1 Java开发环境
1.1 基础知识
Java的跨平台
为什么用c或c++写的程序能直接在Window操作系统上运行?因为Window操作系统本身就是用c或c++编写的,所以用c或c++些的程序Window能将转换成物理二进制字节码直接运行。同理,C#语言也能直接运行,而Java程序是用Window操作系统不能将其转换成物理二进制字节码,所以必须要安装Java虚拟机,由这个虚拟机将其转换测成操作系统所能识别字节码。然后转换成物理二进制字节码。
注意:虚拟机是不可能跨平台的,这个虚拟机就是解析我们Java程序的,由这个虚拟机将程序转换成操作系统所能识别的字节码,再由操作系统将其转成物理机器所能识别的程序,任何程序都要经过操作系统。上面的JVM在不同的系统是不同的版本。
Java的各个版本
| J2EE | Java 2 Platform Enterprise Edition。 Java2平台企业版,主要针对Web应用程序开发。 |
|---|---|
| J2SE | Java 2 Platform Standard Edition Java2平台标准版,主要针对桌面应用程序 |
| J2ME | Java 2 Plateform Micro Edition Java2平台Micro版主要针对小型电子消费类如手机产品 |
每个版本的包含的内容说明
| 概念 | 描述 | 关系 |
|---|---|---|
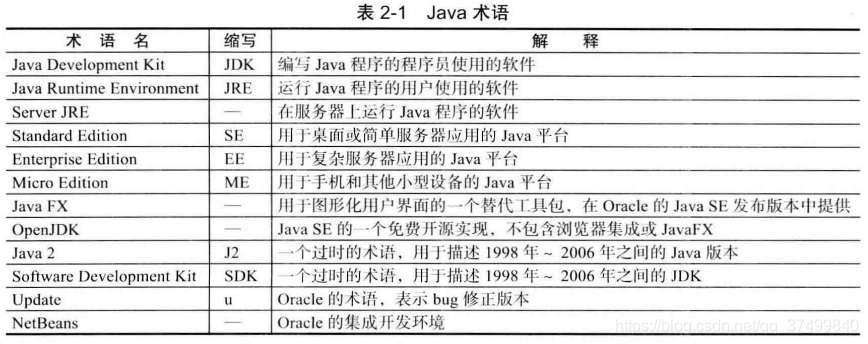
| JVM | Java虚拟机 Java Virtual Machine。Sun公司开发的。 | JDK=JRE+开发工具=(JVM虚拟机+运行类库)+开发工具。 |
| JRE | Java Runtime Environment简称。 包括Java虚拟机和Java程序所需的核心类库。 是用户运行Java程序必须有的环境。 |
|
| JDK | Java Development Kit(Java开发工具包)简称。 包括java的开发工具和JRE。 是开发者开发Java程序所必须的环境。 |
1.2 搭建Java开发环境
[
](https://www.oracle.com/java/technologies/javase/jdk-relnotes-index.html)
编程选择的是安装哪个?
答:实际会选择JavaSE Development Kit的SDK版本,及JavaSE的JDK。
[
](https://www.oracle.com/java/technologies/javase/jdk-relnotes-index.html)
可以粗略的等价认同:JAVA就是指JDK开发工具,所以我们可以理解为JAVA等价于JDK。又因为JAVA有3个版本,所以J2SE(JavaSE)是JDK的3个版本中的其中一个,即标准版本,即我们平时用的最多的版本。
注:根据Oracle官网所示,JavaEE其自己有其自己的JDK,也有其自己的版本历史(一般不带JavaSE的JDK即默认为JavaSE)。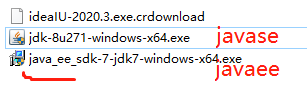

JDK(默认都为JavaEE版本)的下载路径:https://www.oracle.com/java/technologies/javase-downloads.html
完整的历史版本地址:http://jdk.java.net/archive/另:JavaSE的JDK(仅供参考):https://www.oracle.com/java/technologies/java-ee-sdk-7-jdk-7u21-downloads.html
[
](https://www.oracle.com/java/technologies/javase/jdk-relnotes-index.html)
JavaSE版本下的JDK版本和JAVA版本号的对比
注:JDK版本=Java平台(虽然我们一般会把JDK直接等同于JavaSE,但严格上,其实不是,因为除了JavaSE外,还有JavaEE和JavaME版本的JDK)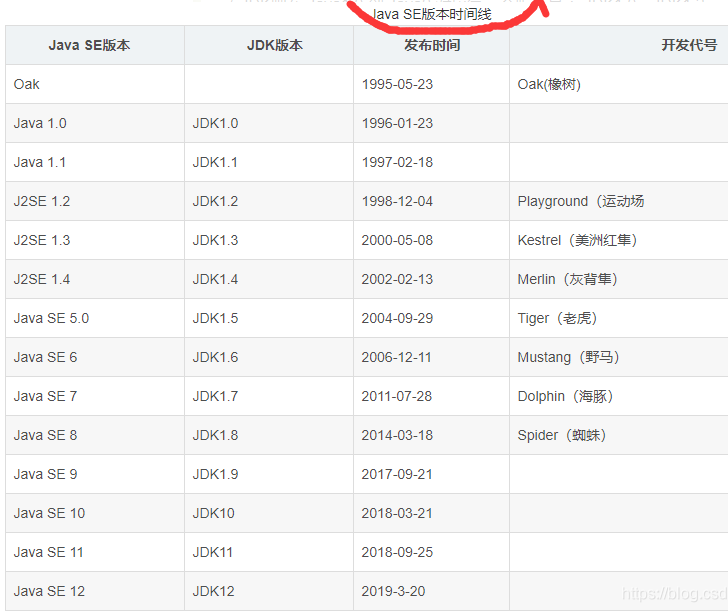
参考链接:https://blog.csdn.net/krismile__qh/article/details/98884337?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-5.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-5.control
着手搭建
先下载JavaSE的JDK,由于JDK中自带了JRE,不需要单独下载。
JDK下载地址:https://www.oracle.com/java/technologies/javase-downloads.html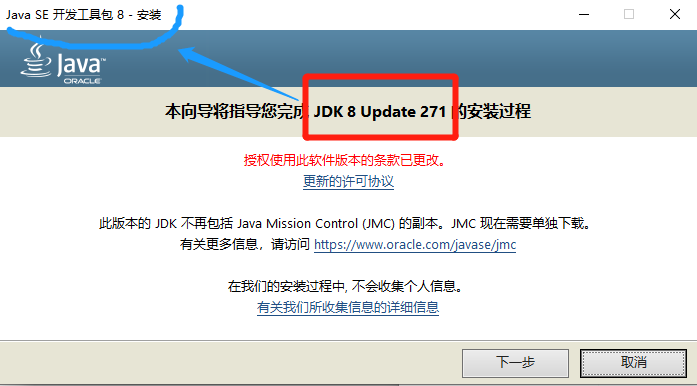
选择安装目录,下一步,装完JDK,会问是否安装JRE,选下一步,
最后还会问是否安装Java FX,
装完后就全部完成了JDK的安装,下面配置JDK,
打开,计算机->属性->高级系统设置->环境变量
- 新建系统变量JAVA_HOME(JDK安装路径):
C:\Program Files\Java\jdk1.7.0_03- 编辑PATH:在前面加上:
%JAVA_HOME%\bin;- 新建系统变量CLASSPATH:
.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar。注意第三句,前面的点,- 配置完后,打开cmd,输入:
java –version(注意java后面还有一个空格)
会出现如下信息:
说明JDK配置成功
如何下载安装多个版本的JDK
完整的历史版本地址:http://jdk.java.net/archive/,下载zip文件,解压到指定目录,在IDEA ->Project Structure中添加即可。如果想要默认的设置,如java -v则必须配置path。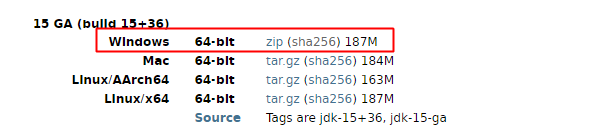
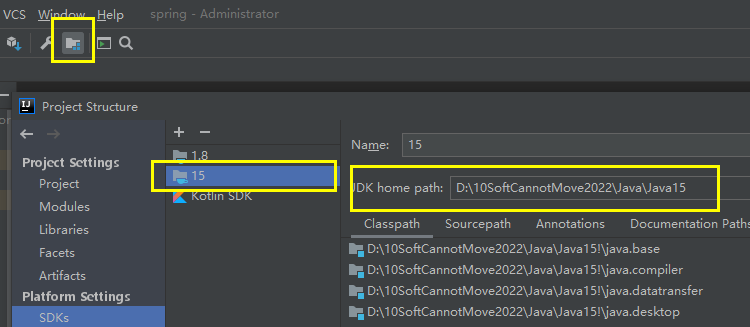 t
t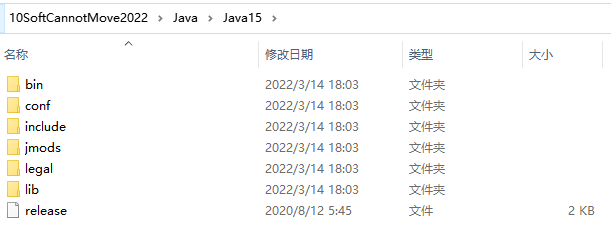
Path的概念说明
参考资料:https://blog.csdn.net/wf131410000/article/details/72618752
系统执行用户命令时(如在cmd中输入就java –version),若用户未给出绝对路径,则首先在当前目录下寻找相应的可执行文件、批处理文件(另外一种可以执行的文件)等。若找不到,再依次在PATH保存的这些路径中寻找相应的可执行的程序文件。系统就以第一次找到的为准;若搜寻完PATH保存的所有路径都未找到,则会报错。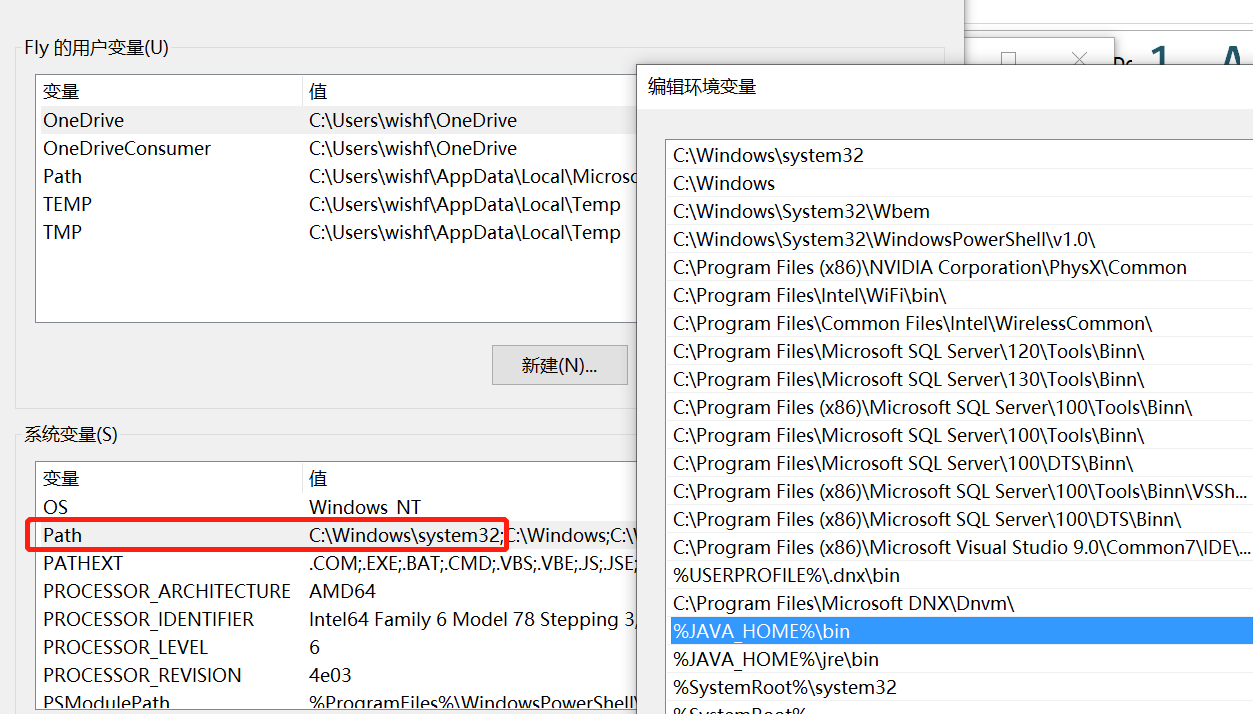

设置了Path,但是读取版本错乱的情况分析:
https://www.cnblogs.com/zeug/p/11446197.html
ClassPath的概念说明
classpath是指定在Java程序中所使用的类(.class)文件所在的位置,就如在引入一个类时:import javax.swing.JTable这句话是告诉编译器要引入javax.swing这个包下的JTable类,而classpath就是告诉编译器该到哪里去找到这个类(前提是你在classpath中设置了这个类的路径);如果你想要编译在当前目录下找,就加上“.”,如:.;C:\Program Files\Java\jdk\,这样编译器就会到当前目录和C:\Program Files\Java\jdk\去找javax.swing.JTable这个类;顺便提下:大多数人都是用Eclipse写程序,不设classpath也没关系,因为Eclipse有相关的配置;
2 基础知识
2.1 规范(小包大常帕类方参变驼)
| 规范说明 | 描述 |
|---|---|
| [强制]类名(帕斯卡) | 类名使用 UpperCamelCas风格,但以下情形例外:DO/BO/DTO/VO/AO/PO/UID 正例: MarcoPolo/UserDO/XmlService/TcpUdpDeal/TaPromotion 反例: macroPolo/UserDo/XMLService/TCPUDPDeal/TAPromotion |
| [强制]方法名、成员变量、局部变量、参数名(驼峰) | 方法名、参数名、成员变量、局部变量都统一使用 lowerCamelCase 风格,必须遵从驼峰形式。 正例:localValue/getHttpMessage()/inputUserId |
| [强制]常量命名(全部大写) | 常量命名全部大写,单词间用下划线隔开,力求语义表达完整清楚,不要嫌名字长。 正例: MAX_STOCK_COUNT 反例: MAX_COUNT |
| [强制]包名统一(全部小写) | 正例:应用工具类包名为 com.alibaba.ai.util、类名为 MessageUtils(此规则参考 spring 的框架结构) |
2.2 原码反码补码
基本概念
原码:在数值前面(即最高位)增加了一位符号位:正数该位为0,负数该位为1(0有两种表示:+0和-0),其余位表示数值的大小。
反码:当原码是正数时,反码跟原码是一样;当原码是负数时,反码除了符号位不变(仍为1),其他位按位取反。
补码:正数的补码是其本身;负数的补码是在其原码的基础上,符号位不变,其余各位取反,最后+1。(也即在反码的基础上+1)
例子:如用8位二进制表示一个数,
11的原码为00001011,-11的原码就是10001011。
11的反码即其本身(00001011),-11(10001011)的反码即为11110100(-116)
11的补码即其本身(00001011),-11(10001011)的补码即为11110101(-117)
为什么需要使用原码反码和补码?
计算机辨别“符号位”显然会让计算机的基础电路设计变得十分复杂,于是人们想出了将符号位也参与运算的方法。我们知道,根据运算法则减去一个正数等于加上一个负数,即: 1-1 = 1 + (-1) = 0,所以机器可以只有加法而没有减法,这样计算机运算的设计就简单了。
总结
对于正数来讲:原码、反码、补码是相同的,即三码合一。
计算机底层都是使用二进制来表示数值,都是使用的数值的补码保存的数据。JVM在运算的也是实用的补码的方式参与运算。
2.3 关键字
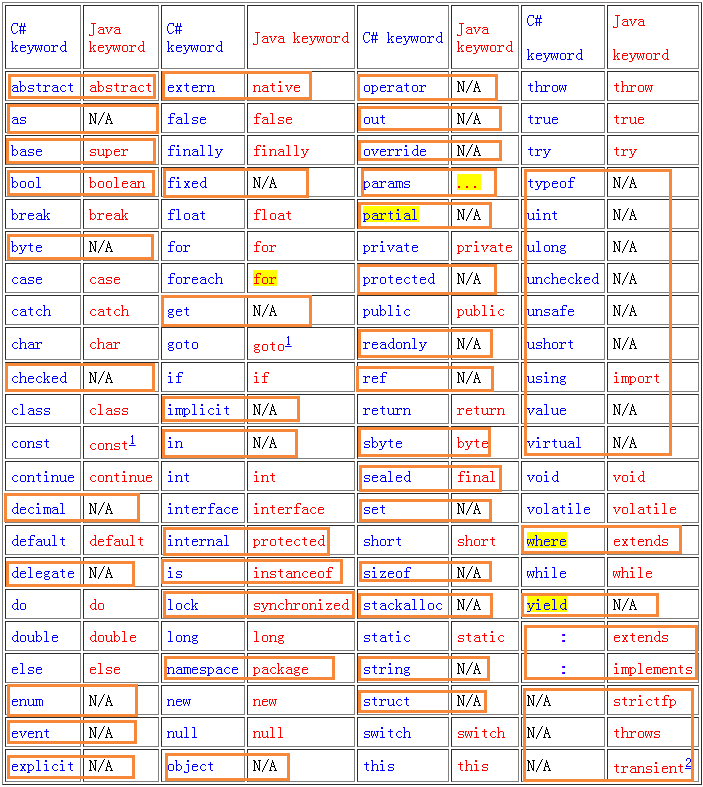
其中数据类型这块的对比情况:左边为Java写法,右边为C#写法
byte<->byteshort<->shortint<->intlong<->longfloat<->floatdouble<->doubleboolen<->boolchar<->charstring<->N/A
2.4 分支流程控制
2.5.1 if else(表达式)
- 条件表达式必须是布尔表达式(关系表达式或逻辑表达式)、布尔变量。
- 一旦其中一个if 语句检测为 true,其他的 else if 以及 else 语句都将跳过执行。
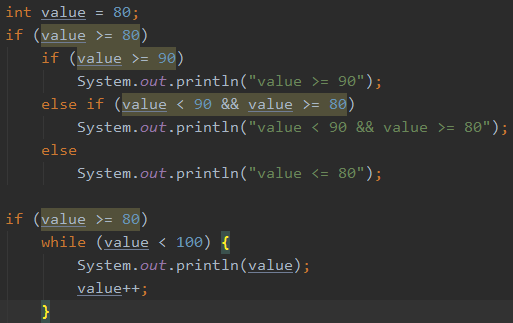
当多个条件是"包含"关系时,条件间的关系是:"小上大下 / 子上父下"。即条件更严格的鱼网在上面。因为:如果条件宽泛的在上面,则一旦条件匹配到,则会跳过整个分支结构的剩余判断语句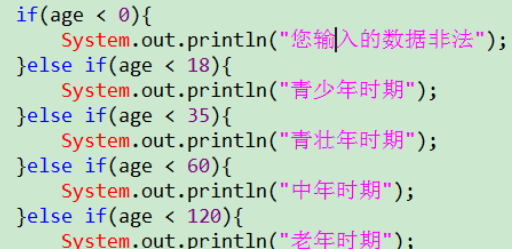
- 当语句块只有一条执行语句或一个流程控制(分支、循环结构)时, {}可以省略,但一般建议保留
2.5.2 switch case(表达式值sc必选-bd可选)
格式: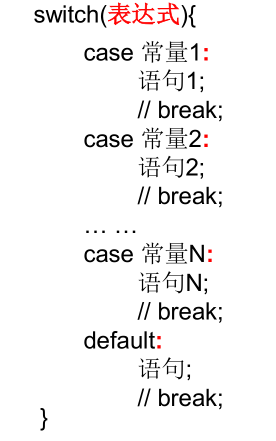
标准的一个switch case语句
int number = 1;switch (number) {case 0:System.out.println(0);break;//可选case 1:System.out.println(1);break; //可选default: //可选System.out.println(2);break; //可选}
几点注意项:
- 【switch必填】switch(表达式值):表达式的值必须是下述几种类型之一: byte、short、char、int、枚举(jdk 5.0开始支持)、String (jdk 7.0开始支持)。不可为boolean、float、double类型。
- 【case必填】case(常量):子句中的值必须是常量,其类型必须与switch的表达式结果类型一致,不能是变量名或不确定的表达式值。同一个switch语句,所有case子句中的常量值互不相同。

- 【break可选,但大部分场景建议加上】
switch一旦匹配上,则就会进入其case字句,直到遇到break语句。当遇到 break 语句时,switch 语句终止,程序跳转到 switch 后面的语句执行。
case 语句不必须要包含 break 语句,但如果没有 break 语句出现,程序会继续执行下一条 case 语句(此时就不需要再判断case了而是直接执行下一个case里面的语句),直到出现 break 语句。
相对于if/else分支的排它性,switch/case必须要靠break去跳出达到互斥排它的目的。
案例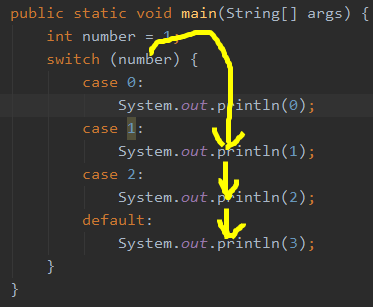
如上结构的输出结果为: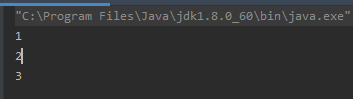
原因解释:没有break,当switch/case找到了一个入口(case 1)即执行,由于case 1语句末尾没有break,则在执行完成后其继续执行case 1下面的语句,且不再进行判断。
- 【default可选】default子句是可任选的。同时,位置也是灵活的,但是强制规定写在结构的末尾。当没有匹配的case匹配到时,执行default。
2.5.3 if else和switch case区别
凡是可以使用switch-case的结构,都可以转换为if-else。反之,不成立。
2. 我们写分支结构时,当发现既可以使用switch-case,(同时,switch中表达式的取值情况不太多),又可以使用if-else时,我们优先选择使用switch-case(枚举罗列项不多的时候)。原因:switch-case执行效率稍高。2.6 循环结构
2.6.1 for循环
基本概念

辅助的一个输出案例
int num = 1;for(System.out.print('a');num <= 2;System.out.print('c'),num++){System.out.print('b');}输出结果:abcbc
2.6.2 while循环

2.6.3 do-while循环

2.6.4 return、break和continue关键字
return(用在方法里)
- return语句并非专门用于结束循环的,它的功能是结束一个方法。
- 当一个方法执行到一个return语句时,这个方法将被结束。与break和continue不同的是,return直接结束整个方法,不管这个return处于多少层循环之内。
break(只能用在分switch分支+循环语句)
- 只能用在分switch分支+循环语句
break语句用于终止退出某个语句块(跳出某个switch case分支或当前for循环结构)的执行,即如果有多个循环嵌套,break默认是退出当前循环。
for (int i = 0; i < 3; i++) {for (int j = 0; j < 3; j++) {if (j == 1)break;//只break里面的这层循环,break后外面的循环还是会继续。System.out.println("i=" + i + ",j=" + j + " =>" + i * j);}}============最终值=============i=0,j=0 =>0i=1,j=0 =>0i=2,j=0 =>0
break语句出现在多层嵌套的语句块中时,可以通过标签指明要终止的是哪一层语句块
- break、continue之后不能有其他的语句,因为程序永远不会执行其后的语句。
- 标号语句必须紧接在循环的头部。标号语句不能用在非循环语句的前面。
continue(只能用在循环里)
- continue只能使用在循环结构中
- continue语句用于跳过其所在循环语句块的一次执行,继续下一次循环
- continue语句出现在多层嵌套的循环语句体中时,可以通过标签指明要跳过的是哪一层循环,继续该层循环的后面循环
- break、continue之后不能有其他的语句,因为程序永远不会执行其后的语句。
案例:使用continue+lable的方式得到1~100000之间的质数
int count = 0;//记录质数的个数label:for (int i = 2; i <= 100000; i++) {//遍历100000以内的自然数for (int j = 2; j <= Math.sqrt(i); j++) {//j:被i去除if (i % j == 0) { //i被j除尽continue label;}}//能执行到此步骤的,都是质数count++;}System.out.println("质数的个数为:" + count);
2.7 字符集
编码统一使用utf-8,包括但不限于java、javaee、javase等。
3 基础知识:运算符
3.1 算术运算符(+-*/)
重要结论
- 加减乘除(+-*/)会改变运算参与项目的数据类型(即为类型自动提升)
- 但是++、—自增自减类型则不会改变参与者的类型(包括赋值+=、-=、%=、*=都不会改变)
求商:被除数/除法=商
取模取余:被取模数%取模数=模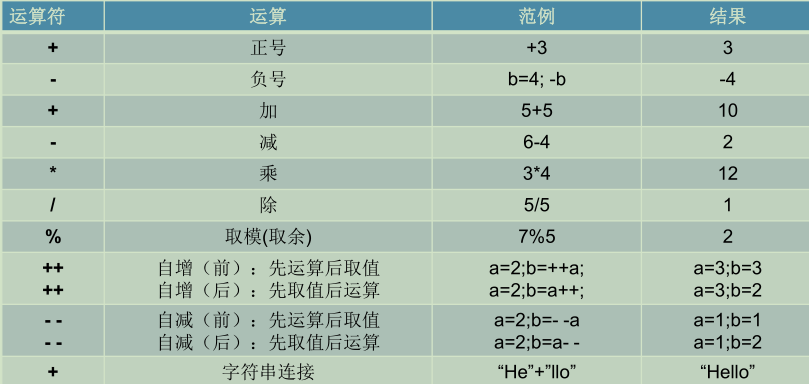
注意点:
- 求商和取模
规律:除法得商的商数:如果被除数和除数符号一致则为正,否则为负
规律:取模的模数跟被模数正负一致
取模运算的结果不一定总是整数。
- 自增
自增操作不会改变变量a本身的类型,其效率比a=a+1效率更高(a如为short类型,则a=a+1会自动变为int类型,因为1默认为int类型)
案例一:++a和a++的区别int a=3;int b=a++;执行完后的值:a=4,b=3,即b=a++语句是先b=a,然后a再自增1int a=3;int b=++a;执行完后的值:a=4,b=4,即b=a++语句是先b=a,然后a再自增1案例二byte b = 127;int b=127;System.out.println(++b); 结果为:-128,更改了首位符号位,二进制位数+1System.out.println(++b); 结果为: 128,二进制位数+1,更改值在范围内
- 对于除号”/”,它的整数除和小数除是有区别的:整数之间做除法时,只保留整数部分而舍弃小数部分。
int x=3510;x=x/1000*1000;x的结果是3000
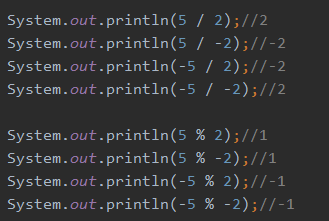
3.2 赋值运算符(=)
重点结论:运算+符号会改变类型(类型自动提升),赋值运算+=、-=、%=、*=则不会改变类型
由于不改变数据类型,故推荐使用+=的方式byte b1=1;byte b2=b1+2;编译失败,因为1为int类型。但是如果用如下byte b2+=2;的方式则可以编译成功,原理和++自增类似,其不会改变变量本身的数据类型。

3.3 比较运算符(==)
比较运算符“==” 不能误写成“=”
比较运算符的结果都是boolean型,也就是要么是true,要么是false
if(true=false)
sout(“xx”);//将会输出xx,因为if(true=false)先赋值再判断,其值为true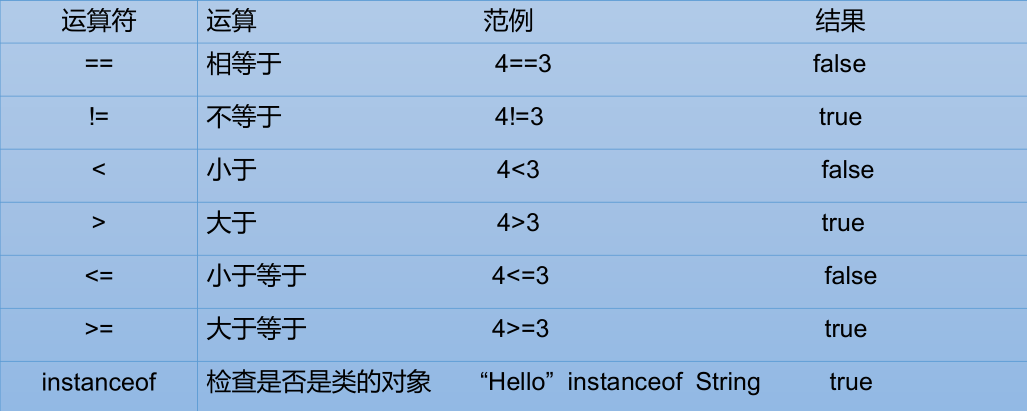
==跟参数值传递一样,其进行比较的是栈区的值。此时,对于值类型,其比较的是具体的值,对于引用类型来讲,其比较的是两个引用类型变量的地址值是否一致。3.4 逻辑运算符(&&||!)
基本使用
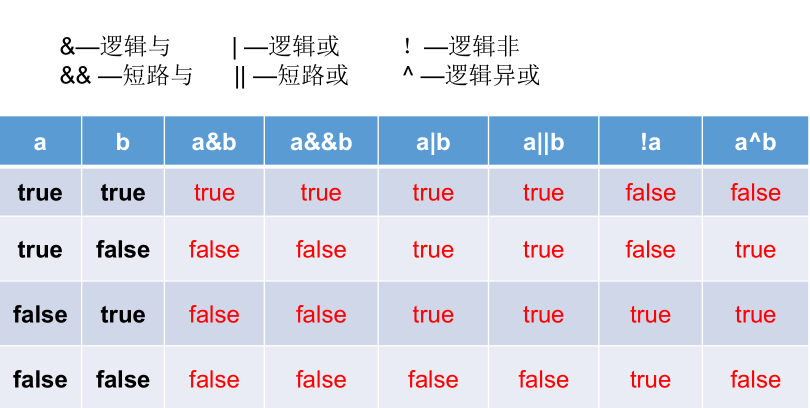
要点总结
- 逻辑运算一般是建议使用&&、||,不建议使用&和|
- 除了在逻辑运算中使用,&、|和^也在位运算中起到了作用。如何区别:两边为boolean则为逻辑运算符,两边为数字的则为位运算符
&和&&的使用(|和||一致)
首先,&和&&的运算结果是一样的。
区别:&:左边无论真假,右边都进行运算;&&:如果左边为真,右边参与运算,如果左边为假,那么右边不参与运算,即短路计算。同理|和||。
案例:
ArrayList arrs = new ArrayList();arrs = null;//方式一:此处会报错,&不会短路,左边为false了,仍然还会判断右边,此时会nullpointerexceptionif (false & arrs.size() > 0){System.out.println("xx");}//方式二:此处不会报错,&&不会短路,左边为false了,则会直接跳出判断语句if (false && arrs.size() > 0){System.out.println("xx");}
异或
当左右均为true或false即两者相同时,结果为false,否则为true。异或,追求的即是异
3.5 位运算符(<<)
概念和特征

要点总结
1) 位运算符是直接对整数的二进制进行的运算。如果是byte、short则默认使用int类型空间去移动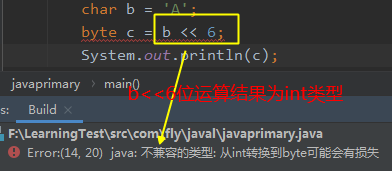
2) 其中&、|、^ 既是位运算符,也是逻辑运算符,如何区别:如果两边类型为boolean,则为逻辑运算符,如果两边是数值型的,则为位运算符。
3) 一般位运算符适用于整数型数据。
<<左移运算
将一个运算对象的各二进制位全部左移若干位
如果int类型位移位<=31
此时左边的二进制位丢弃,右边的补0,左移时舍弃的高位不包括1且没有更改符号位,则每左移一位,相当于该数*2。

左移位数>=32位
在 java 中,int 类型的数据长度为 32 位,如果将 int 类型左移或者右移大于或等于 32 位时,并不会像预计的那样将数据全部填充为1或0。java 的处理方式是:当刚好为数据长度的整数倍时,即32、64······,数据保持原来不变;其他情况下移动除以 32 余数的长度,移动位即参考左移动<=31的情况。同理 long 类型数据以 64 为变化基准。可以理解为是循环移动。
如下两个值跟原值一致System.out.println(-7 << 0);System.out.println(-7 << 32);如下两个移动值一致System.out.println(-7 << 3);System.out.println(-7 << 35);
右移>>运算
将一个数的各二进制位全部右移若干位
如果int类型位移数<=31
如果原值则左边全部补0,原值为负数则全部补1,右边丢弃。
右移位数>=32位
在 java 中,int 类型的数据长度为 32 位,如果将 int 类型左移或者右移大于或等于 32 位时,并不会像预计的那样将数据全部填充为1或0。java 的处理方式是:当刚好为数据长度的整数倍时,即32、64······,数据保持原来不变;其他情况下移动除以 32 余数(位数取模%32)的长度,移动位即参考右移动>=31的情况。同理 long 类型数据以 64 为变化基准。可以理解为是循环移动。
如下两个值跟原值一致System.out.println(-7 >> 0);System.out.println(-7 >> 32);如下两个移动值一致System.out.println(-7 >> 3);System.out.println(-7 >> 35);
无符号位右移动>>>
各个位向右移动指定的位数。
右移位数<=31
右移后左边空出的位置全部用0来填充。移出的右边将被舍弃。
右移位数>=32
当刚好为数据长度的整数倍时,即32、64······,数据保持原来不变;其他情况下移动除以 32 余数(位数取模%32)的长度,移动位即参考右移动>=31的情况。同理 long 类型数据以 64 为变化基准。可以理解为是循环移动。
如下两个值跟原值一致System.out.println(-7 >>> 0);System.out.println(-7 >>> 32);如下两个移动值一致System.out.println(-7 >>> 2);System.out.println(-7 >>> 34);
经典例子
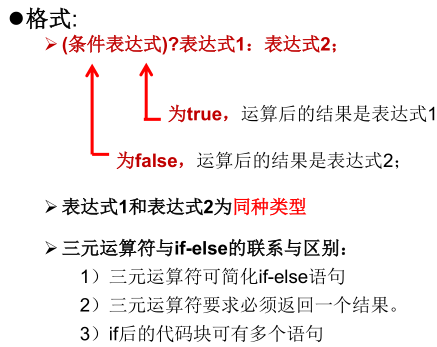
3.6 三元运算符
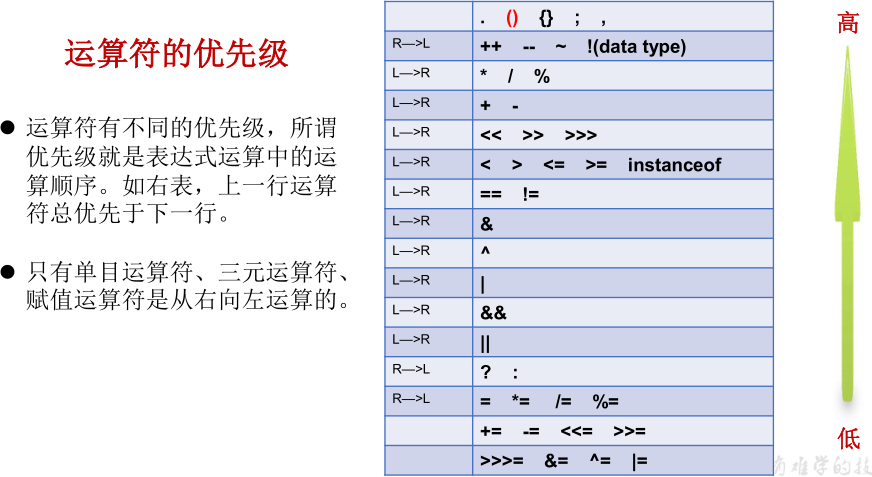
3.7 总结:运算符的优先级
4 八大基本数据类型及其包装类
4.1 基本数据类型说明
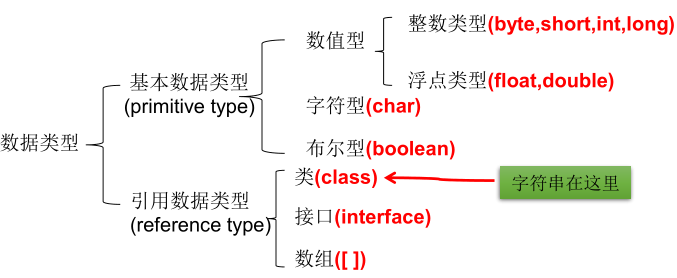
Java语言提供了八种基本类型。六种数值类型(四个整数型,两个浮点型),一种字符类型,还有一种布尔型。这些基本类型及其对应的包装类型
| 基础类型 | 范围 | 包装类型 |
|---|---|---|
| byte 8位 | -128~127 | Byte |
| short 16 位 | -215~215-1 | Short |
| int 32位 | -231~231-1 约21亿 | Integer |
| long 64位 | -263~263-1 | Long |
| float 32 位 I |
EEE754 | Float |
| double 64 位 | IEEE754 | Double |
| boolean 1 位 | Boolean | |
| char16位 | Unicode 0 ~Unicode 216-1 | Character |
3.2 基础类型(8个)
3.2.1 数值型之整数类型(4byte/short/int/long)
整数类型包括byte、short、int、long
Java各整数类型有固定的表数范围和字段长度,不受具体OS的影响,以保证java程序的可移植性。
java的整型常量默认为 int 型,声明long型常量须后加‘l’或‘L’。 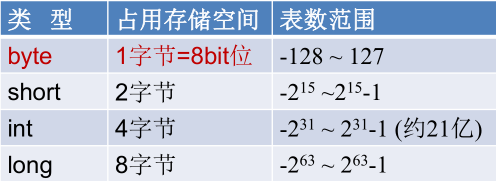
3.2.2 数值型之浮点类型(float/double)
与整数类型类似,Java 浮点类型也有固定的表数范围和字段长度,不受具体操作系统的影响。
浮点型常量有两种表示形式:
十进制数形式:如:5.12 (必须有小数点)
科学计数法形式:如:5.12e2 512E2 100E-2
float:单精度,尾数可以精确到7位有效数字。很多情况下,精度很难满足需求。
double:双精度,精度是float的两倍。通常采用此类型。
float表示的范围比long还大
3.2.3 字符型(char)
char型数据用来表示通常意义上“字符”(2字节)。Java中的所有字符都使用Unicode编码,故一个字符可以存储一个字母,一个汉字,或其他书面语的一个字符。
char类型是可以进行运算的,因为它都对应有Unicode码,如果是运算时候会转换为数值型。直接sout(‘x’)则输出的就是x,不是其对应的数值型。
字符型变量的三种表现形式:
- 字符常量是用单引号(‘’)括起来的单个字符
例如:char c1 = ‘a’; char c2= ‘中’; char c3 = ‘9’;
- 转义字符:Java中还允许使用转义字符’\’来将其后的字符转变为特殊字符型常量
例如:char c3 = ‘\n’; // ‘\n’表示换行符;
- 直接使用 Unicode 值来表示字符型常量:’\uXXXX’。其中,XXXX代表一个十六进制整数
如:\u000a 表示 \n。
记忆:先有普通的字符->转义字符\n->针对转义字符的转义符\n
3.2.4 布尔型号(boolean)
boolean类型数据只允许取值true和false,无null。
不可以使用0或非 0 的整数替代false和true,这点和C语言不同。
Java虚拟机中没有任何供boolean值专用的字节码指令,Java语言表达所操作的boolean值,在编译之后都使用java虚拟机中的int数据类型来代替:true用1表示,false用0表示。《java虚拟机规范 8版》
3.3 基本类型间运算
前提:只讨论7种基本数据类型变量间的运算,不包含boolean类型。其余其中类型可以相互计算。但是可能会进行类型转换(转换规则如下所示)
3.3.1 自动类型提升(范围小的自动->范围大的)
遵循一个大原则:自动类型提升。
自动类型提升转化的几点原则:
- 有多种类型的数据混合运算时,系统首先自动将所有数据转换成运算中范围最大的那个数据类型,然后再进行计算。相应的,运算结果则必须以范围最大或更大数据类型去接收。
数据类型按容量大小排序为
float f1 = (float) 11 / 2;--值为5.5,先将int类型的11转换为float类型,由于float表示的范围空间大于int,则2也会按照float空间去开辟,最后结果即为float类型。float f2 = 11 / 2;--值为5,右边均为int类型,则会按照int类型空间去开辟计算,计算计算再转换为float类型。
- byte,short,char三者在运算时均将首先转换为int类型。相应的运算结果则必须以int或更大的范围类型去接收。一个简易的原则:Java在运算时,操作数均在int范围内(byte/short/char),那么在运算时,会一律将其提升为int类型,在int的空间内运算,接收值也必须为int或以上。
- boolean类型不能与其它数据类型运算。
- 当把任何基本数据类型的值和字符串(String)进行连接运算时(+),基本数据类型的值将自动转化为字符串(String)类型。
3.3.2 声明类型转换(范围大的强制->范围小的)
强制类型转换:自动类型提升运算的逆运算。由范围大的类型强制转换为范围小的类型。
可能会有精度损失的风险。
int value=100;byte i=(byte)value;
char c = ‘a’;byte b=(byte)c;
注意:声明类型转换不能用于字符串<->数值型,即不能
String str=”123”;
int value=(int)str;
3.3.3 案例说明
案例一:byte=byte+byte或byte=byte-byte
结果:出错。原因:在遇到char/byte/short类型的运算时,运算符会类型将上面的类型提升为int类型,此时相当于int+int(int-int),那么左边按照int去接收,则会出现错误。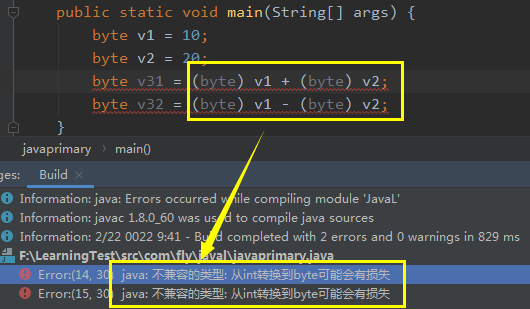
解决方案:使用int=byte+byte或int=byte-byte
案例二:float f=3.1415;
出现错误:从double转换为float可能会有损失,因为浮点型默认即为双精度,此时用单精度去接收则有丢失精度的风险。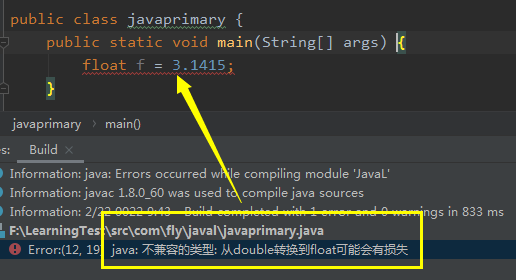
解决方案:采用double去接收,或者float f=3.1415f;
案例三:char+byte
char可以直接转换为整数类型进而和数值型相加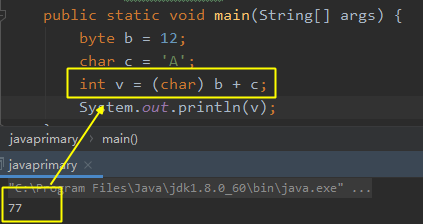
3.4 基础类型与包装类型的关联
3.4.1 为什么要提供基本类型
我们都知道在Java语言中,new一个对象存储在堆里,我们通过栈中的引用来使用这些对象;但是对于经常用到的一系列类型如int,如果我们用new将其存储在堆里就不是很有效——特别是简单的小的变量。所以就出现了基本类型,同C++一样,Java采用了相似的做法,对于这些类型不是用new关键字来创建,而是直接将变量的值存储在栈中,因此更加高效。
3.4.2 有了基本类型为什么还要包装类型
有了基本类型为什么还要有包装类型呢?
我们知道Java是一个面相对象的编程语言,基本类型并不具有对象的性质,为了让基本类型也具有对象的特征,就出现了包装类型(如我们在使用集合类型Collection时就一定要使用包装类型而非基本类型),它相当于将基本类型“包装起来”,使得它具有了对象的性质,并且为其添加了属性和方法,丰富了基本类型的操作。
另外,当需要往ArrayList,HashMap中放东西时,像int,double这种基本类型是放不进去的,因为容器都是装object的,这是就需要这些基本类型的包装器类。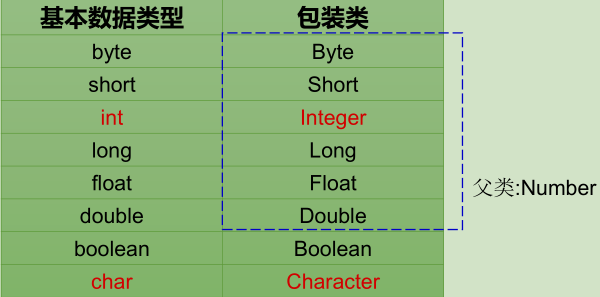
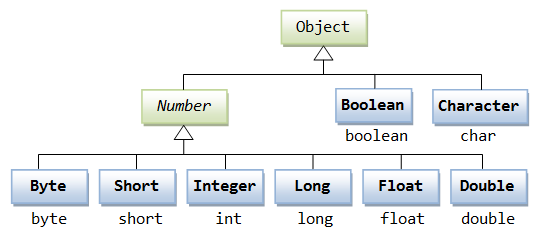
3.4.3 基本类型与包装类型的区别
二者的区别:
1) 声明方式不同:
基本类型不使用new关键字,而包装类型需要使用new关键字来在堆中分配存储空间;
2) 存储方式及位置不同:
基本类型是直接将变量值存储在栈中,而包装类型是将对象放在堆中,然后通过引用来使用;
3) 初始值不同:
基本类型的初始值如int为0,boolean为false,而包装类型的初始值为null;
4) 使用方式不同:
基本类型直接赋值直接使用就好,而包装类型在集合如Collection、Map时会使用到。
3.4.4 基础类型-包装类-String之间的转换
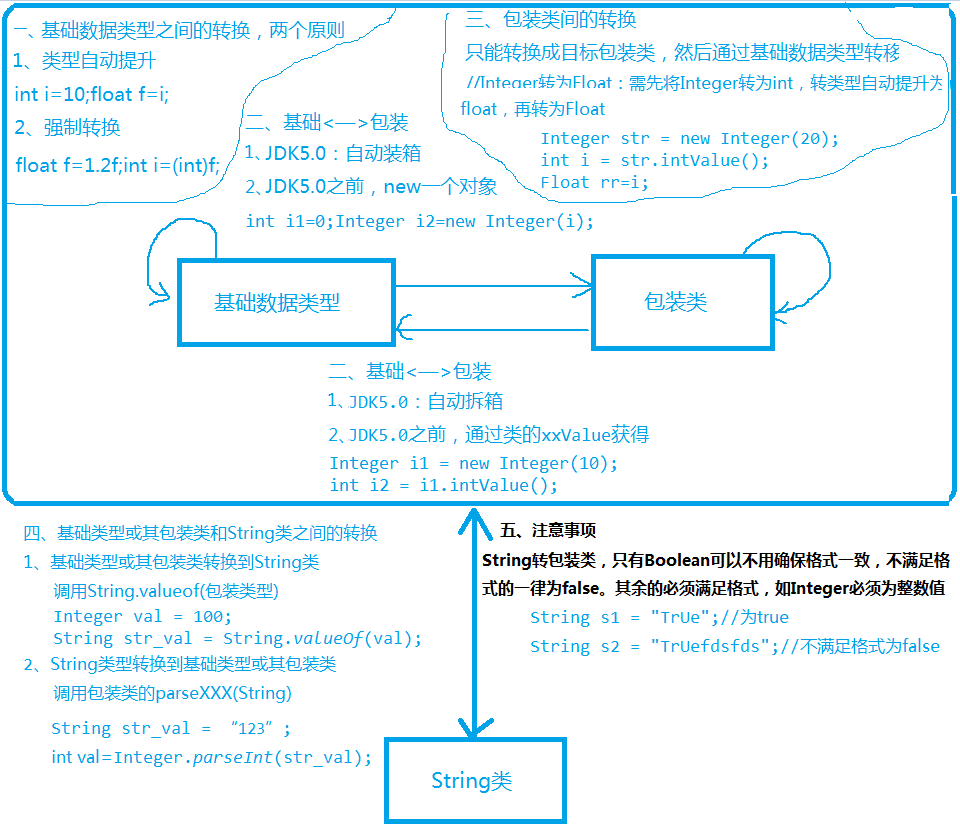
一个案例:Object o1 = true ? new Integer(1) : new Double(2.0);System.out.println(o1);//输出值为1.0原理分析:首先三元远算符是会自动提升的,所以值为Double。其次println(obj)是调用了println(obj.toString()),虽然Object.toString()是输出了类型+地址,但是此处是是double的包装类型Double,其对toString()进行了重写,此时使用到了多态的思路,实际调用的是Double.toString(),所以输出的值为1.0
3.4.5 Integer包装类的缓存策略
Integer内部定义了IntegerCache结构,IntegerCache中定义了Integer[],保存了从-128~127范围的整数。如果我们使用自动装箱的方式,给Integer赋值的范围在-128~127范围内时,可以直接使用数组中的元素,不用再去new了,以提高效率(注意:必须是自动装箱的方式,如果是直接new那还是不是创建对象)。
案例:int value001 = 1;int value128 = 128;Integer i = new Integer(value001);Integer j = new Integer(value001);//1.0 falseSystem.out.println(i == j); Integer m = value001;Integer n = value001;//2.0 true 自动装箱:[-128,127]之间的值使用缓存System.out.println(m == n); Integer x = value128;Integer y = value128;//3.0 falseSystem.out.println(x == y);
3.5 附加:引用类型间的转换
- 声明父类,可以直接实例化子类对象(参数声明父类,实际传入子类对象):Person p = new Student();
- 申明子类,实际父类,需使用贴标签方式告诉编译器强转:Student s = (Student)new Person();//此方法编译期不会报错,但是运行期间会报错

若有收获,就点个赞吧
0 人点赞
