出自 图灵学院 ElasticSearch课程, 我自己学完了,整理了一下,然后给老师说的话,记录了一下,发了个博客
概述
ES支持地理位置的搜索和聚合分析,可实现在指定区域内搜索数据、搜索指定地点附近的数据、聚合分析指定地点附近的数据等操作。
ES中如果使用地理位置搜索的话,必须提供一个特殊的字段类型。GEO - geo_point。地理位置的坐标点。
1、定义geo point mapping
如果需要使用地址坐标,则需要定义一个指定的mapping类型。具体如下:
使用什么数据可以确定,地球上的一个具体的点?经纬度。
PUT /hotel_app{"mappings": {"properties": {"pin": {"type": "geo_point"},"name": {"type": "text","analyzer": "ik_max_word"}}}}
“type”: “geo_point” // 特殊的数据类型
2、录入数据
新增一个基于geo point类型的数据,可以使用多种方式。
多种类型描述geo_point类型字段的时候,在搜索数据的时候,显示的格式和录入的格式是统一的。不影响搜索。任何数据描述的geo_point类型字段,都适用地理位置搜索。
数据范围要求:纬度范围是-90~90之间,经度范围是-180~180之间。
经纬度数据都是浮点数或字符串,但是字符串必须得全都是文字(数字组成的字符串)
最大精度:小数点后7位。(常用小数点后6位即可。)
下面有其中三种方式插入数据
基于数字:latitude:纬度、longitude:经度。语义清晰,建议使用。
PUT /hotel_app/_doc/1{"name": "七天连锁酒店","pin": {"lat": 40.12,"lon": -71.34}}
基于字符串:依次定义纬度、经度。不推荐使用
40.99代表纬度 -701.81代表经度
PUT /hotel_app/_doc/2{"name": "维多利亚大酒店","pin" : "40.99, -70.81"}
基于数组:依次定义经度、纬度。不推荐使用
注意,这个基于数组的经度纬度顺序和上面的基于字符串的顺序不一样的.
40代表经度
-73.81代表纬度
PUT /hotel_app/_doc/3{"name": " 红树林宾馆","pin" : [40, -73.81]}
3、搜索指定区域范围内的数据
总结:
多边形范围搜索:对传入的若干点的坐标顺序没有任何的要求。只要传入若干地理位置坐标点,即可形成多边形。
搜索矩形范围内的数据
geo_bounding_box的意思代表是矩形的形式
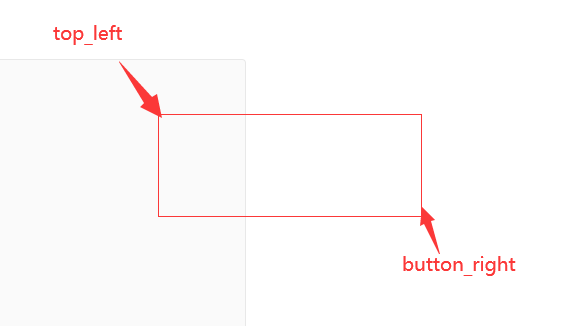
top_left 就是矩形的左上方这个点, bottom_right就是矩形的右下方这个点,指定了这两个点之后,就将这两个点连城一个矩形, 将矩形的数据查询出来
矩形范围搜索:传入的top_left和bottom_right坐标点是有固定要求的。地图中以北作为top,南作为bottom,西作为left,东作为right。也就是top_left应该从西北向东南。Bottom_right应该从东南向西北。Top_left的纬度应该大于bottom_right的纬度,top_left的经度应该小于bottom_right的经度。
GET /hotel_app/_doc/_search{"query": {"geo_bounding_box": {"pin": {"top_left": { //矩形的左上方这个点"lat": 41.73,"lon": -74.1},"bottom_right": { // 矩形的右下方这个点"lat": 40.01,"lon": -70.12}}}}}
但是上面的方式会对结果进行评分排序,效率不如filter效率高,下面这种效率是最高的.
GET /hotel_app/_doc/_search{"query": {"bool": {"must": [{"match_all": {}}],"filter": {"geo_bounding_box": {"pin": {"top_left": {"lat": 41.73,"lon": -74.1},"bottom_right": {"lat": 40.01,"lon": -70.12}}}}}}}
搜索多边形范围内的数据
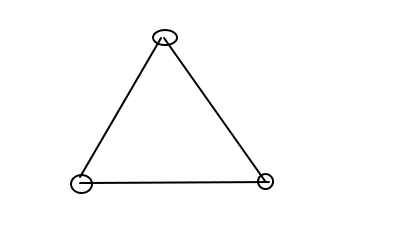
多边形就是你有几个点,然后这几个点就串联起来,
假如说你有三个点,那么就是三个点串联起来成为一个三角形,ElasticSearch会将三角形里面的坐标数据返回给客户端
假如说你有四个点,ElasticSearch会将四个点串联起来,然后将这四个点串联的四边形里面的数据返回给你客户端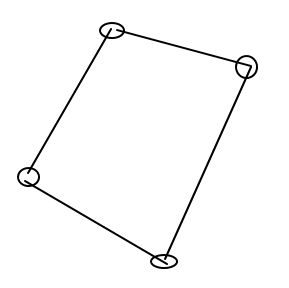
输入:
GET /hotel_app/_doc/_search{"query": {"bool": {"must": [{"match_all": {}}],"filter": {"geo_polygon": {"pin": {"points": [{"lat": 40.73,"lon": -74.1},{"lat": 40.01,"lon": -71.12},{"lat": 50.56,"lon": -90.58}]}}}}}}
结果
{"took" : 22,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "hotel_app","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "七天连锁酒店","pin" : {"lat" : 40.12,"lon" : -71.34}}}]}}
搜索某地点附近的数据
比如说我想去吃饭,我希望找以我为中心,直径两公里的以内的饭店
这个搜索在项目中更加常用。类似附近搜索功能。
Distance距离的单位,常用的有米(m)和千米(km)。
建议使用filter来过滤geo_point数据。因为geo_point数据相关度评分计算比较耗时。使用query来搜索geo_point数据效率相对会慢一些。建议使用filter。
pin就是指定当前的经纬度
distance是距离
geo_distance是圆圈的形式
GET /hotel_app/_doc/_search{"query": {"bool": {"must": [{"match_all": {}}],"filter": {"geo_distance": {//指定以圆圈的形式,以lat是40,lon是-70的地点为中心,直径为200km内的数据"distance": "200km","pin": {"lat": 40,"lon": -70}}}}}}
下面这种会对结果打分排序,效率不如上面带filter的效率高,上面filter方式搜索不会对结果进行打分.效率更高.
GET hotel_app/_search{"query": {"geo_distance": {"distance": "90km","pin": {"lat": 40.55,"lon": -71.12}}}}
统计某位置附近区域内的数据
比如说你打开一个app,里面有个功能,就显示距离你2公里有多少个商家,这个功能就是聚合统计.
聚合统计分别距离某位置80英里,300英里,1000英里范围内的数据数量。
其中unit是距离单位,常用单位有:米(m),千米(km),英里(mi)
distance_type是统计算法:sloppy_arc默认算法、arc最高精度、plane最高效率
dsl内容解释:
GET /hotel_app/_doc/_search{"size": 0,// 这个意思是我不想看到统计的元数据信息"aggs": { //统计"agg_by_pin": { //统计的名字"geo_distance": { //圆圈的形式做统计"distance_type": "arc",//统计的类型 arc是最高精度 plane是最高效率"field": "pin", //字段名"origin": { // 原始的位置,就好比我用这个点做统计"lat": 40,"lon": -70},"unit": "mi", //指定单位是mi ,就是英里"ranges": [ //根据范围统计{ //距离0~80范围的"to": 80},{ //80~300范围的数据"from": 80,"to": 300},{ // 300~1000范围的数据"from": 300,"to": 1000}]}}}}
输入dsl:
GET /hotel_app/_doc/_search{"size": 0,"aggs": {"agg_by_pin": {"geo_distance": {"distance_type": "arc","field": "pin","origin": {"lat": 40,"lon": -70},"unit": "mi","ranges": [{"to": 80},{"from": 80,"to": 300},{"from": 300,"to": 1000}]}}}}
结果
{"took" : 8,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"agg_by_pin" : {"buckets" : [{ // 0~80的数量为1"key" : "*-80.0","from" : 0.0,"to" : 80.0,"doc_count" : 1},{ // 80~300的数量为1"key" : "80.0-300.0","from" : 80.0,"to" : 300.0,"doc_count" : 1},{ // 300~1000的数量为0"key" : "300.0-1000.0","from" : 300.0,"to" : 1000.0,"doc_count" : 0}]}}}

若有收获,就点个赞吧
0 人点赞
