1.引言
IPC有两种方式,第一种是消息队列(MQ),第二种就是内存共享,想必谁更快就不用多介绍了。
2.内存共享的两种方式
内存共享有两种方式,第一种是MMAP(文件映射)。第二个就是Share Memory,也就是直接共享一块内存,在Linux当中使用top、free等命令都可以看到进程、系统所占用的虚拟内存和共享内存大小。
2.1虚拟内存
上面有提到虚拟内存,但是要在讲共享内存之前,要先明白进程是怎样使用物理内存的,首先就要了解每个进程都有的虚拟内存。
每一个进程OS都会让它认为自己独享全部内存,实际上是不可能的,所以OS采用虚拟内存的方法让进程认为自己独享内存。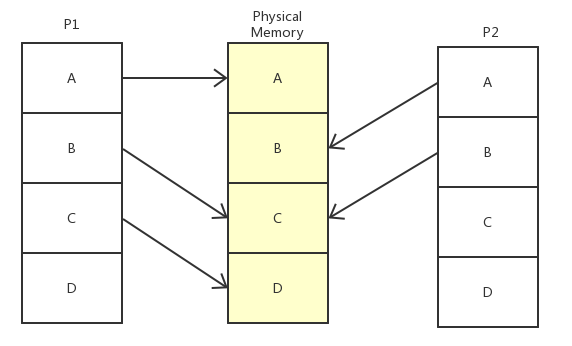
- 如图,进程P1访问实内存地址A、C、D,但对于它自己来说,是连续地址A、B、C,是OS欺骗了它,
- 同样,进程P2访问实内存地址B、C对于它自己来说是A、B
- 虚拟空间对于程序来说(也对于程序员来说)是一段和物理内存相同大小(或自定义,比如JVM自定义堆大小等),连续的地址空间(还没分配内存,所以叫地址空间,预留的空间,还不能读写数据)
- 虚拟内存和物理内存都是划分成同样单位的页,默认1页=4KByte
2.2文件和物理内存和虚拟内存
知道了虚拟内存其实是每个进程虚拟地址空间对物理内存的映射,接下来详细说下虚拟内存的访问文件过程,以便于了解MMAP的原理机制。
在读取文件的时候,物理内存和虚拟内存是怎样配合,让进程能够认为文件读到了内存中,我在读取内存中对应文件的数据呢?
这就要引出页缓存
linux 中页缓存的本质就是对于磁盘中的部分数据在内存中保留一定的副本,使得应用程序能够快速的读取到磁盘中相应的数据,并实现不同进程之间的数据共享。
在虚拟内存机制出现以前,操作系统使用块缓存机制,但是在虚拟内存出现以后,操作系统管理 IO 的粒度更大,因此采用了页缓存机制。此后,和后备存储的数据交互普遍以页为单位。
页缓存是基于页的、面向文件的一种缓存机制。
2.2.1页缓存实现
首先,要明白四个数据结构:
- struct iNode:与磁盘块级数据相映射的数据结构
一个列表,元素存储的是: struct address_space* imapping
- struct address_space:使iNode、vm_area_struct和基数树建立关系
struct iNode *host与上面数据结构的每一个元素一一对应struct radix_tree_root *page_tree基数树(即页缓存结构)的根struct prio_tree_root *imap虚拟内存结构树,每个节点表示一个进程的一个虚拟内存区域(大小不固定)
- struct vm_area_struct:表示一个虚拟内存空间
struct mm_struct *vm_mm指向vm_area_struct所在的mm_struct结构体当中struct prio_tree_node left指向prio_tree的左孩子struct prio_tree_node right指向prio_tree的右孩子struct prio_tree_node parent如果不是根节点,则会有这个字段,指向父节点
ps:往上数三个字段都是prio_tree_node node中的,我展开来写了下,vm_area_struct并没有这三个字段
struct prio_tree_node next指向下一个节点- 这一部分的虚拟空间指向的地址描述等等。。
- struct mm_struct:一个进程所拥有的所有vm_area_struct
struct rb_root mmrb红黑树,元素是一个个的vm_area_struct,与上面的vm_mm对应struct vm_area_struct *mmap链表,元素同上,当虚拟内存少的时候,使用mmap指向vm_area_struct链表,数量多时进化成红黑树有上面那个指针控制struct vm_area_struct *mmap_cache作用同上,不同的是这个链表很短,存储短时间内可能再次访问(即最近访问)的虚拟内存与高速缓存中
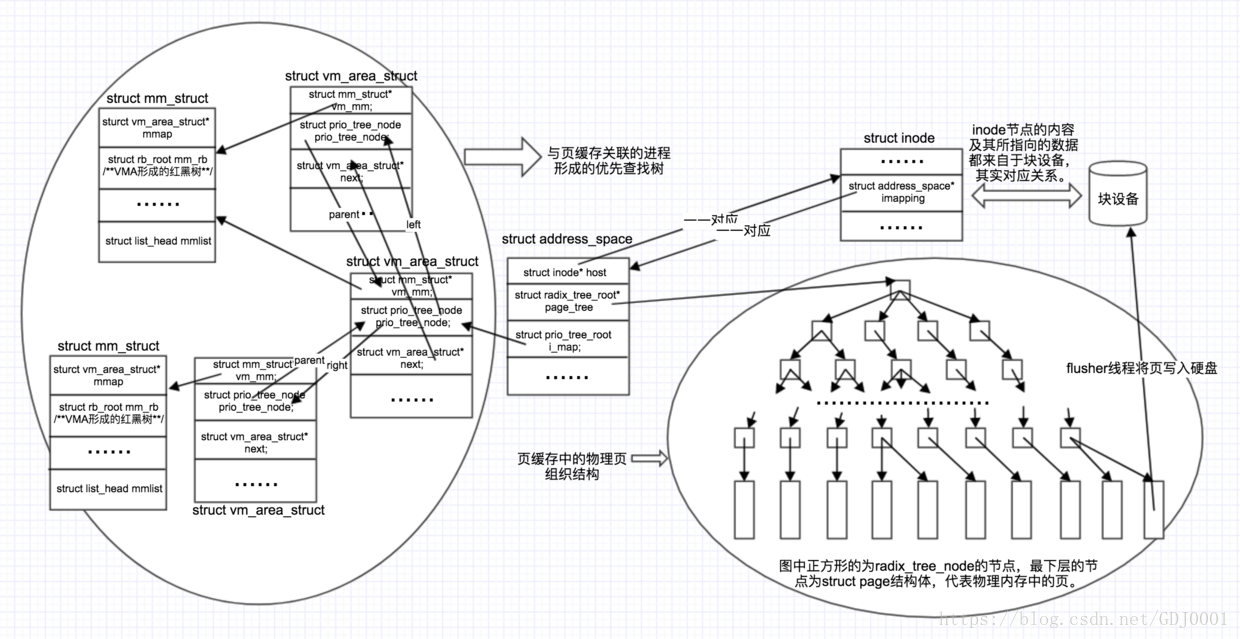
- 如图所示,进程通过访问struct mm_struct找到vm_area_struct OS让文件块对应iNode
- vm_area_struct和iNode通过address_space映射
- address_space相当于文件和虚拟内存以及基数树的桥梁,基数树就是文件数据所存放的页缓存,address_space连接着三者
- 每个进程只有一个mm_struct,进程的搜索树可以很快地从address_space的搜索树根找到该进程的mm_struct以及该进程的所有vm_area_struct,同时进程的task_struct也指向mm_struct
2.2.2基数树
这个数据结构本质上就是字典树(前缀树)。这个前缀就是一段二进制地址的前缀。
基数树用于快速找到某一页(包括dirty页或writeback)
- 首先由一个键key:long来标识某一页,然后long key进行分段,段数=层数
- 第0段开始,找到第i段对应第i层的某个节点,顺着找到叶节点后,叶节点指向一个页
- 对于每次寻找下一层节点:左节点为0,右节点为1
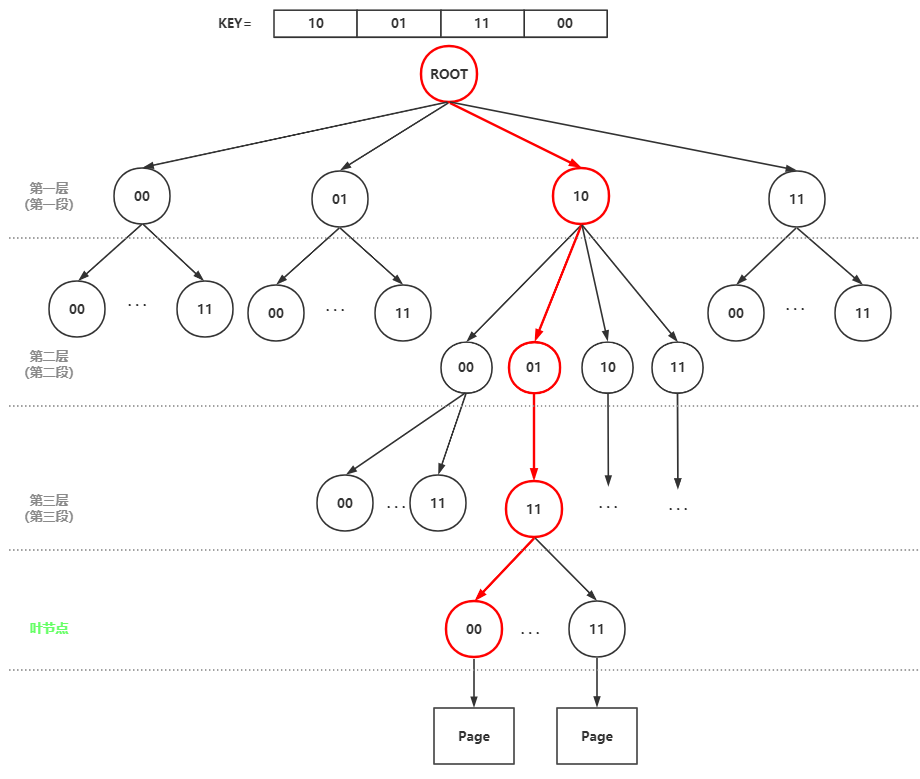
上图例子中,基数树进行了压缩(所以也喊叫压缩前缀树),即一个节点表示多个bit,上图是一个节点2bit,所以一个节点最多有2^2个子节点,以此类推,n个bit压缩择有2^n个节点,相应的key是一个64位的长整形,所以需要高度32的基数树。Linux宏定义中默认配置是节点最多压缩到6bit即2^6=64个子节点。
2.3MMAP
由上面的介绍来看,mmap已经说了个大概了,mmap不是什么Linux内存管理的额外功能,而是内存管理的核心功能,我们所指的mmap,是调用用户态的void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset) ,利用mmap指针的机制(其实文件/内存大了甚至都没有用mmap指针而是红黑树)来对文件做映射,在内核中由核态的 mmap(struct file *filp, struct vm_area_struct *vma) 将vm_area_struct和文件进行链接。
2.3.1MMAP映射流程
1.进程启动映射过程,并在虚拟地址空间中为映射创建虚拟映射区域
- 进程在用户态调用库函数mmap
- 在当前进程的虚拟地址空间中,寻找一段空闲的满足要求的连续的虚拟地址
- 为此虚拟区分配一个vm_area_struct结构,接着对这个结构的各个域进行了初始化
将新建的虚拟区结构(vm_area_struct)插入进程的虚拟地址区域链表或树中
2.调用内核空间的系统调用函数mmap(不同于用户空间函数),实现文件物理地址和进程虚拟地址的一一映射关系
为映射分配了新的虚拟地址区域后,通过待映射的文件指针,在文件描述符表中找到对应的文件描述符,通过文件描述符,链接到内核“已打开文件集”中该文件的文件结构体(struct file),每个文件结构体维护着和这个已打开文件相关各项信息。
- 通过该文件的文件结构体,链接到file_operations模块,调用内核函数mmap,不同于用户空间库函数。
- 内核mmap函数通过虚拟文件系统inode模块定位到文件磁盘物理地址。
通过remap_pfn_range函数建立页表,即实现了文件地址和虚拟地址区域的映射关系。此时,这片虚拟地址并没有任何数据关联到主存中。
3.进程发起对这片映射空间的访问,引发缺页异常,实现文件内容到物理内存(主存)的拷贝
ps:前两个阶段仅在于创建虚拟区间并完成地址映射,但是并没有将任何文件数据的拷贝至主存。真正的文件读取是当进程发起读或写操作时。
进程的读或写操作访问虚拟地址空间这一段映射地址,通过查询页表,发现这一段地址并不在物理页面上。因为目前只建立了地址映射,真正的硬盘数据还没有拷贝到内存中,因此引发缺页异常。
- 缺页异常进行一系列判断,确定无非法操作后,内核发起请求调页过程。
- 调页过程先在交换缓存空间(swap cache)中寻找需要访问的内存页,如果没有则调用nopage函数把所缺的页从磁盘装入到主存中。
- 之后进程即可对这片主存进行读或者写的操作,如果写操作改变了其内容,一定时间后系统会自动回写脏页面到对应磁盘地址,也即完成了写入到文件的过程。
ps:修改过的脏页面并不会立即更新回文件中,而是有一段时间的延迟,可以调用msync()来强制同步, 这样所写的内容就能立即保存到文件里了。
2.3.2MMAP共享内存
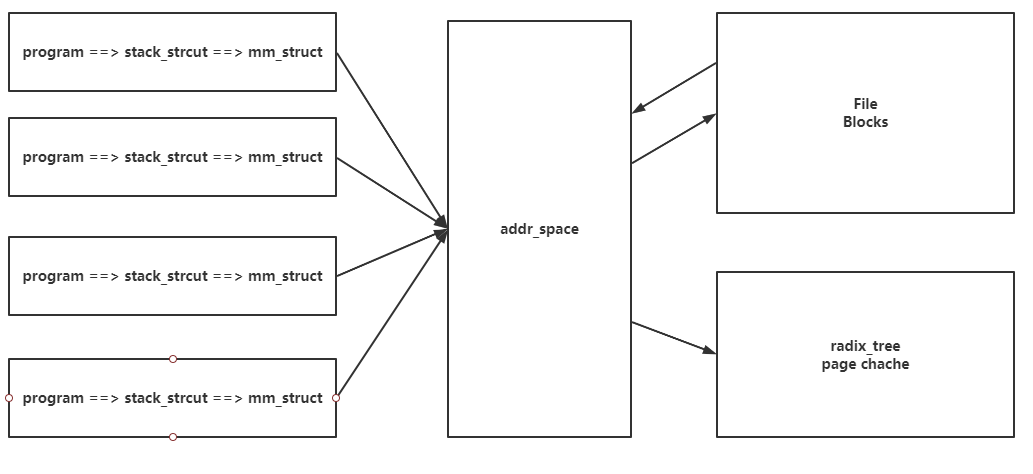
- 每个进程的task_struct对应一个mm_struct,mm_struct存储了该进程所有的虚拟空间片段(vm_area),片段中包括mmap的片段
- 所有进程的片段由addr_scpace的优先查找树管理,与之对应的是基数树,即进程访问mmap的虚拟空间片段,通过addr_space的基数树找到物理内存页缓存
- 而addr_scpace和iNode即磁盘文件以块为单位一一对应
- 所以,对于进程来说就是映射了这个文件,但是在访问映射文件的(虚拟)内存区域时,addr_space会找到对应的页缓存,而mmap的页缓存是由addr_scpace和iNode“绑定”的,所以由addr_scpace来达到根据同一文件映射同一物理内存页缓存的功能。即让多个进程能够共享一块内存。
2.4MMAP与传统文件IO的区别
MMAP可以进行内存共享,但它的最大作用并非这个,而是大文件的高速读写,和传统IO比较。
“普通文件 IO 需要复制两次,内存映射文件 mmap 只需要复制一次”
这个是两者区别最简洁最透彻的解释。
下面就从两者读写流程开始介绍:2.4.1读
IO
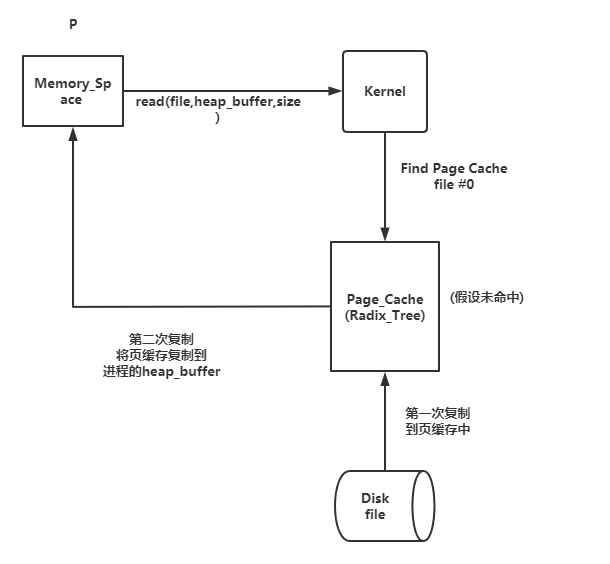
假设一个进程P,需要读取一个文件:
- 进程调用库函数 read() 向内核发起读文件的请求;
- 内核通过检查进程的文件描述符定位到虚拟文件系统已经打开的文件列表项,调用该文件系统对 VFS 的 read() 调用提供的接口;
- 通过文件表项链接到目录项模块,根据传入的文件路径在目录项中检索,找到该文件的 inode;
- inode中,通过文件内容偏移量计算出要读取的页;
- 通过该 inode 的 i_mapping 指针找到对应的 address_space 页缓存树(基数树),查找对应的页缓存节点;
- 如果页缓存节点命中,那么直接返回文件内容;
- 如果页缓存缺失,那么产生一个缺页异常,首先创建一个新的空的物理页框,通过该 inode 找到文件中该页的磁盘地址,读取相应的页填充该页缓存(DMA 的方式将数据读取到页缓存),更新页表项;重新进行第 5 步的查找页缓存的过程;
- 文件内容读取成功;
所有的文件内容的读取(无论一开始是命中页缓存还是没有命中页缓存)最终都是直接来源于页缓存
如上所示,进程发送请求,内核找页缓存且未命中时,先进行缺页处理,此时会占用CPU进行操作,浪费资源,且需要二次拷贝到进程空间,因为页缓存是物理内存,核态,进程空间是用户态,不可直接访问。此时内存占用如下: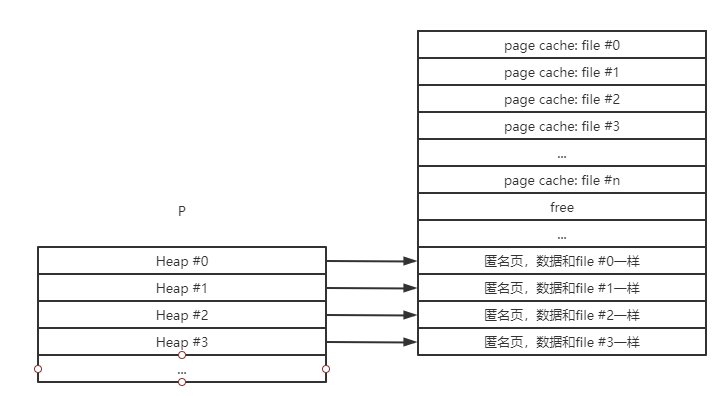
可见不仅浪费资源,还占用内存。
MMAP
mmap则是直接划分一段进程(虚拟)空间,映射到物理内存的页上(不是直接映射过去(是addr_space),过程上面解释过)
仅需要缺页的一次复制到物理内存页缓存上即可。内存占用如下: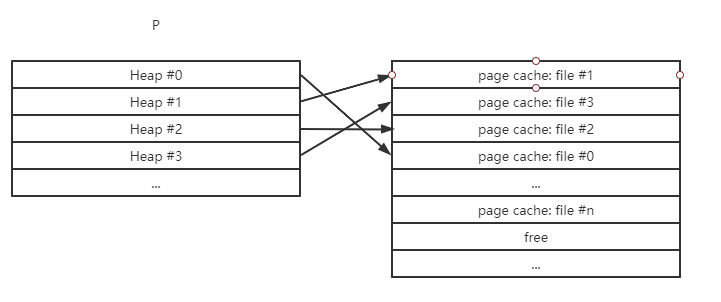
2.4.2写
由于页缓存的架构,当一个进程调用 write 系统调用的时候,对于文件的更新仅仅是被写到了文件的页缓存中,相应的页被标记为 dirty。具体过程如下:
- 前面 5 步和读文件是一致的,在 address_space 中查询对应页的页缓存是否存在;
- 如果页缓存命中,直接把文件内容修改写在页缓存的页中。写文件就结束了。这时候文件修改位于页缓存,并没有写回到磁盘文件中去。
如果页缓存缺失,那么产生一个页缺失异常,创建一个页缓存页,同时通过 inode 找到该文件页的磁盘地址,读取相应的页填充页缓存。此时缓存页命中,进行第 2 步。
IO
普通的 IO 操作需要将写的数据从自己的进程地址空间复制到页缓存中,完成对页缓存的写入
MMAP
mmap 通过虚拟地址(指针)可以直接完成对页缓存的写入,减少了从用户空间到页缓存的复制
2.5同步机制
2.5.1 何时写回
空闲内存的值低于一个指定的阈值的时候,内核必须将脏页写回到后备存储以释放内存。因为只有干净的内存页才可以回收。当脏页被写回之后就变为 PG_uptodate 标志,变为干净的页,内核就可以将其所占的内存回收;
- 当脏页在内存中驻留的时间超过一个指定的阈值之后,内核必须将该脏页写回到后备存储,以确定脏页不会在内存中无限期的停留;
- 当用户进程显式的调用 fsync、fdatasync 或者 sync 的时候,内核按照要求执行回写操作。
2.5.2 由谁写回
为了能够不阻塞写操作,并且将脏页及时的写回后备存储。linux 在当前的内核版本中使用了 flusher 线程负责将脏页回写。
为了满足第一个何时回写的条件,内核在可用内存低于一个阈值的时候唤醒一个或者多个 flusher 线程,将脏页回写;
为了满足第二个条件,内核将通过定时器定时唤醒flusher线程,将所有驻留时间超时的脏页回写。2.5.3线程安全?
看看Linux Manual的解释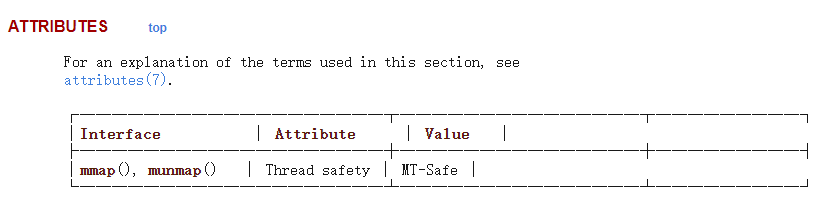
MT-Safe
_MT-Safe_ or Thread-Safe functions are safe to call in thepresence of other threads. MT, in MT-Safe, stands for MultiThread.Being MT-Safe does not imply a function is atomic, nor that ituses any of the memory synchronization mechanisms POSIXexposes to users. It is even possible that calling MT-Safefunctions in sequence does not yield an MT-Safe combination.For example, having a thread call two MT-Safe functions oneright after the other does not guarantee behavior equivalentto atomic execution of a combination of both functions, sinceconcurrent calls in other threads may interfere in adestructive way.Whole-program optimizations that could inline functions acrosslibrary interfaces may expose unsafe reordering, and soperforming inlining across the GNU C Library interface is notrecommended. The documented MT-Safety status is notguaranteed under whole-program optimization. However,functions defined in user-visible headers are designed to besafe for inlining.
简单解释就是:mmap操作本身是线程安全的,但是多个mmap则是非原子性的了。
所以,要实现共享内存必定是多进程(等效于多线程),此时则是不安全的。
经测试验证,的确不安全 测试方式很简单,就用非原子性的“i++”操作,多进程对同一byte位同时进行i++操作,得到的最终结果是不正确的。
2.6Share Memory
Share Memory原理就简单很多了,在了解了虚拟内存和物理内存的关系流程等原理后,ShareMemory就是进程可以向内核申请在物理内存上开辟一段共享内存。这个地方,为了让进程之间的虚拟内存独立,但又要让它们找到相同的共享内存,Linux采用了一个很机智的办法,还是一样,用文件来做标记。
我们知道,Linux的文件都有唯一标识符,那我们可以创建一个文件(可以是空的,甚至目录也行),并且保证文件或目录的路径不改变(即标识符不变),然后通过此文件调用f_tok()就可以返回一个唯一ID,用这个ID来标记共享内存。
然后所有进程就可以用这个ID获取共享内存,并返回共享内存映射在自己虚拟内存的地址。
ps:Share Memory是属于Linux IPC体系的,所以Share Memory也是个IPC对象,拥有IPC ID ,可以用ipc’x’命令操作,但是Linux并没有打算让Share Memory利用IPC ID。
3.共享内存的实现
经探索,基于JAVA目前找到了四种实现方式:
- JDK自带:实现了Buffer接口的ByteBuffer家族的MappedByteBuffer(实际是子类DirectByteBuffer)
- JNI实现C++的原生mmap函数
- JNI实心C++的原生shmget函数
- 第三方jar包:目前找到的是fengzhizi715/bytekit(GitHub)和odnoklassniki/one-nio(Github),都不怎么好用,效果不尽人意,此处就不介绍了。
3.1MappedByteBuffer
由于Java本身运行在JVM之上,离OS较远,通常使用第三方库,调用native(by C++)去实现
不过,JAVA nio有类似方法
这是JDK的NIO包下FileChannel的一个“实现”,在这里先说明,其实第三方开源库都是基于这个而实现的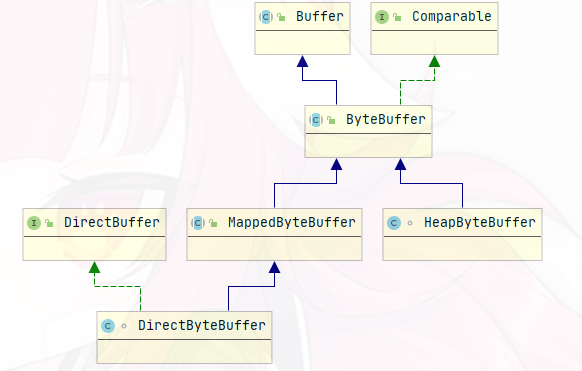
可以看出,MappedByteBuffer继承并实现了ByteBuffer—>Buffer,然后再实际使用中,我们真正用到的是DirectBuffer,这是再继承MappedByteBuffer并实现自己的接口的类
同时还有个HeapByteBuffer,两者的区别就是:
- MappedByteBuffer是FileChannel通过native方法map0实现的,和C一样的mmap,意味着映射地址所在虚拟空间在系统内存里面(JVM之外)
HeapByteBuffer则是类似的操作,但是映射地址所在虚拟空间在JVM内(堆内存)里面
public class FileChannleMap {public final MappedByteBuffer mappedByteBuffer;private final FileChannel fc;@SneakyThrowspublic FileChannleMap(File file, long capacity) {final long fsize = file.length();//File 创建RandomAccessFile,然后创建FileChannelfc = new RandomAccessFile(file, "rw").getChannel();final long l = capacity > 0 ? capacity : fc.size() * 2;//通过FileChannel的map方法就得到了MappedByteBuffer(DirectByteBuffer)mappedByteBuffer = fc.map(FileChannel.MapMode.READ_WRITE, 0, l);//load方法将文件加载到虚拟内存(创建的时候会加载的,如果没出错可以不加这句)mappedByteBuffer.load();}public void writeByte(byte[] bytes) {mappedByteBuffer.rewind();mappedByteBuffer.put(bytes);}public void writeText(String text) {this.writeByte(text.getBytes());}@SneakyThrowspublic String getAll() {mappedByteBuffer.rewind();final byte[] buff = new byte[mappedByteBuffer.limit()];mappedByteBuffer.get(buff);return new String(buff, StandardCharsets.UTF_8);}@SneakyThrowspublic String getPart(int offset, int len) {mappedByteBuffer.rewind();final byte[] buf = new byte[len];mappedByteBuffer.get(buf, offset, len);return new String(buf, StandardCharsets.UTF_8);}public Character getChar(int pos) {return (char) mappedByteBuffer.get(pos);}public void clearAll() {mappedByteBuffer.clear();}@SneakyThrowspublic void close() {mappedByteBuffer.force();if (fc != null && fc.isOpen())fc.close();}}
API:参见BufferAPI
- 这里所有操作是基于byte的,之后自己再转换成String或其他类型,注意,一个char是2Byte,int是4Byte,但是JAVA可以通过编码将一个char转换为一个byte(C就是一个byte)
- map方法第三个参数非常重要,是你开辟的内存的空间大小,是不可更改的!如果设置不合理很容易发生BufferOutBoundsException(or BufferUnderBoundsException)
- MappedByteBuffer实现的方法和C的mmap基本一致,比如C通过指针的数组操作ptr[i]进行读或写,MappedByteBuffer则有对应方法get(index)、get(&byte[],offset.len),put(byte[])、put(index,byte)、put(byte[],offset,len)
3.2Nature mmap
#include <stdio.h>#include <sys/mman.h>#include <fcntl.h>#include <errno.h>#include <sys/stat.h>#define MSIZE_2G 0x80000000using namespace std;char bytes[MSIZE_2G];int main(){int fd = 0;char *ptr = NULL;struct stat buf = {0};char filePath[]="mmapTestFile";/********** 1.open a File *************///use io.h open file ususally return 3(means regular read write) or -1(means fail)if ((fd = open(filePath, O_RDWR)) < 0){printf("open file error\n");return -1;}/*****************1.end********************//********** 2.get File status *************///get file state,file state include meta data of file for example:st_size[file length]if (fstat(fd, &buf) < 0){printf("get file state error:%d\n", errno);close(fd);return -1;}/*****************2.end********************//********** 3.get File's mmap address(virtual) *************///mmap just like fopen() but return a ptr point the address of file headptr = (char *)mmap(NULL, buf.st_size, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);if (ptr == MAP_FAILED){printf("mmap failed\n");close(fd);return -1;}/*****************3.end********************/close(fd);//when get the mmap poniter,you can even close the file objectprintf("length of the file is : %d\n", buf.st_size);printf("the %s content is : %s\n", filePath, ptr);//use ptr* do some read/write operatememcpy(bytes,ptr,bytes.size());//readmemcpy(ptr,bytes,bytes.size());//write//munmap just like close()munmap(ptr, buf.st_size);return 0;}
如上,(注释已经解释了),仅需三个步骤实现mmap
void mmap(void addr, sizet _length, int prot, int flags,int fd, off_t offset);
- addr:当创建mmap时,选择映射的内存所在地址,一般为NULL即内核自己选择,因为人工选择很可能出现内存覆盖问题导致进程发生错误。
length:创建的内存大小,此处有一定说明:
情形一:一个文件的大小是5000字节,mmap函数从一个文件的起始位置开始,映射5000字节到虚拟内存中。 分析:因为单位物理页面的大小是4096字节,虽然被映射的文件只有5000字节,但是对应到进程虚拟地址区域的大小需要满足整页大小,因此mmap函数执行后,实际映射到虚拟内存区域8192个 字节,5000~8191的字节部分用零填充。映射后的对应关系如下图所示:
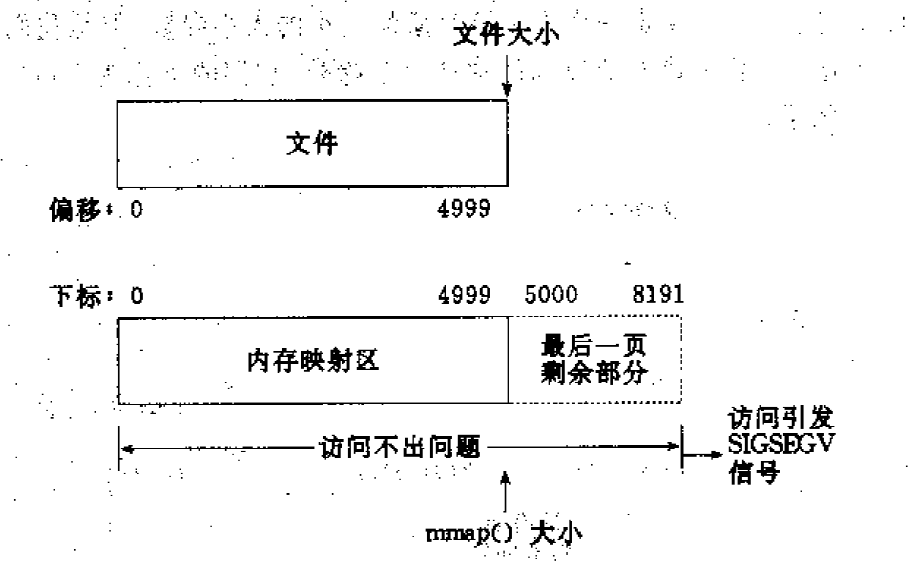
此时: (1)读/写前5000个字节(0~4999),会返回操作文件内容。 (2)读字节5000~8191时,结果全为0。写5000~8191时,进程不会报错,但是所写的内容不会写入原文件中 。 (3)读/写8192以外的磁盘部分,会返回一个SIGSECV错误。
情形二:一个文件的大小是5000字节,mmap函数从一个文件的起始位置开始,映射15000字节到虚拟内存中,即映射大小超过了原始文件的大小。 分析:由于文件的大小是5000字节,和情形一一样,其对应的两个物理页。那么这两个物理页都是合法可以读写的,只是超出5000的部分不会体现在原文件中。由于程序要求映射15000字节,而文件只占两个物理页,因此8192字节~15000字节都不能读写,操作时会返回异常。如下图所示:
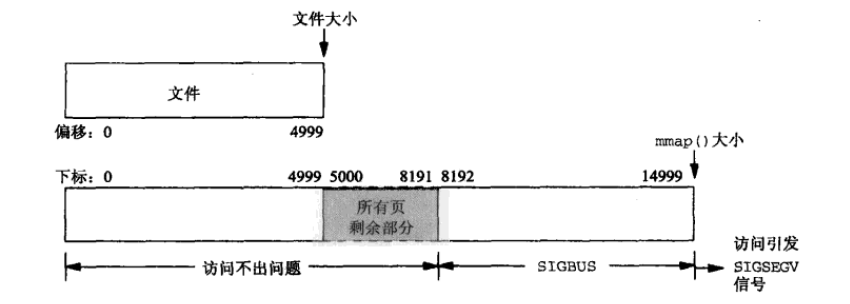
此时: (1)进程可以正常读/写被映射的前5000字节(0~4999),写操作的改动会在一定时间后反映在原文件中。 (2)对于5000~8191字节,进程可以进行读写过程,不会报错。但是内容在写入前均为0,另外,写入后不会反映在文件中。 (3)对于8192~14999字节,进程不能对其进行读写,会报SIGBUS错误。 (4)对于15000以外的字节,进程不能对其读写,会引发SIGSEGV错误。
情形三:一个文件初始大小为0,使用mmap操作映射了1000*4K的大小,即1000个物理页大约4M字节空间,mmap返回指针ptr。 分析:如果在映射建立之初,就对文件进行读写操作,由于文件大小为0,并没有合法的物理页对应,如同情形二一样,会返回SIGBUS错误。 但是如果,每次操作ptr读写前,先增加文件的大小,那么ptr在文件大小内部的操作就是合法的。例如,文件扩充4096字节,ptr就能操作ptr ~ [ (char)ptr + 4095]的空间。只要文件扩充的范围在1000个物理页(映射范围)内,ptr都可以对应操作相同的大小。 这样,方便随时扩充文件空间,随时写入文件,不造成空间浪费
prot:mmap的属性(由CPP头文件
宏定义的八进制或十六进制整形),说明如下: PROT_EXEC Pages may be executed.
PROT_READ Pages may be read.
PROT_WRITE Pages may be written.
PROT_NONE Pages may not be accessed.
flags:mmap的配置(由CPP头文件
宏定义的八进制或十六进制整形),说明如下: MAP_SHARED
创建共享内存(**一般用这个**)
MAP_PRIVATE 创建私有内存(专门读写文件用)
这个flags参数的宏定义非常多,以上只是常用的两种,flags可以配置很多东西,包括mmap的可拓展性,真实物理地址即偏移量设置、地址长度(32/64),内存锁,内存同步设置等等。详见Linux官方Manual
int munmap(void *addr, sizet _length);
- addr:mmap返回的指针
- length:mmap的大小
3.3Nature shmget
int shmget(key_t key, size_t size, int shmflg)
开辟内存(获取内存Id)
key_t key:内存关键字,相当于唯一Id,可以用0或者IPC_PRIVATE来匿名创建。自定义通常使用ftok()函数来想系统获取key值,这个key其实是IPC对象的key,IPC系统有不同的实现,MQ和SM相应的IPC对象都有这个key。
//一般用法 IPC_PRIVATE//匿名创建
define IPCKEY 0x344378 //宏定义
ftok(pathname,0x03)//通过设定一个文件路径,再提供一个八进制数字想系统获取,原理是将数字和文件索引号十六进制拼接,如果文件删除或变化就,key就会变化,所以推荐宏定义。
size_t size 申请的内存大小,字节为单位,但是大小为页大小的倍数,参数可以不是倍数,但返回的大小会补成倍数
- int shmflg 这个是共享内存的标识:它们的功能与open()的O_CREAT和O_EXCL相当
IPC_CREAT 如果共享内存不存在,则创建一个共享内存,否则打开操作。 IPC_EXCL 只有在共享内存不存在的时候,新的共享内存才建立,否则就产生错误。
如果单独使用IPC_CREAT,shmget()函数要么返回一个已经存在的共享内存的操作符,要么返回一个新建的共享内存的标识符。如果将IPC_CREAT和IPC_EXCL标志一起使用,shmget()将返回一个新建的共享内存的标识符;如果该共享内存已存在,则返回-1。IPC_EXEL标志本身并没有太大的意义,但是和IPC_CREAT标志一起使用可以用来保证所得的对象是新建的,而不是打开已有的对象。
真正的用法是将上述的标识符合权限标识(数字)用或运算组合
IPC_CREAT | 0777IPC_CREAT | 0600
这个权限标识就是Linux当中文件的权限数字标识,这里不做解释了。
void shmat(int shmid, const void shmaddr, int shmflg);
通过Id获取指针
shmid:上面的函数返回的就是内存的Id
shmaddr:指定共享内存出现在进程内存地址的什么位置,通常设为NULL,内核自行选择
shmflg:SHM_RDONLY为只读模式,其他为读写模式
返回:内存地址头部指针
int shmdt(const void *shmaddr);
释放进程与内存的绑定
shmaddr:上面函数返回的指针
返回:0成功,-1出错,原因会在errno中
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
对共享内存的一些操作:
shmid:Id,不消解释
cmd:
IPC_STAT:得到共享内存的状态,把共享内存的shmid_ds结构复制到buf中
IPC_SET:改变共享内存的状态,把buf所指的shmid_ds结构中的uid、gid、mode复制到共享内存的shmid_ds结构内
IPC_RMID:删除这片共享内存
buf:共享内存管理结构体。具体说明参见共享内存内核结构定义部分
共享内存不会随着程序结束而自动消除,要么调用shmctl删除,要么自己用手敲命令ipcrm去删除,否则永远留在系统中。
部分数据结构
struct shmid_ds
shmid_ds数据结构表示每个新建的共享内存。当shmget()创建了一块新的共享内存后,返回一个可以用于引用该共享内存的shmid_ds数据结构的标识符。
#include </linux/shm.h>struct shmid_ds {struct ipc_perm shm_perm; /* operation perms */int shm_segsz; /* size of segment (bytes) */__kernel_time_t shm_atime; /* last attach time */__kernel_time_t shm_dtime; /* last detach time */__kernel_time_t shm_ctime; /* last change time */__kernel_ipc_pid_t shm_cpid; /* pid of creator */__kernel_ipc_pid_t shm_lpid; /* pid of last operator */unsigned short shm_nattch; /* no. of current attaches */unsigned short shm_unused; /* compatibility */void *shm_unused2; /* ditto - used by DIPC */void *shm_unused3; /* unused */};
struct ipc_perm
对于每个IPC对象,系统共用一个struct ipc_perm的数据结构来存放权限信息,以确定一个ipc操作是否可以访问该IPC对象。
struct ipc_perm {__kernel_key_t key;__kernel_uid_t uid;__kernel_gid_t gid;__kernel_uid_t cuid;__kernel_gid_t cgid;__kernel_mode_t mode;unsigned short seq;};
ps:也可使用 ipcrm -m shmid的形式删除共享内存,但是如果有其他的进程在使用共享内存,则不会真正的删除共享内存,但会把共享内存的状态(使用ipcs -m查看status)制为dest,该动作是系统维护的。此时共享内能可以使用,当最后一个的进程结束或是不挂载共享内存时,共享内存则会自动删除。
_
demo:
#include <cstdio>#include <sys/ipc.h>#include <sys/shm.h>#include <sys/types.h>#include <cstring>#include <string>#include <iostream>#include <chrono>#define MSIZE_2G 0x80000000#define PROJ_ID 0666using namespace std;static int64_t GetUnixTime();char bytes[MSIZE_2G];int main(int argc, char **argv) {if (argc < 2)return -1;int shm_id;key_t key = ftok(".", PROJ_ID);//get current directory keyshm_id = shmget(key, 0, 0);//get shm's Id with current directoryif (shm_id == -1) {shm_id = shmget(key, MSIZE_2G, IPC_CREAT | 0777);printf("No Shared Memeory,Try to creat\n");if (shm_id == -1) {perror("shmget error");return -1;}}printf("shm_id=%d\n", shm_id);char *ptr = (char *) shmat(shm_id, nullptr, 0);//get shm's head pointer with shm_id//use ptr* do some read/write operatememcpy(bytes,ptr,bytes.size());//readmemcpy(ptr,bytes,bytes.size());//writeshmctl(shm_id, IPC_RMID, nullptr);return 0;}
也是很简单的三步骤搞定
ps:由于mmap和shm在C里面都是拿到连续地址的头部指针,所以可以利用数组操作,还有C的内存操作,比如memcpy高速批量读写。
3.4JNI的实现——JNA框架
如果采用原生C函数实现,那么Java想要调用就只能使用JNI了。
3.4.1原生JavaJNI
- 编写Java的native方法
这个操作很简单,就直接声明一个方法,不用实现,加上关键字native即可
native int function(int var1,char var2,long var3);
为了规范和好用,建议可以将所有native方法包进一个类里面
使用JDK自带的,javah命令将字节码编译成CPP头文件
javac demo.javajavah demo
得到demo.h以后,实现它
要知道,JNI这种面向接口编程,而CPP的接口就是header,所以创建一个项目将header实现,其中需要include JDK的header。
demo.h:
/* DO NOT EDIT THIS FILE - it is machine generated */#include "demo.h"/* Header for class NativeDemo */#ifndef _Included_NativeDemo#define _Included_NativeDemo#ifdef __cplusplusextern "C" {#endif/** Class: Demo* Method: function* Signature: ()V*/JNIEXPORT void JNICALL Java_Demo_function(JNIEnv *, jobject,int var1,char var2,void* var3);#ifdef __cplusplus}#endif#endif
最重要的C函数接口就是这样:JNIEXPORT void JNICALL Java_NativeDemo_sayHello(JNIEnv , jobject);
JNIEXPORT :在Jni编程中所有本地语言实现Jni接口的方法前面都有一个”JNIEXPORT”,这个可以看做是Jni的一个标志,至今为止没发现它有什么特殊的用处。
void :这个学过编程的人都知道,当然是方法的返回值了。
JNICALL :这个可以理解为Jni 和Call两个部分,和起来的意思就是 Jni调用XXX(后面的XXX就是JAVA的方法名)。
Java_NativeDemo_sayHello:这个就是被上一步中被调用的部分,也就是Java中的native 方法名,这里起名字的方式比较特别,是:包名+类名+方法名。
JNIEnv env:这个env可以看做是Jni接口本身的一个对象,jni.h头文件中存在着大量被封装好的函数,这些函数也是Jni编程中经常被使用到的,要想调用这些函数就需要使用JNIEnv这个对象。例如:env->GetObjectClass()。(详情请查看jni.h)
jobject obj:代表着native方法的调用者,本例即new NativeDemo();但如果native是静态的,那就是NativeDemo.class .
也就是说,我们的native sayHello()方法实际上是运行C的Java_NativeDemo_sayHello()这个方法,我们是不能随意写C函数名的的,只能这样写。
另外,参数和返回值牵扯到类型转换,java和CPP的类型转换基于类型所占字节,特别的,CPP指针所存储的是进程虚拟内存地址,可以在JAVA中转换成long
- 实现header后,讲项目编译打包成动态链接库
Windows:.dll
Linux:.so
- 在Java项目的linux-x86-64/win32-x86-64目录下放入动态链接库:libXXX.dll/libXXX.so
- 在native方法所在类的首部添加一个代码块:
然后就能正常调用了class Demo{{/*** 系统加载其他的语言的函数*/System.load("Demo");//libDemo.so}native int function(int var1,char var2,long var3);}
3.4.2JNA框架
JNI实现起来不难,但是,类型转换就特别麻烦了,基本数据类型还行,指针?转换成long也还算简单。
那么引用类型呢?看看C要怎么做:
没错,每个类型要用JNIEnv *env -> getXXX一个个获取
还包含一部分你无法理解的C++问题
- 类型转换
- linux windows多环境编译
- 内存泄漏
- 异常处理
- 各种找不到原因的报错
- debug 困难
- …
这时,sun公司的JNA框架出现了
- 你不需要通过 javah 生成头文件, 不需要给它写实现
- 不需要在 windows/linux 环境各自编译成 .dll/.so 来调用真正的函数
- 只需要声明一个接口, 其他的事情让 JNA 做好就行
public class HelloWorld {public interface CLibrary extends Library {CLibrary INSTANCE = Native.load((Platform.isWindows() ? "msvcrt" : "c"), CLibrary.class);void printf(String format, Object... args);}public static void main(String[] args) {CLibrary.INSTANCE.printf("Hello, World\n");}}
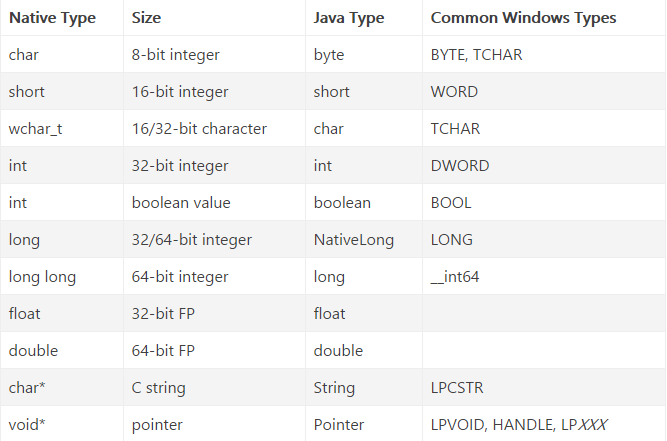
JNA数据类型映射
步骤
添加依赖
<dependency><groupId>net.java.dev.jna</groupId><artifactId>jna</artifactId><version>5.3.1</version></dependency>
编写一个Library项目(当然,你嫌麻烦可以不用.h+.cpp形式的项目,直接写个cpp也行)
int max(int num1, int num2) {return num1 > num2 ? num1 : num2;}
使用工具(VS,CMake等等)编译成dll或so
在Java中创建一个集成jna.Library的接口,使用懒汉式单例模式
// javapublic interface JnaLibrary extends Library {// JNA 为 dll 名称除掉lib即DLL文件名为:libJNA.dllJnaLibrary INSTANCE = Native.load("JNA", JnaLibrary.class);int max(int a, int b);}
调用
public static void main(String[] args) {int max = JnaLibrary.INSTANCE.max(100, 200);// out: 200System.out.println(max);}
引用类型
通过值传递对象的时候需要注意
对象需要继承
Structure, 且它的属性必须为 public- Structure fields corresponding to native struct fields must be public. If your structure is to have no fields of its own, it must be declared abstract.
- JNA 有时候会判断错误, 导致原本的值传递, 变成引用传递, 从而报出
Invalid memory access的异常, 这时候最好实现一下Structure.ByValue接口
- FieldOrder 需要按顺序写, 否则会报出
Invalid memory access
// javapublic interface JnaLibrary extends Library {// JNA 为 dll 名称JnaLibrary INSTANCE = Native.load("JNA", JnaLibrary.class);// 实际测试下来 void printUser(User.ByValue user); 也是可以的void printUser(User user);void printUserRef(User user);@Structure.FieldOrder({"name", "height", "weight"})public static class User extends Structure {public static class UserValue extends User implements Structure.ByValue {public UserValue(String name, int height, double weight) {super(name, height, weight);}}public User(String name, int height, double weight) {this.name = name;this.height = height;this.weight = weight;}public String name;public int height;public double weight;}}
// .hstruct User {char* name;int height;double weight;};void printUser(User user);void printUserRef(User& user);// cppvoid printUser(User user) {printf("printUser user: %s height: %d weight: %.2f \n", user.name, user.height, user.weight);}void printUserRef(User& user) {printf("printUserRef user: %s height: %d weight: %.2f \n", user.name, user.height, user.weight);}
注意:经测试,引用类型不能作为返回值,会造成字段数据为空,需要返回引用类型的对象时,采用引用传参的方式即可。
指针类型
在JNA中指针被包装成了Pointer对象,非常好用,内存采用JNA自己实现的Native类下的很多方法。
可直接类型转换,所以此处省略。
Pointer API详见官方文档
4.读写速度测试
| 以下皆是2GB数据读写总用时 | CPP原生ShareMemory | CPP原生MMAP | JNA(JNI)_ShareMemory | JNA(JNI)_MMAP | JDK实现的MMAP | CPP直接使用内存 即直接对2GB大小的数组进行读写测试 |
JAVA直接使用内存 即直接对2GB大小的数组进行读写测试 |
|---|---|---|---|---|---|---|---|
| 单个字节循环写 | 4288ms | 4775ms | 16128ms | 18008ms | 1876ms | / | / |
| 单个字节循环读 | 3743ms | 3485ms | 16439ms | 16237ms | 967ms | / | / |
| 字节数组批量写 | 824ms | 888ms | 768ms | 922ms | 965ms | 4471ms | 2690ms |
| 字节数组批量读 | 1649ms | 1308ms | 1486ms | 1105ms | 499ms | 3391ms | 1092ms |
- 由于JNA框架包装的Pointer对象,native方法的缘故,JNI操作指针以byte为单位循环多次效率极低
- 批量(以byte数组为单位),JNI效率和原生CPP几乎一致
- 与JDK实现的MMAP对比,读的速度更快,写的速度差不多,另外,JDK的MMAP对于单字节读写效率也很高,与JNI不同的原因是native方法的实现不同,后续会再改进。
- 共享内存(两种方法)与直接读写堆内存速度差异也不大,原因是两者本质都是在对进程虚拟内存读写。
本次测试还有些许不确定的地方,后续再更新和解释

若有收获,就点个赞吧
0 人点赞
