正排索引是以文档的 ID 为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。
而倒排索引,是通过分词策略,形成了词和文章的映射关系表,这种词典+映射表即为倒排索引。
有了倒排索引,就能实现 o(1)时间复杂度的效率检索文章了,极大的提高了检索效率。
所以总的来说,正排索引是从文档到关键字的映射(已知文档求关键字),倒排索引是从关键字到文档的映射(已知关键字求文档)。
加分项: 倒排索引的底层实现是基于:FST(Finite State Transducer)数据结构。 Lucene 从 4+ 版本后开始大量使用的数据结构是 FST。FST 有两个优点: 1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间; 2)查询速度快。O(len(str)) 的查询时间复杂度。
学术的解答方式:
倒排索引,相反于一篇文章包含了哪些词,它从词出发,记载了这个词在哪些文档中出现过,由两部分组成——词典和倒排表。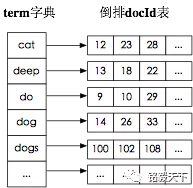
详细解释
在搜索引擎中,每个文档都有一个对应的文档 ID,文档内容被表示为一系列关键词的集合。
例如,文档 1 经过分词,提取了 20 个关键词,每个关键词都会记录它在文档中出现的次数和出现位置。
那么,倒排索引就是关键词到文档 ID 的映射,每个关键词都对应着一系列的文件,这些文件中都出现了关键词。
例子:
有以下文档:
| DocId | Doc |
|---|---|
| 1 | 谷歌地图之父跳槽 Facebook |
| 2 | 谷歌地图之父加盟 Facebook |
| 3 | 谷歌地图创始人拉斯离开谷歌加盟 Facebook |
| 4 | 谷歌地图之父跳槽 Facebook 与 Wave 项目取消有关 |
| 5 | 谷歌地图之父拉斯加盟社交网站 Facebook |
对文档进行分词之后,得到以下倒排索引。
| WordId | Word | DocIds |
|---|---|---|
| 1 | 谷歌 | 1, 2, 3, 4, 5 |
| 2 | 地图 | 1, 2, 3, 4, 5 |
| 3 | 之父 | 1, 2, 4, 5 |
| 4 | 跳槽 | 1, 4 |
| 5 | 1, 2, 3, 4, 5 | |
| 6 | 加盟 | 2, 3, 5 |
| 7 | 创始人 | 3 |
| 8 | 拉斯 | 3, 5 |
| 9 | 离开 | 3 |
| 10 | 与 | 4 |
| .. | .. | .. |
另外,实用的倒排索引还可以记录更多的信息,比如文档频率信息,表示在文档集合中有多少个文档包含某个单词。
那么,有了倒排索引,搜索引擎可以很方便地响应用户的查询。比如用户输入查询 Facebook ,搜索系统查找倒排索引,从中读出包含这个单词的文档,这些文档就是提供给用户的搜索结果。
要注意倒排索引的两个重要细节:
- 倒排索引中的所有词项对应一个或多个文档;
- 倒排索引中的词项根据字典顺序升序排列
倒排索引的整个过程
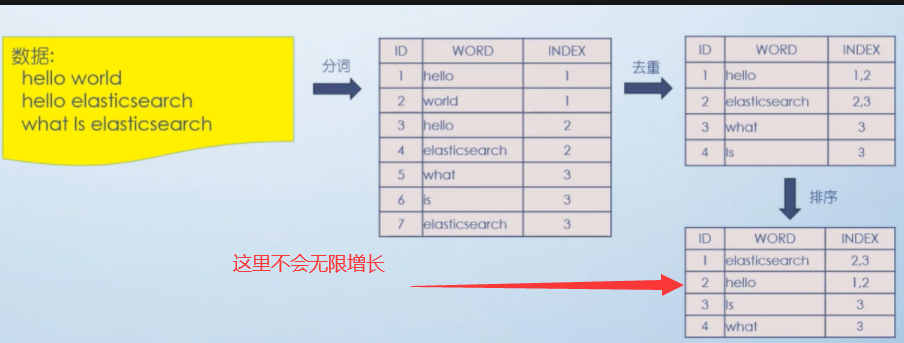
下面这个图里面 不全,只是参考, 比如说下面图去重之后 没有 world ,不要在意细节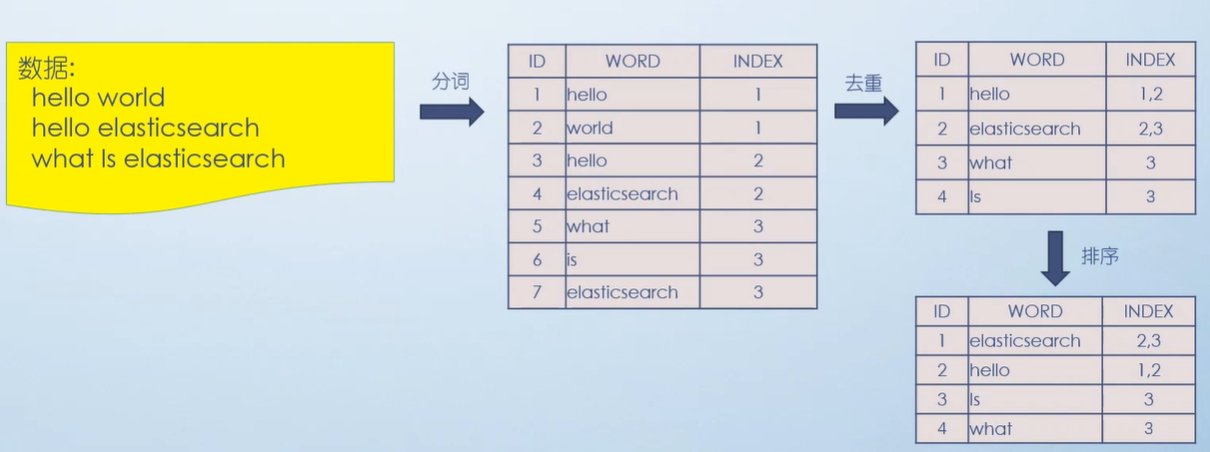
数据存到索引库
原封不动
步骤一:分词,将词语进行拆开
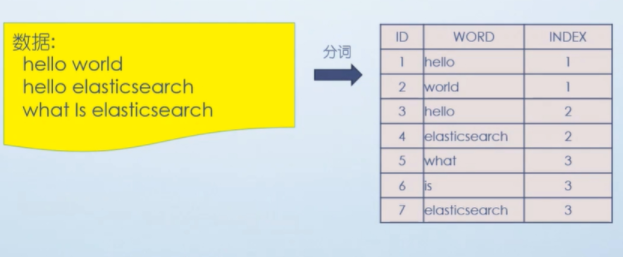
比如说 hello world , 拆成 “hello” “world” 两个词, 这两个词都在第一行,index就是1
hello elasticsearch,拆成 “hello” “elasticsearch” 两个词, 这两个词都在第二行,index就是2
what is elasticsearch,拆成 “what” “ is “ “elasticsearch” 三个词,这三个词都在第三行,index就是3
当然分词具体怎么分,还跟你的分词器有关系
步骤二:去重
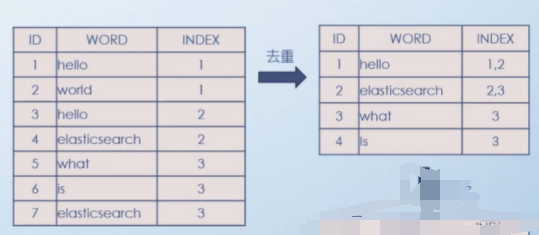
hello在第一条记录和第二条记录都有,那么就 1和2
elasticsearch 在第二条第三条记录都有,那么就记录2 3
what 在第三条记录有 ,那么就记录3
Is 在第三条记录有 , 那么就记录3
步骤三:排序
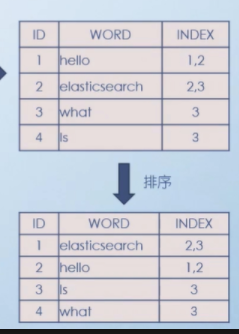
将单词首字母按照字母顺序排序, e在上面就排到第一位, h在第二位 I在第三位, w 就在最后了.
用户输入关键字的时候
用户输入 “hello what world” 关键字之后, ElasticSearch 会把这个关键字拆成 “hello” “what “ “world” 这三个词,
然后拿这个词去步骤三排序完了之后的结果里面找, 发现 hello 在index为1和2的有,
what在 index 3 的有
找完之后,最终根据 index的行数去索引库找到对应的数据返回给用户

为什么海量数据ElasticSearch要比MySQL查询快
因为你MySQL每新增条记录就多一行, ElasticSearch虽然每新增一条记录索引库也多一行, 但是ElasticSearch 索引表里面可能不会无限增长,因为常用的单词也就那么多.
可能ElasticSearch索引库新增一条数据之后,然后索引表不会增数据,也就是在原来的索引word后面的index多个指向索引库的索引而已.
比如说原来hello是 1 ,2 ,你又多了个 “hello单词”,那么 索引表里面的 hello 顶多就追加一个index编号而已.

若有收获,就点个赞吧
0 人点赞
