深分页原理
ES集群的分页查询支持from和size参数,查询的时候,每个分片必须构造一个长度为from+size的优先队列,然后回传到网关节点,网关节点再对这些优先队列进行排序找到正确的size个文档。
假设在一个有6个主分片的索引中,from为10000,size为10,每个分片必须产生10010个结果,在网关节点中汇聚合并60060个结果,最终找到符合要求的10个文档。
由此可见,当from足够大的时候,就算不发生OOM,也会影响到CPU和带宽等,从而影响到整个集群的性能。所以应该避免深分页查询,尽量不去使用。
如何在Elasticsearch中进行深分页
业务背景
在传统业务系统中,一个常见的信息展现方式就是“分页列表”,随着数据量的增大,就会遇到“深分页”问题。比如用户一页一页的翻,一直翻到第5万页。比如导出全部列表数据到excel,实现时一页一页的把数据追加到excel,直到导出全部数据。“深分页”通常的一个问题就是:随着页数越来越大,ES或者关系数据库响应越来越慢,甚至内存溢出OOM!其中的原理是什么呢?如何在ES中进行深分页呢?
技术原理
- 分页的本质 分页的本质是从“大的数据集”中取出一部分。比如10000条记录,每页10条数据。取第二页即第11条到20条数据。ES或者数据库怎么知道哪些数据是第二部分(第2页),哪些是第三部分(第3页)呢?答案是ES或者数据库不知道,所以正确的分页必须要指定分页的顺序,即要有order by或者sort语句。
- 单机数据库系统分页 单机数据库系统有一种分页实现叫做“先正序排后倒排序排”。即先对”offset+limit”的数据集根据order字段正序排列,然后再倒序找到limit条数据。
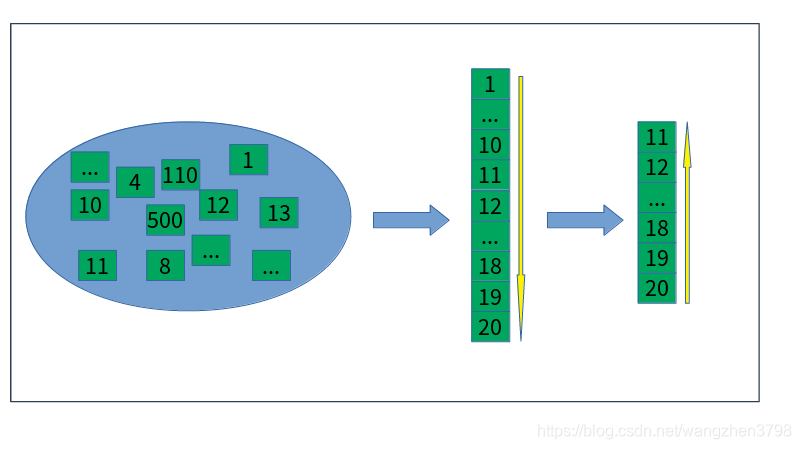
- 分布式数据库系统分页
分布式数据库系统相对于单机数据库系统,在各个节点取出limit条数据后,还要将各个节点的”limit”条数据汇总到master节点。由master节点对limit*N(节点数)再排序,找到最终的limit条数据返回给应用程序。所以在深分页时,offset+limit过大,要排序的数据过多,对于内存分页数据库很容易超过进程的内存限制,产生OOM!
限制查询1W条不让查询
查询超过1W条的话,ElasticSearch会帮我限制,限制查询不能超过1W条以上的数据,
如果想查询1W条以上的话,就配置’index.max_result_window’ 参数.
分页方式
在ES中有三种方式可以实现分页:from+size、scroll、search_after
方式一: from+size
ES的标准分页方法是from+size。from相当于postgresql的offset,size相当于limit的作用。每页10条数据,获取第11页的数据,其语法如下:
POST rzfx-sqlinfo/sqlinfo/_search{"query": {"bool": {"must": [{"term": {"architect.keyword": {"value": "郭锋"}}},{"range": {"NRunTime": {"lte": 100}}}]}},"size": 10,"from": 100}
ES为了保证分页不占用大量的堆内存,避免OOM,参数 index.max_result_window 设置了 from+size的最大值为10000。即每页10条的话,最多可以翻到1000页。index的全部参数可以通过以下语句查看:GET /rzfx-sqlinfo/_settings?flat_settings=true&include_defaults=true
对于结构比较简单、size比较小的文档,可以适当的扩大index.max_result_window参数,部分实现深分页。调整方式
PUT rzfx-sqlinfo/_settings{"index.max_result_window":100000}
方式二:scroll
scroll api提供了一个全局深度翻页的操作,首次请求会返回一个scroll_id,使用该scroll_id可以顺序获取下一批次的数据
案例
初始的搜索请求在查询字符串中指定 scroll 参数,这个参数会告诉 Elasticsearch 将 “search context” 保存多久。 例如:?scroll=5m
GET /db10/_search?&scroll=5m{"query": {"match_all": {}}, "sort": [{"_doc": {"order": "desc"}}], "size": 2}
反回结果
上面的请求返回的结果里会包含一个 _scroll_id ,我们需要把这个值传递给 scroll API ,用来取回下一批结果。
"_scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAzVUWazVqSWpwSm1UTUc5U1Y4OGN5SWN6QQ==","took" : 0,
执行下一页查询
GET _search/scroll{"scroll":"5m","scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAy_kWazVqSWpwSm1UTUc5U1Y4OGN5SWN6QQ=="}
删除scroll
当超出了 scroll timeout 时,搜索上下文会被自动删除。 保持 scrolls 打开是有成本的,当不再使用 scroll 时应当使用 clear-scroll API 进行显式清除
DELETE _search/scroll{"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAABZOkWazVqSWpwSm1UTUc5U1Y4OGN5SWN6QQ=="}
性能
案例DSL
scroll=5m 滚动分页标识
GET /filebeat-7.4.0-2019.10.17-000001/_search?&scroll=5m{"query": {"match_all": {}}, "sort": [{"_doc": {"order": "desc"}}], "size": 10}
结果
获得_scroll_id
观察took,此处消耗 15349ms
"_scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAFnssWeUdmZzFOcHBUeFdzVTVwMTVPVTZNZw==","took" : 15349,"timed_out" : false,"_shards" : {"total" : 1,
取上一步的_scroll_id
GET /_search/scroll{"scroll":"5m","scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAFm2IWeUdmZzFOcHBUeFdzVTVwMTVPVTZNZw=="}
结果
通过_scroll_id,滚动翻页锁消耗时间大致相同
观察took,此处消耗 2742ms
"_scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAFm2IWeUdmZzFOcHBUeFdzVTVwMTVPVTZNZw==","took" : 2742,"timed_out" : false,"_shards" : {"total" : 1,
方式三: search_after
5.0以后版本提供的功能 search_after分页方式,第一次搜索需要指定sort,并保证值是唯一的,用前一次查询结果中最后一条记录的 sort 结果值作为下一次的查询条件
案例
GET /db10/_search?pretty=true{"size": 1,"query": {"match_all": {}}, "sort": [{"age": {"order": "desc"}}]}
结果截取
},*"sort" : [22]*
检索下一页
“search_after”:基于上一页排序sort结果值检索下一页实现动态分页
GET /db10/_search?pretty=true{"size": 1,"query": {"match_all": {}},*"search_after": [ 22 ]*, "sort": [{"age": {"order": "desc"}}]}
性能
案例DSL
GET /filebeat-7.4.0-2019.10.17-000001/_search?pretty{"size": 20,"query": {"match_all": {}}, "sort": [{"@timestamp": {"order": "desc"}}]}
结果
观察”took” : 4825
"took" : 4825,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"sort" : [1571522951167]}
取下一页
“search_after”: [ 1571522951167 ] 取上一页最后一个sort值
GET /filebeat-7.4.0-2019.10.17-000001/_search?pretty
{
"size": 20,
"query": {
"match_all": {
}
},
"search_after": [ 1571522951167 ]
, "sort": [
{
"@timestamp": {
"order": "desc"
}
}
]
}
结果
观察”took” : 4318,
{
"took" : 4318,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
总结
- from+size
- 使用from+size方式进行分页,受max_result_window默认参数10000条文档的限制,不建议针对该参数进行修改
- 默认分页方式,适用小数据量场景,大数据量场景应避免使用
- 通过性能测试,随着分页越来越深,执行时间和堆内存使用逐渐升高的趋势,在并发情况下from+size容易 造成集群服务的OutOfMemory问题
- Scroll
- Scroll游标方式分页查询适用大数据量场景,只能向后增量查找,无法向前或者跳页查询,适用增量滚动抽取、数据迁移、重建索引等场景
- 通过性能案例分析,滚动分页查找性能消耗相差不大,不会像from+size方式随着分页的深入性能逐渐升高的问题,且不会存在OOM问题
- 该分页方式是查询的历史快照,对文档的更改(索引的更新或者删除)只会影响以后的搜索请求,不适用实时性查询场景
- search_after
- 分页方式弥补了 scroll 方式打开scroll 占用内存资源问题
- search_after可并行的拉取大量数据
- search_after分页方式通过唯一排序值定位,将每次需要处理的数据控制在一定范围,避免深度分页带来的开销,适用深度分页的场景

若有收获,就点个赞吧
0 人点赞
