- 1 String框架
- 2 Object
- 6 常见类
- 日期框架类
- 7 集合框架
- 概览已记
- 7.2 Iterator(辅助迭代器)
- 7.3 Collection(基类接口簇一)
- 7.4 Collection_List接口簇
- 7.5 Collection_Set接口簇
- 7.6 Map(基类接口簇二)
- 7.7 Map_HashMap(数组+单向链表+~红黑树)
- 7.8 Map_TreeMap(红黑树排序)
- 7.9 Map_Hashtable(几乎过时)
- 7.10 Collections(集合静态工具类)
- 8 IO框架
- 9 Trowable异常框架
1 String框架
StringTable
參考JVM-StringTable
10 StringTable
StringBuffer和StringBuilder类
三大对比
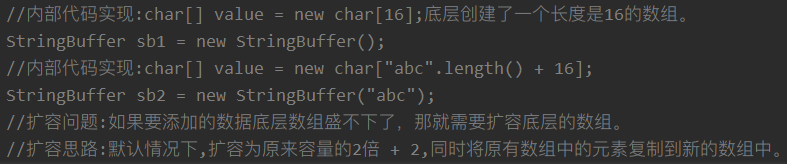
- String(JDK1.0):不可变字符序列,底层使用
final char[]/final byte[]存储。 - StringBuffer(JDK1.0):可变字符序列,底层使用
char[]/byte[]存储。效率低、线程安全,如果是多线程需求必须选择StringBuffer。 - StringBuilder(JDK5.0):可变字符序列,效率高、线程不安全,底层使用
char[]/byte[]存储。

使用重点
- 作为参数传递的话,方法内部String不会改变其值。
StringBuffer和StringBuilder会改变其值。 - 内部实现机制上,除了方法的线程安全差异外,其他情况
StringBuffer和StringBuilder的基本相同。 - 在循环拼接方法的时候,效率对比:
StringBuilder > StringBuffer > String。 - 在开发中,建议初始化StringBuffer和StringBuilder的容量空间。
常用方法
增加:append(xxx)删除:delete(int start,int end)修改:setCharAt(int n ,char ch)/replace(int start, int end, String str)查找:charAt(int n )插入:insert(int offset, xxx)字符串长度:length();遍历:for() + charAt()
一道试题
//试题1StringBuilder sb = new StringBuilder();String str = null;sb.append(str);System.out.println(sb);//结果值为null//试题2String str = null;StringBuilder sb2 = new StringBuilder(str);System.out.println(sb2);//結果Exception in thread "main" java.lang.NullPointerExceptionat java.lang.StringBuilder.<init>(StringBuilder.java:112)at ClassTest.main(ClassTest.java:12)
2 Object
基本概述
- java.lang.Object类是所有Java类的根父类,如果在类的声明中未使用extends关键字指明其父类,则默认父类为java.lang.Object类。
即public class Person {}等价于:public class Person extends Object{}
Object类中的功能(属性、方法)就具有通用性。
equals是一个方法,而非运算符,只能适用于引用数据类型。
- 在Object类中定义的equals()和==的作用是相同的:比较两个对象的地址值是否相同。即两个引用是否指向同一个对象实体。如果想要比较实例内容则必须重写equals方法。
- 但是像String、Date、File、包装类等都重写了Object类中的equals()方法。重写以后,比较的不是两个引用的地址是否相同,而是比较两个对象的”实体内容”是否相同。
```java
//Object.equals源码
public class Object {
public boolean equals(Object obj) {
} }return (this == obj);
//String重写了Object.equals的源码 public final class String{ public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n— != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false; } }
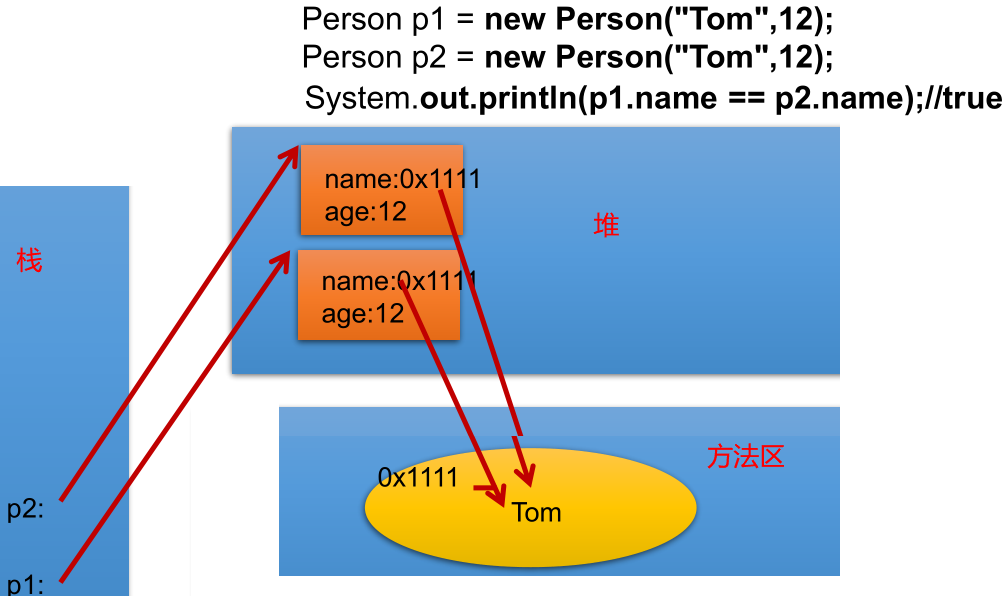
**小总结**- ==是100%比较的栈空间值。对于八大基础数据类型,栈空间存的就是数据的值。对于引用类型,其存储的是引用对象的堆空间地址。注意:boolean类型的值不能参与和其他七大基础数据类型的比较。- equals比较只能用于引用类型的比较(其属于Object类),Object的实现方式也是==,但是像String/Date/File/八大类型的包装类其对equals进行了重写,重写之后其比较的就是具体对象的"实例内容"了。**扩展:==运算符的使用**<br />可以使用在基本数据类型变量和引用数据类型变量中,其都是比较的栈空间上存储的值。- 如果比较的是基本数据类型:比较两个变量保存的数据是否相等:用"=="进行比较时,符号两边的数据类型必须兼容(可自动转换的基本数据类型或拆装箱的除外)。```javaint i = 10;double d = 10.0;System.out.println(i == d);//true
- 如果比较的是引用数据类型变量:比较两个对象的地址值是否相同。即两个引用是否指向同一个对象实体。
- 如果直接比较p1==p2则为false
- 如果比较p1、p2堆区name元素上存的值,则相等(均为指向常量区的0x111)。
toString()
概念
- toString()方法用于返回对象的字符串表示形式。Object.toString()方法默认的返回格式为:对象的class名称 + @ + hashCode 的十六进制字符串。
- 多个类重写了toString()方法,如String、Date、File、包装类等,这使得它们在调用对象的toString()时,返回”实体内容”信息。
```java
//Object.toString()
public class Object {
public String toString() {
} }return getClass().getName() + "@" + Integer.toHexString(hashCode());
//String.toString() public final class String public String toString() { return this; } }
**Object.toString()方法与PrintStream.**_**println**_**打印方法的结合**<br />输出一个对象时,默认调用的就是该对象的toString()方法,如果是基本数据类型,则是调用其对应包装类型的toString()<br /><br />**案例**```javachar[] arr1 = new char[]{'a', 'b', 'c'};int[] arr2 = new int[]{1, 2, 3};double[] arr3 = new double[]{1.1, 2.2, 3.3};String[] arr4 = new String[]{"Hello", "World"};System.out.println(arr1);//abcSystem.out.println(arr2);//[I@1b6d3586System.out.println(arr3);//[D@4554617cSystem.out.println(arr4);//[Ljava.lang.String;@74a14482
原理分析:print/println只有针对char[]提供了额外的重载方法,其余的数组格式都是调用的print(object),而默认的print(Object)内部就是调用的obj.toString(),故输出的是类+地址。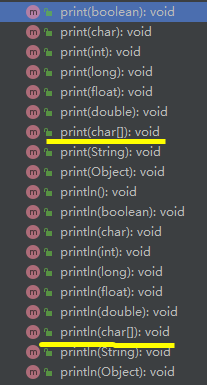
hashCode()
概念
- 将任意大小的输入数据转换成特定大小的输出数据的函数,转换后的数据称为哈希值或哈希编码,也叫散列值。
- 默认Object的hashCode()方法调用的native方法,String等类重写了hashCode。
- 如有必要必须重写hashCode,如HashMap的自定义key对象。 ```java //Object.hashCode()方法 public class Object { public native int hashCode(); }
//Integer.hashCode()方法
public final class Integer extends Number implements Comparable
}
//测试:结果为10
Integer integer=new Integer(10);
System.out.println(integer.hashCode());
//String重写的hashCode() public final class String public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value;
for (int i = 0; i < value.length; i++) {h = 31 * h + val[i];}hash = h;}return h;}
}
**哈希冲突的案例**```java//案例1:字符串哈希冲突public static void main(String[] args) {System.out.println("Aa".hashCode());System.out.println("BB".hashCode());}//案例2:Object哈希冲突public static void main(String[] args) {List<Integer> list = new ArrayList<>();int count = 0;for (int i = 0; i < 200000; i++) {int hashCode = new Object().hashCode();if (list.contains(hashCode)) {System.out.println("哈希冲突了");count++;continue;}list.add(hashCode);}System.out.println("存在哈希冲突的场景" + count);}
6 常见类
6.2 八大基础类型的包装类
6.3 引用类型之数组(数组和Array)
6.3.1 基本概念/特征和分类
数组(Array),是多个相同类型数据按一定顺序排列的集合,并使用一个名字命名,并通过编号的方式对这些数据进行统一管理。
数组的特征
- 数组本身是引用数据类型,而数组中的元素可以是任何数据类型,包括基本数据类型和引用数据类型。
- 创建数组对象会在内存中开辟一整块连续的空间,而数组名中引用的是这块连续空间的首地址。数组是有序的。
- 数组的长度(arrs.length)一旦确定,就不能修改。数组的length要么动态初始化时指定,要么静态初始化时去计算,即不能写成:
int[] arrs=new int[3]{1,2,3}; - 我们可以直接通过下标(或索引)的方式调用指定位置的元素,速度很快。
- 一维数组元素默认初始化值
数组是引用类型,它的元素相当于类的成员变量,因此数组一经分配空间,其中的每个元素也被按照成员变量同样的方式被隐式初始化。
各类型元素默认初始化的值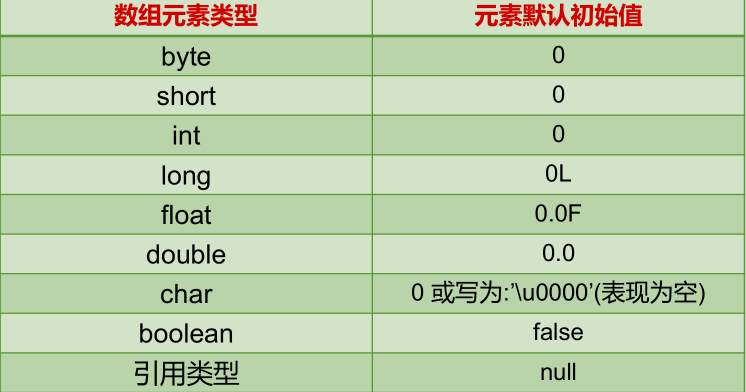
sout可以输出null类型(不会报错):System.out.println(null);
数组的分类
方式一(动态初始化):int[] arrs = new int[3];//只初始化了数组,未手动初始化数组元素
方式二(静态初始化):int[] arrs2 = {1, 2, 3}或int[] arr2=new int[]{1,2,3};
- 使用数组
数组的元素是通过arrs[index]索引角标去访问,数组的长度为arrs.length,数组索引从 0 开始,索引范围为[0, arrs.length-1]。
- 数组的使用(循环)
循环方法一
int[] arrs2 = {1, 2, 3};
for (int i = 0; i < arrs2.length; i++) {
System.out.println(arrs2[i]);
}
循环方法二
int[] arrs2 = {1, 2, 3};
for (int value : arrs2) {
System.out.println(value);
}
6.3.3 多维数组(本质也是一维数组)
基本特征说明
- 对于二维数组的理解,我们可以看成是一维数组arrs每个元素都是一个一维数组。
其实,从数组底层的运行机制来看,其实没有多维数组。
- Java中多维数组不必都是规则矩阵形式,即可以这样int[][] arrs = {{1, 2, 3}, {12, 13}}。
这也从侧面反映了二维数组本质其实就是一维数组。
- 【注意】二维数值元素的默认值
要根据不同的情况去分析
方式一(双定长动态初始化)
比如:int[][] arr = new int[4][3];
外层元素arr[index]的初始化值为地址值(因为数组的元素也是一个确定了长度的数组,所以一维数组的每个必须开辟空间),内层元素arr[index][index]的初始化值与一维数组初始化情况相同.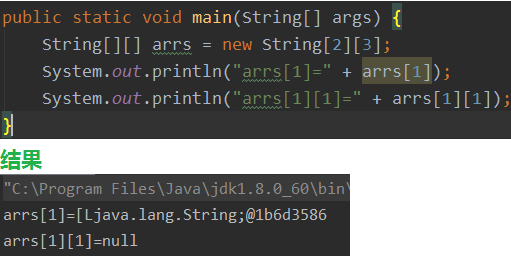
方式二(单定长动态初始化)
比如:int[][] arr = new int[4][]; 外层元素arr[index]的初始化值为null(因为数组的每个元素指向的数组长度没确定,不需要先创建),内层元素的初始化值不能调用,否则报错。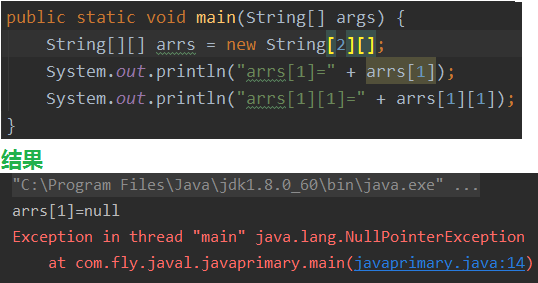
- 二维数组的内存空间(一个数组的元素也是一个数组)
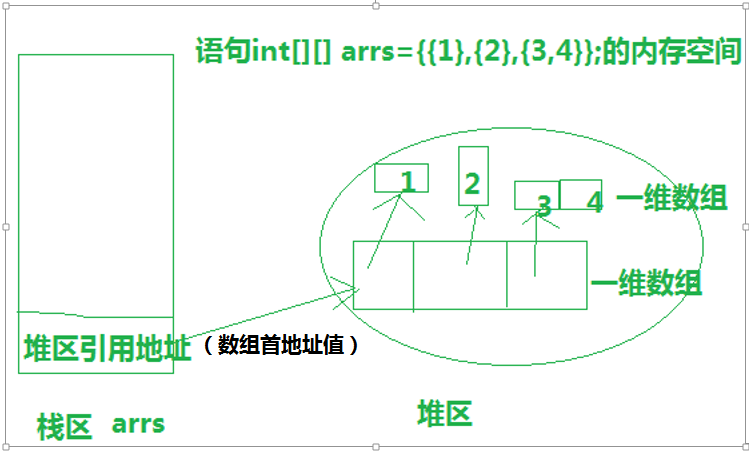
使用
- 声明和初始化
方式一(动态初始化):int[][] arrs = new int[3][2];或int[][] arrs = new int[3][];
方式二(静态初始化):int[][] arrs = {{1, 2}, {12}};或int[][] arrs = new int[][]{{1, 2}, {12}};
- 调用
使用arrs[index][index]索引下标的方式去获取,如arrs[1][1]
6.3.4 Array类
6.3.4.1 基本说明
所属包:java.util
类特征:该类的所有方法均为静态方法
6.3.4.2 equals方法(数组间的比较)
基本说明:
public static boolean equals(long[] a, long[] a2)
如果两个指定的 long 型数组彼此相等,则返回 true。即如果两个数组包含相同数量的元素,并且两个数组中的所有相应元素对都是相等的,则认为这两个数组是相等的。
简单总结:如果两个数组以相同顺序包含相同的元素,则两个数组是相等的。
案例
int[] arrs = {1, 2};
int[] arrs2 = new int[2];arrs2[0] = 1;arrs2[1] = 2;
boolean isOK = Arrays.equals(arrs, arrs2);System.out.println(isOK);
结果
true
6.3.4.3 file方法(给数组的每个元素赋值)
说明:将指定的值分配给指定型数组指定范围中的每个元素
语法:public static void fill(int[] a,int fromIndex,int toIndex, int val)
案例:
int[] arrs = {1, 2, 3};
//含义:将arrs数组索引index为1到index为2的值替换为100
Arrays.fill(arrs, 1, 2, 100);
for (int value : arrs)
System.out.println(value);
}
输出结果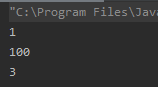
6.3.4.4 sort方法(对数组排序)
通过 sort 方法,按升序进行排序,直接修改原数组,该方法返回值为void
public static void sort(int[] a)
案例
int[] arrs = {1, 2, 34, 454};Arrays.sort(arrs);
for (int value : arrs) {
System.out.println(value);}
输出结果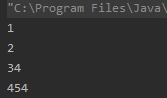
6.3.4.5 binarySearch方法(查找数组元素)
通过 binarySearch 方法能对排序好的数组进行二分查找法操作。数组必须排好序,如果找到则返回该元素在数组的索引下标位置,否则为-1
案例
//1.0 未排序数组
int[] arrs = {1, 2, 34, 454, 12, 4, 3};
int index = Arrays.binarySearch(arrs, 12);
结果为:-1
//2.0 先对数组进行排序
int[] arrs = {1, 2, 34, 454, 12, 4, 3};Arrays.sort(arrs);
int index = Arrays.binarySearch(arrs, 12);System.out.println(index);
结果为:4
6.7 Java比较器Compare
Java实现对象排序的方式有两种:
默认自然排序:java.lang.Comparable
特殊定制排序:java.util.Comparator
6.7.1 java.lang.Comparable:自然排序
- Comparable接口强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序。
实现 Comparable 的类必须实现 compareTo(Object obj)方法,两个对象(传入的obj和this两个对象)即通过compareTo(Object obj)方法的返回值来比较大小
- String/包装类等实现了Comparable接口,重写了compareTo(obj)方法,其内部进行了从小到大排列
- 对于自定义类来说,如需要排序,可让其实现Comparable接口并重写compareTo(obj)方法
重写compareTo(obj)的规则(升序排列,如为降序则取反):
如果当前对象this大于形参对象obj,则返回正整数
如果当前对象this小于形参对象obj,则返回负整数
如果当前对象this等于形参对象obj,则返回零
扩展:方法内部排序也类似于冒泡排序(未经验证)
案例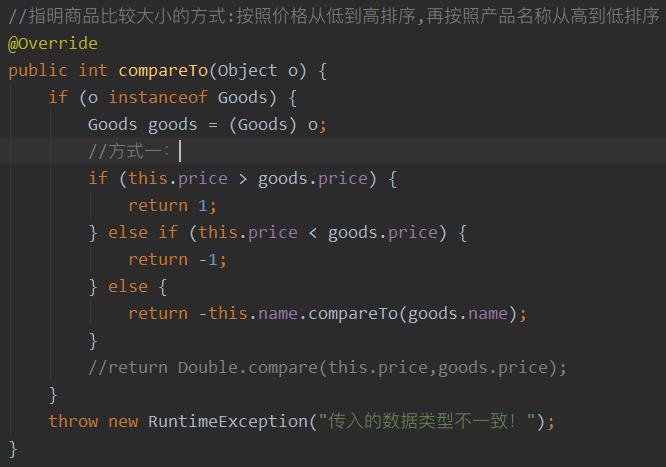
6.7.2 java.util.Comparator:定制排序
- 背景:当元素的类型没有实现java.lang.Comparable接口,或实现了java.lang.Comparable接口
的排序规则不适合当前的操作,那么可以考虑使用 Comparator 的对象来排序
- 重写compare(Object o1,Object o2)方法,比较o1和o2的大小
如o1大于o2,此时返回正整数则为升序,返回负整数则为降序
如o1小于o2,此时返回负整数则为升序,返回正整数则为降序
案例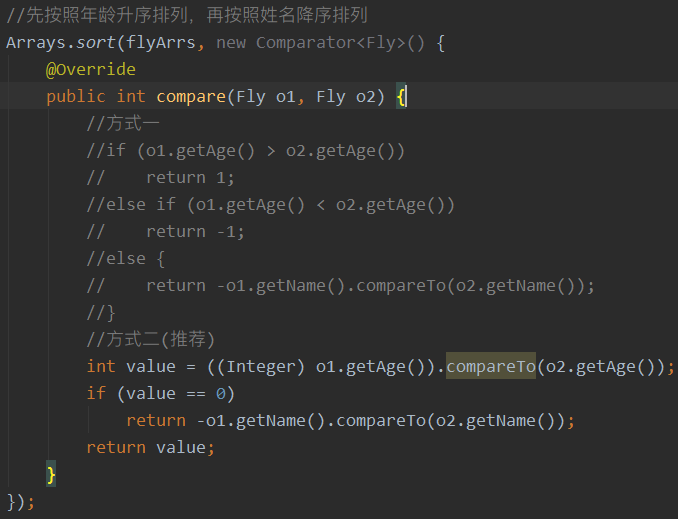
6.8 Java.lang.System系统类
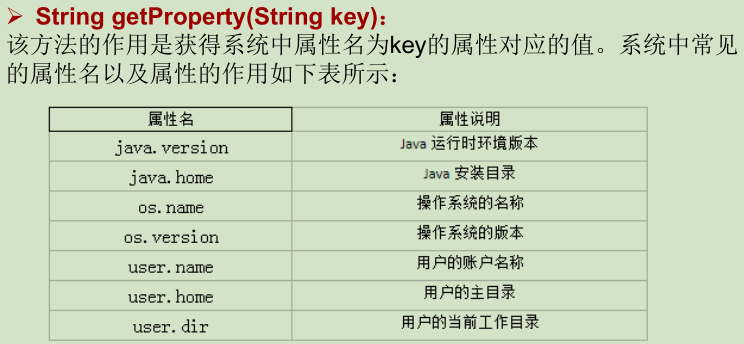
6.9 BigInteger和BigDecimal类


6.10 Scanner(获取用户输入类)
java.util.Scanner是Java5的新特征,我们可以通过Scanner类来获取用户的输入。
scan.next()过程:程序断点等待用户输入->用户输入->将用户输入的值赋值给方法返回值->程序继续执行。
- next()
1、一定要读取到有效字符后才可以结束输入。
2、对输入有效字符之前遇到的空白,next() 方法会自动将其去掉。
3、只有输入有效字符后才将其后面输入的空白作为分隔符或者结束符。
next() 不能得到带有空格的字符串。
- nextLine()
1、以Enter为结束符,也就是说 nextLine()方法返回的是输入回车之前的所有字符。
2、可以获得空白。
案例一:从键盘读入个数不确定的整数,并判断读入的正数和负数的个数,输入为0时结束程序
Scanner scan = new Scanner(System.in);
int positiveNumber = 0;//记录正数的个数int negativeNumber = 0;//记录负数的个数for(;;){//while(true){
int number = scan.nextInt();
//判断number的正负情况
if(number > 0){
positiveNumber++;
}else if(number < 0){
negativeNumber++;
}else{
//一旦执行break,跳出循环
break;
}
}
System.out.println(“输入的正数个数为:” + positiveNumber);System.out.println(“输入的负数个数为:” + negativeNumber);
案例二:演示next()和nextline()的区别
Scanner scan = new Scanner(System.in);
if (scan.hasNext()) {
System.out.println(“scan.next()接收输入的数据为:” + scan.next());}
Scanner scan2 = new Scanner(System.in);
if (scan.hasNext()) {
System.out.println(“scan.nextLine()接收输入的数据为:” + scan2.nextLine());}
结果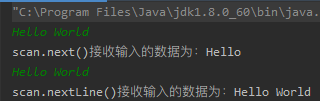
如果想获得基本数据类型,如nextInt、nextBoolean,可以用scan.nextXXType来获得,一般需要搭配hasNext使用(此时输入类型必须是能和指定类型相匹配的,否则会报错
(java.util.InputMismatchException),如nextInt不能输入123.5
Scanner scan = new Scanner(System.in);
if (scan.hasNext()) {
System.out.println(scan.nextInt());}
日期框架类
JDK8.0之前的日期和时间类:基本过时
6.5.1 java.lang.System 类
note:如在北京,得到的即是北京时间
System类提供的public static long currentTimeMillis()用来返回当前时间与1970年1月1日0时0分0秒之间以毫秒为单位的时间差。//此方法常适于计算时间差。
long iStrt = System.currentTimeMillis();Thread.sleep(10000);
long iEnd = System.currentTimeMillis();System.out.println(iEnd - iStrt);
计算世界时间的主要标准有:
UTC(Coordinated Universal Time)
GMT(Greenwich Mean Time)
CST(Central Standard Time)
java.util.Date 类
含义:表示特定的瞬间,精确到毫秒。注:Date类的API不易于国际化,大部分被废弃了.
//构造器Date():使用无参构造器创建的对象可以获取本地当前时间(note:如在北京,得到的即是北京时间)。Date(long date)//常用方法getTime():返回自 1970 年 1 月 1 日 00:00:00 GMT 以来此 Date 对象表示的毫秒数。toString():把此 Date 对象转换为以下形式的 String:dow mon dd hh:mm:ss zzz yyyy。其中:dow周,zzz是时间标准。如: Tue Mar 09 18:24:54 CST 2021
java.sql.Date类
为java.util.Date的子类,对应MySQL的Date类型数据。和java.util.Date一样,其内部的大量方法也都废弃了。
java.text.simpleDateFormate类
含义:java.text.SimpleDateFormat类是一个不与语言环境有关的方式来格式化和解析日期的具体类。它允许进行日期和文本之间进行转换
- 格式化(java.util.Date对象->String文本)
SimpleDateFormat():默认的模式和语言环境创建对象
SimpleDateFormat(String pattern)+String format(Date date):根据指定样式格式化时间对象date
案例:
SimpleDateFormat sdf = new SimpleDateFormat(“yyyy-MM-dd”);
String strDate = sdf.format(new java.util.Date());
System.out.println(strDate);
- 解析(String文本->java.util.Date对象)
public Date parse(String source):从给定字符串的开始解析文本,以生成一个日期对象。
案例:
SimpleDateFormat sdf = new SimpleDateFormat(“yyyy-MM-dd”);
java.util.Date date = sdf.parse(“2008-01-01”);
6.5.5 java.util.Calendar
- 含义:Calendar是一个抽象基类,主用用于完成日期字段之间相互操作的功能。
- 获取Calendar实例的方法
使用Calendar.getInstance()方法(如在北京,得到的即是北京时间)
调用它的子类GregorianCalendar的构造器(较少用)。
- 通过get(int field)方法来取得想要的时间信息
如YEAR、MONTH、DAYOF_WEEK、HOUR_OF_DAY 、MINUTE、SECOND
_public void set(int field,int value)
public void add(int field,int amount)
public final Date getTime()
public final void setTime(Date date)
- 注意
获取月份时:一月是0,二月是1,以此类推,12月是11
获取星期时:周日是1,周二是2 , 。。。。周六是7
JDK8.0及之后的日期和时间类
6.6.1 背景说明
JDK 1.0中包含了java.util.Date类,但是它的大多数方法已经在JDK 1.1引入Calendar类之后被弃用
了。而Calendar并不比Date好多少。它们面临的问题是:
可变性:日期和时间这样的类应该是不可变的。
偏移性:Date中的年份是从1900开始的,而月份都从0开始。
格式化:格式化只对Date有用,Calendar则不行。
此外,它们也不是线程安全的;不能处理闰秒等。
JDK8.0之后的解决方案:直接使用本地日期(LocalDate)、本地时间(LocalTime)、本地日期时间(LocalDateTime)、时区(ZonedDateTime)和持续时间(Duration)的类。如果是JDK8.0之前想用如上类,可以在Maven中引入:Joda-Time类库。
<!— https://mvnrepository.com/artifact/joda-time/joda-time —>
6.6.2 LocalDateTime/LocalDate/LocalTime(本地时区)
LocalDate、LocalTime、LocalDateTime 类是其中较重要的几个类,其均属于java.time包下
它们的实例是不可变的对象,分别表示使用 ISO-8601日历系统的日期、时间、日期和时间。
- 默认提供了简单的本地日期或时间相关的信息。即如在北京,得到的即是北京时间。除非手动指定了时区
LocalDateTime datetime = LocalDateTime.now(ZoneId.of(“Europe/Paris”));
- 没有偏移量了,即星期一从1开始,月份索引也是从1月开始
LocalDate date = LocalDate.of(2021, 3, 12);
int value = date.getDayOfWeek().getValue();
System.out.println(value);//值为5
- 字符串化和对象化
将字符串转换为时间对象:
LocalDate d = LocalDate.parse(“2020-01-01”);
将时间转换为字符串:
DateTimeFormatter formatter = DateTimeFormatter.ofPattern(“yyyy-MM-dd”);
LocalDate d = LocalDate.parse(“2020-01-01”);
String date1 = d.format(formatter);
- 其他常用方法
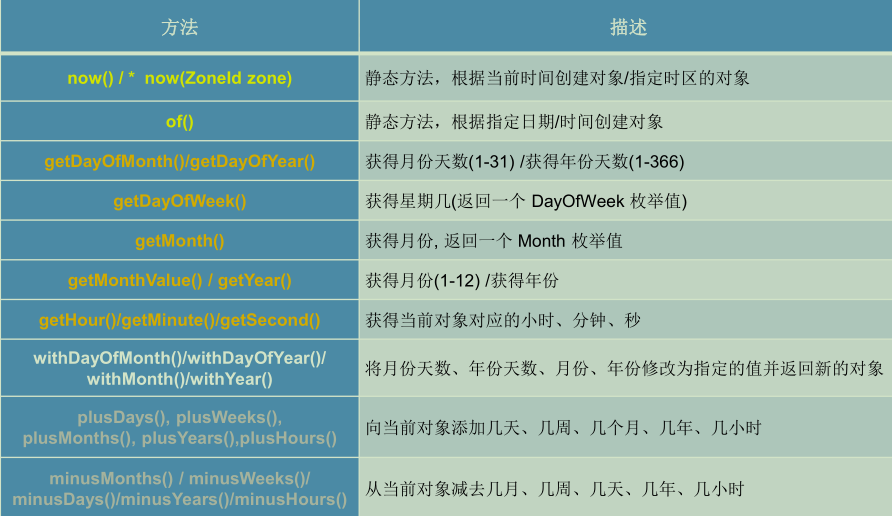
6.6.3 DateTimeFormatter(格式化附加类)
- 含义:java.time.format.DateTimeFormatter类可以实现日期对象和字符串间的转换,功能类似于
SimpleDateFormate类
- 格式化和解析方法(类似于JSON序列化和反序列化)
//格式化:将实现了TemporalAccessor接口的日期对象—>为字符串
DateTimeFormatter formatter3 = DateTimeFormatter.ofPattern(“yyyy-MM-dd hh:mm:ss”);
String str4 = formatter3.format(LocalDateTime.now());
System.out.println(str4);//2019-02-18 03:52:09
//解析:将字符串转换为TemporalAccessor接口对象(多态)
TemporalAccessor accessor = formatter3.parse(“2019-02-18 03:52:09”);
System.out.println(accessor);
如果要将字符串转换为LocalDateTime对象,则使用语句:
LocalDate d = LocalDate.parse(“2020-01-01”);
6.6.4 Instant(瞬时类)
- java.time.Instant表示时间线上的一点。其只是简单的表示自1970年1月1日0时0分0秒(UTC)
开始的秒数。默认是从UTC标准时间开始,和北京时间相差了8个时区。
- java.time包是基于纳秒计算的,所以Instant的精度可以达到纳秒级。
- 常用方法

简言之:类的toEpochMilli()方法的时间戳是指格林威治时间1970 年01 月01 日00 时00 分00 秒(北京时间1970 年01 月01日08 时00 分00 秒)起至现在的总秒数。
6.6.5 Duration和Period类(日期时间相隔类)
Duration的使用(计算时间)
Period的使用(计算日期)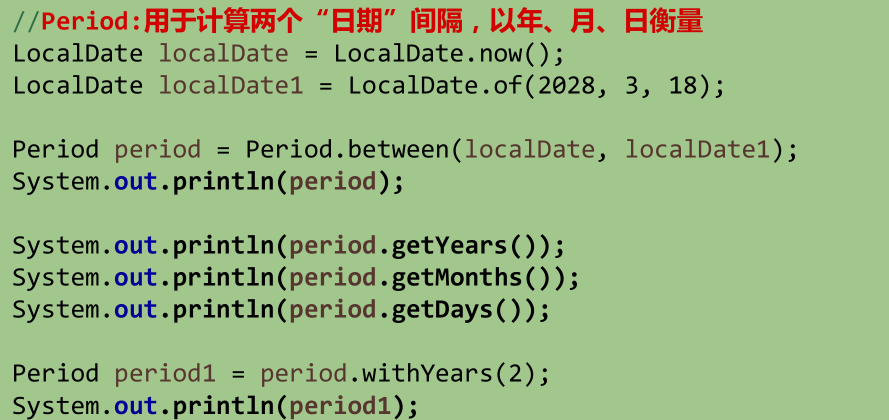
6.6.6 其他日期API

6.6.7 一些使用案例
- 根据File.lastModified来计算其实际的北京修改时间
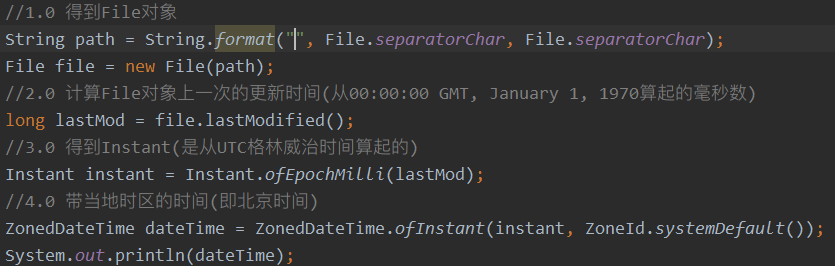
7 集合框架
概览已记
易记:
- LSP=> List、Set、Map
- AVL:Array、Vector、LinkedList;
- HS2:Hashset、SortedSet;HashMap、SortedMap
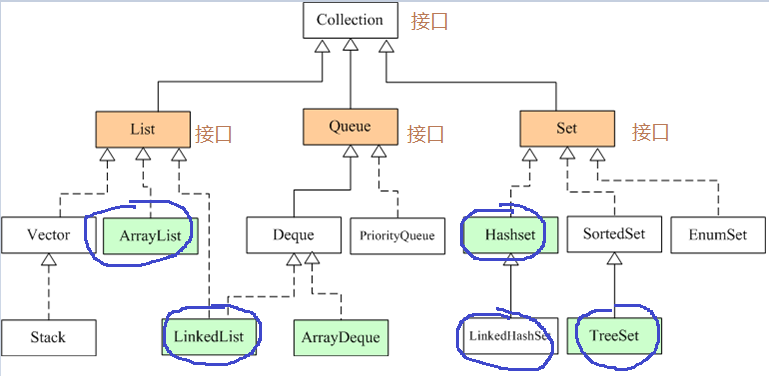
Java 集合框架主要包括两种类型的容器
- Collection集合簇(存储引用类型元素)
分为3 个子接口:List、Set 和 Queue。
- List接口簇是元素有序、可重复的集合,常用的有 ArrayList(最重要的)、LinkedList、Vector等等
- Set接口簇是元素无序、不可重复的集合,常用的有HashSet、LinkedHashSet、TreeSet等等
- Map接口簇(存储引用类型键/值对映射)
Map里存储的是键/值对。尽管 Map 不是集合,但是它们完全整合在集合中。
常见的Map类型有HashMap、LinkedHashMap 、TreeMap、HashTable、Properties等等。 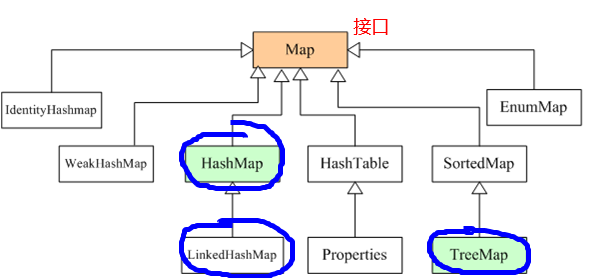
扩展:百度脑图参考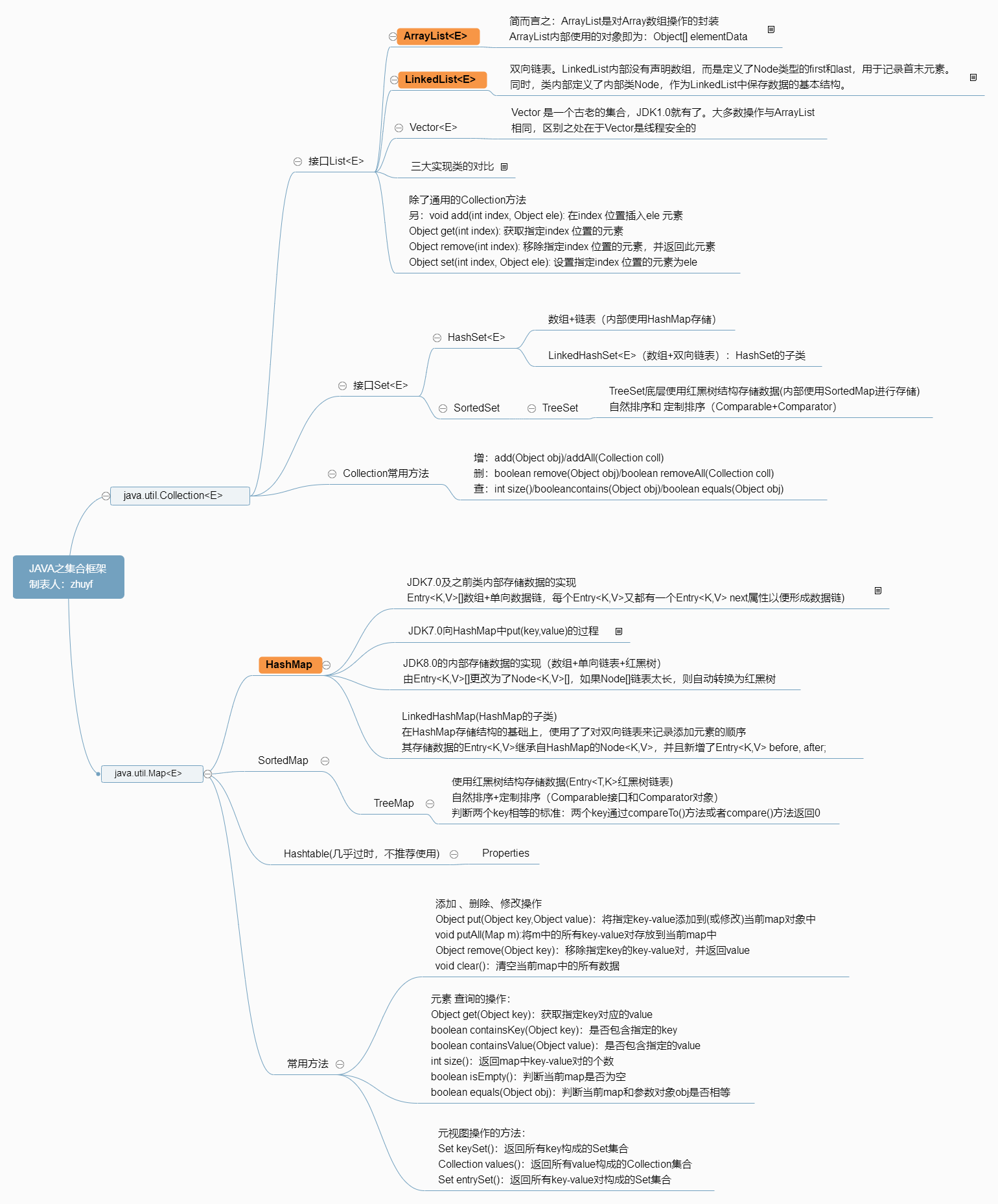
7.2 Iterator(辅助迭代器)
7.2.1 基本概念
- Iterator对象称为迭代器(设计模式的一种),主要用于遍历 Collection 集合中的元素。GOF给迭代器模式的定义为:提供一种方法访问一个容器(container)对象中各个元素,而又不需暴露该对象的内部细节。 迭代器模式,就是为容器而生。
- Collection接口继承了java.lang.Iterable接口,并且声明了一个iterator()方法,那么所有实现了Collection接口的集合类都有一个iterator()方法,用以返回一个实现了Iterator接口的对象。
- Iterator 仅用于遍历集合,Iterator 本身并不提供承装对象的能力。如果需要创建Iterator 对象,则必须有一个被迭代的集合。
- 集合对象每次调用iterator()方法都得到一个全新的迭代器对象,默认游标都在集合的第一个元素之前。

7.2.2 方法和使用
Iterator有三个主要方法:hasNext()、next()、remove()
next():指针先下移,返回值为下移后的迭代器指向的元素值
hasNext():判断是否还有下一个元素,调用迭代器的next()方法之前必须要调用hasNext()进行检测。若不调用,且下一条记录无效,直接调用it.next()会抛出NoSuchElementException异常
//1.0 循环方法一
Iterator iterator = arrayList.iterator();
//hasNext():判断是否还有下一个元素while(iterator.hasNext()) {
//next()方法:指针先下移,再返回下移后的迭代器指向的元素值
String next = (String) iterator.next();
System.out.println(next);}
//2.0 循环方法二
for (Iterator iterator1 = arrayList.iterator(); iterator1.hasNext(); ) {
String next = (String) iterator1.next();
System.out.println(next);}
//3.0 测试remove()方法
ArrayList arrayList = new ArrayList();arrayList.add(“Value”);arrayList.add(“HelloWorld”);Iterator iterator = arrayList.iterator();
while (iterator.hasNext()) {
if (iterator.next() == “Value”)
iterator.remove();}
System.out.println(arrayList.size());
结果为:1
7.2.3 foreach
- 基本说明
Java 5.0 提供了 foreach 循环迭代访问 Collection和数组。其为增强型的for循环。
遍历操作不需获取Collection或数组的长度,无需使用索引访问元素,其内部调用Iterator完成操作。
foreach还可以用来遍历数组。
- foreache原理分析
foreache内部调用了迭代器Iterator,在调用的过程中会将迭代器next()的值赋给变量
通过一个案例深入理解foreach和for循环在赋值时的差别
ArrayList
//1.0 foreach相当于迭代器内部拿到集合的String value=iterator.next()。相当于拷贝了栈地址
//后续在foreach里面做的更改都是对新的栈空间值进行的更改
for (String str : arrayList) {
str += “Update”;
System._out.println(“方法一:” + str);}for (String str : arrayList) {
System.out.println(“方法一:” + str);}
//2.0 for循环,直接对原数组更改,同一份引用地址
for (int i = 0; i < arrayList.size(); i++) {
String value = arrayList.get(i);
arrayList.set(i, value + “Update”);
System._out.println(“方法二:” + arrayList.get(i));}for (int i = 0; i < arrayList.size(); i++) {
System.out.println(“方法二:” + arrayList.get(i));}
如上的输出值结果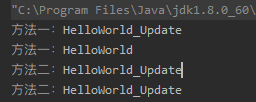
扩展补充(C#下foreach对变量进行更改__无法重新赋值):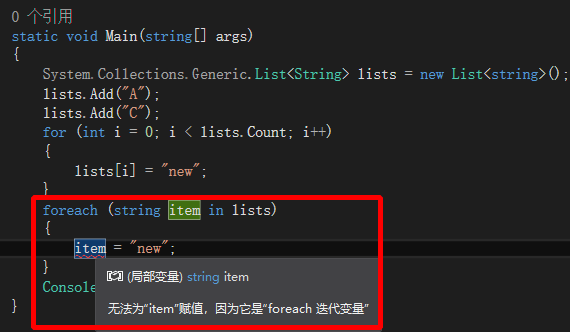
7.3 Collection(基类接口簇一)
7.3.1 基本说明
- java.util.Collection 接口是java.util.List、java.util.Set 和 java.util.Queue 接口的父接口,该接口里定义的方法,既可用于操作 Set 集合,也可用于操作 List 和 Queue 集合。
- JDK不提供此接口的任何直接实现,而是提供更具体的子接口(如:Set和List)实现。
- 在 Java5 之前,Java 集合会丢失容器中所有对象的数据类型,把所有对象都当成 Object 类型处理;从 JDK 5.0 增加了 泛型以后,Java 集合可以记住容器中对象的数据类型。
- 图示接口簇
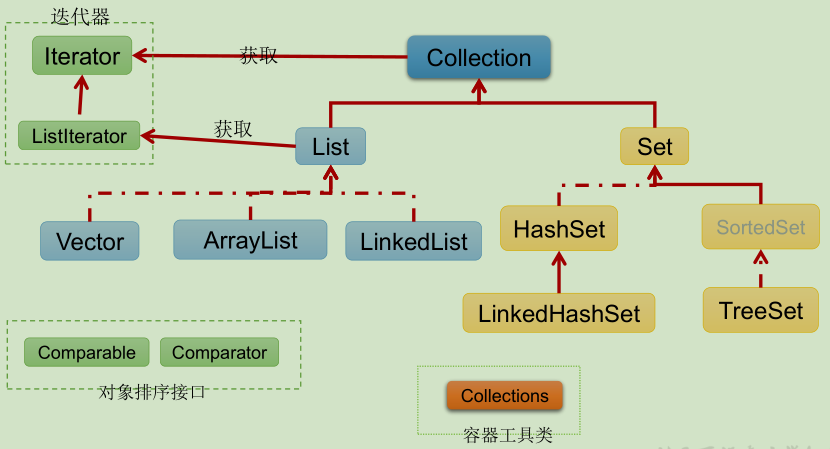
7.3.2 通用方法
- 添加
add(Object obj)
addAll(Collection coll)
- 获取有效元素的个数
int size()
- 清空集合
void clear(),清空集合的元素,不是将集合的置为null
- 是否是空集合
boolean isEmpty(),判断集合的size()==0?
- 是否包含某个元素
boolean contains(Object obj):是通过元素的equals方法来判断是否是同一个对象
boolean containsAll(Collection c):也是调用元素的equals方法来比较的。拿两个集合的元素挨个比较。注:如果是自定义的对象,需要重写equals,否则是==的比较(引用类型为比较引用地址)
- 删除
boolean remove(Object obj) :通过元素的equals方法判断是否是要删除的那个元素。只会删除找到的第一个元素
boolean removeAll(Collection coll):取当前集合的差集
- 取两个集合的交集
boolean retainAll(Collection c):把交集的结果存在当前集合中,不影响c
- 集合是否相等
boolean equals(Object obj)
- 转成对象数组
Object[] toArray()
- 获取集合对象的哈希值
hashCode()
- 遍历
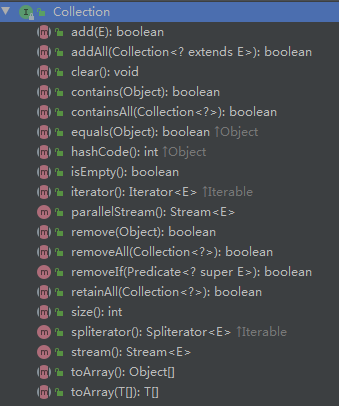
7.4 Collection_List接口簇
7.4.1 基本说明
- 鉴于Java中数组用来存储数据的局限性,我们通常使用java.util.List替代数组
- List集合类中元素有序、且可重复,集合中的每个元素都有其对应的顺序索引。
- List容器中的元素都对应一个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素。
List接口的实现类常用的有:java.util.ArrayList、java.util.LinkedList和java.util.Vector。
7.4.2 常见方法
List除了从Collection集合继承的方法外,List 集合里添加了一些根据索引来操作集合元素的方法。
void add(int index, Object element): 在index 位置插入element元素
boolean addAll(int index, Collection eles): 从index 位置开始将eles 中的所有元素添加进来
Object get(int index): 获取指定index 位置的元素
int indexOf(Object obj): 返回obj 在集合中首次出现的位置
int lastIndexOf(Object obj): 返回obj 在当前集合中末次出现的位置
Object remove(int index): 移除指定index 位置的元素,并返回此元素
Object set(int index, Object element): 设置指定index 位置的元素为element
List subList(int fromIndex, int toIndex): 返回从fromIndex 到toIndex位置的子集合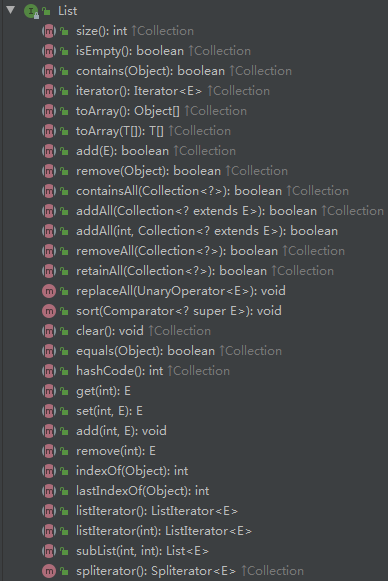
7.4.3 Collection_List_ArrayList(数组)
7.4.3.1 基本说明
底层数据结构:数组
java.util.ArrayList是 List 接口的典型实现类、主要实现类,是一个可动态修改的数组,可构造为泛型也可以不为泛型
特点:与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删除元素。
- ArrayList 继承了 AbstractList ,并实现了 List 接口.
完整包为:import java.util.ArrayList;
- ArrayList 的JDK1.8 之前与之后的实现区别?
JDK1.7:ArrayList像饿汉式,直接创建一个初始容量为10的数组
JDK1.8:ArrayList像懒汉式,一开始创建一个长度为0的数组,当添加第一个元素时再创建一个始容量为10的数组
- 构造方法可泛型和非泛型
定义使用ArrayList objectName =new ArrayList()
定义使用ArrayList
其中E为泛型数据类型,且必须为引用类型,
即不能使用ArrayList
只能使用ArrayList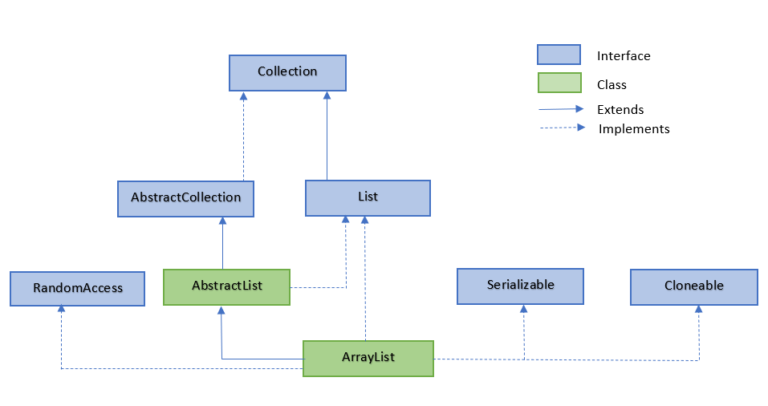
7.4.3.2 基本操作(增删查改)
//1.0 添加元素:add()
arrList.add(1);
arrList.add(2);
arrList.add(3);
//2.0 修改元素(索引下标从0开始)
arrList.set(1, 22);
//3.0 获取某个元素:get(index)
int value=arrList.get(1);
//4.0 删除元素(索引下标从0开始):remove(index)
arrList.remove(2);
//4.0 计算长度(size())
int size = arrList.size();
//5.0 循环输出
for (int v : arrList) {
System.out.println(v);
}
7.4.3.3 排序算法
使用Collections.sort(List
Collections类是一个非常有用的类,位于 java.util 包中,提供的 sort() 方法可以对字符或数字列表进行排序,该方法返回值为void,即针对原数组进行排序。
ArrayList
//使用此方法则arrList直接排好序,无需再使用返回值接收Collections.sort(arrList);
for (int v : arrList) {
System.out.println(v);}
输出结果
7.4.4 Collection_List_LinkedList(双向线性链表)
7.4.4.1 类的说明
底层数据结构:双向链表
java.util.LinkedList 继承了 java.util.AbstractSequentialList 类。
LinkedList 实现了 Queue 接口,可作为队列使用。
LinkedList 实现了 List 接口,可进行列表的相关操作。
LinkedList 实现了 Deque 接口,可作为队列使用。
LinkedList 实现了 Cloneable 接口,可实现克隆。
LinkedList 实现了 java.io.Serializable 接口,即可支持序列化,能通过序列化去传输。
LinkedList 类位于 java.util 包中,使用前需要引入它,语法格式如下:
//引入 LinkedList 类
import java.util.LinkedList;
LinkedList
或者
LinkedList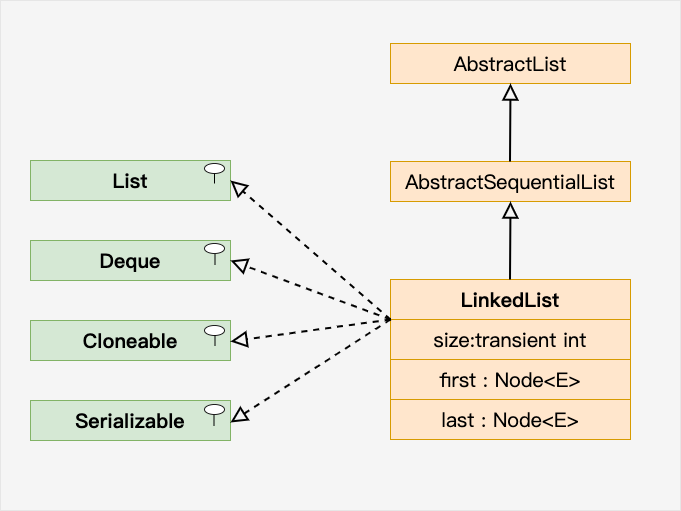
7.4.4.2 基本特征
链表(Linked list)是一种常见的基础数据结构,是一种线性表
特点:
- 是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的地址。
- 分为单链表和双链表
一个单向链表包含两个值: 当前节点的值和一个指向下一个节点的链接。
一个双向链表有三个整数值: 数值、向后的节点链接、向前的节点链接。
7.4.4.3 基本操作(增删查改)
//1.0 创建一个链表
LinkedList
//2.0 添加数据:add
linkedList.add(“Lucy”);
linkedList.add(“Lily”);
linkedList.add(“Jack”);
//3.0 修改数据(索引下标从0开始):set()
linkedList.set(1, “Lily_Update”);
//4.0 删除数据(索引下标从0开始):remove
linkedList.remove(2);
//移除第一个
linkedList.removeFirst();
//移除最后一个
linkedList.removeLast();
//5.0 查找
linkedList.get(1);
linkedList.getFirst();
linkedList.getLast();
//6.0 迭代:长度大小为size()
for (String str : linkedList) {
System.out.println(str);
}
for (int i = 0; i < linkedList.size(); i++) {
System.out.println(linkedList.get(i));
}
7.4.5 CollectionList_Vector(数组几乎过时List实现类)
底层数据结构:数组
java.util.Vector 是一个古老的集合,JDK1.0就有了。大多数操作与ArrayList相同,区别之处在于Vector是线程安全的。在各种list中,最好把ArrayList作为缺省选择。当插入、删除频繁时,使用LinkedList;Vector总是比ArrayList慢,所以尽量避免使用。
7.4.6 【小总结】ArrayList、LinkedList和Vector的区别
7.4.6.1 ArrayList和LinkedList的对比
- 基本说明
二者都线程不安全,相对线程安全的Vector,执行效率高
ArrayList:插入,删除数据慢;是顺序结构,定位快,查找快(用索引下标可以直接定位到指定下标位置), 就像电影院位置一样,有了电影票,一下就找到位置了.
LinkedList:插入,删除数据快;是链表结构,查找慢,就像手里的一串佛珠,要找出第99个佛珠,必须得一个一个的数过去,所以定位慢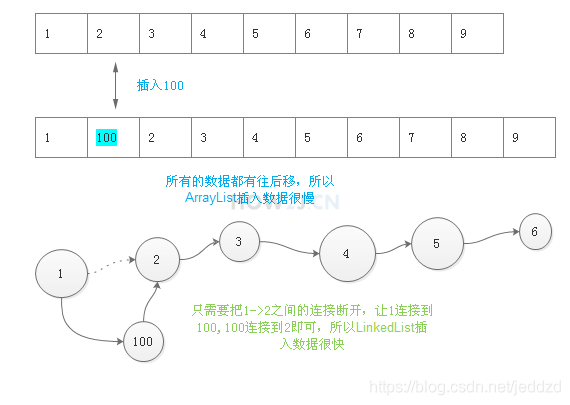
- 使用
以下情况使用 ArrayList
频繁访问列表中的某一个元素,直接快速定位。
只需要在列表末尾进行添加和删除元素操作。
以下情况使用 LinkedList
你需要通过循环迭代来访问列表中的某些元素,因为都是迭代器循环,LinkedList还有添加和删除的优势。
需要频繁的在列表开头、中间、末尾等位置进行添加和删除元素操作。
7.4.6.2 ArrayList和Vector的对比
ArrayList和Vector的区别
Vector和ArrayList几乎是完全相同的,唯一的区别在于Vector是同步类(synchronized),属于
强同步类。因此开销就比ArrayList要大,访问要慢。正常情况下,大多数的Java程序员使用
ArrayList而不是Vector,因为同步完全可以由程序员自己来控制。Vector每次扩容请求其大
小的2倍空间,而ArrayList是1.5倍。Vector还有一个子类Stack。
7.5 Collection_Set接口簇
Set接口是Collection的子接口,相对于Collection接口,Set接口本身没有再提供额外的方法
Set 集合不允许包含相同的元素,如果试把两个相同的元素加入同一个Set 集合中,则添加操作失败。
Set 判断两个对象是否相同不是使用 == 运算符,而是根据 equals() 方法。
类似于高中的集合:无需性、互异性、确定性。
7.5.1 Collection_Set_HashSet(数组+线性链表)
HashSet底层是采用:数组+链表的结构。
- java.util.HashSet是Set 接口的典型实现,大多数时候使用Set集合时都使用这个实现类。其使用
hash算法来存储集合中的元素,因此具有很好的存取、查找、删除效率。
- HashSet具有以下特点:
无序性:hashSet存储的数据在底层数组中并非按照数组索引的顺序添加,而是根据数据的哈希值决定的。无序性不等于随机性。
去重性:相同的元素只能添加一个(通过hashCode()+equals()判断相同时,会过滤掉重复的数据)
非线程安全的
集合元素可以为null
- 添加元素的过程(HashSet的原理)
本质上HashSet.add内部就是map.put(e, new Object);其中map就是HashMap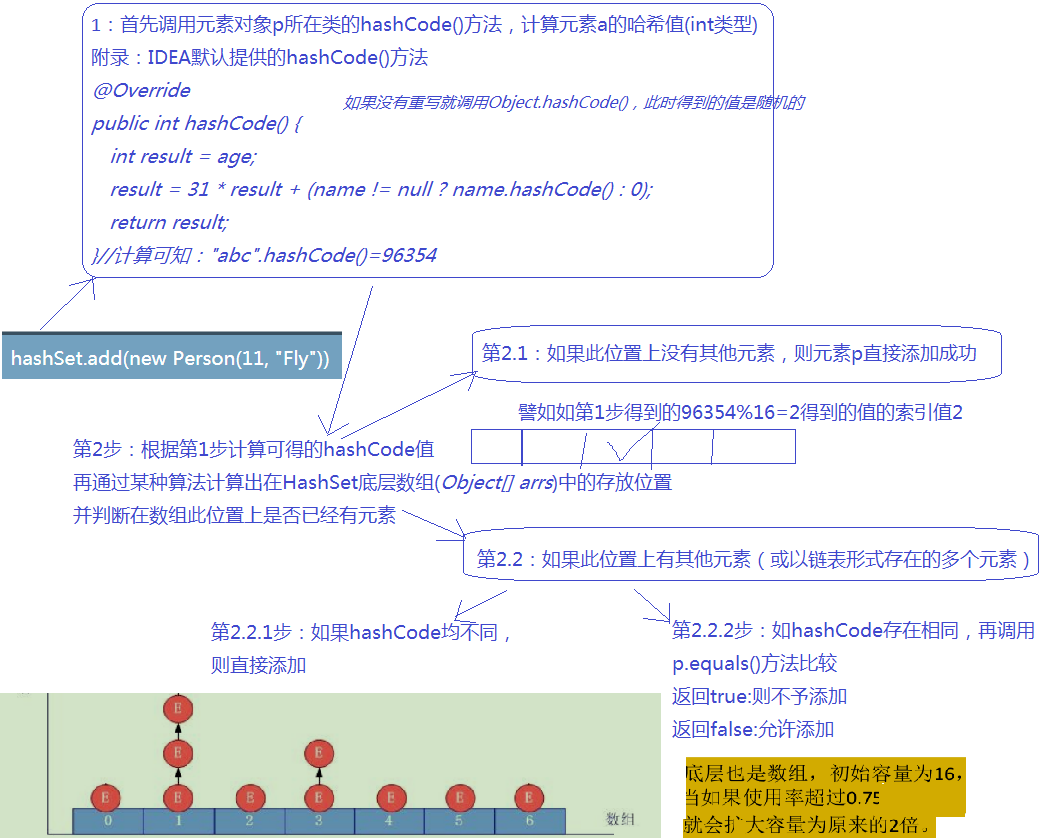
7.5.2 CollectionSet HashSet_LinkedHashSet(数组+节点线性链表)
底层结构:数组+双向链表(链表上每个节点都印象其前后值)
- java.util.LinkedHashSet是HashSet 的子类,其根据元素的 hashCode 值来决定元素的存储位置。
在添加数据的同时,每个数据还维护了两个引用,记录此数据前一个数据和后一个数据。
注:LinkedHashSet底层的插入顺序还是无序的(注:无序不代表随机),只是因为每个数据维护了两个引用,故其遍历输出的时看起来是有序的。
- 插入性能略低于 HashSet,但在迭代访问 Set 里的全部元素时有很好的性能(关键是在迭代输出时可达
到顺序输出的目的)。
- 和HashSet一样其也拥有去重性

7.5.3 Collection_Set_TreeSet(红黑树)
底层结构:红黑树
特征:向java.util.TreeSet中添加数据时,要求添加的对象必须是相同类型的且再添加时会判断该数据是否已存在,存在的则不会添加,数据在添加时会自动排序好。即:同一类性、过滤重复性、有序性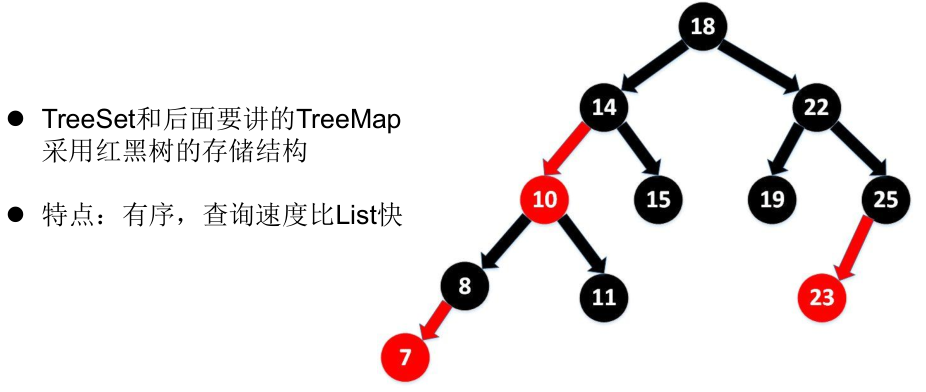
排序+添加元素的方式方式
- 自然排序添加元素
自然排序即自定义类实现了实现了Comparable接口
向TreeSet添加元素时,只有第一个元素无须比较compareTo()方法,后面添加的所有元素都会调用compareTo()方法进行比较。
添加元素判断两个对象是否相等的唯一标准是:通过compareTo(Object obj)方法比较返回值,如果是0则为相同则不添加。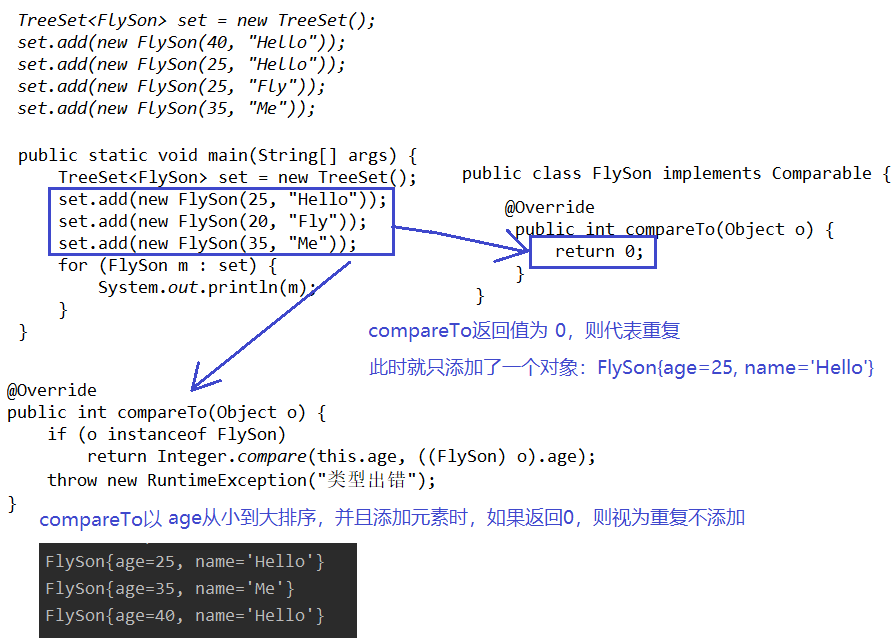
- 定制排序添加元素(自定义元素实现了Comparator接口)
发的萨芬
public static void main(String[] args) {
TreeSet
@Override
public int compare(Object o1, Object o2) {
//先根据age降序排序
if (o1 instanceof FlySon && o2 instanceof FlySon) {
int value = Integer.compare(((FlySon) o1).getAge(), ((FlySon) o2).getAge());
if (value != 0)
return -value;
//再根据name升序排序
return ((FlySon) o1).getName().compareTo(((FlySon) o2).getName());
}
throw new RuntimeException(“类型出错”);
}
});
set.add(new FlySon(40, “Hello”));
set.add(new FlySon(25, “Hello”));
set.add(new FlySon(25, “Fly”));
set.add(new FlySon(35, “Me”));
for (FlySon m : set) {
System.out.println(m);
}
}
运算结果: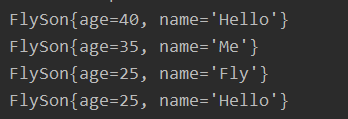
- 原理分析:TreeSet.add()方法里调用的是其内部属性TreeMap
用Comparator.compare()方法(如果TreeSet添加的对象有重写了compare方法则会在TreeMap构造器里重置该Comparator对象)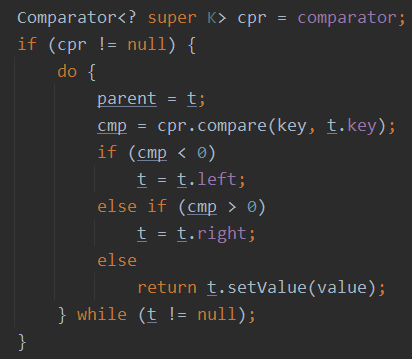
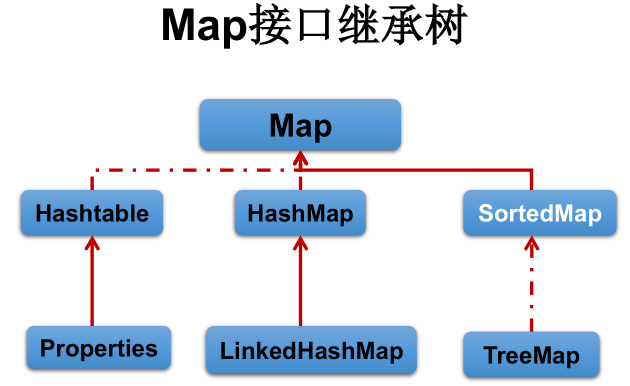
7.6 Map(基类接口簇二)
7.6.1 Map继承树
7.6.2 Map定义的方法
- 添加、删除、修改操作
Object put(Object key,Object value):将指定key-value添加到(或修改)当前map对象中
void putAll(Map m):将m中的所有key-value对存放到当前map中
Object remove(Object key):移除指定key的key-value对,并返回value
void clear():清空当前map中的所有数据
- 元素查询的操作
Object get(Object key):获取指定key对应的value
boolean containsKey(Object key):是否包含指定的key
boolean containsValue(Object value):是否包含指定的value
int size():返回map中key-value对的个数
boolean isEmpty():判断当前map是否为空
boolean equals(Object obj):判断当前map和参数对象obj是否相等
- 元视图操作的方法
Set keySet():返回所有key构成的Set集合
Collection values():返回所有value构成的Collection集合
Set entrySet():返回所有key-value对构成的Set集合
- 总结(常用方法)
添加:put(Object key,Object value)
删除:remove(Object key)
修改:put(Object key,Object value)
查询:get(Object key)
长度:size()
遍历:keySet()/values()/entrySet()
7.7 Map_HashMap(数组+单向链表+~红黑树)
7.7.1 类的说明
底层数据结构:数组+链表(jdk7及之前)/数组+链表+红黑树(jdk 8)
HashMap继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable 接口。
- java.util.HashMap是一个散列表,实现了 Map 接口,根据key.hashCode()值存储数据。综合了数组+链表的特征,具有很快的访问速度。
- 线程不安全性:不支持线程同步
- 无序性:HashMap 是无序的,即不会记录插入的顺序。
- 去重性:如果key相同的话,hashMap将不会再加入
7.7.2 HashMap的Entry结构(key-value)
存储键值对key/value支持泛型和非泛型,必须是引用类型,最多允许一条记录的key/value为null。
Map中的key:使用Set存储所有的key,是无序的、不可重复的集合。key所在的类要重写equals()和hashCode()(以HashMap为例)。Stone平台的规定 【强制】:凡是重写过equals,则必须重写hashCode。
Map中的value:使用Collection存储所有的value,是无序的、可重复的集合,value所在的类要重写equals()。
一个键值对:key-value构成了一个Entry对象,Map中的entry是无序的、不可重复的,使用Set存储所有的entry。
7.7.3 HashMap底层知识的一些常量知识

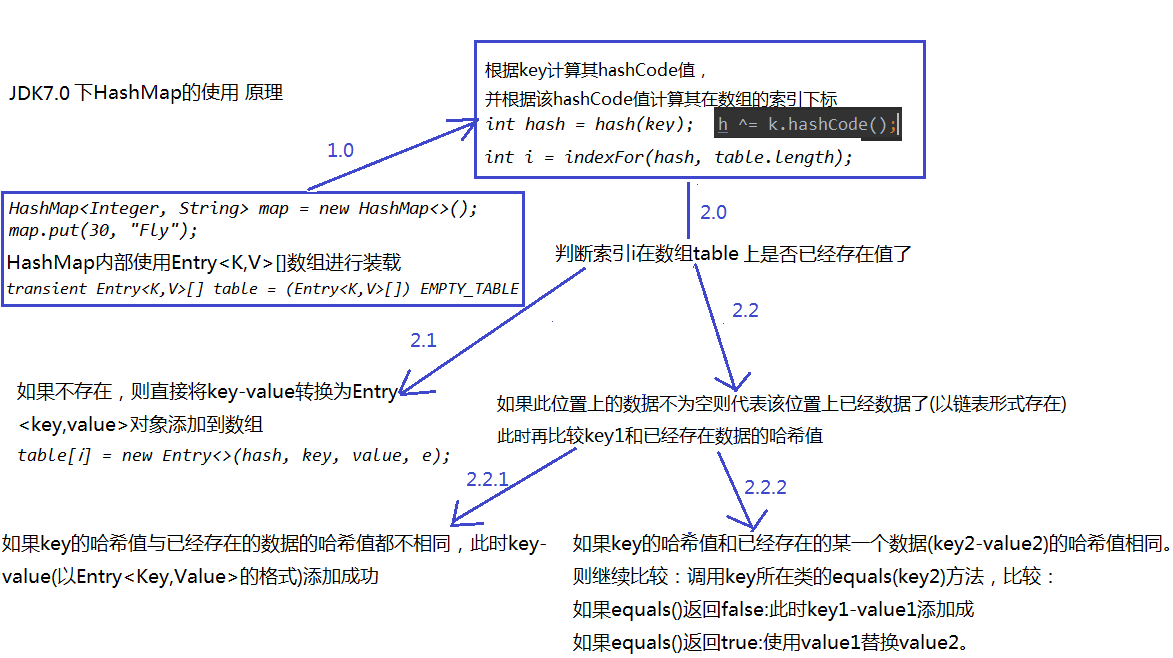
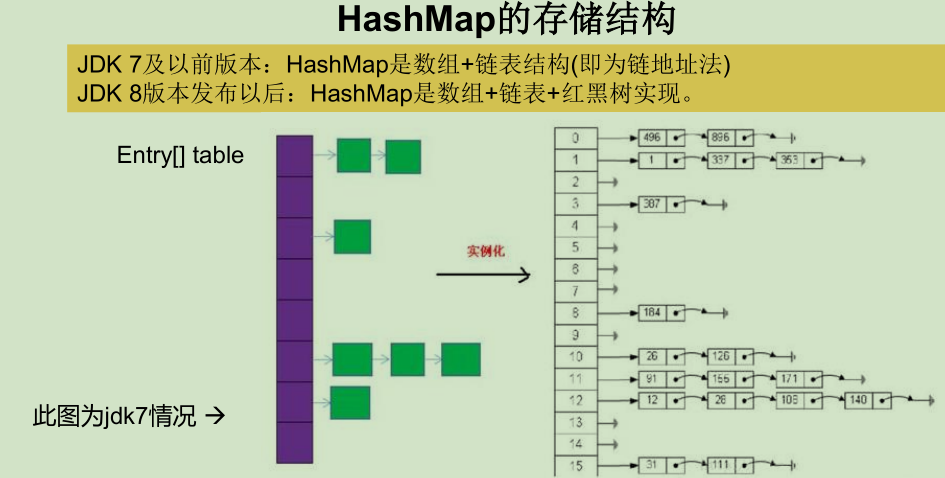
7.7.4 HashMap存储结构及添加元素的原理
- JDK7.0HashMap添加元素的原理以及存储结构
- JDK8.0相对于JDK7.0的改动

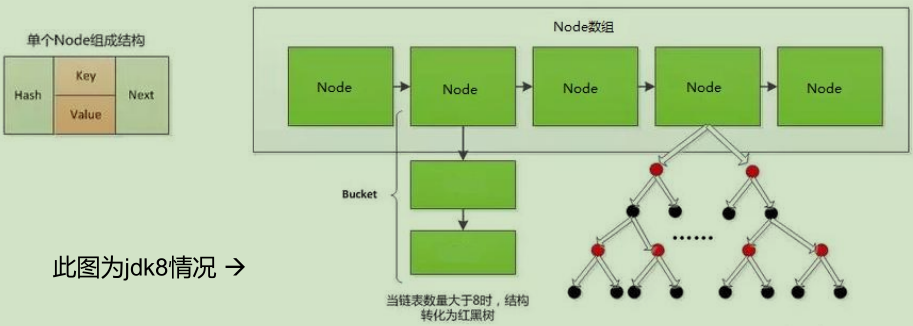

7.7.5 HashMap的扩容和树形化机制



7.7.6 基本操作(增删查改)
//1.0 创建一个HashTable
HashMap
//2.0 添加数据:add
//特别说明:如果key相同的话,hashMap将不会再加入
hashMap.put(“Fly”, “Zhu”);
if (hashMap.containsKey(“EHua”) == false)
hashMap.put(“EHua”, “Wu”);
//3.0 修改数据
//不提供修改功能
//4.0 删除数据:remove(key),不支持以索引下标的方式删除
hashMap.remove(“Fly”);
//清空HashMap对象
hashMap.clear();
//5.0 查找:get(key),不支持以索引下标的方式search
hashMap.get(“Fly”);
//6.0 迭代:循环keys、循环values
//循环entry
for (Map.Entry
System.out.println(kvPair.getKey());
System.out.println(kvPair.getValue());
}
//循环keys
for (String key : hashMap.keySet()) {
System.out.println(key);
}
//循环values
for (String value : hashMap.values()) {
System.out.println(value);
}
7.7.7 Map_HashMap_LinkedHashMap(数组+双向链表+~红黑树)
java.util.LinkedHashMap是HashMap的子类,在HashMap存储结构的基础上,使用了一对双向链表来记录添加元素的顺序;与LinkedHashSet类似,LinkedHashMap可以维护Map的迭代顺序:迭代顺序与 Key-Value 对的插入顺序一致。
7.8 Map_TreeMap(红黑树排序)

7.9 Map_Hashtable(几乎过时)
和Collection_List_Vector一样古老的API,JDK1.0就有了。现基本处于被放弃状态。
Hashtable不允许添加null对象
线程安全的,效率低,已不再推荐使用,如果需要使用线程安全的HashMap,可使用
Collections.synchronizedMap()方法
7.10 Collections(集合静态工具类)
7.10.1 常用方法
reverse(List):反转 List 中元素的顺序
shuffle(List):对 List 集合元素进行随机排序
sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序
sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换
Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
Object min(Collection)
Object min(Collection,Comparator)
int frequency(Collection,Object):返回指定集合中指定元素的出现次数
void copy(List dest,List src):将src中的内容复制到dest中
boolean replaceAll(List list,Object oldV,Object newVal):使用新值替换 List 对象的所有旧值
7.10.2 转线程安全对象
Collections 类中提供了多个 synchronizedXxx() 方法,该方法可使将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题
//返回的list1即为线程安全的List
List list = new ArrayList();
List synlist = Collections.synchronizedList(list);
8 IO框架
8.1 system.io.File类
8.1.1 一些基础知识
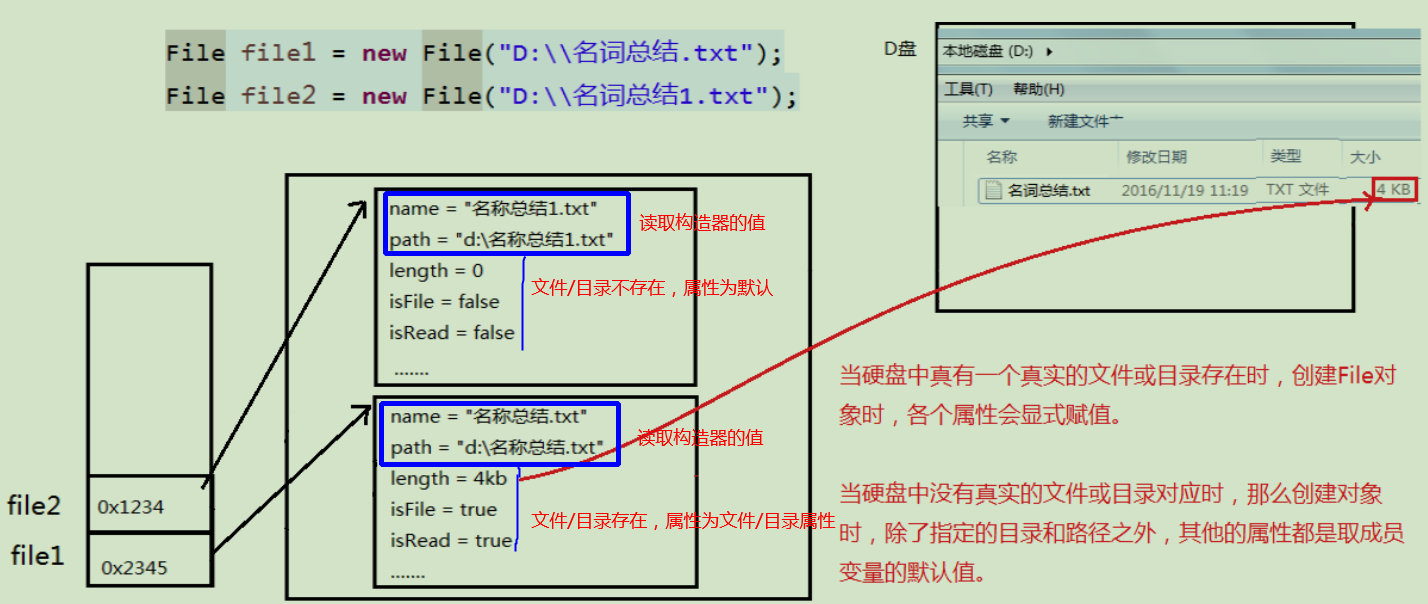
- system.io.File类的概念:一个文件和目录的抽象表示类,主要用于文件和目录的创建、查找、删除等。
File 不能访问文件内容本身,访问文件内容本身需要使用输入/输出流。其并不要求是真实存在的文件和目录,即new File(Path),如果Path不存在,则不会报错。
- 路径的分隔符:Java的跨平台
路径分隔符和系统有关:windows和DOS系统默认使用”\”来表示,UNIX和URL使用”/”来表示。Java程序支持跨平台运行,因此路径分隔符要慎用:使用String.format()进行格式化拼接
String path = String.format(“%cF%cn.txt”, File.separatorChar, File.separatorChar);File file = new File(path);
System.out.println(file.getAbsoluteFile());
输出结果: F:\F\n.txt
8.1.2 File类的重要特征(文件/目录的抽象表示对象)
8.1.3 File类的常用方法



8.2 Java的编码和解码
8.2.1 计算机存储的基础概念
- 比特(bit)
是计算机存储的最小单位
- 字节(Byte)
是计算机信息技术用于计量存储容量的一种计量单位。通常情况下,1Byte=8bit
字符集合(Character set)
是一组形状的集合,例如所有汉字的集合,发明于公元前,发明者是仓颉。它体现了字符的“形状”,与计算机、编码等无关。
8.2.2 计算机编码的相关术语
- 编码字符集(Coded character set)
是一组字符对应的编码(即数字),为字符集合中的每一个字符给予一个数字。最早的编码字符集ASCII,发明于1967年。Java使用的unicode,发明于1994年(持续更新中)。由于编码字符集为每一个字符赋予一个数字,因此在java内部,字符可以认为就是一个16位的数字,因此以下方式都可以给字符赋值
- 字符编码方案(Character-encoding schema)
将字符编码(数字)映射到一个字节数组的方案,因为在磁盘里,所有信息都是以字节的方式存储的。因此Java的16位字符必须转换为一个字节数组才能够存储。例如UTF-8字符编码方案,它可以将一个字符转换为1、2、3或者4个字节。
- 字符集(Charset)
是编码字符集和字符编码方案的组合。
====具体内容===
- Unicode是一个编码字符集
Unicode的全称是“Universal Multiple-Octet Coded Character Set”,通用多字节编码字符集,简写为UCS。 因此我们知道:Unicode规定了一组字符对应的编码。恰好这组字符就是全人类目前所有的字符。 那么UCS-2和UCS-4是什么意思?UCS-2是指用两个字节对应一个字符的编码字符集;UCS-4则是指用四个字节对应一个字符的编码字符集。你可以认为,目前为止Unicode有两个具体的编码字符集,UCS-2和UCS-4。 Java使用的是UCS-2,即我们前面提到的,一个字符由一个16位的二进制数(2个字节)表示。
- GBK是一个字符集
GBK同时包含编码字符集和字符编码方案。GBK编码了目前使用的大多数汉字(编码字符集),它将每一个汉字映射为两个字节,对于英文和数字,它则使用与ASCII相同的一个字节编码(字符编码方案)。
- UTF是字符编码方案
Unicode是某种编码字符集(目前包括UCS-2和UCS-4两种),而UTF则是字符编码方案,就是将字符编码(数字)映射到一个字节数组的方案。UTF中的U是指Unicode,也就是将Unicode编码映射到字节数组的方案。目前UTF包括UTF-7、UTF-8、UTF-16和UTF-32,后面的数字代表转换时最小的位数。例如UTF-8就是用几个8位二进制数来代表一个Unicode编码。而UTF-15就是用几个16位二进制数来代表一个Unicode编码。
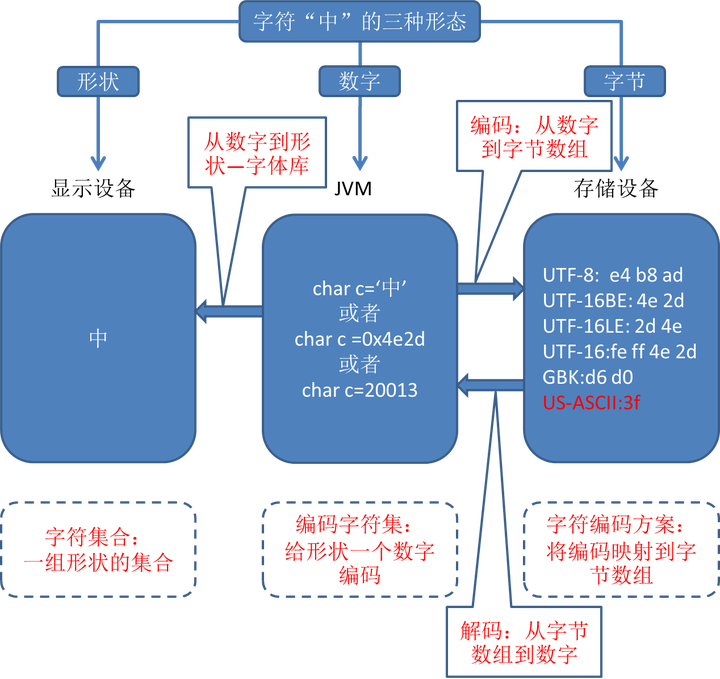
8.2.3 字符的三态转换
简言之:字符的形态有三种,分别是“形状”、“数字”和“字节数组”,分别涉及字符的“形状”、“数字(字符集)”、“字节数组(字符编码方案-涉及到存储和内存计算)”
- 形状和数字之间的转换(通过字体库—Java是通过Unicode字体库)
char/Character在JVM内部是基于Unicode规范的,每个char占据2个字节.
故char c1=’中’;和十进制的char c2 = 20013;以及十六进制的char c3 = 0x4E2D;三者是相等的
- 数字和字节数组之间的转换(通过字符编码)
譬如char c=’中’的Unicode编码为20013(十进制),其在内存里面就是两个字节存着二进制的20013。如果要将这个20013(100111000101101)得到字节数组(程序使用或存入硬盘),此时就涉及到编码/解码了
从数字(数字是从形状转化而来)到字节数组:编码
从字节数组到数字(进一步到形状):解码

8.3 I/O流程基础框架概览
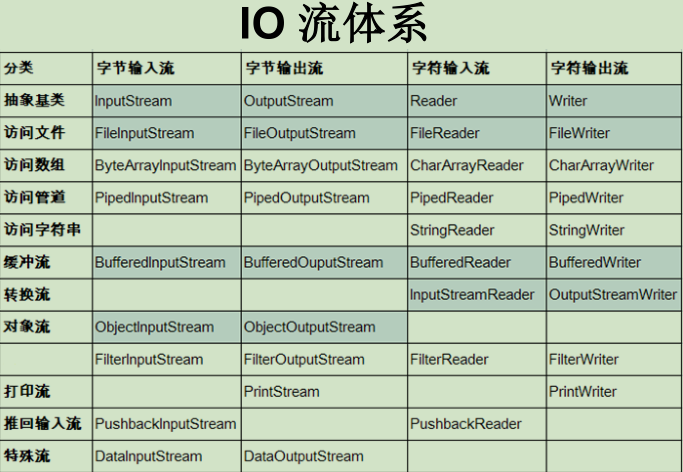
8.3.1 流的分类和体系
按操作数据单位不同分为:字节流(8 bit),字符流(16 bit)
按数据流的流向不同分为:输入流,输出流
按流的角色的不同分为:节点流,处理流
Java只有FileInputStream/OutputStream/Reader/Writer才是节点流,其余的都是包装了节点流的处理流
8.3.2 关键使用注意点
- 流在读取文件时,必须要保证文件已存在,否则会报异常。
- 字节流操作字节,比如:mp3、avi、rmvb、mp4、jpg、doc、ppt;字符流操作字符,只能操作普通文本文
件,如:txt、java、c、cpp等语言的源代码。note:其实涉及到文件的复制传递,字节流也是可以操作的,只是一般推荐使用字符流来操作,因为字符流会更高效
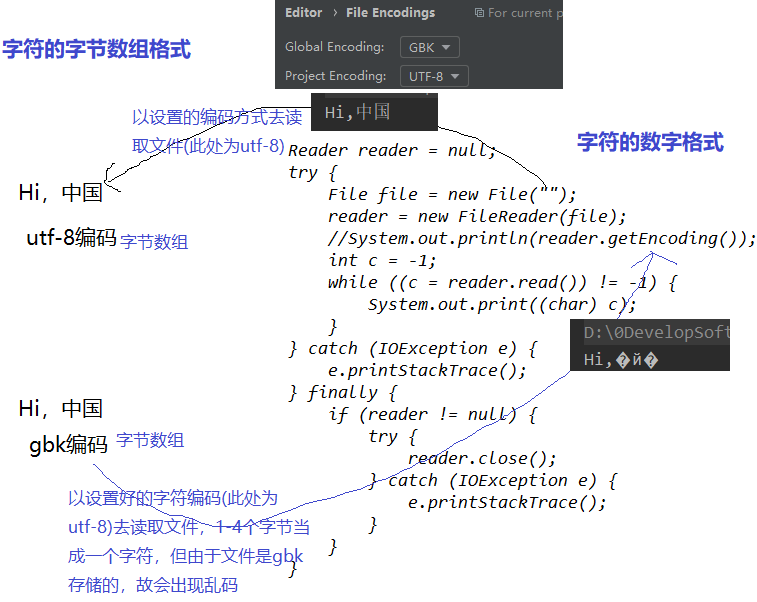
- 通过字符流读取文本文件,需要确保文本本身的编码格式和IDEA设置的编码格式保持一致,否则会出
现乱码(字符流类不能手动设置编码格式)。
- 流的使用一般分为4个操作:造File对象、造流(包括节点及处理流)、操作、关闭流
8.3.3 四大抽象基础流之InputStream字节流
基础方法
- int read():从输入流中读取数据的下一个字节。返回 0 到 255 范围内的 int 字节值。如果因
为已经到达流末尾而没有可用的字节,则返回值 -1。
- int read(byte[] b):从此输入流中将最多 b.length 个字节的数据读入一个 byte 数组中。如果因
为已经到达流末尾而没有可用的字节,则返回值 -1。否则以整数形式返回实际读取的字节数。
- int read(byte[] b, int off,int len):将输入流中最多 len 个数据字节读入 byte 数组。尝试读
取 len 个字节,但读取的字节也可能小于该值。以整数形式返回实际读取的字节数。如果因为流位于文件末尾而没有可用的字节,则返回值 -1。
pubslic void close() throws IOException:关闭此输入流并释放与该流关联的所有系统资源。
8.3.4 四大抽象基础流之OutputStream字节流
基础方法
void write(int b):将指定的字节写入此输出流。write 的常规协定是:向输出流写入一个字节。要
写入的字节是参数 b 的八个低位。b 的 24 个高位将被忽略。 即写入0~255范围的。
- void write(byte[] b):将 b.length 个字节从指定的 byte 数组写入此输出流。write(b) 的常规
协定是:应该与调用 write(b, 0, b.length) 的效果完全相同。
- void write(byte[] b,int off,int len):将指定 byte 数组中从偏移量 off 开始的 len 个
字节写入此输出流。
- public void flush()throws IOException:刷新此输出流并强制写出所有缓冲的输出字节,调用此
方法指示应将这些字节立即写入它们预期的目标。
- public void close() throws IOException:关闭此输出流并释放与该流关联的所有系统资源。
再调用close前应确保flush已经关闭了(有些子类的内部已经显示调用了flush)
8.3.5 四大抽象基础流之Reader字符流
基础方法
- int read():以设置的编码方法读取文件的单个字符,并将其转换为Unicode字符码并返回(范围在
0~65535之间),如果已达到流的末尾,则返回-1。
- int read(char[] cbuf):以设置的编码方法将字符读入数组。如果已到达流的末尾,则返回 -1。否则
返回本次读取的字符数。
- int read(char[] cbuf,int off,int len):将字符读入数组的某一部分。存到数组cbuf中,从off
处开始存储,最多读len个字符。如果已到达流的末尾,则返回 -1。否则返回本次读取的字符数。
void close() throws IOException:关闭此输入流并释放与该流关联的所有系统资源。
8.3.6 四大抽象基础流之Writer字符流
基础方法
void write(int c):写入单个字符。要写入的字符包含在给定整数值的 16 个低位中,16 高位被忽略。
即写入0 到 65535 之间的Unicode码。所以为什么不能通过Reader和Writer读取图片、视频等字节文件,因为字节文件不是根据Unicode进行编码的,其字符值在转Unicode有可能超过了65535。
- void write(char[] buf,int off,int len)写入字符数组的某一部分。从off开始,写入len个字符
- void write(String str,int off,int len)写入字符串的某一部分。
- void flush():刷新该流的缓冲,则立即将它们写入预期目标。
- public void close() throws IOException:关闭此输出流并释放与该流关联的所有系统资源。
再调用close前应确保flush已经关闭了(有些子类的内部已经显示调用了flush)
8.4 文件流(输入输出+字节字符+节点)
常见的直接访问文件的具体流包括
FileReader: 输入流+字符流+节点流
FileWritter:输出流+字符流+节点流
FileInputStream:输出流+字节流+节点流
FileOutputStream:输出流+字节流+节点流
8.4.1 读字符文本(FileReader和FileWriter)
FileInputStream fis = null;FileOutputStream fos = null;
try {
//1.0 造File对象
File srcFile = new File(srcPath);
File destFile = new File(destPath);
//2.0 造流
fis = new FileInputStream(srcFile);
fos = new FileOutputStream(destFile);
//3.0 复制的过程
byte[] buffer = new byte[1024];
int len;
while((len = fis.read(buffer)) != -1){
fos.write(buffer,0,len);
}
} catch (IOException e) {
e.printStackTrace();} finally {
//4.0 关闭流
if(fos != null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(fis != null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
8.4.2 读字节文本(FileInputStream和FileOutputStream)
/需求:通过FileInputStream和FileOutputStream来复制一个字节文件(如图片/视频等)/
FileInputStream fis = null;FileOutputStream fos = null;
try {
//1.0 造File对象
File srcFile = new File(“1.jpg”);
File destFile = new File(“2.jpg”);
//2.0 造流
fis = new FileInputStream(srcFile);
fos = new FileOutputStream(destFile);
//3.0 复制
byte[] buffer = new byte[5];
int len;
while((len = fis.read(buffer)) != -1){
fos.write(buffer,0,len);
}
} catch (IOException e) {
e.printStackTrace();} finally {
//4.0 关闭流
if(fos != null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(fis != null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
8.5 缓冲流(输入输出+字节字符+处理)
8.5.1 基本概念
- 为了提高数据读写的速度,Java API提供了带缓冲功能的流类,在使用这些流类时,会创建一个内部缓冲
区数组,缺省使用8192个字节(8Kb)的缓冲区。
缓冲流要”套接”在相应的节点流之上,根据数据操作单位可以把缓冲流分为:
BufferedInputStream 和BufferedOutputStream
BufferedReader 和BufferedWriter
- 缓存区字节组的使用
读操作:当使用BufferedInputStream读取字节文件时,BufferedInputStream会一次性从文件中读取8192个(8Kb),存在缓冲区中,直到缓冲区装满了,才重新从文件中读取下一个8192个字节数组当读取数据时,数据按块读入缓冲区,其后的读操作则直接访问缓冲区。
写操作:向流中写入字节时,不会直接写到文件,先写到缓冲区中直到缓冲区写满,BufferedOutputStream才会把缓冲区中的数据一次性写到文件里。使用方法flush()可以强制将缓冲区的内容全部写入输出流。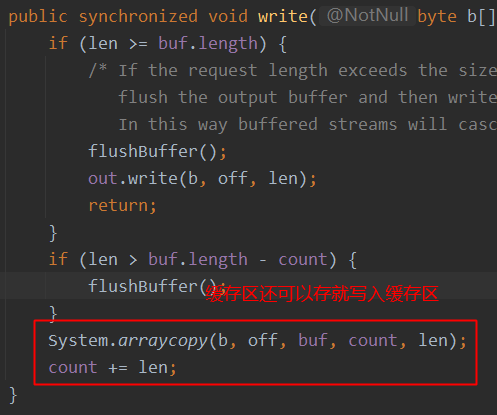
flush()方法的使用:手动将buffer中内容写入文件,只有Write输出流才有flush()方法,即不存储
在缓冲区了,直接往目标文件里面写。
- 关闭流close():关闭流的顺序和打开流的顺序相反。只要关闭最外层流即可,关闭最外层流也会相应关
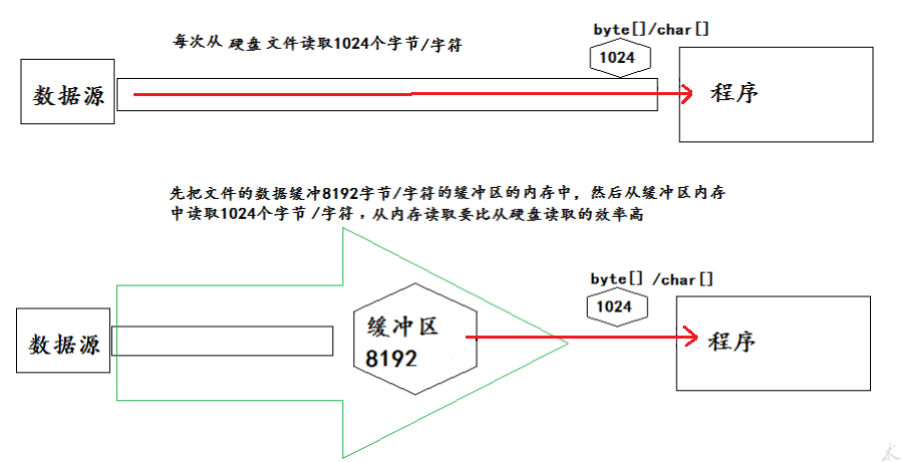
8.5.2 典型案例
- 一个典型的使用BufferedInputStream/ BufferedOutputStream复制文件(字符or字节文件)的案例
BufferedInputStream bufferedInputStream = null;BufferedOutputStream bufferedOutputStream = null;
try {
//1.0 造文件
File srcfile = new File(“11.png”);//也可以复制文本
File desFile = new File(“111.png”);
//2.1 造节点流
FileInputStream inputStream = new FileInputStream(srcfile);
FileOutputStream outputStream = new FileOutputStream(desFile);
//2.2 造缓冲流(处理流)
bufferedInputStream = new BufferedInputStream(inputStream);
bufferedOutputStream = new BufferedOutputStream(outputStream);
//4.0 开始读-写数据(此时读写数据都是直接从缓冲区里面读的)
byte[] bytes = new byte[1024];
int hasReadLen = -1;
while ((hasReadLen = bufferedInputStream.read(bytes)) != -1) {
//System.out.println(hasReadLen);
//必须要指定读了多少才能写入多少,否则会出错
bufferedOutputStream.write(bytes, 0, hasReadLen);
//强制刷新缓冲区,使其数据写入到缓存流里面
//可以省略,因为前面的write()方法内部已经flush()了
//bufferedOutputStream.flush();
}
} catch (IOException e) {
e.printStackTrace();} finally {
//4.1 关闭输出流
if (bufferedOutputStream != null) {
try {
//关闭了缓冲流的close(),其附加的节点流outputStream也关闭了
//按道理,调用close()方法应先flush,但是前面writer方法内部已经flush了
bufferedOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
//4.2 关闭输入流
if (bufferedInputStream != null) {
try {
//关闭了缓冲流的close(),其附加的节点流inputStream也关闭了
bufferedInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
- 使用BufferReader和BufferedWriter来复制文本文件(仅能复制文本文件)
BufferedReader br = null;BufferedWriter bw = null;
try {
//创建文件和相应的流
br = new BufferedReader(new FileReader(new File(“dbcp.txt”)));
bw = new BufferedWriter(new FileWriter(new File(“dbcp1.txt”)));
//读写操作
/方式一:使用char[]数组
char[] cbuf = new char[1024];
int len;
while((len = br.read(cbuf)) != -1){
bw.write(cbuf,0,len);
bw.flush();
}
/
//方式二:使用String
String data;
while((data = br.readLine()) != null){
//方法一:
//bw.write(data + “\n”);//data中不包含换行符
//方法二:
bw.write(data);//data中不包含换行符
bw.newLine();//提供换行的操作
}
} catch (IOException e) {
e.printStackTrace();} finally {
//关闭资源
if(bw != null){
try {
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(br != null){
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
8.6 转换流(输入输出+字符+处理)
8.6.1 基本概念
- 转换流提供了在字节流和字符流之间的转换,其本身即属于字符流,Java API提供了两个转换流:
InputStreamReader:将InputStream 转换为Reader
OutputStreamWriter:将Writer 转换为OutputStream
- 使用场景:字节流中的数据都是字符时,转成字符流操作更高效;文件转码
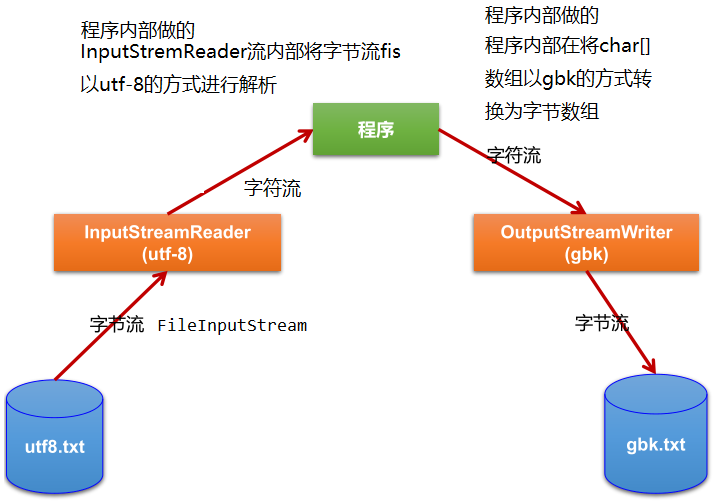
8.6.2 案例:文件转码
将一个utf-8编码格式的文件转码为gbk编码格式的
InputStreamReader reader = null;OutputStreamWriter writer = null;
try {
//1.0 造File对象
File srcFile = new File(“utf8.txt”);
File descFile = new File(“gbk.txt”);
//2.1 造节点流
FileInputStream fis = new FileInputStream(srcFile);
FileOutputStream fos = new FileOutputStream(descFile);
//2.2 造处理流(设置指定的字符编码)
reader = new InputStreamReader(fis, “utf-8”);//以utf-8编码形式解析源文件
writer = new OutputStreamWriter(fos, “gbk”);//以gbk编码形式保存新文件
//3.0 开始转换处理
int hasReadLen = -1;
char[] chars = new char[1024];
while ((hasReadLen = reader.read(chars)) != -1) {
//无需手动调用flush
writer.write(chars, 0, hasReadLen);
}
} catch (IOException e) {
e.printStackTrace();} finally {
//4.0 关闭流(关闭了处理流close()方法内部就关闭了其附加的节点流)
if (writer != null) {
try {
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
8.7 对象流(输入输出+字节+处理)
8.7.1 基本概念
- ObjectInputStream 和OjbectOutputSteam:用于存储和读取基本数据类型数据或对象的处理流。可
以把Java中的对象写入到数据源中,也能把对象从数据源中还原回来。
- 序列化和反序列化
序列化:用ObjectOutputStream类,保存基本类型数据或对象的机制
反序列化:用ObjectInputStream类,读取基本类型数据或对象的机制
ObjectOutputStream和ObjectInputStream不能序列化static和transient修饰的成员变量
8.7.2 对象可序列化
对象可序列化必须满足两个条件
- 【强制】实现Serializable接口,大部分作为参数的类如String 、Integer 等都实现了
java.io.Serializable 的接口,也可以利用多态的性质,作为参数使接口更灵活,自定义的类如果需要序列化也需要实现Serializable接口。
- 【强制建议】指定serialVersionUID。private static final long serialVersionUID.该字段用
来验证版本是否一致性。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化。如果类没有显示定义这个静态常量,它的值是Java运行时环境根据类的内部细节自动生成的。若类的实例变量做了修改,serialVersionUID 可能发生变化。故强制建议显式声明。
8.7.3 典型案例
/序列化对象并保存到磁盘,同时读取/
ObjectOutputStream oos = null;ObjectInputStream ois = null;
try {
//1.0 输出:造文件、造流(节点+处理流)
oos = new ObjectOutputStream(new FileOutputStream(“obj.data”));
//2.0 输出:添加对象
oos.writeObject(10);
oos.flush();
oos.writeObject(“Fly”);
oos.flush();
oos.writeObject(new FlySon(10, “F”));
oos.flush();
//3.0 输入:得到对象
ois = new ObjectInputStream(new FileInputStream(“obj.data”));
int intVal = (int) ois.readObject();
String strVal = (String) ois.readObject();
FlySon flySonVal = (FlySon) ois.readObject();
System.out.println(intVal);
System.out.println(strVal);
System.out.println(flySonVal);} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();} finally {
if (oos != null) {
try {
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (ois != null) {
try {
ois.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
自定义类
public class FlySon implements Serializable {
public static final long serialVersionUID = 47546353457732L;
}
8.8 随机读取流
8.9 NIO及NIO2.0
8.9.1 NIO
Java NIO (New IO,Non-Blocking IO)是从Java 1.4版本开始引入的一套新的IO API,可以替代标准的Java IO API。NIO与原来的IO有同样的作用和目的,但是使用的方式完全不同,NIO支持面向缓冲区的(IO是面向流的)、基于通道的IO操作。NIO将以更加高效的方式进行文件的读写操作。
Java API中提供了两套NIO,一套是针对标准输入输出NIO,另一套就是网络编程NIO。
8.9.2 NIO2.0(Path/Files/Paths)
随着 JDK 7 的发布,Java对NIO进行了极大的扩展,增强了对文件处理和文件系统特性的支持,以至于我们称他们为 NIO.2。因为 NIO 提供的一些功能,NIO已经成为文件处理中越来越重要的部分。
- Path(File类的升级版)
早期的Java只提供了一个File类来访问文件系统,但File类的功能比较有限,所提供的方法性能也不高。而且,大多数方法在出错时仅返回失败,并不会提供异常信息。NIO.2(JDK7.0)为了弥补这种不足,引入了Path接口,代表一个平台无关的平台路径,描述了目录结构中文件的位置。Path可以看成是File类的升级版本,实际引用的资源也可以不存在。
在以前IO操作都是这样写的:
import java.io.File;
File file = new File(“index.html”);
但在Java7 中,我们可以这样写:
import java.nio.file.Path;
import java.nio.file.Paths;
Path path = Paths.get(“index.html”);
- Files和Paths工具类
NIO.2在java.nio.file包下还提供了Files、Paths工具类,Files包含了大量静态的工具方法来操作文件;Paths则包含了两个返回Path的静态工厂方法。
Paths 类提供的静态 get() 方法用来获取 Path 对象
static Path get(String first, String … more) : 用于将多个字符串串连成路径
static Path get(URI uri): 返回指定uri对应的Path路径
- Path/Files/Paths常用方法



8.10 第三方Jar包
9 Trowable异常框架
异常体系概述
Java的错误异常分为两个体系:Error、Exception,均继承自Throwable->Object。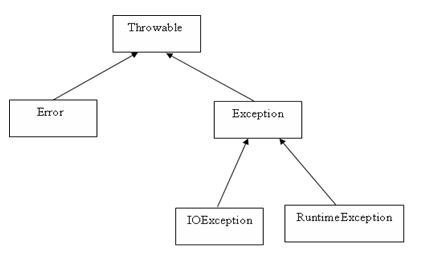
- Error错误类体系:Java虚拟机无法解决的严重问题,如JVM系统内部错误、资源耗尽等严重情况。
- 一般不针对性的进行处理,但也还是可以使用try-catch-finally或者全局异常类进行捕获,同时Spring的事务回滚默认也会进行回滚。
Exception异常类体系:其它因编程错误或偶然的外在因素导致的一般性问题。又分为编译时异常(checked)和运行时异常(unchecked)。
系统自动生成并自动抛出(由java环境检测并自动抛出)
- 手动的生成一个异常对象,并抛出(throw)
Java异常类对象除在程序执行过程中由系统自动生成并抛出,也可根据需要手动创建并抛出。
- 可以抛出的异常必须是Throwable或其子类的实例:
throw new String("want to throw");(报错)。 - 手动抛出的异常和系统抛出的异常一样,都属于抛抓模型的抛出异常这一步骤。
- 手动抛出了编译时异常(须使用了try-catch-finally或throws处理了才可以)。

- 手动抛出了运行时异常(编译可以通过,但是也需要处理,否则运行时还是会出问题)。

- 可以抛出的异常必须是Throwable或其子类的实例:
过程二:捕获异常
为异常的处理方式,也分为两种
try-catch-finally
- try的使用:在try结构中声明的变量,再出了try结构以后,就不能再被调用。
- catch的使用:多个catch之间是互斥的,即如果匹配到了一个catch则后续的catch将不再匹配直接跳出。故如果多个catch的类型满足子父类关系,则要求子类一定声明在父类的上面。否则编译会不通过。
- finally的使用:finally是可选的,最重要特征是:finally里的代码是一定会被执行(即使catch中又出现异常了,try或catch语句中有return语句)。像数据库连接、输入输出流、网络编程Socket等资源,JVM是不能自动的回收的,我们需要自己手动的进行资源的释放。此时的资源释放,就需要声明在finally中。如果finally里面有return语句,则会直接return。
图解案例:

- 执行顺序为:try块内代码Sysytem.out.println(arr[10])出现了索引越界错误并由系统抛出了异常,此时匹配到了catch的ArrayIndexOutOfBoundsException块,执行块内代码,当遇到return语句时,则再跳到finally代码块执行,如果finally块内有return语句,则执行返回,方法体结束。如果finally内没有return语句,则再回到catch块,执行catch块内的return语句。
throws
throws + 异常类型写在方法的声明处。指明此方法执行时,可能会抛出的异常类型,一旦当方法体执行时出现异常,则会在异常代码处生成一个异常类的对象,此对象满足throws后面的异常类型时,就会被抛出。异常代码后续的代码,就不再执行。如果抛出的对象没有被throws后的异常类型捕获到,则程序退出执行。注:方法的调用者必须显示的处理掉(使用try/catch/finally或再次throws)。
补充
try-catch-finally和throws的对比
- try-catch-finally:真正在方法里面将异常给捕获-处理掉了。
- throws:只是在方法里面讲异常捕获了然后将异常抛给了方法的调用者,并没有真正在方法里面将异常处理掉。
如何选择使用try-catch-finally还是throws?
- 如果父类中被重写的方法没有throws方式处理异常,则子类重写的方法也不能使用throws。
- 执行的方法a中,先后又调用了另外的几个方法,这几个方法是递进关系执行的。建议这几个方法使用throws的方式进行处理。而执行的方法a可以考虑使用try-catch-finally方式进行处理。
OutOfMemoryError能否被try-catch
答案:可以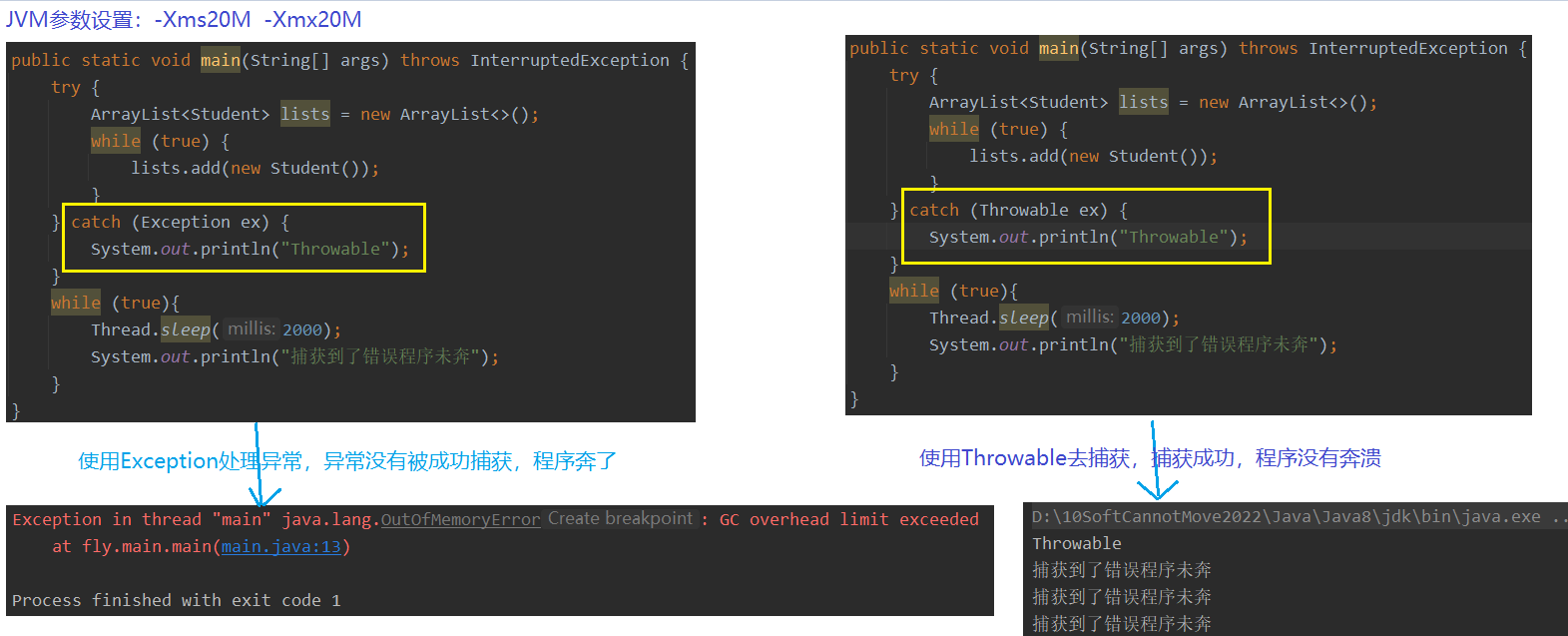

若有收获,就点个赞吧
0 人点赞
