位不会自动降低。另一方面,在此Flush后显式降低脏位是安全的,因为排他锁可防止任何重叠写入。
- 然后Swapper被通知驱逐。这会调用关联分页文件(创建Swapper的分页文件)中的回调,该回调通过页面当前绑定到的文件页面 ID 清除转换表条目。
A. 从这点开始,如果一个线程想要访问该页面,他们会注意到转换表没有条目,并且他们将启动一个页面错误。
B. 如果在我们驱逐这个页面之前分页文件已经被取消映射,那么我们将在Swapper集中找不到相关的Swapper实例,我们将跳过Flush和驱逐回调步骤。 - 然后我们清除页面绑定。这意味着该页面不再加载。
- 最后,页面要么被添加到空闲列表(在后台驱逐的情况下),要么返回到页面错误线程(在合作驱逐的情况下)。
6.3. 缺页异常
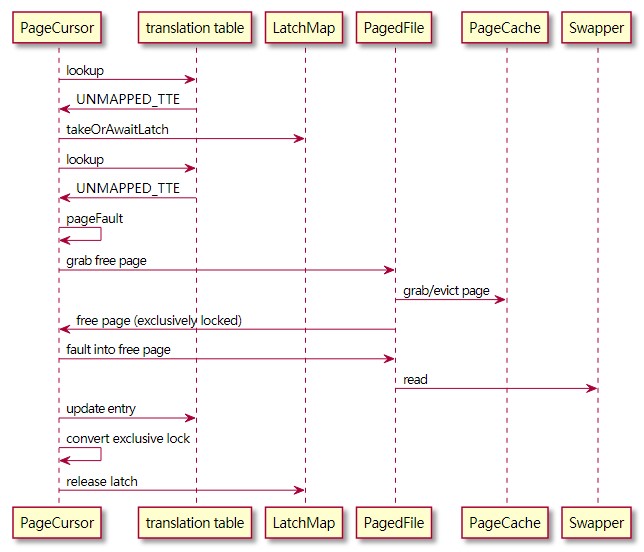
- 线程希望访问分页文件中的页面,并且注意到转换表缺少该页面的条目,或者引用的页面未绑定到预期的文件页面。
- 然后线程尝试在 LatchMap 中获取相关文件页面 ID 的闩锁。
A. 然后线程将等待任何正在进行的和潜在相关的页面错误完成,然后从顶部重试,或者……
B. 线程获得了锁存器并可以继续执行页面错误,因为此时没有其他线程可以在此特定页面中出错。 - 我们再次检查translate table条目是否丢失,这是一个双重检验。可能是另一个线程在我们第一次注意到丢失的转换表条目和我们获得锁存器之间完成了页面错误。
A. 如果转换表条目不是特殊的 UNMAPPED_TTE 值,那么我们释放我们得到的锁存器,并从头开始。 - 缺页准备开始,第一步是获得一个空闲的缺页。空闲页面从空闲列表中获得,或者,如果空闲列表为空,则通过合作驱逐获得。请参阅上面关于驱逐协议的内容,了解它是如何发挥作用的。
- 获得空闲页面时已经持有排它锁。页错误线程采用此排他页锁的所有权,并负责最终释放它。
- 然后页面错误执行必要的 IO 以将数据读入页面。
A. 如果这一步失败,那么页面在页面错误被中止之前释放了它的排他锁。这确保驱逐最终会收集页面并再次释放它,将其返回到独占锁定状态。 - 然后用页面的条目更新translate table。
- 然后排它锁被转换为乐观读锁或写锁,这取决于执行页面错误的页面游标的类型。
- 然后最后释放缺页锁存器,完成缺页。
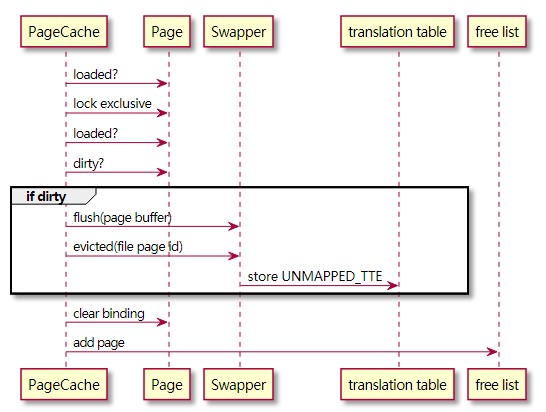
6.4. 脏页刷盘(ForceFlush,not page fault)
- 转换表被迭代,被映射的条目检查其脏/修改位。
A. 脏位检查发生在乐观读锁下,以防止任何重叠的写锁。 - 如果页面是脏的,则获取其Flush锁。或者,如果Flush是作为取消映射文件的一部分而发生的,则采用排他锁。
- 然后检查页面绑定(这个页面是否绑定到当前文件中期望的文件页面?)。
- 按照双重检查的锁定模式,第二次检查脏位。
- 这个顺序可以重复,直到收集到一批脏页。
- 然后Flush一个或多个页面。
- IO 完成后,释放Flush锁或排他锁。
A. 解锁步骤还会降低所有相关页面上的脏位。在Flush锁的情况下,这是自动发生的,而对于排他锁,这是显式完成的。 - 最后,当文件中的所有页面都被Flush时,Swapper被强制执行。这会转化为对文件的 fsync(2) 系统调用。
- 关于脏页收集:
- 脏页捕获(Grab)过程上述描述很清楚,通过遍历tt[][],每次遍历一个Chunk,每个Chunk有最多默认1<<12个页面。
- 当在此Chunk Grab到第一个脏页后,会continue chunkLoop:go to next page
- 如果下一个页面为空或者不为脏页,则进入pagesGrabbed>0?判断是否有脏页需要刷盘。不管有没有在刷盘或不刷盘后继续遍历Chunk
- 否则才会继续Grab
- 这么做的目的是因为,Swapper的write方法只支持一页或连续多页,为了连续写入优化。此时脏页Grab要么一页,要么连续多页,不能跳页。
- BTW:Grab脏页原理是记录第一个脏页FilePageId,以及每一个脏页的Address存于bufferAddresses[]

若有收获,就点个赞吧
0 人点赞
