出自
Elasticsearch文档写入原理
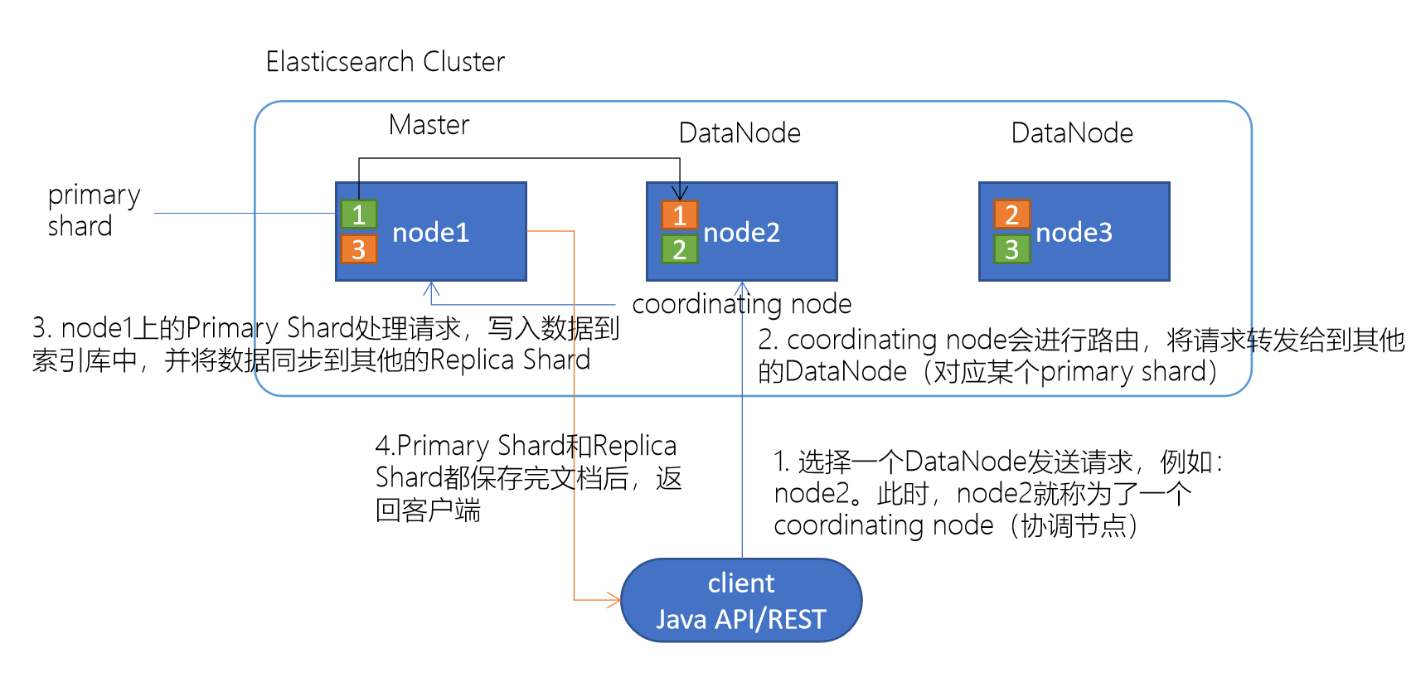
假如说Java客户端,或者是kibana等客户端发送写数据的请求的时候:
1.client会选择任意一个DataNode发送请求,例如:node2。此时,node2就成为一个coordinating node(协调节点)
2.协调节点计算得到文档要写入哪个主分片
计算的公式是: shard = hash(routing) % number_of_primary_shards
说明: routing 是一个可变值,默认是文档的 _id
3.coordinating node协调节点会进行路由,将请求转发给对应的primary shard所在的DataNode(假设primary shard在node1、replica shard在node2)
4.node1节点上的Primary Shard处理请求,写入数据到索引库中,并将数据同步到这个Primary Shard 对应的Replica Shard上
5.Primary Shard和Replica Shard都保存好了新插入的文档,将结果信息返回client,给client一个响应.
Elasticsearch检索原理
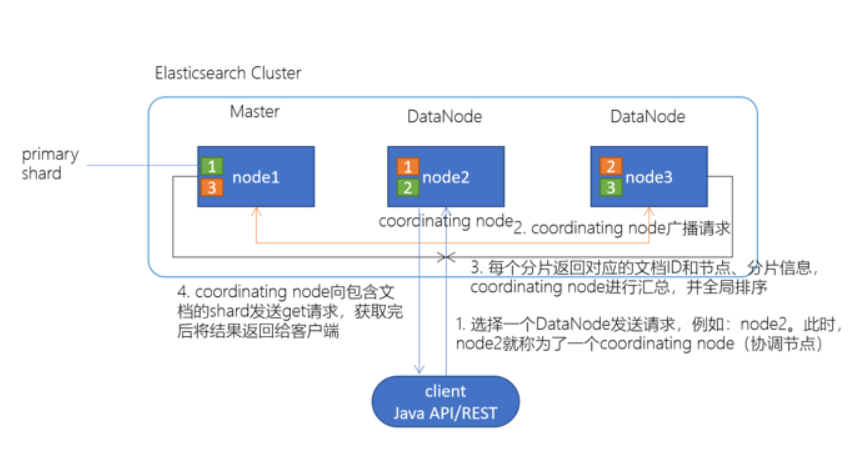
1.client发起查询请求,随机由某个DataNode接收到请求,该DataNode就会成为协调节点(Coordinating Node)
2. 协调节点(Coordinating Node)将查询请求广播到每一个数据节点的,这些数据节点的分片会处理该查询请求
3. 每个分片进行数据查询,将符合条件的数据放在一个优先队列中,并将这些数据的文档ID、节点信息、分片信息返回给协调节点
协调节点将所有的结果进行汇总,并进行全局排序
注意: 分片越多,查询的效率会有一定的影响的.因为要做数据的汇总.
4.协调节点向有这些文档ID的分片发送get请求,对应的分片收到请求之后会将这些ID对应的文档数据返回给协调节点,最后协调节点将数据返回给客户端

若有收获,就点个赞吧
0 人点赞
