什么是Elasticsearch?
Elasticsearch 是一个基于 Lucene 的搜索引擎。它提供了具有 HTTP Web 界面和无架构 JSON 文档的分布式,多租户能力的全文搜索引擎。
Elasticsearch 是用 Java 开发的,根据 Apache 许可条款作为开源发布
为什么要使用Elasticsearch?
因为在我们商城中的数据,将来会非常多,所以采用以往的模糊查询,模糊查询前置配置,会放弃索引,导致商品查询是全表扫面,在百万级别的数据库中,效率非常低下,而我们使用ES做一个全文索引,我们将经常查询的商品的某些字段,比如说商品名,描述、价格还有id这些字段我们放入我们索引库里,可以提高查询速度。
1、Elasticsearch的功能
(1)分布式的搜索引擎和数据分析引擎
搜索:百度,网站的站内搜索,IT系统的检索
数据分析:电商网站,最近7天牙膏这种商品销量排名前10的商家有哪些;新闻网站,最近1个月访问量排名前3的新闻版块是哪些
分布式,搜索,数据分析
(2)全文检索,结构化检索,数据分析
(3)对海量数据进行近实时的处理
分布式:ES自动可以将海量数据分散到多台服务器上去存储和检索
海联数据的处理:分布式以后,就可以采用大量的服务器去存储和检索数据,自然而然就可以实现海量数据的处理了
近实时:检索个数据要花费1小时就不是近实时,ElasticSearch可以在在秒级别对数据进行搜索和分析
2、Elasticsearch的适用场景
国外
(1)维基百科,类似百度百科,牙膏,牙膏的维基百科,全文检索,高亮,搜索推荐
(2)The Guardian(国外新闻网站),类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+社交网络数据(对某某新闻的相关看法),数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,坏,热门,垃圾,鄙视,崇拜)
(3)Stack Overflow(国外的程序异常讨论论坛),IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案
(4)GitHub(开源代码管理),搜索上千亿行代码
(5)电商网站,检索商品
(6)日志数据分析,logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana)
(7)商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅牙膏的监控,如果高露洁牙膏的家庭套装低于50块钱,就通知我,我就去买
(8)BI系统,商业智能,Business Intelligence。比如说有个大型商场集团,BI,分析一下某某区域最近3年的用户消费金额的趋势以及用户群体的组成构成,产出相关的数张报表,**区,最近3年,每年消费金额呈现100%的增长,而且用户群体85%是高级白领,开一个新商场。ES执行数据分析和挖掘,Kibana进行数据可视化
国内
(9)国内:站内搜索(电商,招聘,门户,等等),IT系统搜索(OA,CRM,ERP,等等),数据分析(ES热门的一个使用场景)
Elasticsearch的特点
1.实时分析
2.分布式实时文件存储,并将每一个字段都编入索引
3.文档导向,所有的对象全部是文档
4.高可用性,易扩展,支持集群(Cluster)、分片和复制(Shards 和 Replicas) 接口友好,支持 JSON
(1)可以作为一个大型分布式集群(数百台服务器)技术,处理PB级数据,服务大公司;也可以运行在单机上,服务小公司
(2)Elasticsearch不是什么新技术,主要是将全文检索、数据分析以及分布式技术,合并在了一起,才形成了独一无二的ES;lucene(全文检索),商用的数据分析软件(也是有的),分布式数据库(mycat)
(3)对用户而言,是开箱即用的,非常简单,作为中小型的应用,直接3分钟部署一下ES,就可以作为生产环境的系统来使用了,数据量不大,操作不是太复杂
(4)数据库的功能面对很多领域是不够用的(事务,还有各种联机事务型的操作);特殊的功能,比如全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理;Elasticsearch作为传统数据库的一个补充,提供了数据库所不不能提供的很多功能
ES 相关概念
Node: 装有一个 ES 服务器的节点。
Cluster: 有多个 Node 组成的集群
Document: 一个可被搜素的基础信息单元
Index: 拥有相似特征的文档的集合
Type: 一个索引中可以定义一种或多种类型
Filed: 是 ES 的最小单位,相当于数据的某一列
Shards: 索引的分片,每一个分片就是一个 Shard
Replicas: 索引的拷贝
什么是分词器
分词是将文本转换成一系列单词(Term or Token)的过程,也可以叫文本分析,在 ES
里面称为 Analysis
分词器是 ES 中专门处理分词的组件,英文为 Analyzer,它的组成如下:
Character Filters:针对原始文本进行处理,比如去除 html 标签
Tokenizer:将原始文本按照一定规则切分为单词
Token Filters:针对 Tokenizer 处理的单词进行再加工,比如转小写、删除或增新等
处理
ES 提供了一个可以测试分词的 API 接口,方便验证分词效果,endpoint 是_analyze
ES 也提供了很多内置的分析器。
ElasticSearch中的集群、节点、索引、文档、类型是什么?
群集是一个或多个节点(服务器)的集合,它们共同保存您的整个数据,并提供跨所有节点的联合索引和搜索功能。群集由唯一名称标识,默认情况下为“elasticsearch”。此名称很重要,因为如果节点设置为按名称加入群集,则该节点只能是群集的一部分。
节点是属于集群一部分的单个服务器。它存储数据并参与群集索引和搜索功能。
索引就像关系数据库中的“数据库”。它有一个定义多种类型的映射。索引是逻辑名称空间,映射到一个或多个主分片,并且可以有零个或多个副本分片。 MySQL =>数据库 ElasticSearch =>索引
文档类似于关系数据库中的一行。不同之处在于索引中的每个文档可以具有不同的结构(字段),但是对于通用字段应该具有相同的数据类型。 MySQL => Databases => Tables => Columns / Rows ElasticSearch => Indices => Types =>具有属性的文档
类型是索引的逻辑类别/分区,其语义完全取决于用户。
ElasticSearch为什么要比MySQL搜索性能高
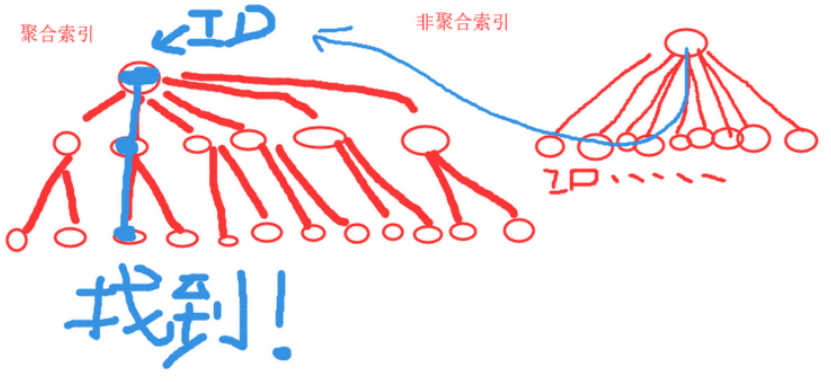
数据库的索引是B+tree结构
主键是聚合索引 其他索引是非聚合索引,先从非聚合索引找,见下图
MySQL找数据
ElasticSearch

对于倒排索引,要分两种情况:
1、基于分词后的全文检索
基于分词后的全文检索:例如select * from test where name like ‘%张三%’,对于关系型数据库mysql来说简直是一种灾难,因为会进行全表检索,如果是搜索头几个字符的话,可能还好一点. 但是对es而言分词后,每个字都可以利用FST高速找到倒排索引的位置,并迅速获取文档id列表,大大的提升了性能减少了磁盘IO。
这种情况是es的强项,而对于mysql关系型数据库而言完全是灾难
因为es分词后,每个字都可以利用FST高速找到倒排索引的位置,并迅速获取文档id列表
但是对于mysql检索中间的词只能全表扫(如果不是搜头几个字符)
2、精确检索
这种情况我想两种相差不大,有些情况下mysql的可能会更快些
如果mysql的非聚合索引用上了覆盖索引,无需回表,则速度可能更快
es还是通过FST找到倒排索引的位置并获取文档id列表,再根据文档id获取文档并根据相关度算分进行排序,但es还有个杀手锏,即天然的分布式使得在大数据量面前可以通过分片降低每个分片的检索规模,并且可以并行检索提升效率
用filter时更是可以直接跳过检索直接走缓存
3.多条件查询
mysql除非使用联合索引,将每个查询的字段都建立联合索引,如果是两个字段上有两个不同的索引,那么mysql将会选择一个索引使用,然后将得到的结果写入内存中使用第二个条件过滤后,得到最终的答案
es,可以进行真正的联合查询,将两个字段上查询出来的结果进行“并”操作或者“与”操作,如果是filter可以使用bitset,如果是非filter使用skip list进行
什么是ElasticSearch中的编译器?
编译器用于将字符串分解为术语或标记流。一个简单的编译器可能会将字符串拆分为任何遇到空格或标点的地方。Elasticsearch有许多内置标记器,可用于构建自定义分析器。
ElasticSearch中的分析器是什么?
在ElasticSearch中索引数据时,数据由为索引定义的Analyzer在内部进行转换。 分析器由一个Tokenizer和零个或多个TokenFilter组成。编译器可以在一个或多个CharFilter之前。分析模块允许您在逻辑名称下注册分析器,然后可以在映射定义或某些API中引用它们。
Elasticsearch附带了许多可以随时使用的预建分析器。或者,您可以组合内置的字符过滤器,编译器和过滤器器来创建自定义分析器。

若有收获,就点个赞吧
0 人点赞
