ES 集群构成
首先,一个 Elasticsearch 集群 (下面简称 ES 集群) 是由许多节点 (Node) 构成的,Node 可以有不同的类型,通过以下配置,可以产生四种不同类型的 Node:
conf/elasticsearch.yml:node.master: true/falsenode.data: true/false
四种不同类型的 Node 是一个 node.master 和 node.data 的 true/false 的两两组合。当然还有其他类型的 Node,比如 IngestNode(用于数据预处理等),不在本文讨论范围内。
当 node.master 为 true 时,其表示这个 node 是一个 master 的候选节点,可以参与选举,在 ES 的文档中常被称作 master-eligible node,类似于 MasterCandidate。ES 正常运行时只能有一个 master(即 leader),多于 1 个时会发生脑裂。
当 node.data 为 true 时,这个节点作为一个数据节点,会存储分配在该 node 上的 shard 的数据并负责这些 shard 的写入、查询等。
此外,任何一个集群内的 node 都可以执行任何请求,其会负责将请求转发给对应的 node 进行处理,所以当 node.master 和 node.data 都为 false 时,这个节点可以作为一个类似 proxy 的节点,接受请求并进行转发、结果聚合等。
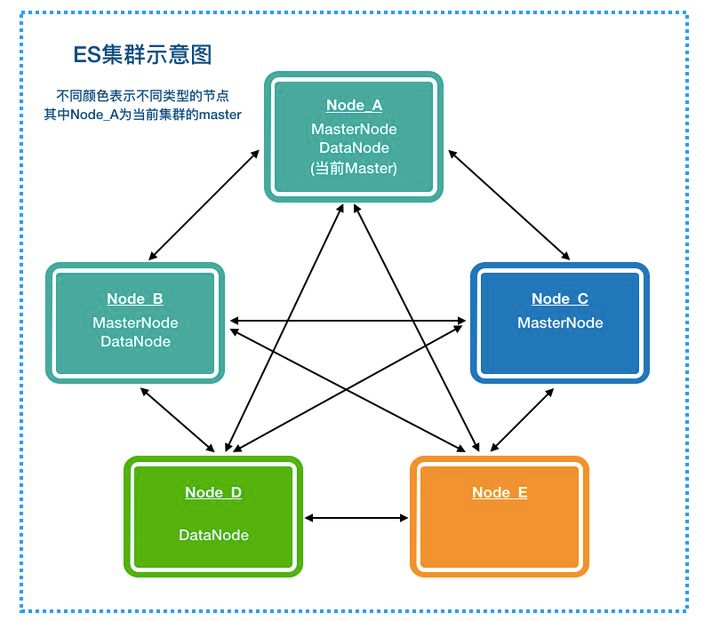
上图是一个 ES 集群的示意图,其中 NodeA 是当前集群的 Master,NodeB 和 NodeC 是 Master 的候选节点,其中 NodeA 和 NodeB 同时也是数据节点 (DataNode),此外,NodeD 是一个单纯的数据节点,Node_E 是一个 proxy 节点。每个 Node 会跟其他所有 Node 建立连接。
Master节点
master主要是管理ElasticSearch集群的元数据,比如说对索引的维护创建和删除,维护索引的元数据,节点增减和移除,维护集群的元数据.
默认情况下会自动选择出一台服务器节点作为master节点,但是说master不承载所在的请求,所以master不会是单点瓶颈
意思是说,集群所有请求如果都必须通过master去读取转发的话,那么整个集群性能就取决于master节点.而ElasticSearch的master不是这样,ElasticSearch的master只是比别的节点多了管理元数据的功能
Master选举
集群中可能会有多个 master-eligible node,此时就要进行 master 选举,保证只有一个当选 master。如果有多个 node 当选为 master,则集群会出现脑裂,脑裂会破坏数据的一致性,导致集群行为不可控,产生各种非预期的影响。
为了避免产生脑裂,ES 采用了常见的分布式系统思路,保证选举出的 master 被多数派 (quorum) 的 master-eligible node 认可,以此来保证只有一个 master。这个 quorum 通过以下配置进行配置:
conf/elasticsearch.yml:discovery.zen.minimum_master_nodes: 2
这个配置对于整个集群非常重要。
1 master 选举谁发起,什么时候发起?
master 选举当然是由 master-eligible 节点发起,当一个 master-eligible 节点发现满足以下条件时发起选举:
- 该 master-eligible 节点的当前状态不是 master。
- 该 master-eligible 节点通过 ZenDiscovery 模块的 ping 操作询问其已知的集群其他节点,没有任何节点连接到 master。
- 包括本节点在内,当前已有超过 minimum_master_nodes 个节点没有连接到 master。
总结一句话,即当一个节点发现包括自己在内的多数派的 master-eligible 节点认为集群没有 master 时,就可以发起 master 选举。
2 当需要选举 master 时,选举谁?
首先是选举谁的问题,如下面源码所示,选举的是排序后的第一个 MasterCandidate(即 master-eligible node)。
public MasterCandidate electMaster(Collection<MasterCandidate> candidates) {assert hasEnoughCandidates(candidates);List<MasterCandidate> sortedCandidates = new ArrayList<>(candidates);sortedCandidates.sort(MasterCandidate::compare);return sortedCandidates.get(0);}
那么是按照什么排序的?
public static int compare(MasterCandidate c1, MasterCandidate c2) {int ret = Long.compare(c2.clusterStateVersion, c1.clusterStateVersion);if (ret == 0) {ret = compareNodes(c1.getNode(), c2.getNode());}return ret;}
如上面源码所示,先根据节点的 clusterStateVersion 比较,clusterStateVersion 越大,优先级越高。clusterStateVersion 相同时,进入 compareNodes,其内部按照节点的 Id 比较 (Id 为节点第一次启动时随机生成)。
总结一下:
- 当 clusterStateVersion 越大,优先级越高。这是为了保证新 Master 拥有最新的 clusterState(即集群的 meta),避免已经 commit 的 meta 变更丢失。因为 Master 当选后,就会以这个版本的 clusterState 为基础进行更新。(一个例外是集群全部重启,所有节点都没有 meta,需要先选出一个 master,然后 master 再通过持久化的数据进行 meta 恢复,再进行 meta 同步)。
- 当 clusterStateVersion 相同时,节点的 Id 越小,优先级越高。即总是倾向于选择 Id 小的 Node,这个 Id 是节点第一次启动时生成的一个随机字符串。之所以这么设计,应该是为了让选举结果尽可能稳定,不要出现都想当 master 而选不出来的情况。
3 什么时候选举成功?
当一个 master-eligible node(我们假设为 Node_A) 发起一次选举时,它会按照上述排序策略选出一个它认为的 master。
- 假设 Node_A 选 Node_B 当 Master:
Node_A 会向 Node_B 发送 join 请求,那么此时:
(1) 如果 Node_B 已经成为 Master,Node_B 就会把 Node_A 加入到集群中,然后发布最新的 cluster_state, 最新的 cluster_state 就会包含 Node_A 的信息。相当于一次正常情况的新节点加入。对于 Node_A,等新的 cluster_state 发布到 Node_A 的时候,Node_A 也就完成 join 了。
(2) 如果 Node_B 在竞选 Master,那么 Node_B 会把这次 join 当作一张选票。对于这种情况,Node_A 会等待一段时间,看 Node_B 是否能成为真正的 Master,直到超时或者有别的 Master 选成功。
(3) 如果 Node_B 认为自己不是 Master(现在不是,将来也选不上),那么 Node_B 会拒绝这次 join。对于这种情况,Node_A 会开启下一轮选举。
- 假设 Node_A 选自己当 Master:
此时 NodeA 会等别的 node 来 join,即等待别的 node 的选票,当收集到超过半数的选票时,认为自己成为 master,然后变更 cluster_state 中的 master node 为自己,并向集群发布这一消息。
有兴趣的同学可以看看下面这段源码:
if (transportService.getLocalNode().equals(masterNode)) {final int requiredJoins = Math.max(0, electMaster.minimumMasterNodes() - 1);logger.debug("elected as master, waiting for incoming joins ([{}] needed)", requiredJoins);nodeJoinController.waitToBeElectedAsMaster(requiredJoins, masterElectionWaitForJoinsTimeout,new NodeJoinController.ElectionCallback() {@Overridepublic void onElectedAsMaster(ClusterState state) {synchronized (stateMutex) {joinThreadControl.markThreadAsDone(currentThread);}}@Overridepublic void onFailure(Throwable t) {logger.trace("failed while waiting for nodes to join, rejoining", t);synchronized (stateMutex) {joinThreadControl.markThreadAsDoneAndStartNew(currentThread);}}});} else {nodeJoinController.stopElectionContext(masterNode + " elected");final boolean success = joinElectedMaster(masterNode);synchronized (stateMutex) {if (success) {DiscoveryNode currentMasterNode = this.clusterState().getNodes().getMasterNode();if (currentMasterNode == null) {logger.debug("no master node is set, despite of join request completing. retrying pings.");joinThreadControl.markThreadAsDoneAndStartNew(currentThread);} else if (currentMasterNode.equals(masterNode) == false) {joinThreadControl.stopRunningThreadAndRejoin("master_switched_while_finalizing_join");}joinThreadControl.markThreadAsDone(currentThread);} else {joinThreadControl.markThreadAsDoneAndStartNew(currentThread);}}}
按照上述流程,我们描述一个简单的场景来帮助大家理解:
假如集群中有 3 个 master-eligible node,分别为 Node_A、 Node_B、 Node_C, 选举优先级也分别为 Node_A、Node_B、Node_C。三个 node 都认为当前没有 master,于是都各自发起选举,选举结果都为 Node_A(因为选举时按照优先级排序,如上文所述)。于是 Node_A 开始等 join(选票),Node_B、Node_C 都向 Node_A 发送 join,当 Node_A 接收到一次 join 时,加上它自己的一票,就获得了两票了 (超过半数),于是 Node_A 成为 Master。此时 cluster_state(集群状态) 中包含两个节点,当 Node_A 再收到另一个节点的 join 时,cluster_state 包含全部三个节点。
其它说明
Elasticsearch的选主是ZenDiscovery模块负责的,主要包含Ping(节点之间通过这个RPC来发现彼此)和Unicast(单播模块包含一个主机列表以控制哪些节点需要ping通)这两部分;
前置条件:
1)只有是候选主节点(master:true)的节点才能成为主节点。
2)最小主节点数(min_master_nodes)的目的是防止脑裂。
获取主节点的核心入口为 findMaster,选择主节点成功返回对应 Master,否则返回 null。
选举流程大致描述如下:
第一步:确认候选主节点数达标,elasticsearch.yml 设置的值 discovery.zen.minimum_master_nodes;
第二步:对所有候选主节点根据nodeId字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点。
第三步:如果对某个节点的投票数达到一定的值(候选主节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。
- 补充:
- 这里的 id 为 string 类型。
- master 节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data 节点可以关闭 http 功能。
详解:
master选举默认是由zendiscovery模块负责。
系统刚刚启动的时候,选取id最小的备选master为master节点。
系统运行起来之后,master和非master节点间是存在一个类似心跳检测的ping机制的,当master ping不到其他节点,或者其他节点ping不到master的时候,他们之间就会互相判断,是否大多数都连不到主节点上了,如果大多数都连不上,那么就开始重新进行master选举。
master选举的底层实现是对于所有的master备选节点的clustersate进行比较,选择最新的clusterstate节点作为主节点,如果有两个节点的clusterstate值相同,那么选择id较小也就是较早的node作为主节点。我猜测这样选举的原因是用最新clusterstate可以保证集群处在最近的版本中,避免陈旧数据或操作的出现导致数据冲突,而用最早id其实也就是应用最先生成的节点的原因,应该是为了保证集群的稳定,最小的id应该最早执行完所有的数据一致性及各种操作了,所以可以保证数据的相对稳定。这样选举出来的一个主节点如果被大多数的备选主节点同意选为主节点并且该节点也选择自己作为主节点,那么这个节点就可当选,否则进行下一轮选举,一直到选举成功。
这里有两个重要的配置,elasticsearch.yml文件中的
discovery.zen.ping.unicast.hosts[]:这是一个master备选节点的主机表,所有想要加入集群的节点都向他们发送请求来加入集群。
discovery.zen.mininum_master_nodes的数量最好设定为备选主节点数量/2+1.因为这个配置控制了选举的最少节点数,即最少这么多个节点投票通过才能选举出master,否则不行,这样,可以保证一个集群中只有一个主节点。
脑裂问题
什么是脑裂
比如共 20 个ElasticSearch节点,其中的 10 个选了一个 master,另外 10 个选了另一个 master 的情况,这就是脑裂.
脑裂现象就是一个集群因为网络超时或其他原因产生了两个或两个以上以上的主节点的情况,可以理解为一个大集群分裂成了多个小集群,这些小集群各自有各自的master,各自为政,能够自己对数据进行操作,导致大集群产生了数据不一致的现象,而当其中一个Master再次挂掉时,即便它恢复后回到了原有的集群,在它作为主Master期间写入的数据都会丢失,因为它上面维护了Index信息。
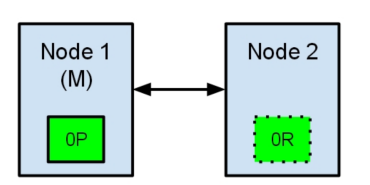
节点1在启动时被选举为主节点并保存主分片标记为0P,而节点2保存复制分片标记为0R
现在,如果在两个节点之间的通讯中断了,会发生什么?由于网络问题或只是因为其中一个节点无响应,这是有可能发生的。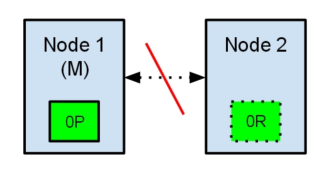
两个节点都相信对方已经挂了。节点1不需要做什么,因为它本来就被选举为主节点。但是节点2会自动选举它自己为主节点,因为它相信集群的一部分没有主节点了。
在elasticsearch集群,是有主节点来决定将分片平均的分布到节点上的。节点2保存的是复制分片,但它相信主节点不可用了。所以它会自动提升Node2节点为主节点。
现在我们的集群在一个不一致的状态了。打在节点1上的索引请求会将索引数据分配在主节点,同时打在节点2的请求会将索引数据放在分片上。在这种情况下,分片的两份数据分开了,如果不做一个全量的重索引很难对它们进行重排序。在更坏的情况下,一个对集群无感知的索引客户端(例如,使用REST接口的),这个问题非常透明难以发现,无论哪个节点被命中索引请求仍然在每次都会成功完成。问题只有在搜索数据时才会被隐约发现:取决于搜索请求命中了哪个节点,结果都会不同。
如何解决脑裂
当集群 master 候选数量不小于 3 个时,可以通过设置最少投票通过数量(discovery.zen.minimum_master_nodes)超过所有候选节点一半以上来解决脑裂问题;
当候选数量为两个时,只能修改为唯一的一个 master 候选,其他作为 data 节点,避免脑裂问题
为了避免脑裂,es采取了一个大多数原则的解决方案:即选举主节点时需要得到大多数的支持才可成功选举,需要配置文件中的discovery.zen.mininum_master_node的值为所有master备选主节点的数量/2+1保证大多数的有参选资格的主节点都承认某一节点的master身份才可以,感觉这样配置就类似于Leader选举了,超过半数承认这个节点是master身份才可以
这样就保证了另一部分分裂出去的有参选资格的节点永远也达不到n/2+1的数量,就保证了不会脑裂。
discovery.zen.minimum_master_nodes含义
discovery.zen.minimum_master_nodes的配置的意思是: 假如说 discovery.zen.minimum_master_nodes 参数为2,那么意思是至少有2个节点投票支持你,你才能成为master节点.
discovery.zen.minimum_master_nodes 默认值为1
discovery.zen.minimum_master_nodes 值设置讲究
官方推荐: master候选节点数量(有资格成为master节点的数量)/2+1
为什么这么设置呢.假如说有三台节点有资格成为master,ElasticSearch官方建议你discovery.zen.minimum_master_nodes 这个值最少配置为 3/2+1 ,就是2台
假如说你有五台节点有资格成为master,.那么ElasticSearch建议你discovery.zen.minimum_master_nodes 配置成5/2+1 , 就是3台.
比如我们有10个节点,都能维护数据,也可以是master候选节点,那么quorum就是10 / 2 + 1 = 6。
如果我们有三个master候选节点,还有100个数据节点,那么quorum就是3 / 2 + 1 = 2
如果我们有2个节点,都可以是master候选节点,那么quorum是2 / 2 + 1 = 2。此时就有问题了,因为如果一个node挂掉了,那么剩下一个master候选节点,是无法满足quorum数量的,也就无法选举出新的master,集群就彻底挂掉了。此时就只能将这个参数设置为1,但是这就无法阻止脑裂的发生了。
2个节点,discovery.zen.minimum_master_nodes分别设置成2和1会怎么样
综上所述,一个生产环境的es集群,至少要有3个节点,同时将这个参数设置为quorum,也就是2。discovery.zen.minimum_master_nodes设置为2,如何避免脑裂呢?
那么这个是参数是如何避免脑裂问题的产生的呢?比如我们有3个节点,quorum是2.现在网络故障,1个节点在一个网络区域,另外2个节点在另外一个网络区域,不同的网络区域内无法通信。这个时候有两种情况情况:
(1)如果master是单独的那个节点,另外2个节点是master候选节点,那么此时那个单独的master节点因为没有指定数量的候选master node在自己当前所在的集群内,因此就会取消当前master的角色,尝试重新选举,但是无法选举成功。然后另外一个网络区域内的node因为无法连接到master,就会发起重新选举,因为有两个master候选节点,满足了quorum,因此可以成功选举出一个master。此时集群中就会还是只有一个master。
(2)如果master和另外一个node在一个网络区域内,然后一个node单独在一个网络区域内。那么此时那个单独的node因为连接不上master,会尝试发起选举,但是因为master候选节点数量不到quorum,因此无法选举出master。而另外一个网络区域内,原先的那个master还会继续工作。这也可以保证集群内只有一个master节点。
综上所述,集群中master节点的数量至少3台,三台主节点通过在elasticsearch.yml中配置discovery.zen.minimum_master_nodes: 2,就可以避免脑裂问题的产生。
错误检测
1. MasterFaultDetection 与 NodesFaultDetection
这里的错误检测可以理解为类似心跳的机制,有两类错误检测,一类是 Master 定期检测集群内其他的 Node,另一类是集群内其他的 Node 定期检测当前集群的 Master。检查的方法就是定期执行 ping 请求。ES 文档:
There are two fault detection processes running. The first is by the master, to ping all the other nodes in the cluster and verify that they are alive. And on the other end, each node pings to master to verify if its still alive or an election process needs to be initiated.
如果 Master 检测到某个 Node 连不上了,会执行 removeNode 的操作,将节点从 cluste_state 中移除,并发布新的 cluster_state。当各个模块 apply 新的 cluster_state 时,就会执行一些恢复操作,比如选择新的 primaryShard 或者 replica,执行数据复制等。
如果某个 Node 发现 Master 连不上了,会清空 pending 在内存中还未 commit 的 new cluster_state,然后发起 rejoin,重新加入集群 (如果达到选举条件则触发新 master 选举)。
2. rejoin
除了上述两种情况,还有一种情况是 Master 发现自己已经不满足多数派条件 (>=minimumMasterNodes) 了,需要主动退出 master 状态 (退出 master 状态并执行 rejoin) 以避免脑裂的发生,那么 master 如何发现自己需要 rejoin 呢?
- 上面提到,当有节点连不上时,会执行 removeNode。在执行 removeNode 时判断剩余的 Node 是否满足多数派条件,如果不满足,则执行 rejoin。
if (electMasterService.hasEnoughMasterNodes(remainingNodesClusterState.nodes()) == false) {final int masterNodes = electMasterService.countMasterNodes(remainingNodesClusterState.nodes());rejoin.accept(LoggerMessageFormat.format("not enough master nodes (has [{}], but needed [{}])",masterNodes, electMasterService.minimumMasterNodes()));return resultBuilder.build(currentState);} else {return resultBuilder.build(allocationService.deassociateDeadNodes(remainingNodesClusterState, true, describeTasks(tasks)));}
- 在 publish 新的 cluster_state 时,分为 send 阶段和 commit 阶段,send 阶段要求多数派必须成功,然后再进行 commit。如果在 send 阶段没有实现多数派返回成功,那么可能是有了新的 master 或者是无法连接到多数派个节点等,则 master 需要执行 rejoin。
try {publishClusterState.publish(clusterChangedEvent, electMaster.minimumMasterNodes(), ackListener);} catch (FailedToCommitClusterStateException t) {logger.debug("failed to publish cluster state version [{}] (not enough nodes acknowledged, min master nodes [{}])",newState.version(), electMaster.minimumMasterNodes());synchronized (stateMutex) {pendingStatesQueue.failAllStatesAndClear(new ElasticsearchException("failed to publish cluster state"));rejoin("zen-disco-failed-to-publish");}throw t;}
- 在对其他节点进行定期的 ping 时,发现有其他节点也是 master,此时会比较本节点与另一个 master 节点的 cluster_state 的 version,谁的 version 大谁成为 master,version 小的执行 rejoin。
if (otherClusterStateVersion > localClusterState.version()) {rejoin("zen-disco-discovered another master with a new cluster_state [" + otherMaster + "][" + reason + "]");} else {logger.warn("discovered [{}] which is also master but with an older cluster_state, telling [{}] to rejoin the cluster ([{}])", otherMaster, otherMaster, reason);try {transportService.connectToNode(otherMaster);transportService.sendRequest(otherMaster, DISCOVERY_REJOIN_ACTION_NAME, new RejoinClusterRequest(localClusterState.nodes().getLocalNodeId()), new EmptyTransportResponseHandler(ThreadPool.Names.SAME) {@Overridepublic void handleException(TransportException exp) {logger.warn((Supplier<?>) () -> new ParameterizedMessage("failed to send rejoin request to [{}]", otherMaster), exp);}});} catch (Exception e) {logger.warn((Supplier<?>) () -> new ParameterizedMessage("failed to send rejoin request to [{}]", otherMaster), e);}}
Elasticsearch中的节点(比如共20个),其中的10个选了一个master,另外10个选了另一个master,怎么办?
当集群master候选数量不小于3个时,可以通过设置最少投票通过数量(discovery.zen.minimum_master_nodes)超过所有候选节点一半以上来解决脑裂问题;
当候选数量为两个时,只能修改为唯一的一个master候选,其他作为data节点,避免脑裂问题。
es的分布式架构原理能说一下么(es是如何实现分布式的啊)?
ElasticSearch底层基于Lucene开发的.
假设三台机器组成集群,ElasticSearch用来存储数据的基本单位是索引
es中存储数据的基本单位是索引,比如说你现在要在es中存储一些订单数据,你就应该在es中创建一个索引,order_idx,所有的订单数据就都写到这个索引里面去,一个索引差不多就是相当于是mysql里的一张表。index -> type -> mapping -> document -> field。
index:mysql里的一张表
type:没法跟mysql里去对比,一个index里可以有多个type,每个type的字段都是差不多的,但是有一些略微的差别。
好比说,有一个index,是订单index,里面专门是放订单数据的。就好比说你在mysql中建表,有些订单是实物商品的订单,就好比说一件衣服,一双鞋子;有些订单是虚拟商品的订单,就好比说游戏点卡,话费充值。就两种订单大部分字段是一样的,但是少部分字段可能有略微的一些差别。
所以就会在订单index里,建两个type,一个是实物商品订单type,一个是虚拟商品订单type,这两个type大部分字段是一样的,少部分字段是不一样的。
很多情况下,一个index里可能就一个type,但是确实如果说是一个index里有多个type的情况,你可以认为index是一个类别的表,具体的每个type代表了具体的一个mysql中的表.
每个type有一个mapping,如果你认为一个type是一个具体的一个表,index代表了多个type的同属于的一个类型,mapping就是这个type的表结构定义,你在mysql中创建一个表,肯定是要定义表结构的,里面有哪些字段,每个字段是什么类型。。。
mapping就代表了这个type的表结构的定义,定义了这个type中每个字段名称,字段是什么类型的,然后还有这个字段的各种配置
实际上你往index里的一个type里面写的一条数据,叫做一条document,一条document就代表了mysql中某个表里的一行给,每个document有多个field,每个field就代表了这个document中的一个字段的值
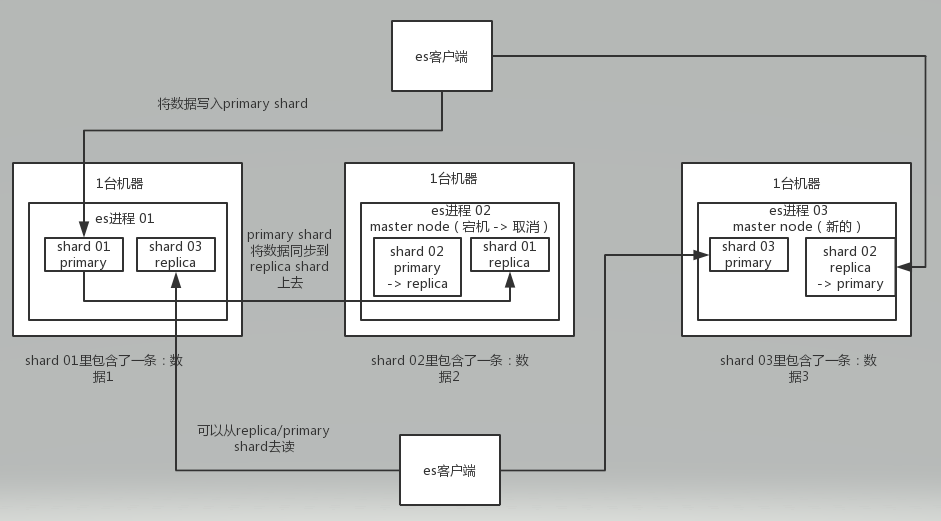
接着你搞一个索引,这个索引可以拆分成多个shard,多个shard在ElasticSearch集群的多台机器上,每个shard存储一部分数据.
接着就是这个shard的数据实际是有多个备份,就是说每个shard都有一个primary shard,负责写入数据,但是还有几个replica shard。primary shard写入数据之后,会将数据同步到其他几个replica shard上去。
通过这个replica的方案,每个shard的数据都有多个备份,如果某个机器宕机了,没关系啊,还有别的数据副本在别的机器上呢。高可用了吧。
es集群多个节点,会自动选举一个节点为master节点,这个master节点其实就是干一些管理的工作的,比如维护索引元数据拉,负责切换primary shard和replica shard身份拉,故障转移之类的,主要做集群的全局性的监控和把控等等.
要是master节点宕机了,那么shard02 primary 和shard01 replica都死了 ,那么ElasticSearch会在剩下的节点里面重新选举一个节点为master节点。然后新的Master识别出来shard02 primary 和shard01 replica没了,会把shard02 replica 的 变成 shard02 primary .后续客户端还可以往这个新的shard02 primary 里面去写.
如果是非master节点宕机了,那么会由master节点,让那个宕机节点上的primary shard的身份转移到其他机器上的replica shard。急着你要是修复了那个宕机机器,重启了之后,master节点会控制将缺失的replica shard分配过去,同步后续修改的数据之类的,让集群恢复正常。
客户端如果要读某个shard里面的数据,比如说shard01,那么可以从这个primaryShard 01里面去读,也可以从replica shard 01 里面去读.
如果之前宕机的机器故障好了,正常启动了,那么会变成从节点,这台机器里面的shard如果是primary的话,会自动变成replica shard.
其实上述就是elasticsearch作为一个分布式搜索引擎最基本的一个架构设计
ElasticSearch集群容灾
分布式的集群是一定要具备容灾能力的,对于es集群同样如此,那es集群是如何进行容灾的呢?接下来听我娓娓道来。
在前文我们详细讲解了primary shard和replica shard。replica shard作为primary shard的副本当集群中的节点发生故障,replica shard将被提升为primary shard。具体的演示如下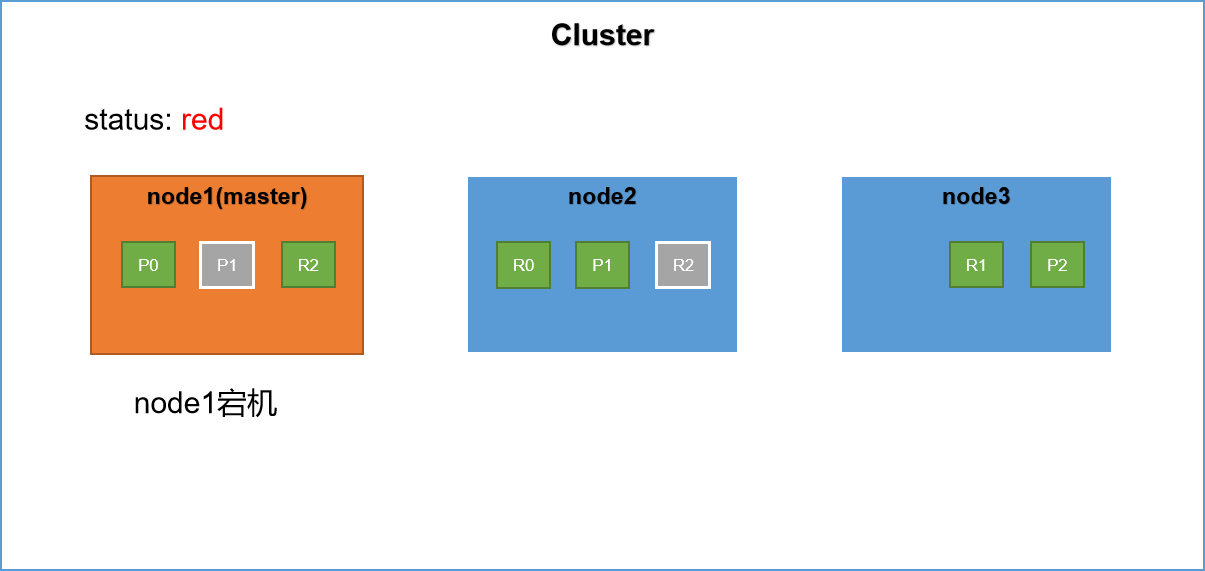
集群中有三台服务器,其中node1节点为master节点,primary shard 和 replica shard的分布如上图所示。此时假设node1发生宕机,也就是master节点发生宕机。此时集群的健康状态为red,为什么呢?因为不是所有的primary shard都是active的。
具体的容灾过程如下:
1,重新选举master节点,当es集群中的master节点发生故障,此时es集群将再次进行master的选举,选举出一个新的master节点。假设此时新的主节点为node2。
2,node2被选举为新的master节点,node2将作为master行驶其分片分配的任务。
3,replica shard升级,此时master节点会寻找node1节点上的P0分片的replica shard,发现其副本在node2节点上,然后将R0提升为primary shard。这个升级过程是瞬间完成的,就像按下一个开关一样。因为每一个shard其实都是lucene的实例。此时集群如下所示,集群的健康状态为yellow,因为不是每一个replica shard都是active的。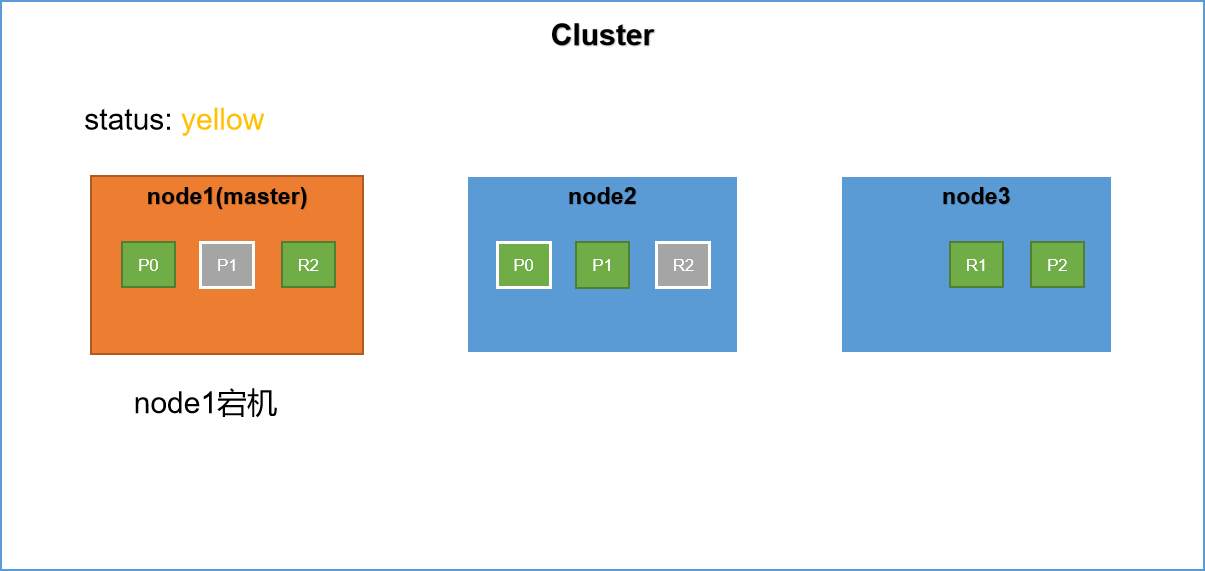
容灾的过程如上所示,其实这也是一般分布式中间件容灾备份的一般手段。如果你很了解kafka的话,这个就很容易理解了。
架构原理
1、Elasticsearch的节点类型
在Elasticsearch主要分成两类节点,一类是Master,一类是DataNode。
1.1 Master节点
在Elasticsearch启动时,会选举出来一个Master节点。当某个节点启动后,然后使用Zen Discovery机制找到集群中的其他节点,并建立连接。
discovery.seed_hosts: [“192.168.21.130”, “192.168.21.131”, “192.168.21.132”]
并从候选主节点中选举出一个主节点。
cluster.initial_master_nodes: [“node1”, “node2”,”node3”]
Master节点主要负责:
- 管理索引(创建索引、删除索引)、分配分片
2. 维护元数据
3. 管理集群节点状态
4. 不负责数据写入和查询, node节点才负责数据的写入和查询.
一个Elasticsearch集群中,只有一个Master节点。在生产环境中,内存可以相对小一点,但机器要稳定。
1.2 DataNode节点
node主要负责功能
在Elasticsearch集群中,会有N个DataNode节点。DataNode节点主要负责:
数据写入、数据检索,大部分Elasticsearch的压力都在DataNode节点上
在生产环境中,内存最好配置大一些
Rebalance扩容机制
如果一台服务器有两个shard,这台服务器的请求量和负载量会大一些,假如说新采购了一台机器加入到ElasticSearch集群里面,此时那个有两个shard的服务器会自动把自己的一个shard转移到这个新加入到ElasticSearch集群的服务器上.
总有某些服务器的请求量和负载量会大一些.ElasticSearch会自动的根据当前的机器情况进行负载均衡尽量让每台服务器处理请求均匀一些.
ES对复杂分布式机制的透明隐藏特性
Elasticsearch是一套分布式的系统,分布式是为了应对大数据量,ElasticSearch隐藏了复杂的分布式机制.我们只需要通过api调用es完成业务代码就可以了,底层无需关心.
隐藏了哪分布式机制
1.分片机制:
我们之前随随便便就将一些document插入到es集群中去了,我们有没有关心过数据怎么进行分片的,数据到哪个shard中去.
2.cluster discovery
群发现机制,我们之前在做那个集群status从yellow转green的实验里,直接启动了第二个es进程,那个进程作为一个node自动就发现了集群,并且加入了进去,还接受了部分数据,replica shard.
3.shard负载均衡
举例,假设现在有3个节点,总共有25个shard要分配到3个节点上去,es会自动进行均匀分配,以保持每个节点的均衡的读写负载请求.
4.shard副本
请求路由,集群扩容,shard重分配.
节点平等的分布式架构
节点对等的意思是,每个节点都能接收所有的请求
任何节点接收到请求之后都可以自由路由到由相关的其它节点上去处理请求.
原始的节点会负责从其它节点采集相关的数据,最后将数据处理完了返回给客户端.
比如说请求一个document,而document是存储在多个shard上的,每个shard只是存储document的部分数据的,假如说web客户端将读取这个document请求发送给了shard1上.
此时shard1发现这个document不在自己节点上,就会给这个请求转发给有document的那个shard2上, shard2处理完请求就会给结果返回给shard1,shard1再将结果返回给web客户端.
解释一下 Elasticsearch Node
节点是 Elasticsearch 的实例。实际业务中,我们会说:ES 集群包含 3 个节点、7 个节点。
这里节点实际就是:一个独立的 Elasticsearch 进程,一般将一个节点部署到一台独立的服务器或者虚拟机、容器中。
不同节点根据角色不同,可以划分为:
主节点
帮助配置和管理在整个集群中添加和删除节点。
数据节点
存储数据并执行诸如 CRUD(创建/读取/更新/删除)操作,对数据进行搜索和聚合的操作。
1、 客户端节点(或者说:协调节点) 将集群请求转发到主节点,将与数据相关的请求转发到数据节点。
2、 摄取节点
用于在索引之前对文档进行预处理。
集群健康状态
如何快速了解集群的健康状况?green、yellow、red?
green:每个索引的primary shard和replica shard都是active状态的
yellow:每个索引的primary shard都是active状态的,但是部分replica shard不是active状态,处于不可用的状态
red:不是所有索引的primary shard都是active状态的,部分索引有数据丢失了
集群什么情况会处于red状态?
有一台服务器宕机之后,集群就会出现red状态
集群什么情况会处于一个yellow状态?
假设现在就一台linux服务器,就启动了一个es进程,相当于就只有一个node。现在es中有一个index,就是kibana自己内置建立的index。由于默认的配置是给每个index分配1个primary shard和1个replica shard,而且primary shard和replica shard不能在同一台机器上(为了容错)。
现在kibana自己建立的index是1个primary shard和1个replica shard。当前就一个node,所以只有1个primary shard被分配了和启动了,但是一个replica shard没有第二台机器去启动(因为当前只有一台机器启动)。 所以此时集群状态是yellow状态.
当启动第二个es进程,就会在es集群中有2个node,然后那1个replica shard就会自动分配过去,然后cluster status就会变成green状态。
https://www.yuque.com/docs/share/3cd35127-c5a1-4bb7-a910-0ea19025261e?# 《Elasticsearch 集群健康状态》

若有收获,就点个赞吧
0 人点赞
