比如说MySQL表与表之间会有关联关系,
ES 提供了类似关系型数据库中 Join 的实现。使用 Join 数据类型实现,可以通过 Parent / Child 的关系,从而分离两个对象
父文档和子文档是两个独立的文档
更新父文档无需重新索引整个子文档。子文档被新增,更改和删除也不会影响到父文档和其他子文档。
要点:父子关系元数据映射,用于确保查询时候的高性能,但是有一个限制,就是父子数据必须存在于一个shard中
父子关系数据存在一个shard中,而且还有映射其关联关系的元数据,那么搜索父子关系数据的时候,不用跨分片,一个分片本地自己就搞定了,性能当然高
父子关系
- 定义父子关系的几个步骤
- 设置索引的 Mapping
- 索引父文档
- 索引子文档
- 按需查询文档
设置 Mapping

PUT my_blogs{"mappings": {"properties": {"blog_comments_relation": {"type": "join","relations": {"blog": "comment"}},"content": {"type": "text"},"title": {"type": "keyword"}}}}
插入数据
往父索引里面插入数据
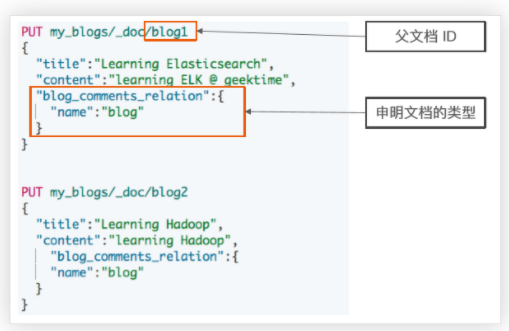
PUT my_blogs/_doc/blog1{"title": "Learning Elasticsearch","content": "learning ELK is happy","blog_comments_relation": {"name": "blog" // 这个名字不能随便写}}PUT my_blogs/_doc/blog2{"title": "Learning Hadoop","content": "learning Hadoop","blog_comments_relation": {"name": "blog"}}
往子索引库添加信息
- 父文档和子文档必须存在相同的分片上
- 确保查询 join 的性能
- 当指定文档时候,必须指定它的父文档 ID
- 使用 route 参数来保证,分配到相同的分片
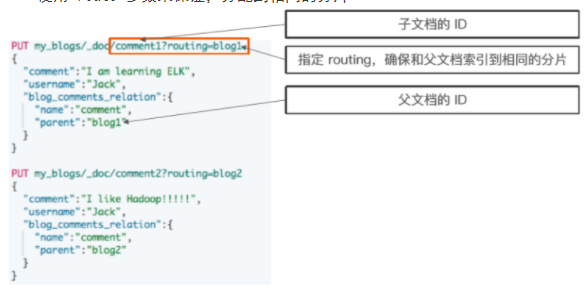
PUT my_blogs/_doc/comment1?routing=blog1{"comment": "I am learning ELK","username": "Jack","blog_comments_relation": {"name": "comment","parent": "blog1"}}PUT my_blogs/_doc/comment2?routing=blog2{"comment": "I like Hadoop!!!!!","username": "Jack","blog_comments_relation": {"name": "comment","parent": "blog2"}}PUT my_blogs/_doc/comment3?routing=blog2{"comment": "Hello Hadoop","username": "Bob","blog_comments_relation": {"name": "comment","parent": "blog2"}}
查询
Parent / Child 所支持的查询
- 查询所有文档
- Parent Id 查询
- Has Child 查询
- Has Parent 查询
查询所有文档
POST my_blogs/_search{}
结果
{"took" : 611,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 5,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "my_blogs","_type" : "_doc","_id" : "blog1","_score" : 1.0,"_source" : {"title" : "Learning Elasticsearch","content" : "learning ELK is happy","blog_comments_relation" : {"name" : "blog"}}},{"_index" : "my_blogs","_type" : "_doc","_id" : "blog2","_score" : 1.0,"_source" : {"title" : "Learning Hadoop","content" : "learning Hadoop","blog_comments_relation" : {"name" : "blog"}}},{"_index" : "my_blogs","_type" : "_doc","_id" : "comment1","_score" : 1.0,"_routing" : "blog1","_source" : {"comment" : "I am learning ELK","username" : "Jack","blog_comments_relation" : {"name" : "comment","parent" : "blog1"}}},{"_index" : "my_blogs","_type" : "_doc","_id" : "comment2","_score" : 1.0,"_routing" : "blog2","_source" : {"comment" : "I like Hadoop!!!!!","username" : "Jack","blog_comments_relation" : {"name" : "comment","parent" : "blog2"}}},{"_index" : "my_blogs","_type" : "_doc","_id" : "comment3","_score" : 1.0,"_routing" : "blog2","_source" : {"comment" : "Hello Hadoop","username" : "Bob","blog_comments_relation" : {"name" : "comment","parent" : "blog2"}}}]}}
根据父文档ID查看
GET my_blogs/_doc/blog2
结果
{"_index" : "my_blogs","_type" : "_doc","_id" : "blog2","_version" : 1,"_seq_no" : 1,"_primary_term" : 1,"found" : true,"_source" : {"title" : "Learning Hadoop","content" : "learning Hadoop","blog_comments_relation" : {"name" : "blog"}}}
根据Parent Id 查询评论信息
POST my_blogs/_search{"query": {"parent_id": {"type": "comment","id": "blog2"}}}
结果
{"took" : 4,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 0.53899646,"hits" : [{"_index" : "my_blogs","_type" : "_doc","_id" : "comment2","_score" : 0.53899646,"_routing" : "blog2","_source" : {"comment" : "I like Hadoop!!!!!","username" : "Jack","blog_comments_relation" : {"name" : "comment","parent" : "blog2" //父id}}},{"_index" : "my_blogs","_type" : "_doc","_id" : "comment3","_score" : 0.53899646,"_routing" : "blog2","_source" : {"comment" : "Hello Hadoop","username" : "Bob","blog_comments_relation" : {"name" : "comment","parent" : "blog2" //父id}}}]}}
Has Child 查询,返回父文档
查找 username 包含 jack 的
POST my_blogs/_search{"query": {"has_child": {"type": "comment","query": {"match": {"username": "Jack"}}}}}
结果
{"took" : 19,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "my_blogs","_type" : "_doc","_id" : "blog1","_score" : 1.0,"_source" : {"title" : "Learning Elasticsearch","content" : "learning ELK is happy","blog_comments_relation" : {"name" : "blog"}}},{"_index" : "my_blogs","_type" : "_doc","_id" : "blog2","_score" : 1.0,"_source" : {"title" : "Learning Hadoop","content" : "learning Hadoop","blog_comments_relation" : {"name" : "blog"}}}]}}
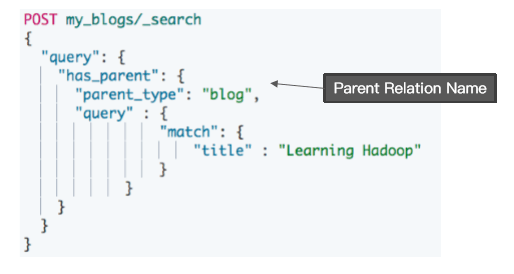
Has Parent 查询,返回相关的子文档
根据博客的标题来找, 父类型是 blog
父文档是博客,我的查询条件是 标题是 “Learning Hadoop”
POST my_blogs/_search{"query": {"has_parent": {"parent_type": "blog","query": {"match": {"title": "Learning Hadoop"}}}}}
结果
{"took" : 17,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "my_blogs","_type" : "_doc","_id" : "comment2","_score" : 1.0,"_routing" : "blog2","_source" : {"comment" : "I like Hadoop!!!!!","username" : "Jack","blog_comments_relation" : {"name" : "comment","parent" : "blog2"}}},{"_index" : "my_blogs","_type" : "_doc","_id" : "comment3","_score" : 1.0,"_routing" : "blog2","_source" : {"comment" : "Hello Hadoop","username" : "Bob","blog_comments_relation" : {"name" : "comment","parent" : "blog2"}}}]}}
使用 has_child 查询
- 返回父文档
- 通过对子文档进行查询
返回具体相关子文档的父文档
父子文档在相同的分片上,因此 Join 效率高

使用 has_parent 查询
- 返回相关性的子文档
- 通过对父文档进行查询
- 返回相关的子文档
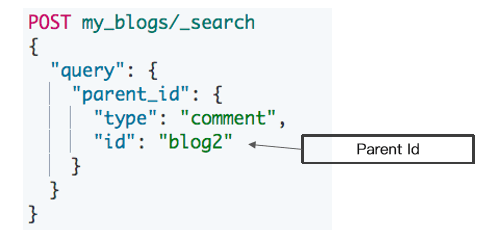
使用 parent_id 查询
- 返回所有相关子文档
- 通过对付文档 Id 进行查询
- 返回所有相关的子文档
访问子文档
- 需指定父文档 routing 参数

#通过ID ,访问子文档GET my_blogs/_doc/comment2#通过ID和routing ,访问子文档GET my_blogs/_doc/comment3?routing=blog2
更新子文档
- 更新子文档不会影响到父文档
PUT my_blogs/_doc/comment3?routing=blog2{"comment": "Hello Hadoop??","blog_comments_relation": {"name": "comment","parent": "blog2"}}
嵌套对象 v.s 父子文档
Nested Object Parent / Child
优点:文档存储在一起,读取性能高、父子文档可以独立更新
缺点:更新嵌套的子文档时,需要更新整个文档、需要额外的内存去维护关系。读取性能相对差
适用场景子文档偶尔更新,以查询为主、子文档更新频繁

若有收获,就点个赞吧
0 人点赞
